










Services on Demand
Journal

Article
 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
Related links
-
 Cited by Google
Cited by Google -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkSouth African Journal of Industrial Engineering
On-line version ISSN 2224-7890
S. Afr. J. Ind. Eng. vol.26 n.3 Pretoria Nov. 2015
https://doi.org/10.7166/26-3-1030
GENERAL ARTICLES
A heuristic approach to minimising maximum lateness on a single machine
B. Çaliş; S. BulkanII; F. TurçerIII
IDepartment of Industrial Engineering Marmara University, Turkey. bcalis@marmara.edu.tr,
IIDepartment of Industrial Engineering Marmara University, Turkey.sbulkan@marmara.edu.tr
IIIDepartment of Computer Engineering Marmara University, Turkey ferittuncer@marun.edu.tr
ABSTRACT
This paper focuses on the problem of scheduling on a single machine to minimise the maximum lateness when each job has a different ready time, processing time, and due date. A simple procedure is developed to find a better solution than the early due date (EDD) algorithm. The new algorithm suggested in this paper is called Least Slack Time -Look Ahead (LST-LA), which minimises the maximum lateness problem. Computational results show that when the number of jobs increases, LST-LA outperforms EDD.
OPSOMMING
Die artikel konsentreer op die skedulering van 'n enkele masjien om die maksimum laatwees probleem, wanneer elke taak 'n verskillende gereedheidstyd, prosesseertyd en keerdatum het, te minimeer. 'n Eenvoudige prosedure om 'n beter oplossing tot die vroeé keerdatum algoritme te bepaal, is ontwikkel. Die nuwe algoritme word die "Least Slack Time Look Ahead" genoem en dit minimiseer die maksimum laatwees probleem. Simulasie resultate toon dat soos die aantal take toeneem, vertoon die nuwe algoritme beter as die vroeé keerdatum algoritme.
1 INTRODUCTION
This paper considers the problem of finding an effective schedule for n jobs with different release dates on a single machine, in order to minimise the maximum lateness. The single machine scheduling problem is one of the important problem types in machine scheduling models; it can be used to solve the single machine models, or it gives an initial solution to the decomposition of big problems into sub-problems, such as job shops or flow shops. Minimising maximum lateness (Lmax) is an important objective if all preceding activities must be completed before the rest can begin in a project; i.e., a very late activity may cause a delay in the project. In addition, Lmax may be used as an aid for solving other problems [1].
To define a scheduling problem, the well-known three-field notation of Graham et al. [2], α I β I γ, is used, where α, β, and γ represent the machine environment, job characteristics (problem constraints), and objective function respectively. The scheduling problem studied in this work is minimising maximum lateness (Lmax) for n jobs, with release dates (rj) on a single machine. The problem is denoted by 1 I rjI Lmax and shown as NP-hard by Lenstra et al. [3]. When the difference of Cj-dj (completion time of job j - due date of job j) is positive, the job is said to be late; if the difference of Cj-dj is negative, the job is said to be early; if the result of the difference equals zero, the job is said to be on time.
This paper provides a brief and up-to-date literature review of the single machine maximum lateness with release times. It then proposes a simple and effective heuristic called Least Slack Time - Look Ahead (LST-LA) to solve the 1 | r,| Lmax problem. The solutions obtained by the full enumeration (for the problems up to 13 jobs) and early due date (EDD) rule (for the problems with more than 13 jobs) are compared. Experimential results of the study show that the proposed algorithm (LST-LA) outperforms the EDD algorithm, on average, by at least 400 per cent on the Carrier's instances.
The outline of this paper is as follows. In Section 2, the maximum lateness problem is defined. In Section 3, the analysis of the proposed heuristic algorithm, procedures, and a computational example are explained in detail. Section 4 presents computational results based on the randomly generated problem instances for the single machine minimising maximum lateness problem under study. Section 5 presents the statistical analysis of the results. Test results on Carlier's problems are also presented in Section 5.2. Finally, in Section 6, overall conclusions are drawn and future research paths are highlighted.
