










Serviços Personalizados
Artigo
 Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
Indicadores

Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkSouth African Journal of Industrial Engineering
versão On-line ISSN 2224-7890
versão impressa ISSN 1012-277X
S. Afr. J. Ind. Eng. vol.28 no.4 Pretoria Dez. 2017
http://dx.doi.org/10.7166/28-4-1754
GENERAL ARTICLES
A two-stage solution approach for the large-scale home healthcare routeing and scheduling problem
M. ErdemI, II, *; S. BulkanII
IDepartment of Industrial Engineering, Faculty of Engineering, Atilim University, Turkey
IIDepartment of Industrial Engineering, Faculty of Engineering, Marmara University, Turkey
ABSTRACT
The purpose of this study is to introduce a two-stage solution approach for a large-scale home healthcare routeing and scheduling problem (HHCRSP). In the first part of the two-stage solution approach, a cluster-assign algorithm is employed, based on the home location and the time to obtain feasible clusters. In the second stage, using these clusters, route construction heuristics start to create schedules and routes, taking the side constraints of the model into consideration. Using the novelty of this two-stage solution approach, higher diversification is achieved with a series of newly-developed cross movement strategies. The computational results show that our solution approach offers certain advantages, such as an increase in the efficient use of human resources, and a decrease in the working time of nurses.
OPSOMMING
Die doel van hierdie studie is om 'n tweeledige oplossingsbenadering vir grootskaalse tuissorg roetebeplanning en skedulering voor te stel vir gesondheidsorg. In die eerste deel van die benadering word 'n groepering-algoritme, gebaseer op die ligging van die tuiste en die tyd om vatbare groepe te vorm, toegepas. Tydens die tweede stap van die benadering word die groepe gebruik saam met roetebeplanning-heuristiek om skedules en roetes te skep terwyl die randvoor-waardes van die model in ag geneem word. Die tweeledige benadering bewerkstellig hoër diversifikasie met 'n reeks nuut ontwikkelde kruisbeweging strategieë. Die gesimuleerde resultate toon dat die voorgestelde oplossingsbenadering sekere voordele inhou, onder andere die 'n verhoging in die effektiewe aanwending van menslikehulpbronne en 'n afname in die werktyd van verpleegsters.
1 INTRODUCTION
Health can be briefly defined as the general physical, mental, and social conditions of being well and free from disease [1]. Although there are different and contradictory definitions of health in the literature [2, 3], the general importance of health cannot be ignored. Today, as the population gets older, there is an even greater demand for public healthcare. The World Health Organization (WHO) predicts that the allocation of human resources will be a crucial challenge for the healthcare industry in the next ten years as the population ages. Moreover, the growth rate in healthcare expenses exceeds that of the gross domestic product (GDP) in many countries; thus this issue is crucial for the financial sustainability of healthcare systems. In the US, healthcare spending was 17.5 per cent of GDP ($3 trillion) [4] in 2014, and is predicted to reach 19.3 per cent of GDP (about $4.5 trillion) in 2019. In France, healthcare expenditure is expected to reach €70 billion in 2020 [5]. Many countries are thus looking for ways to improve their fiscal support of healthcare. Furthermore, with labour costs representing nearly half of a hospital's operating costs, executives struggle to manage their healthcare workforce efficiently [6].
The home healthcare routeing and scheduling problem (HHCRSP) comprises the aspects of two well-known problems: routeing and rostering. The HHCRSP gives patients the opportunity to be nursed at home, which is preferable to visiting clinics or hospitals. Furthermore, home care increases the level of service quality and becomes more cost-efficient. On the other hand, designing schedules is difficult due to factors such as patients' or nurses' preferences, policies, time intervals, and travel time according to transportation modes [7].
In this paper, we attempt to address and solve this large-scale HHCRSP. The main motivation of this work is to develop a solution approach to be used to create appropriate solutions while taking all restrictions, preferences, regulations, etc. into consideration. Our two-stage solution approach is based on the 'cluster first and schedule route second' procedure. In the first stage, a cluster-assign procedure is developed, based on the two-step cluster (TSC) algorithm; and in the second stage, the variable neighbourhood descend (VND) algorithm with a series of newly developed strategies is implemented for systematic exploration. Moreover, it is free from a parameter selection/tuning phase; the proposed schedule-route construction heuristics do not necessarily cover all the jobs at the beginning of the second stage; and a series of newly developed cross movement neighbourhood structures provide for higher diversification for the large-scale HHCRSP. Synchronisation is also considered within the proposed model. A two-stage solution approach considers not only the preferences of the nurses and clients, but also those of the healthcare institutions.
This paper is organised as follows. In Section 2, a literature review on the HHCRSP and, in Section 3, the definition of the problem and the model are presented. The proposed solution approach appears in Section 4. The results of the large-scale HHCRSP and comparisons are reported in Section 5. The paper is concluded and future research is discussed in the last section.
2 LITERATURE REVIEW
In this section we review some of the works that tackle the short-term HHCRSP. Cheng and Rich [8] present a mixed integer programming (MIP) model and heuristic approach to deal with the HHCRSP as a multiple vehicle routeing problem with time windows (VRPTW). Full-time and part-time home carers are distinguished, and the lunch break is also considered within the time windows. The authors consider minimising the cost of home carers as an objective. A two-step heuristic approach is proposed. In the first step, a randomised greedy heuristic finds an initial solution. During the next step, the solution is improved using a local search algorithm. The approach is tested using randomly-generated small test examples (four home carers and 10 patients) and larger (up to 300 home carers and 900 patients).
