










Serviços Personalizados
Artigo
 Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
Indicadores

Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkSouth African Computer Journal
versão On-line ISSN 2313-7835
versão impressa ISSN 1015-7999
SACJ vol.35 no.1 Grahamstown Jun. 2023
http://dx.doi.org/10.18489/sacj.v35i1.1219
VIEWPOINT
Developing an ontology-based system for semantic processing of scientific digital libraries
Kyrylo MalakhovI; Mykola PetrenkoI; Ellen CohnII
IMicroprocessor technology lab, Glushkov Institute of Cybernetics of the National Academy of Sciences of Ukraine, Kyiv, Ukraine. Email: Kyrylo Malakhov - malakhovks@nas.gov.ua (corresponding); Mykola Petrenko - petrng@ukr.net
IIDepartment of Communication and Rhetoric University of Pittsburgh, Pittsburgh, PA, USA. Email: ecohn@pitt.edu
ABSTRACT
The development of theories, methods, and algorithms for the discovery and formation of new knowledge remains one of the most important tasks for any researcher, especially if they are actively working to create new scientific publications. Yet, there is no universal language to describe full formal concepts (i.e. knowledge) or the systemology of transdisciplinary scientific research. Because of this, researchers face a set of urgent challenges. One such challenge is how to speed up the process of finding information in their own sources. To address this challenge, we created an ontology-related system for processing digital libraries of scientific publications. This system implements the technologies of information retrieval and knowledge discovery in digital libraries with an emphasis on technologies and instruments such as those used in the Semantic Web and cognitive graphics.
CATEGORIES: · Information systems ~ Information retrieval, Document representation, Ontologies
Keywords: Transdisciplinary research, Semantic Web, Ontology engineering, SPARQL, Digital library
1 INTRODUCTION
Many applications are available to search for information in different databases, and some are quite specialised. Most do not take into account the cognitive aspect of data processing that is needed for creative approaches, in particular for researchers.
A separate problem is the multimedia (conceptual and figurative) presentation of the search results, and their comparison with the conceptual structure of the subject area or knowledge domain. This interests us for the purposes of gaining new knowledge. For scientific research, it is relevant to process the scientific publications of one author, authors of a scientific unit, or of an institute by using the Semantic Web, known as Web 3.0 (W3C, 2023b), technology.
An ontology-related system (OrS) for processing digital libraries (i.e. databases or other types of digital repositories) of scientific publications (DLSP) uses technologies of information retrieval and knowledge discovery in databases with an emphasis on technologies and instruments of the Semantic Web and cognitive graphics (Palagin et al., 2014; V. Y. Velychko et al., 2014). This technology and corresponding instruments allow for the creation of multimedia presentations of conceptual and figurative structures, which are described in scientific papers. Semantic Web technologies allow for the creation and processing of the Resource Description Framework (RDF) (W3C, 2023a) repository of scientific publications, development of local and/or remote endpoints, and the assembling and execution of SPARQL-queries. Of the entirety of Semantic Web technologies, we need to highlight SPARQL-technology, which allows a researcher to create queries of arbitrary complexity and to receive a response that can include all kinds of information.
A generalised diagram for the development of OrS DLSP is shown in Figure 1, where SP denotes 'scientific publication'. It includes the preparation stage block and blocks of the main stage with variations A, B, and C. The preparation stage is described in detail in previous studies (Palagin et al., 2014; Palagin & Petrenko, 2020; Palagin et al., 2011) where ontology graphs of the subject area are provided. They serves as data for implementation of the main stage, variation B, phase 2 (B2).
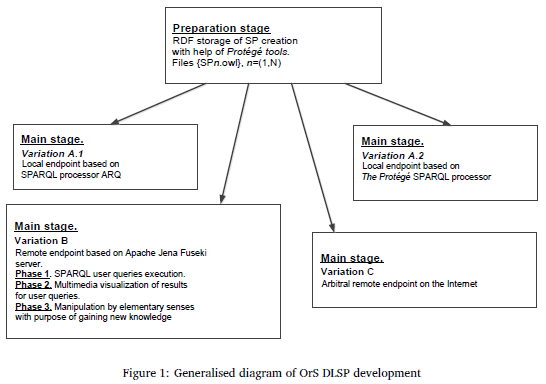
We can know about the personal knowledge database of a specific researcher, in which a sum of functional capabilities is declared. These capabilities support processes of scientific and creative activity. Such a personal knowledge database is:
• A tool that supports scientific research, and one of the central directions of practical informatics development (Palagin et al., 2017; Palagin et al., 2014; Palagin et al., 2020; Palagin, Velychko et al., 2018);
• A knowledge system development for researchers, for the purposes of new knowledge gain (or arrangement of existing knowledge, error checking and checking for contradictions, etc.) (Palagin, 2006, 2013; Palagin & Petrenko, 2018; V. Velychko et al., 2022);
• One of the main subsystems for the modern system of research design (Palagin, 2016; Palagin, Petrenko & Malakhov, 2018), and an automated workplace for researchers (Palagin et al., 2017; Palagin et al., 2020; Palagin, Velychko et al., 2018);
• One of the main elements for the creation of permanent canonical knowledge and support for knowledge-oriented information system functioning.