2 MINIMISING THE MAXIMUM LATENESS PROBLEM
The problem without release times (1|| Lmax) is optimally solvable by the EDD first in polynomial time [4]. The EDD rule can be defined as the set of n jobs, with known processing times and due dates; the minimum value of Lmax is achieved by sequencing the jobs in non-decreasing order of their due dates [5]. A detailed literature review on the single machine maximum lateness problem with release times (1 |rj|Lmax) can be found in Sels and Vanhoucke [6]. The well-studied problem 1|rj|Lmax is a special case of problem 1|prec;rj|Lmax.
Oyetunji and Oluleye [7] proposed a heuristic to reduce the number of tardy jobs by scheduling the jobs according to an ascending order of the job allowance; test results show that the given algorithm is faster than others when the number of jobs is large.
McMahon and Florian [8] provide efficient branch and bound algorithms to solve this problem. Lagaweg et al. [9] studied scheduling jobs on a single machine subject to given release dates and precedence constraints; they described applications to the theory of job-shop scheduling and to a practical scheduling situation.
Frederickson [10] showed that the problem of scheduling n unit-time tasks with integer release times and deadlines is solvable in O(n log n) time, if a sufficient amount of uninitialised space is available. Baker et al. [11] considered that n jobs are to be processed on a single machine, subject to release dates and precedence constraints, and they presented an O(n2) algorithm for this problem.
Gordon [12] considered the optimal assignment of slack due-dates and sequencing in the single-machine shop to the case when pre-emption is allowed and there are precedence constraints and ready times of jobs. The study shows that under special conditions, the presented algorithm may be used when pre-emption is not allowed.
Oyetunji and Oluleye [13] considered the single machine scheduling problem subject to release dateto minimise total completion time and the number of tardy jobs and a proposed a solution algorithm, which was recommended when there are 30 or more jobs in the problem.
Monma and Potts [14] studied the single machine scheduling problem with sequence-dependent family setup times. Results of their study showed that "for the maximum lateness problem, there is an optimal schedule where the jobs within each batch are ordered by the EDD rule".
Schrage [15] proposed an algorithm that considers scheduling an available job with the largest tail time. Carlier [16] studied how to solve the 1| η, qj | Lmax problem. Results from Carrier's algorithms shows that this is the most promising approach in the literature.
A lot of researchers considered minimising the maximum lateness problem under different constraints. Due to the NP-hard nature of the problem, a number of different heuristics have been developed. In this study, minimising the maximum lateness problem is studied under a release date constraint; and a simple and efficient heuristic algorithm called LST-LA is proposed and tested on randomly-generated problems.
The next section includes detailed information about the proposed heuristic algorithm.
3 PROPOSED LST-LA ALGORITHM
The problem of 1|1rj |Lmax is strongly NP-hard [15]. The problem considers n independent jobs (j=1,2,...,n ) with unequal release dates (rj) on a single machine to minimise maximum lateness. There are no precedence constraints between jobs, and each job has positive due dates, dj (dj > 0). The machine is continuously available and can process one job at a time.
The problem of 1 || Lmax is the best-known special case of 1 | prec | hmax. The function hj is then defined as Cj-dj, and the algorithm results in the schedule that orders the jobs in increasing order of their due date [14]; in order to minimise the maximum lateness the algorithm processes the jobs in non-decreasing due date order. This dispatching rule is known as EDD, or Jackson's rule, after Jackson [16] who studied it in 1955 [17].
The results obtained by LST-LA are compared with the results from the EDD rule. The notations below are used to describe the scheduling problem.
Problem procedures: the flow chart of the LST-LA algorithm is given in Figure 1.