Eveborn, Flisberg and Rönnqvist [9] propose a decision support system (DSS) to solve daily schedules for an organisation in Sweden. They use a set-partitioning problem (SPP) model and improve it by using a repeated matching heuristic approach. The objective function consists of the cost related to the travelling time, and the constraints are time windows for visits or breaks for meals, and the competence level of the staff. Their model is evaluated with small test examples (21 home carers and 123 tasks).
Bertels and Fahle [10] develop a model to minimise transportation costs while maximising the satisfaction level of home carers and patients. The patients' preferences for certain visits, the working time limitations for home carers, and their competence level are considered as constraints. In order to solve single-day problem instances (20-50 nurses and 111-326 tasks), the authors apply a combination of exact approaches (linear programming (LP) and constraint programming (CP)) and metaheuristic approaches (simulated annealing (SA) and tabu search (TS)). The initial solutions are constructed by combining the exact methods, and then the metaheuristics start to improve the solutions. Akjiratikarl, Yenradee and Drake [11] present particle swarm optimisation (PSO) and local improvement procedures to solve five instances (12 nurses, 50 patients, and more than 100 visits). Bredström and Rönnqvist [12] introduce a mathematical programming model that employs additional synchronisation and precedence constraints. They apply a local branching heuristic approach to solve small to medium size test instances.
Rasmussen, Justesen, Dohn and Larsen [13] model the HHCRSP as a SPP with additional constraints, and the problem is generalised as a VRPTW. The branch-and-price (BP) algorithm is proposed as an exact solution approach. The objective function consists of the total travelling cost, uncovered visits, and the preferences of the home carers. The constraints include time windows and a generalised precedence employed to model the different types of temporal dependencies. In order to decrease the dimension of the problem and reduce the run time, a visit-based clustering arrangement is devised, depending on the preferences. However, the use of cluster analysis based on preferences is less effective than the geographical location-based clustering.
Castillo-Salazar, Landa-Silva and Qu [14] introduce a literature survey of workforce rostering and routeing problems. They investigate the characteristics of problem-solution approaches. The authors propose a model that is based on the same model as in the work done by Bredström and Rönnqvist [12].
Trautsamwieser and Hirsch [15] propose a variable neighbourhood search (VNS) approach to optimising the daily scheduling of Austrian Red Cross (ARC) home carers. Their real-world examples cover urban areas (13 nurses, 140 clients, and 140 tasks) and suburban (75 nurses, 420 clients, and up to 512 tasks) areas. The objective is to minimise the travelling and waiting time, and to cover the preferences of clients and nurses. The constraints are working time and breaks. Their proposed method is able to solve small generated examples (four nurses and 20 tasks) optimally. Hiermann, Prandtstetter, Rendl, Puchinger and Raidl [7] present a multi-modal HHCRSP model (driving a car, using public transport) to allocate nurses to the clients of an Austrian HHC provider. Moreover, while Trautsamwieser and Hirsch [15] use time-dependent travelling time, Hiermann et al. [7] use stochastic travelling time estimations. In both of the mathematical models stated above, no synchronisation constraints exist. The objective of Hiermann et al. [7] is to minimise the deviation of different constraints; however, computational comparison with this work is a challenging issue [16]. As in the Trautsamwieser and Hirsch [15] work, Hiermann et al. [7] propose a two-step heuristic solution. Firstly, the initial solutions are generated randomly or via CP. Secondly, these generated solutions are improved by employing different heuristics such as VNS, memetic algorithm (MA), scatter search (SS), and simulated annealing hyper-heuristic (SAHH). In local search procedures, a VND is embedded in VNS, and the neighbourhood structure comprises three movements: swapping nurses, swapping jobs, and repositioning jobs. Moreover, the authors employ a dynamic neighbourhood change/reordering (in VND) based on the improvement of the objective function value.
In a more recent study, Fikar and Hirsch [17] developed a solution procedure for daily schedules by using a dial-a-ride-problem (DARP). In this work, more flexibility is offered by walking to the clients' homes. The objective is to minimise driving-working time; and the constraints are time windows, qualification level, interdependencies, and the capacity of vehicles. They offer a two-stage solution approach that is initialised by building a walking route using the SPP, and then optimising a generated solution via a TS heuristic. The proposed solution procedure is evaluated with a real-life set of data provided by the ARC.
Only small instances (four nurses and 20 clients [15], nine nurses and 45 clients [18]) can be solved optimally; hence, to deal with larger instances, a heuristic approach is required in this framework.
Our solution approach starts with the cluster-assign procedure based on time and location; this leads to improvements in the objectives, and does not sacrifice optimality - as happens with Rasmussen et al. [13]. To our knowledge, this procedure is the first in the field of HHC to consider the location of clients and nurses; more than ten different working time intervals; the preferred starting time of jobs; and the distance between a pair of clusters. Furthermore, within this procedure, the TSC algorithm can yield the number of clusters automatically. This makes our cluster-assign procedure free from parameter- tuning processes. Rasmussen et al. [13] developed a model in which each client demands one job. On the other hand, Hiermann et al. [7] define only the formulation of the problem. In our proposed multi-modal mathematical model, clients can demand more than one job with different competence levels, different durations, and different time intervals. Although the developed model does not involve the term 'the number of nurses', as mentioned before, the proposed approach covers both construction and improvement strategies to reduce the number of nurses. Instead of directly defining a term in the mathematical model, we tackle this issue by using a series of newly-developed neighbourhood strategies.