It is common knowledge that there is a tight connection between Semantic Web and Unified Modelling Language (UML) technologies. In particular, this is a connection between the Web Ontology Language (OWL) (W3C, 2022) syntax and the visual modelling of UML diagrams. UML is presented as a general-purpose language of visual modelling, which is developed for the specification, visualisation, designing, and documenting of software components, business processes, and other systems (Booch et al., 2005). UML is an easy and powerful tool for modelling, which can be used effectively for the creation of conceptual, logical, and graphical models of complex systems that are built for different purposes. This language absorbed all the best software engineering methods and qualities, and has been successfully used for many years to model large and complex systems (Booch et al., 2005; OMG, 2022).
Visual modelling in UML can be presented as a process of a gradual descent from the most general and abstract conceptual model of the source system to the logical, and later physical model of the corresponding software system. For this purpose, a model in a form of a use case diagram is built first. This diagram describes the functional purpose of the system, and what this system will perform in a process of its functioning. A use case diagram is a conceptual presentation, or a conceptual model of the system in the process of its design and development (Schmuller, 1999).
An OrS "database of scientific publications" is created for an author who is actively engaged in the preparation and production of new scientific publications. Of course, searching through one's own scientific publications can be done manually, which in most cases is how it is presently done. However, with the help of OrS, this search can be accelerated significantly. In addition, it is possible to automatically structure received data into appropriate templates for future scientific papers.
Now we will discuss the development of architectural, structural components, and UML diagrams. These diagrams show OrS functioning on the base of remote Apache Jena Fuseki (Apache.org, 2022a) endpoints. In addition, we will discuss examples of the formal description of scientific paper usage by performing a set of queries.
The goal of this article is OrS development. The system allows significant acceleration of information retrieval by an author (from his DLSP), provides a visual presentation of scientific publication concepts and respective subject areas, and implements the famous Brooks formula for acquiring new knowledge (Palagin, 2006; Palagin & Petrenko, 2018):
K (S) + dI = K (S + dS)
where K (S) denotes the source knowledge structure, which is modified by results of information processing of portion dl, creating new structure K (S + dS) with new knowledge portion dS. It is assumed that components dl and dS are closely tied with elementary senses - a simple two-syllable sentence with a direct object (Palagin & Petrenko, 2020).
The main stage of user task performance is split into three OrS architecture variations - A, B, and C. These variations have different functional power. A is the least powerful (organised as a local endpoint on the user's PC). B is of average power (organised as a remote endpoint based on an Apache Jena Fuseki server). C is the most powerful (organised as a remote endpoint, which is implemented with the help of original software). We can see that these variations of OrS realizations fit different purposes.
The A architecture scenario applies to one user in a local network with a knowledge engineer (KE is an expert in artificial intelligence language and knowledge representation who investigates a particular problem domain, determines important concepts, and creates correct, and efficient representations of the objects and relations in the domain). In this scenario, the user can form queries and receive answers only by working with one scientific publication at a time.
The B architecture scenario can be employed by a few users of the same scientific unit. When applying the B variation, it becomes possible to form one query for retrieval of structured information from multiple articles simultaneously, which is impossible to do with popular search systems.
The most powerful C architecture scenario can be used by users from an entire institute. The primary focus of this paper is to describe the processes with UML diagrams usage for variation B, phase 1 (B1).