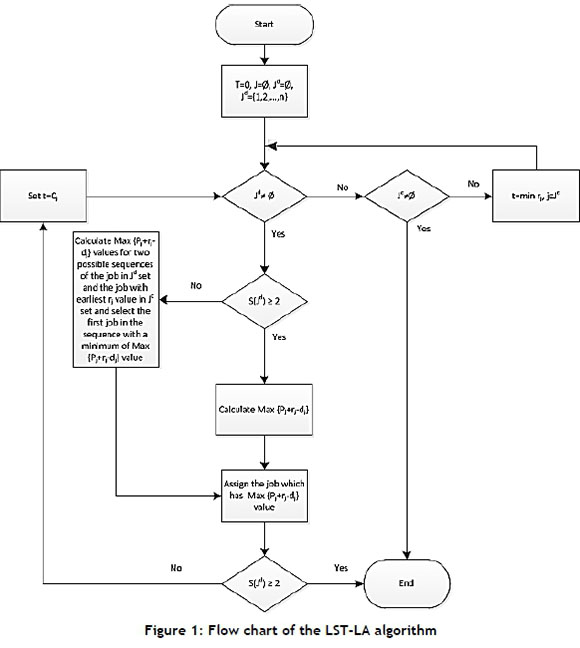
Notations:
J : set of scheduled operations
Jd : candidate to schedule jobs at time t, (rj < t)
Jc : set of unscheduled operations
t : scheduling time
Lmax : maximum lateness
Lj : lateness of job j
Pj : processing time of job j
dj : due date of job j
Cj : completion time of job j
The machine is assumed to be continuously available and can process, at most, one job at a time.
The jobs may not be pre-empted, and each job j is characterised by its processing time pj, its release time rj, and its due date dj.
3.1 Algorithm definition
The flow chart of the proposed LST-LA algorithm can be seen in Figure 1.
The pseudo code of the proposed model is given in Figure 2.

3.2 A computational example
In this part of the study, execution of the algorithm is presented using a small example in order to demonstrate the algorithm. Sample data is given in Table 1.
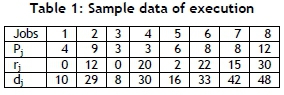
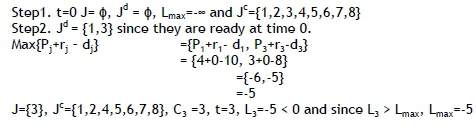
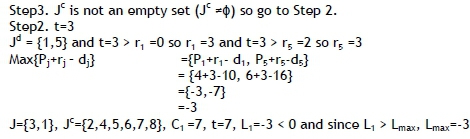
Step3. J° is not an empty set (Jc ≠ ø), so go to Step 2.
Step2. t=7 and Jd set has only one job (J5), check the next available job (j2 and r2 =12), which has next minimum rj value in Jc set and calculate Lmax values for two possible sequences of two jobs, and then schedule the first job in the sequence that results in minimum Lj value for the second job in the sequence. Jd = {2, 5}
For the sequence of 5, 2:
Since t=7 > r5 =2 so r5 =7
L5={P5+r5-d5}= {6+7-16}=-3 and C5=13, t=13 > r2 =12 so r2 =13.
L2={P2+r2- d2}= {9+13-29}=-7 and C2=22, t=22
Max {L5, L2} = -3 < 0 so Lmax =-3 (for the sequence of 5, 2)
For the sequence of 2, 5:
Since t=7 < r2 =12 so keep the machine idle until time 12 and set t=12
L2={P2+r2-d2}= {9+12-29}=-8 and C2=21, t=21 > r5 =2 so r5 =21
L5={P5+r5-d5}= {6+21-16}=11 and C5=27, t=27
Max {L2, L5} =11 > 0 so Lmax =11 (for the sequence of 2, 5)
Since Lmax value is minimum for the first sequence (i.e., sequence of 5, 2) Job 5 will be selected and assigned to the J set. So, J={3,1,5}, Jc={2,4,6,7,8}, C¡ =13, t=13, Lj=-3 < 0 Lmax=-3.