The proposed solution approach has the following differences from, or improvements on, the work of Hiermann et al. [7]:
• The first stage of our proposed solution approach starts with a clustering algorithm, and then the assignment is carried out by considering the location, time intervals, and travelling distance.
• At the beginning of the second stage, we generate the initial solutions by using three different construction strategies: deterministic, random, and semi-random. Construction strategies do not necessarily cover all the jobs.
• A series of newly-developed neighbourhood strategies proposes a higher diversification ability, while the work of Hiermann et al. [7] only employs three neighbourhood strategies.
• We employ the VND algorithm, which has two parameters: the order of neighbourhood structure, and the maximum number of iterations in the second stage. However, Hiermann et al. [7] used different heuristics that have more than two parameters, making it necessary to apply parameter tuning processes that result in increasing the run time.
• Synchronisation is also considered in our proposed model.
• We focus on large-scale problems in the field of HHC.
• Although Hiermann et al. [7] defined the time windows as soft constraints, in our case a nurse is not allowed to start a job before the time window, and must start a job within the time window.
3 PROBLEM FORMULATION
In this section, a mathematical model and its components representing the HHCRSP will be formulated. The notations for the mathematical model are summarised in Table 1.

The set of nurses and jobs are denoted by N = {1,...,N} and J = {1,..., J } respectively. JAn is the set of all possible jobs for the nurse n. In order to perform some of the jobs, proper coordination may be required. Hence, P is defined as the set of synchronised jobs. The home location of nurses is the starting and ending point of their routes. Thus we introduce two artificial jobs for each nurse. These artificial jobs are {sln, eln}, which represent the starting and ending home locations of nurse n. The working time interval of each nurse is defined by the working time window [nan, nbn], where nurses cannot begin jobs before nai and should finish the assigned job(s) before nbj. If any nurse starts the service before the end of working hours, s/he can continue to work. The clients may demand more than one job represented in the set. For each job I e J, a time window is defined by [jaf, jbj], where jai and jbi correspond to the starting and ending time of the job i respectively. In addition, for each job i, the preferred starting time pt Є e[ja,jfy] and the duration (service time) of the job di are determined. The time window of the artificial jobs equals the working time windows [nasl, nbsl] = [nael, nbel] = [nan, nbn], and the duration and preferred starting time of the artificial jobs are set at zero.
The travelling time between two jobs is based on the parameters of either Sjin(car) or srjn (public transport). Moreover, the travelling time between job sln and job j and the travelling time between job j and job eln are defined as zero for the nurse set. The mode of transportation (car or public transport) of each nurse n is defined by TRn. If any nurse prefers to use public transport, then TRn is one; otherwise, it becomes zero. Each nurse must use her/his own modality, and there is no switch while travelling between jobs. There are five different competence levels, defined from one to five, representing the qualifications of the nurses (nqn). In order to perform a job, it is necessary to satisfy the required level of competence. Nurses can only carry out a job as long as they have a higher or equal level. Furthermore, nurses and clients have some features such as gender, smoking habits, and pet ownership. These features must be considered when creating schedules.
The time cost (Cijn) consists of travelling time (sijn or s’ijn) based on the transportation mode; the duration of job i (di); and idle time (ein) of nurse n if s/he arrives before jai. For the mathematical model, the following decision variables are defined: the binary routeing variables xijne {0,1} ; the binary coverage variables uxie {0,1} ; and the scheduling variables tin, tn, and on. If nurse n travels to job j after handling job i, a binary variable xijnis one; otherwise it is zero. The binary coverage variable is one if job i is uncovered within the solution; otherwise it is zero. The scheduling variable tinis nurse n's starting time for job i. vin is defined as nurse n's arriving time for job i. Nurse n's completion time of the last assigned job and her/his overtime work are denoted as tn, and on respectively.
The general formulation of the HHCSRP is equal to the uncapacitated multi-depot VRPTW [12]. Some of the modifications that cover the topics, such as synchronisation, uncovered visits [13], multimodality, and preferences [7], are added to our proposed model.
The objective function is to minimise the total time costs, uncovered visits, overtime work, and deviation from the preferred time of the job (constraint (1)). The objective function terms are prioritised by assigning time weights (w1and w2), which are J (the number of jobs) and J/2 respectively. Constraint (2) means that visits are either covered or left unassigned; and similarly constraints (3) and (4) are defined to calculate uncovered synchronised visit constraints (M is considered a big number). Nurses can only perform the job if the competence level is satisfied by constraint (5). Constraints (6) and (7) ensure that the nurses start and finish their jobs from their own home. Constraint (8) is introduced to maintain the flow. The time windows must be respected (constraints (9) and (10)), and travelling times are considered via constraint (11). The synchronisation is introduced by constraint (12). Constraint (13) guarantees that a synchronised job can be performed by different nurses. The overtime work of the nurses is calculated via constraint (14). Constraint (15) ensures the characteristics of nurse-client match. Constraints (16) and (17) express a piecewise linear function of the deviation from the starting time of the activity. Constraint (18) determines the arriving times of nurses according to the starting time of the previous jobs, the travelling times based on the transportation mode, and the duration of the jobs. The idle times of nurses are computed via constraints (19) and (20). Similarly, time cost (constraint (21)) is defined as the summation of durations, the travelling times based on transportation mode, and idle times. Constraint (22) is a non-negativity constraint. Constraints (23) to (27) set the domains of the decision variables.