2 ARCHITECTURAL AND STRUCTURAL ORGANISATION OF OrS DLSP (VARIATION B, PHASE 1)
For this variation, the OrS functions as a remote endpoint based on Apache Jena Fuseki (Apache.org, 2022a), and consists of three phases: phase 1 - SPARQL (Apache.org, 2022b) user queries processing; phase 2 - multimedia visualisation of user query results, or creation and usage of conceptual and figurative structures for the subject area; and phase 3 - manipulation by elementary senses with the purpose of gaining new knowledge.
In Figure 2 the B1 variation of the OrS is presented. Initially, the knowledge engineer downloads the relevant files and deploys Apache Jena Fuseki as a remote endpoint (DuCharme, 2013). The knowledge engineer then uploads scientific publications in the form of RDF graphs to the server; this data is generated in the preparation stage.
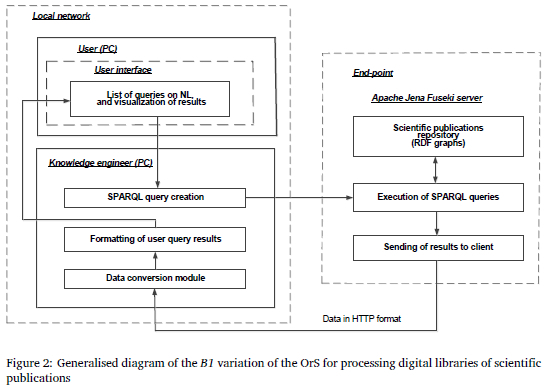
The user can see the list of possible queries in natural language in their user interface. The user can choose any query from this list, one-by-one. The chosen query is transferred via the network to a knowledge engineer module. The user systematically validates the information they are working with. Since it is possible to choose a subset of articles used for a search, this feature is useful if a researcher does not need to search in all databases.
2.1 Basic user queries
The researcher database contains N scientific papers published in popular scientific journals. Serial numbers of scientific publications (in this case we deal with articles) serve as arguments for queries and are numbered as follows:
m1,m2, . . . ,mk, . . . ,N−1,N
Data is organised in such a way that the author of a scientific publication is the first co-author of the publication, or in another case, the author is the one who owns the database. Below are examples of queries in natural language (NL).
1. Show titles of articles on the topic of "transdisciplinarity".
2. Show titles of articles on the topic of "ontological".
3. Show annotations of articles m1,m2,... ,mk
4. Show keywords of articles m1,m2,... ,mk,...
5. Show titles of all N articles:
5.1. in the order of publication date
5.2. without co-authors.
6. Show titles of articles m1,m2,... ,mk,..., where (query arguments are set by a user).
7. Show full names of co-authors for articles m1,m2,... ,mk,...
3 UML DIAGRAMS OF THE OrS FUNCTIONING FOR VARIATION B1
We now discuss UML diagrams, which reveal the core of OrS functions for variation B1 .
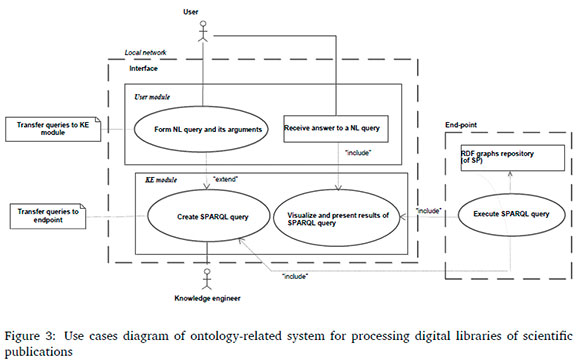
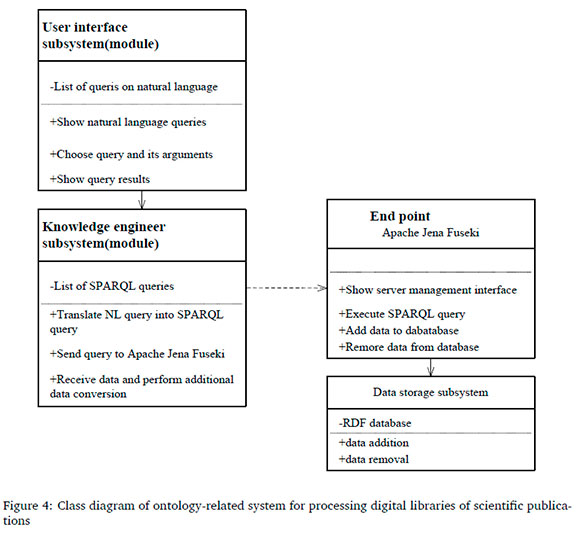
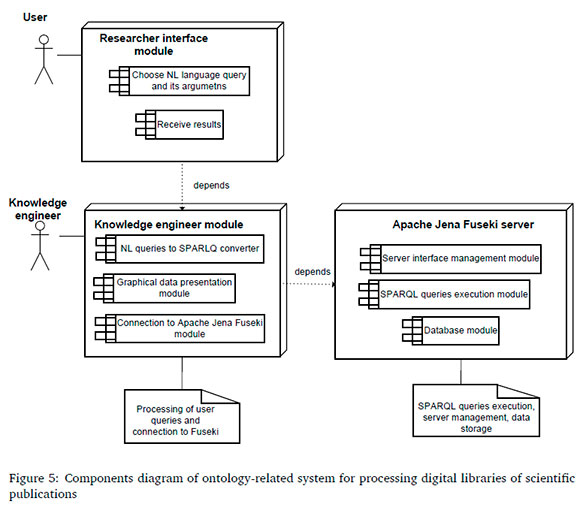
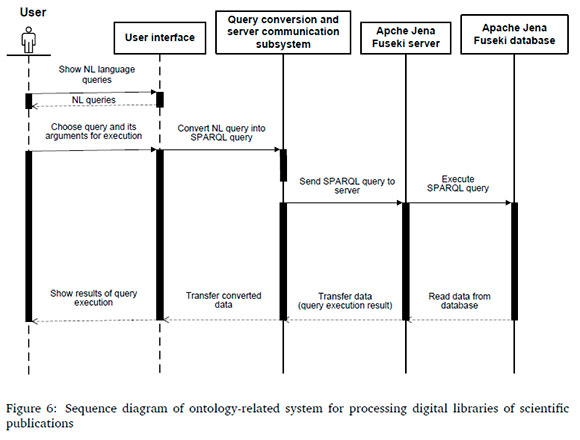
Figure 3 is a use case diagram; Figure 4 is a class diagram; Figure 5 is a components diagram, and Figure 6 is a sequence diagram (Figures are in Appendix A).