Step3. Jº is not an empty set (Jc *φ), so go to Step 2.
At the end of the solution all sets are calculated as:
J={3,1,5,2,6,4,7,8}, Jc= φ, C8 =53, t=53, L3 =-5, L1=-3, L5=-3, L2=-7, L6=-3, L4=3, L7=-1 and L8=5. LST-LA yields an Lmax=5, which is identical to the Lmax obtained by EDD solution although the sequence is different.
4 TEST PROBLEMS AND RESULTS
First, the problem data is generated as follows:
pj is generated from a discrete uniform distribution between 5 to 50
rj is generated from a discrete uniform distribution between 0 and 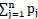
dj is generated from a discrete uniform distribution between 0 and [max rj + max pj]
The problem is then tested with 15 independent samples with a constant size of 10. LST-LA, EDD, and full enumeration (FE) solutions are calculated and compared in Table 2.
LST-LA obtained an optimal solution eight times out of 15 for randomly-selected problems, the EDD rule obtained an optimal solution only once, and the EDD rule ended up with a better solution than the LST-LA algorithm only once. The percentage differences show that the EDD rule yielded a maximum lateness up to 57 per cent away from the optimum value obtained by the full enumeration, whereas the LST-LA algorithm yielded a maximum lateness up to 19.3 per cent away from the optimum solution. The average percentage differences are calculated to be 23.17 per cent between EDD and FE, and 5.12 per cent between LST-LA and FE. LST-LA yields solutions that are 17.41 per cent lower than EDD, and these results mean that LST-LA gives a better solution than EDD, on average.
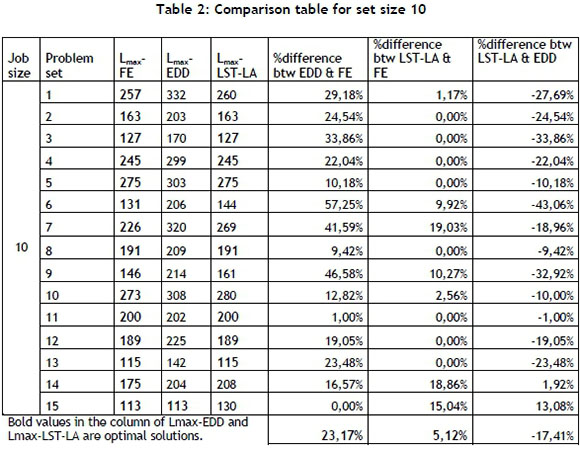
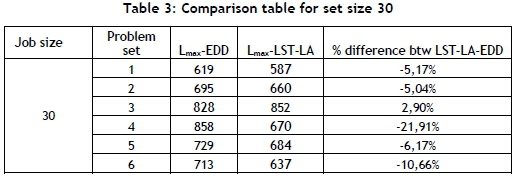
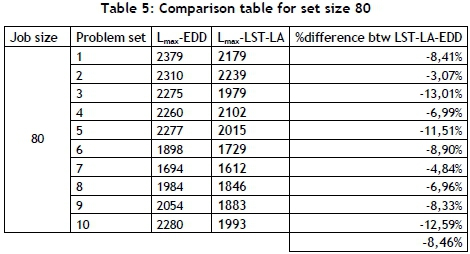
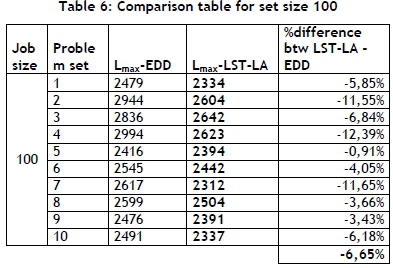
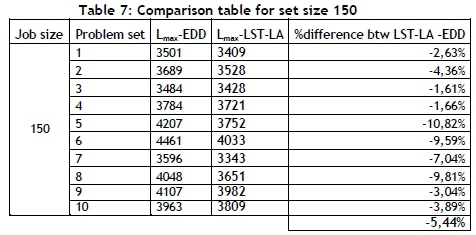
Hereafter, the problem set size is increased to 30, 50, 80, 100, and 150 jobs, and the results are listed in Table 3, Table 4, Table 5, Table 6, and Table 7, respectively.