4 SOLUTION APPROACH
In order to deal with the large-scale HHCRSP, a two-stage solution approach is developed, based on the 'cluster-first route-second' approach (Figure 1). Each component of the framework will be presented in this section in turn.
4.1 The cluster-assign procedure (Stage 1)
' Cluster analysis' or ' clustering' is the process of grouping a given set of data into classes. The aim of this process is to consider similar items within the same group and those that are dissimilar to the ones in the other groups [19]. It can also be used to decrease the size of the problem. In our case, the cluster-assign procedure is developed for this perspective.
• Apply the two-step cluster (TSC) algorithm depending on the geospatial data, and construct the clusters for the nurse (cnurse) and job (cjob) sets automatically.
• Calculate the minimum number of cluster sets (min {Cnurse, Cjob}) and re-construct the maximum number of cluster sets for the equalisation of each cluster (Cnurse=Cjob) via TSC.
• Compute the appropriate time interval between the clusters of jobs and the clusters of nurses, considering the average working time interval (for the clusters of nurses) and the average preferred time (for the clusters of jobs).
• Compute the travelling time between each cluster.
• Assign the clusters of jobs to the clusters of nurses for an appropriate time interval and travelling time.
4.1.1 Two-step cluster analysis
In the proposed solution approach, TSC analysis is chosen to identify groups of homes in a city according to location. TSC was proposed by Chiu, Fang, Chen, Wang and Jeris [20] as a method that can be handled with large-scale data, and without considering categorical and continuous variables. Furthermore, one of the benefits of the TSC is to assign the number of clusters automatically. The TSC algorithm consists of two steps: pre-clustering and clustering. In the first step, each case of the data set is scanned, and then a decision is made about whether the case is to merge with the previously created clusters, or whether to construct a new cluster based on the distance criterion. In this step, the cluster feature (CF) tree is constructed to hold the summary statistics of the pre-clusters. This also helps to identify the pre-clusters. One of the advantages of the first step is to reduce the dimension of the initial data by constructing a new data matrix that has fewer cases [20, 21]. In the second step of the algorithm, each pre-cluster is considered as an entity, and an agglomerative hierarchical clustering method is applied to the pre-clusters. This method uses a bottom-up strategy, and begins with each of the sub-clusters obtained in the first step. The algorithm then merges the two closest clusters into a single cluster until all clusters are members of the same cluster [22]. The number of clusters is automatically determined in the second step by considering the lowest Bayesian information criterion (BIC) and the highest ratio of distance measure [20, 21]. After creating the cluster, the next step is to generate the schedules via a metaheuristic approach.
4.2 The schedule-route procedure (Stage 2)
The next stage is the generation of the initial solution. Improving the obtained solution will be discussed later (Figure 1).
4.2.1 Variable neighbourhood search
A VNS is a metaheuristic approach developed by Mladenovic and Hansen [23]. VNS is based on the concept of systematic neighbourhood change that is proposed not only to find a local minimum, but also to avoid being stuck in the area of local minima. VNS advances by using a descent method to reach a local minimum. VND [24] is a version of the VNS method that is employed for improvement. The difference between VNS and VND is the deterministic neighbourhood change: VND does not cover the shaking step, whereas the basic VNS method does. The general scheme of VNS offers simplicity, robustness, and user-friendliness [24]. VND has two parts: the generation of the initial schedule, and the neighbourhood structure, as explained below.
i. Generation of initial schedule
Our solution approach starts with an heuristic that selects jobs in some of the predetermined orders until a solution has been obtained. Jobs are assigned to nurses (routes) based on some criteria by satisfying a set of constraints such as time windows, competence level, etc. [25]. The proposed construction heuristics do not necessarily cover all the jobs at the beginning.
In order to generate an initial schedule, three different approaches are developed in the proposed method. Construction strategy (CS) 1 starts with the smallest index-employee and tries to assign the smallest index-job to this employee if the set of constraints is satisfied. It can be said that CS 1 generates solutions deterministically. CS 2 is the second strategy, and randomly assigns selected jobs to randomly selected nurses. In this way, it can be viewed as a random-solution generation heuristic. The last strategy is CS 3, which can be considered a hybrid of the first two strategies. It starts with the smallest index-nurse and assigns randomly selected jobs to it.
ii. Neighbourhood structures
Different neighbourhood structures are developed to improve the solution constructed in the initialisation phase. These can be classified into three groups: cross, vertical, and horizontal, according to the structure of the HHCRSP (Figure 2). The neighbourhoods are ordered from the smallest to the largest, based on the number of the neighbourhoods [26]. The order of this structure numbers each strategy numerically from 1 to 9. The best solutions are generated by this order of neighbourhoods in the initial runs.