A discrete number of researchers are connected to a local network, which is administrated by a knowledge engineer. We will discuss the network operation for one user; the processes are organised in a similar fashion for other users.
For researchers, the PC functions as the module of the general interface. All the queries on NL are displayed in the interface, from which the researcher can choose one with desired arguments; a different element of the interface shows results of the query execution.
Another part of the system contains a module for the knowledge engineer. In this module, a SPARQL-query is formed out of the NL-query and transferred over HTTP protocol to the endpoint. On the Apache Jena Fuseki server, the SPARQL-query is executed and the response is sent via HTTP protocol to the knowledge engineer module and corresponding interface. The operation of forming and processing user queries, and receiving replies are shown in detail in the main UML diagrams in Figure 3 through Figure 6.
It is important to note that these diagrams do not show the process of argument selection and their transformation into article numbers in the database.
4 EXAMPLES OF SPARQL-QUERIES EXECUTION AND THEIR RESULTS
Below are some typical requests to the DLSP using the natural language requests and their corresponding representation in the form of SPARQL-queries. It is important to note that all NL and SPARQL queries are made to the digital library that contains articles in Russian and Ukrainian languages. The DLSP by Alexandr Palagin was taken as a basis for these examples. Requests to endpoints can be made either using the ARQ (Apache.org, 2022b) query engine or directly from the Fuseki user interface (which is shown in Figure 7). The Apache Jena Fuseki SPARQL server address is https://triplestorage.ai-service.ml/. Credentials for access can be provided on request.
Important note: The Jena Fuseki SPARQL server is in active development. For any technical clarifications and questions contact the first author via email. The recent Russian rocket shelling on critical infrastructure in Ukraine and Kyiv led to the shutdown of the https://triplestorage.ai-service.ml/ server.
5 CONCLUSION
The goal of our research was to develop an ontology-related system for processing digital libraries (i.e., databases or other kinds of digital repositories) of scientific publications, which will allow researchers to significantly increase the retrieval speed of required information (in the form of cognitive structures) from their sources.
This article introduced and described the architectural and structural organisation of OrS, which includes the local network with PCs of user and administrator/knowledge engineer, and remote endpoints based on the Apache Jena Fuseki server. This was shown via core UML diagrams of OrS functioning and examples of user query execution.