When the job size increases to 30 jobs (Table 3), LST-LA yields solutions that are 8.16 per cent lower than EDD, on average. The LST-LA algorithm obtains better results than EDD in 13 out of the 15 test problems, whereas EDD yields better results than LST-LA only twice out of the 15 test problems. The LST-LA algorithm yields better results than EDD 8.16 per cent of the time, on average.
The LST-LA algorithm yields solutions that are 4.61 per cent lower than EDD, on average, for the problems with 50 jobs, as seen in Table 4.
The LST-LA algorithm yields solutions that are 8.46 per cent lower than EDD, on average, for the problems with 80 jobs, as seen in Table 5.
For 100 job problems, LST-LA yields solutions that are 6.65 per cent lower than EDD, on average, as seen in Table 6.
For the problems with 150 jobs, as can be seen in Table 7, improvement of LST-LA's results is 5.44 per cent compared with EDD, on average.
5 STATISTICAL ANALYSIS
5.1 Statistical analysis of the randomly-generated problems
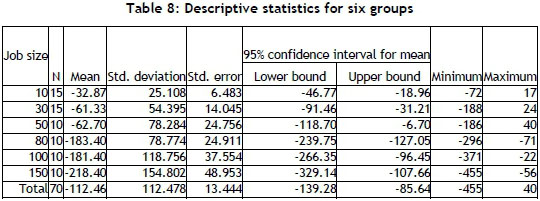
In order to discover the relationship between the two algorithms and to obtain more reliable test results, the data was transferred to SPSS software. First, descriptive statistics were gathered for μΩ(mean differences) for six test sets. The results are given in Table 8 where, as can be seen, negative differences show that LST-LA reaches lower maximum lateness values than EDD.
The paired t test is performed for all groups to see whether there is a significant difference between the two algorithms [18].
Ho: μD =0
Ho: μD =0
As can be seen from Table 9, p value = 0.00 <0.05 and H0 is rejected at level 0.05.
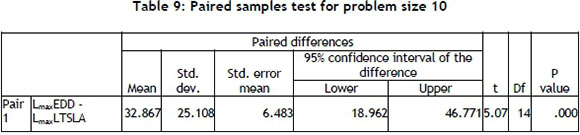
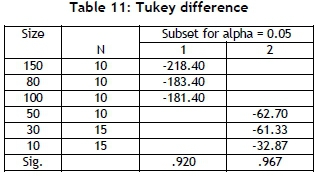
Tukey's procedures are then used to look for significant differences among μDIs [17]. The ANNOVA table (Table 10) is also used to see whether there is a significant difference between the results of LST-LA and EDD, both between and within groups.

Hypothesis testing is:
Ho: All μDI. s are equal
H1: At least two of the μDIs are different
Group sizes 10, 30, and 50 are not significantly different from each other. Group sizes 80,100, and 150 are also not significantly different from one another, but these two groups are significantly different from each other, as seen in Table 11. This result shows that when the number of jobs increases, LST-LA outperforms EDD on minimising the maximum lateness problem.