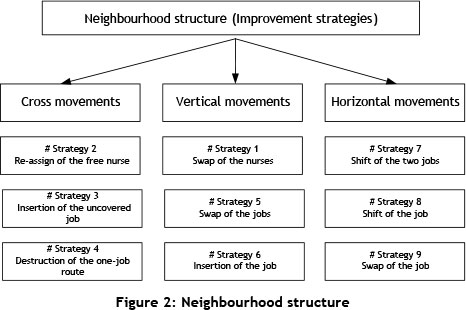
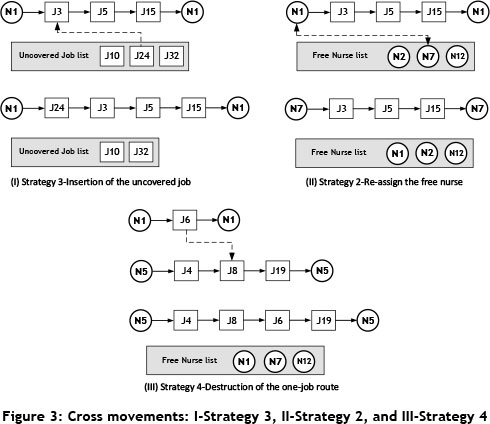
Cross movements: This group covers a series of newly developed neighbourhood structures. The aim of the newly developed cross movement strategies is to achieve an improved ability to diversify. Once the initial schedule is generated, some of the jobs might be left unassigned, and similarly some of the nurses might not be a part of the schedule. Thus, in order to cover all the jobs and to use the human resources efficiently, three movements or neighbourhoods are developed (Strategies 3, 2, and 4). These are illustrated in Figure 3, where circular and square nodes correspond to the nurses and the jobs respectively. Strategy 3 chooses one of the jobs randomly from the uncovered job list, and assigns this job to a randomly selected route/nurse. The aim of Strategy 2 is to benefit more efficiently from the human resources. When the free nurse list has an element, Strategy 2 starts to work. A randomly selected nurse from the free nurse list is exchanged with a randomly selected working nurse if there is a reduction in the objective function value. Strategy 4 is employed to remove one-job routes. This strategy looks for one-job routes and checks whether or not the element (job) of the route can be inserted into randomly selected multi-job routes. If this movement results in a reduction in the objective function value, the removal of the one-job route takes place during this step. Strategy 4 is developed to cover all of the jobs with the minimum number of nurses.
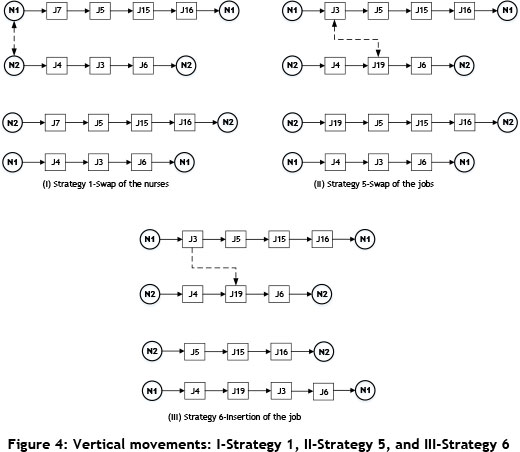
Vertical movements: This group consists of three strategies: Strategy 1, Strategy 5, and Strategy 6, as illustrated in Figure 4. Strategy 1 is proposed to swap two randomly selected employees if there is an improvement in the objective. Similar to Strategy 1, Strategy 5 is developed to swap these two randomly selected jobs. In this vertical movement, the locations of the two are also chosen by chance. The last movement in this group is Strategy 6, which employs insertion.
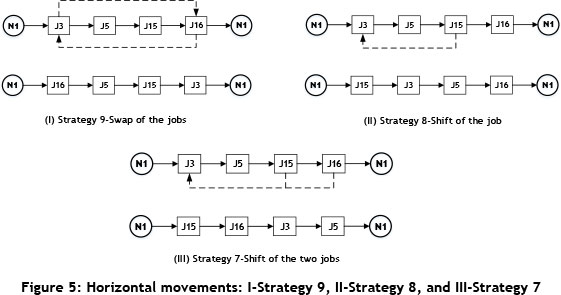
Horizontal movements: This group covers the basic neighbourhood structures: swap and shift. They are developed to find the best sequence/location of jobs. These locations are chosen by chance, and if there is an improvement, the swap occurs in the schedule during the Strategy 9 process. The difference between Strategy 9 and Strategy 8 is the shift mechanism; the working principle is the same for this improvement perspective. The last member of the horizontal movements is Strategy 7; this is the two-job shift version of Strategy 8. These strategies are illustrated in Figure 5.
4.3 Test instances
Initially, the proposed solution approach is tested on the four instances (Days 1, 2, 3, and 4) provided by Hiermann et al. [7]. (The test instances and their detailed explanation can be found at https://www.ads.tuwien.ac.at/w/Research/Problem_Instances.) No benchmark data is available, so we have generated a series of large-scale instances in accordance with these publicly available instances. Moreover, because of the lack of synchronisable jobs, five per cent of the jobs are added for each instance. The data instances involve more than 10 different working time windows and varied specified time windows for the jobs. The time in these instances is represented by a discrete time unit, which is set at 5. Assume that a nurse travels from one customer to another; this then takes six time units, which is a total of 30 minutes. The time windows are also computed in a similar manner.
5 COMPUTATIONAL RESULTS
In this section, the proposed solution approach is run on the four publicly available instances, and the results are compared with the solution method used by Hiermann et al. [7]. The proposed algorithm is then run on the series of generated large-scale instances. As stated in Cissé, Yalçindag, Kergosien, Sahin, Lenté and Matta [27], there is no benchmark instance in the literature: all the published papers have used different models and different instances. In this study, we modified the VNS solution approach of Hiermann et al. [7] to solve our instances and compare them with the proposed solution approach.
The algorithm is run 10 times for all test instances on an Intel i7-5500U CPU 2.4GHz PC with 8GB RAM. The maximum number of iterations is set to 30,000 for each run. In the first stage of the proposed method, the cluster-assign procedure runs and forms the clusters. The second stage of the proposed method is to generate schedules and routes for each cluster with a VND heuristic, in which nine different neighbourhood structures are employed for a higher diversification ability.