5.2 Experimental tests on Carrier's benchmark problems
For the additional experimental analysis, test instances were generated in the way defined by Carlier [16]. For the generation of problems, the following parameters were used:
n= 50, 100,150,200, 1000, and
K= 16, 17, 18, 19, 20, 21, 22, 23, 24, 25
A sample of 20 instances was generated for each job size and difficulty level.
pj is generated from a discrete uniform distribution between 0 and pmax= 50,
rj is generated from a discrete uniform distribution between 0 and rmax =n*K
qj is generated from a discrete uniform distribution between 0 and qmax=n*K
dj = rj+pj+qj
where n is the job size, pj is the processing time of the job j, rj is the release date of job j, K is the parameter to define the tightness of due dates, qj is the tail time of job j, pmax is the maximum processing time of jobs, rmax is the maximum release time, qmax is the maximum tail time, and dj is the due date of job j.
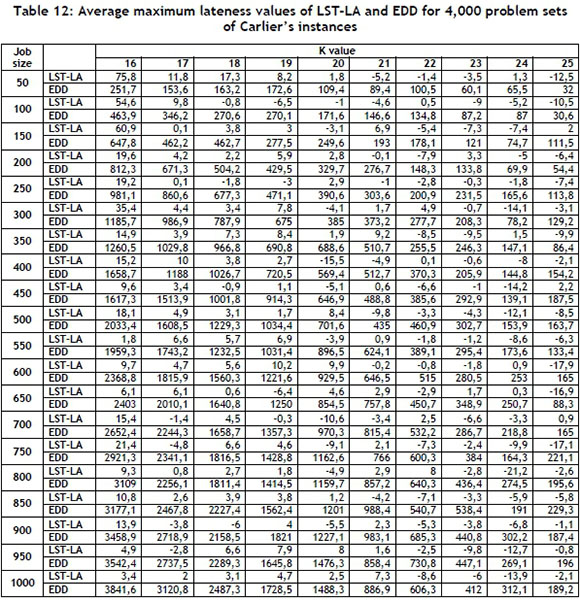
In this case, 4,000 instances were analysed in 200 different problem sets; the average maximum lateness values obtained by LST-LA and EDD are summarised in Table 12. A straightforward comparison between LST-LA and EDD for Carlier's benchmark problem shows that LST-LA outperforms EDD. For example, for the job size of 50 and difficulty level of 16, the average difference between LST-LA and EDD rules is 480.18 per cent.
6 CONCLUSION
Considering the NP-hardness of the 1|r/|Lmax scheduling problem, the heuristic algorithm called LST-LA was developed to obtain a better solution than the EDD algorithm. The algorithm was first tested on six different job size groups, which were 10, 30, 50, 80,100, and 150 jobs. These job size groups were generated randomly with defined parameters, as presented in Section 4, and the results were tested in SPSS. For each set, computational results show that LST-LA outperforms EDD and that the highest improvement over the EDD rule is obtained on the problems with 10 jobs.
In order to see the performance of the proposed LST-LA algorithm, it was also tested on randomly-generated Carlier's instances, as explained in Section 5.2. In these instances, LST-LA outperformed the EDD rule, even on the hard problems with difficulty levels of K= 18, 19, and 20.
The main contribution of the LST-LA algorithm is that it solves the 1|rJ,-1 Lmax problem as easily as the EDD rule, but with an improved solution performance. This proposed algorithm can be used easily in practice in a make-to-order environment that uses a single machine (e.g., plastic injection machine, moulding machine, or press machine). The proposed algorithm (LST-LA) can also be used to solve more complex scheduling problems, such as the shifting bottleneck algorithm, which iteratively solves a job shop scheduling problem by considering each machine as a single machine sub-problem.
For future work, we plan to use the LST-LA algorithm to boost the performance of the algorithms that solve a more complicated scheduling problem, by partitioning it to single machine sub-problems.