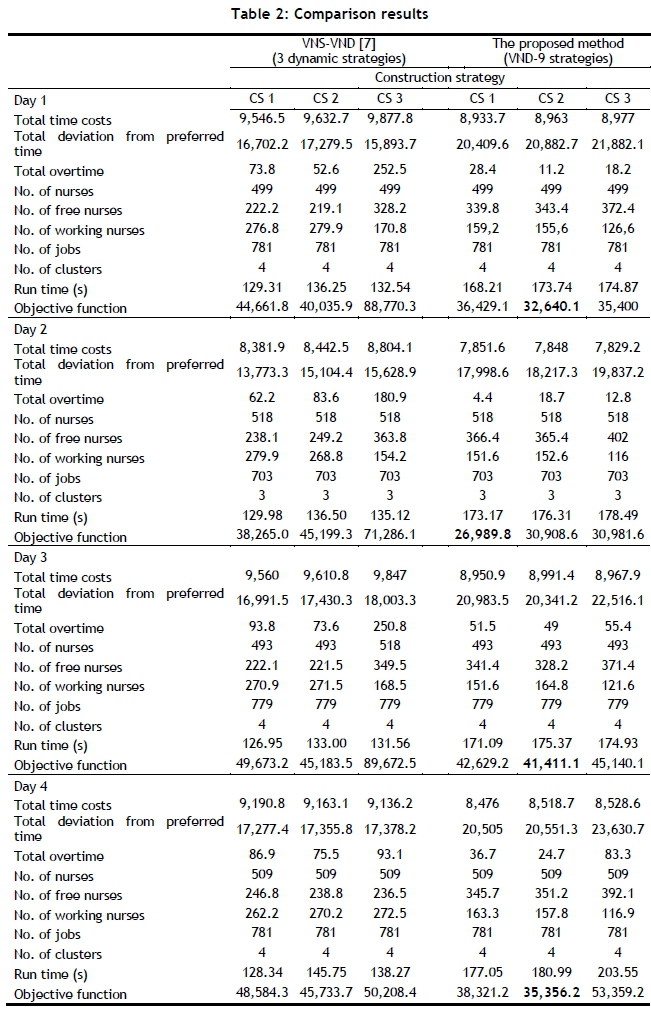
The computational comparisons with the work of Hiermann et al. [7] are a challenge [16], since the comparisons have been carried out based on our model and considerations for the HHCRSP. In order to investigate the efficiency of the proposed VND approach, the computational results will be compared with the VNS-VND embedded in the three dynamic neighbourhood strategies proposed by Hiermann et al. [7]. Although they generated initial solutions via CP and a random construction heuristic, here the VNS-VND algorithm starts with the three proposed construction strategies. The performance measures by which the solutions are evaluated are the number of uncovered jobs and assigned (or working) nurses, the total time costs, the total overtime work, and the deviation from the preferred time. The average computational results and the details of these results are presented in Table 2 and Table 3 respectively. The objective function and its components, the number of nurses and jobs, the number of working and free nurses, and the number of clusters for each instance are represented in rows. The best solution for each instance is shown in bold. Although using different neighbourhood structures increases the run time, the proposed approach provides better results than the VNS-VND method in terms of objective function value for all instances. When the initial solution strategies are considered, CS 3 uses a smaller healthcare workforce for each instance. On the other hand, CS 1 and 2 schedule more nurses than CS 3, depending on the deterministic and random insertion mechanisms.
When Table 2 is investigated further, it can be said that all the jobs are a part of the schedule. Thus the total duration time is fixed, and there is no room for the minimisation of this term. In order to minimise the total time costs, we should deal with the travelling time components. The proposed solution approach yields reduced total time costs, which means that the assigned nurses take less time. This improvement is accomplished because of the reduced total travelling time and idle (waiting) time. The VNS-VND approach of Hiermann et al. [7] generates schedules for the HHCRSP with more working time than the results presented in this paper. Similarly, the solutions of the VNS-VND approach propose more overtime work than the proposed method.
The last measure of quality of the results is the preferred time deviation. It can easily be seen that our solution approach causes higher time deviations for a number of reasons. First, the initial aim is to complete all of the sets of jobs with the minimum number of nurses, causing an increase in the deviation of time. That is, the generated schedules assign more jobs to fewer nurses. At first glance, this solution approach seems to increase the nurse-to-patient ratio; however, it considers the safety issues for the HHC system. This ratio should not exceed 1:8 [28, 29] for hospitals. Moreover, if the jobs are regarded as customers, or if we convert the nurse-to-patient ratio to a nurse-to-job ratio, this ratio does not exceed 1:8 for the HHC system. Secondly, time windows for the jobs are not considered as soft constraints. In other words, the nurses must wait before the opening time window of a job, and then continue to work if they start to complete the job before the closing time window.
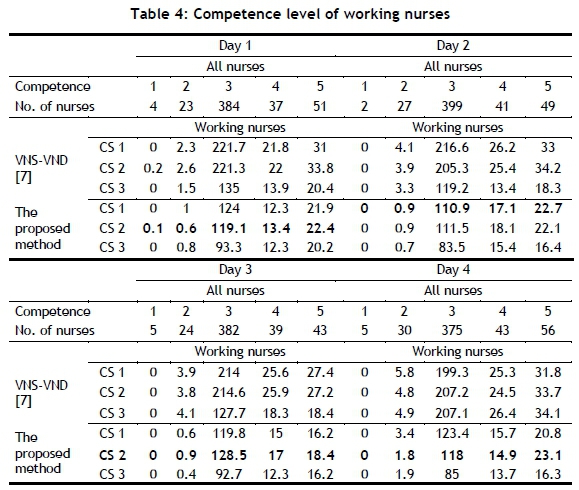
The results of the proposed approach employ the minimum number of nurses; in fact, it also does not send overqualified nurses to the clients. Indeed, the proposed approach - including especially CS 3 - is the leading method for assigning the minimum number of nurses. The distribution of working nurses for four days according to their competence is illustrated in Table 4. The results mean that our approach provides more nurse satisfaction than the VNS-VND approach.
In order to investigate the efficiency of the newly developed cross movement structures, more computations have been carried out. The algorithm was tested on the Day 1 instance; the results are compared in Figure 6. Here, in case the initial construction strategies cannot cover all of the jobs, only Strategy 6 will run. It is obvious that the newly developed cross movement strategies offer higher diversification and improvement without considering construction heuristics. In a similar way, the efficiency of the clustering approach is examined; the results are illustrated in Figure 7. The number of different clusters is shown on the horizontal axis, with the lines corresponding to the objective function, and the columns represent the run time. Although clustering increases the run time, the objective function begins to improve by applying clustering. The important point here is that, to determine the appropriate number of clusters, we assign the number of clusters according to the min{cnurse, Cj0b} in the cluster-assign procedure; for the Day 1 instance, the number of clusters is set at four, and this four-cluster formation proposes the minimum objective function values for all the construction strategies. The same pattern is followed for the Day 2 instance. As a result, it is reasonable to apply clustering in the first stage, and the solution quality is not deteriorated by the use of clustering.
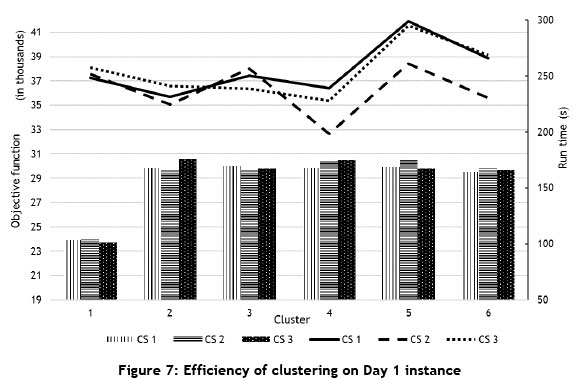
Table 5 provides an overview of the generated large-scale instances consisting of different numbers of nurses and jobs, and summarises the computational results. Synchronisation is also considered for the generated instances. Here, the algorithm covers all the jobs, and the results based on three different construction strategies represent the average value of 10 runs. For Instance 1, with the initial solution CS 1, the objective function value is calculated to be 16,653.30, the run time is 132.99 s, and the number of working nurses is 88.8. According to the objective function value, CS 2 initialisation generally yields better solutions. The algorithm initialised with CS 1 generally runs faster than the others. CS 3 constructs solutions with the minimum number of nurses.
6 CONCLUSION
The work introduces a two-stage solution approach for a large-scale HHCRSP. The approach integrates cluster analysis and heuristics into an optimisation framework. Some of the advantages are that it is free from optimal parameter selection in each stage, it creates feasible clusters, and has a higher diversification ability covering different strategies.
Our model considers nurses, clients, and healthcare institutions; thus there is no violation of the preferences of the clients and nurses. Only the preferred starting time of the jobs deviates. The numerical results indicate profitable outcomes. The decrease in the total time helps nurses to arrive at the clients' homes on time because of the reduced travelling time. Minimising the length of the schedules also increases the nurses' satisfaction. Furthermore, choosing an appropriate mode of transport and minimising the total travelling time leads to a lower fuel and energy consumption by vehicles and nurses. From the perspective of the healthcare institutions, they have the opportunity to create schedules with a minimum number of healthcare workers and to decrease personnel costs without being understaffed.
For future research, we intend to apply the route-first cluster-second method (based on the giant tour), which is the opposite of the approach proposed here. The extension of the daily planning horizon to the medium term is another subject for the HHCRSP. Because of the modularity of this two-stage solution approach, it can employ different clustering algorithms in the first stage, and different metaheuristics can be used for the improvement stage without ignoring the newly developed neighbourhood structures.