REFERENCES
[1] Chang, P.C. and Su, L.H. 2001. Scheduling n jobs on one machine to minimize the maximum lateness with a minimum number of tardy jobs. Computer and Industrial Engineering, 40(4), pp. 349-360. [ Links ]
[2] Graham, R.L., Lawler, E.L., Lenstra, J.K., and Rinnooy-Kan, A.H.G. 1979. Optimization and approximation in deterministic sequencing and scheduling: A survey. Annals of discrete mathematics, 5, pp. 287-326. [ Links ]
[3] Lenstra, J.K., Rinnooy, Kan, A.H.G. & Brucker, P. 1977. Complexity of machine scheduling problems. Annals of Discrete Mathematics, 1, pp. 343-362. [ Links ]
[4] Liu, L. and Zhou, H. 2012. Applying variable neighborhood search to the single-machine maximum lateness rescheduling problem, Electronic Notes in Discrete Mathematics, 39, pp. 107-114. [ Links ]
[5] Baker, K.R. and Magazine, M.J. 2000. Minimizing maximum lateness with job families. European Journal of Operational Research, 127(1), pp. 126-139. [ Links ]
[6] Sels, V. and Vanhoucke, M. 2011. A hybrid dual-population genetic algorithm for the single machine maximum lateness problem. Lecture Notes in Computer Science, 6622, pp. 14-25. [ Links ]
[7] Oyetunji, E.O. and Oluleye, A.E. 2008. Heuristics for minimizing the number of tardy jobs on a single machine with release time. South African Journal of Industrial Engineering, 19(2), pp.183-196. [ Links ]
[8] McMahon, G. and Florian, M. 1975. On scheduling with ready times and due dates to minimize maximum lateness. Operations Research, 23(3), pp. 475-482. [ Links ]
[9] Lageweg, B.J., Lenstra, J.K., and Rinnooy-Kan, A.H.G. 1976. Minimizing maximum lateness on one machine: Computational experience and some applications. Statistica Neerlandica, 30(1), pp. 25-41. [ Links ]
[10] Frederickson, G.N. 1983. Scheduling unit-time tasks with integer release times and deadlines. Information Processing Letters, 16(4), pp. 171-173. [ Links ]
[11] Baker, K.R., Lawler, E.L., Lenstra, J.K., and Rinnooy-Kan, A.H.G. 1983. Preemptive scheduling of a single machine to minimize maximum cost subject to release dates and precedence constraints. Operations Research, 31(2), pp. 381-386. [ Links ]
[12] Gordon, V.S. 1993. A note on optimal assignment of slack due-dates in single-machine scheduling. European Journal of Operational Research, 70(3), pp. 311-315. [ Links ]
[13] Oyetunji, E.O. and Oluleye, A.E. 2010. New heuristics for minimising total completion time and the number of tardy jobs criteria on a single machine with release time. South African Journal of Industrial Engineering, 21(2), pp. 101-113. [ Links ]
[14] Monma, C. and Potts, C. 1989. On the complexity of scheduling with batch setup times. Operations Research, 37(5), pp. 798-804. [ Links ]
[15] Schrage, L.E. 1971. Obtaining optimal solution to resource constrained network scheduling problems. Unpublished manuscript, 189. [ Links ]
[16] Carlier, J. 1982. The one-machine sequencing problem, European Journal of Operational Research, 11(1), pp.42-47. [ Links ]
[17] Pinedo, M. 2002. Scheduling theory algorithms and systems. 4th edition, Prentice Hall. [ Links ]
[18] Jackson, J.R. 1955. Scheduling a production line to minimize maximum tardiness. Research Report 43, Management Science Research Project, University of California, Los Angeles, CA. [ Links ]
[19] Potts, C.N. and Strusevich, V.A. 2009. Fifty years of scheduling: A survey of milestones. The Journal of the Operational Research Society, 60(5)(Supplement), pp. 41-68. [ Links ]
[20] Devore, J.L. 1995. Probability and statistics for engineering and sciences. 4th edition, Wadsword Inc. [ Links ]
* Corresponding author
1 The author was enrolled for an PhD degree in the Department of Industrial Engineering, Marmara University, Turkey
2 The author was enrolled for a BSc degree in the Department of Computer Engineering, Marmara University, Turkey