REFERENCES
[1] WHO. 1948. WHO definition of health, http://www.who.int/about/definition/en/print.html [accessed 01/06/16]. [ Links ]
[2] Huber, M. 2015. Health: Definitions A2, in James D. Wright (ed.), International Encyclopedia of the Social & Behavioral Sciences (second edition). Oxford: Elsevier. [ Links ]
[3] Song, M. & Kong, E.-H. 2015. Older adults' definitions of health: A metasynthesis. International Journal of Nursing Studies, 52(6): pp. 1097-1106. [ Links ]
[4] Leonard, K. 2015. Obamacare, drug prices behind health spending growth. http://www.usnews.com/news/articles/2015/12/02/rate-of-spending-on-health-care-is-on-its-way-up-again [acessed 09/06/16]. [ Links ]
[5] Mattke, S., Klautzer, L., Mengistu, T., Garnett, J., Hu, J. & Wu, H. 2010. Health and well-being in the home: A global analysis of needs, expectations, and priorities for home health care technology. Santa Monica: RAND Corporation. [ Links ]
[6] Maenhout, B. & Vanhoucke, M. 2013. An integrated nurse staffing and scheduling analysis for longer-term nursing staff allocation problems. Omega, 41(2): pp. 485-499 [ Links ]
. [7] Hiermann, G., Prandtstetter, M., Rendl, A., Puchinger, J. & Raidl, G. 2015. Metaheuristics for solving a multimodal home-healthcare scheduling problem. Central European Journal of Operations Research, 23(1): pp. 89-113. [ Links ]
[8] Cheng, E. & Rich, J.L. 1998. A home health care routing and scheduling problem. [ Links ]
[9] Eveborn, P., Flisberg, P. & Rönnqvist, M. 2006. Laps care: An operational system for staff planning of home care. European Journal of Operational Research, 171(3): pp. 962-976. [ Links ]
[10] Bertels, S. & Fahle, T. 2006. A hybrid setup for a hybrid scenario: Combining heuristics for the home health care problem. Computers & Operations Research, 33(10): pp. 2866-2890. [ Links ]
[11] Akjiratikarl, C., Yenradee, P. & Drake, P.R. 2007. PSO-based algorithm for home care worker scheduling in the UK. Computers & Industrial Engineering, 53(4): pp. 559-583. [ Links ]
[12] Bredström, D. & Rönnqvist, M. 2008. Combined vehicle routing and scheduling with temporal precedence and synchronization constraints. European Journal of Operational Research, 191(1): pp. 19-31. [ Links ]
[13] Rasmussen, M.S., Justesen, T., Dohn, A. & Larsen, J. 2012. The home care crew scheduling problem: Preference-based visit clustering and temporal dependencies. European Journal of Operational Research, 219(3): pp. 598-610. [ Links ]
[14] Castillo-Salazar, J.A., Landa-Silva, D. & Qu, R. 2014. Workforce scheduling and routing problems: Literature survey and computational study. Annals of Operations Research, pp. 1-29. [ Links ]
[15] Trautsamwieser, A. & Hirsch, P. 2011. Optimization of daily scheduling for home health care services. Journal of Applied Operational Research, 3: pp. 124-136. [ Links ]
[16] Fikar, C. & Hirsch, P. 2017. Home health care routing and scheduling: A review. Computers & Operations Research, 77: pp. 86-95. [ Links ]
[17] Fikar, C. & Hirsch, P. 2015. A matheuristic for routing real-world home service transport systems facilitating walking. Journal of Cleaner Production, 105: pp. 300-310. [ Links ]
[18] Trautsamwieser, A. & Hirsch, P. 2014. A branch-price-and-cut approach for solving the medium-term home health care planning problem. Networks, 64(3): pp. 143-159. [ Links ]
[19] Han, J. & Kamber, M. 2006. Data mining: Concepts and techniques. The Morgan Kaufmann Series in Data Management Systems, 2nd edition. Morgan Kaufmann. [ Links ]
[20] Chiu, T., Fang, D., Chen, J., Wang, Y. & Jeris. C. 2001. A robust and scalable clustering algorithm for mixed type attributes in large database environment. In Proceedings of the seventh ACM SIGKDD international conference on Knowledge discovery and data mining: pp. 263-268. San Francisco: ACM. [ Links ]
[21] Michailidou, C., Maheras, P., Arseni-Papadimititriou, A., Kolyva-Machera, F. & Anagnostopoulou, C. 2009. A study of weather types at Athens and Thessaloniki and their relationship to circulation types for the cold-wet period, part I: Two-step cluster analysis. Theoretical and Applied Climatology, 97(1-2): pp. 163-177. [ Links ]
[22] Zaki, M.J. & Meira Jr., W. 2014. Data mining and analysis: Fundamental concepts and algorithms. 1st edition. USA: Cambridge University Press. [ Links ]
[23] Mladenovic, N. & Hansen, P. 1997. Variable neighborhood search. Comput. Oper. Res., 24(11): pp. 1097-1100. [ Links ]
[24] Hansen, P., Mladenovic, N., Brimberg, J. & Pérez, J.A.M. 2010. Variable neighborhood search, in M. Gendreau and J.-Y. Potvin (eds), Handbook of metaheuristics. Boston: Springer US. [ Links ]
[25] Bräysy, O. & Gendreau, M. 2005. Vehicle routing problem with time windows, Part I: Route construction and local search algorithms. Transportation Science, 39(1): pp. 104-118. [ Links ]
[26] Hansen, P. & Mladenovic, N. 2002. Developments of variable neighborhood search, in C.C. Ribeiro and P. Hansen (eds), Essays and surveys in metaheuristics. Boston: Springer US. [ Links ]
[27] Cissé, M., Yalçindag, S., Kergosien, Y., Çahin, E., Lenté, C. & Matta, A. 2017. OR problems related to home health care: A review of relevant routing and scheduling problems. Operations Research for Health Care, [ Links ]
[28] Aiken, L., Clarke, S., Sloane, D., Sochalski, J. & Silber, J. 2002. Hospital nurse staffing and patient mortality, nurse burnout, and job dissatisfaction. JAMA, 288(16): pp. 1987-1993. [ Links ]
[29] Pasnap. 2016. Studies on nurse-to-patient ratios. http://www.pennanurses.org/pac/ratio-research/ [accessed 21/06/16]. [ Links ]
Submitted by authors 31 Mar 2017
Accepted for publication 25 Oct 2017
Available online 13 Dec 2017
* Corresponding author: mehmet.erdem@atilim.edu.tr


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}