6 FURTHER RESEARCH
This research is far from its end goal. As we explained, it is necessary to implement phases 2 and 3, and for that we need to develop algorithms of creation for conceptual and figurative structures; algorithms of their comparison; an analysis with the further intention of building subject area knowledge; and algorithms for the discovery of new knowledge following the Brooks formula.
In a future study, our team plans to implement the ontology-related system as a part of the knowledge-oriented digital library of the smart-system for remote support of rehabilitation activities and services (Chaikovsky et al., 2023; Malakhov, 2022, 2023; Malakhov et al., 2022; Palagin et al., 2022). Further research will aim to develop original instruments and tools with the purpose of optimising user queries, and optimising usability for ontology-related systems.
CREDIT AUTHORSHIP CONTRIBUTION STATEMENT
Mykola Petrenko: Supervision, Conceptualization, Methodology, Writing - original draft, Validation. Kyrylo Malakhov: Software, Validation, Resources, Term, Writing - review and editing. Ellen Cohn: Writing - review and editing.
ACKNOWLEDGEMENTS
Corresponding author Kyrylo Malakhov, on behalf of himself and co-author Mykola Petrenko, thanks Ellen Cohn (PhD, CCC-SLP, ASHA-F, Department of Communication, University of Pittsburgh, PA, USA) who assisted in the review and editing of the article, and international support to preserve Ukrainian science in wartime and to scale up international scientific cooperation.
The research team of the Glushkov Institute of Cybernetics would like to give special recognition to Katherine Malan, Editor-in-Chief of the South African Computer Journal. We greatly appreciate her efforts in promoting Ukrainian science through the dissemination of research works in scholarly publications.
FUNDING
This study would not have been possible without the financial support of the National Research Foundation of Ukraine. Our work was funded by Grant contracts:
• Transdisciplinary intelligent information and analytical system for the rehabilitation processes support in a pandemic (TISP), application ID: 2020.01/0245 (2020-2021, project was successfully completed).
• Development of the cloud-based platform for patient-centered telerehabilitation of oncology patients with mathematical-related modelling, application ID: 2021.01/0136.
DECLARATION OF COMPETING INTEREST
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
Apache.org. (2022a). Apache Jena - Apache Jena Fuseki. Retrieved August 30, 2022, from https://jena.apache.org/documentation/fuseki2/
Apache.org. (2022b). Apache Jena - ARQ - A SPARQL Processor for Jena. Retrieved August 30, 2022, from https://jena.apache.org/documentation/query/
Booch, G., Rumbaugh, J., & Jacobson, I. (2005). Unified Modeling Language User Guide, The (2nd Edition) (Addison-Wesley Object Technology Series). Addison-Wesley Professional.
Chaikovsky, I., Dykhanovskyi, V., Malakhov, K. S., & Bocharov, M. (2023). Military medicine: Methods of control, improvement in individual combat readiness and telerehabilitation of military personnel. Iowa State University Digital Press. https://doi.org.10.31274/isudp.2023.128
DuCharme, B. (2013). Learning SPARQL: Querying and updating with SPARQL 1.1 (2nd ed.). O'Reilly Media. http://learningsparql.com/
Malakhov, K. S. (2022). Update from Ukraine: Rehabilitation and Research [Letter to the Editor]. InternattionalJournal of Telerehabilitation, 14(2), 1-2. https://doi.org/10.5195/ijt.2022.6535 [ Links ]
Malakhov, K. S. (2023). Update from Ukraine: Development of the cloud-based platform for patient-centered telerehabilitation of oncology patients with mathematical-related modeling [Letter to the Editor]. International Journal of Telerehabilitation, 15(1), 1-3. https://doi.org/10.5195/ijt.2023.6562 [ Links ]
Malakhov, K. S., Velychko, V., Palagin, O. V., & Prykhodniuk, V. (2022). A Guide to TISP: Hospital Information System for Rehabilitation. Iowa State University Digital Press. https://doi.org/10.31274/isudp.2022.126
OMG. (2022). About the Unified Modeling Language Specification Version 2.5.1. Retrieved August 30, 2022, from https://www.omg.org/spec/UML/2.5.1/
Palagin, O. V. (2006). Architecture of ontology-controlled computer systems. Cybernetics and Systems Analysis, 42(2), 254-264. https://doi.org/10.1007/s10559-006-0061-z [ Links ]
Palagin, O. V. (2013). Transdisciplinarity Problems and the Role of Informatics. Cybernetics and Systems Analysis, 49(5), 643-651. https://doi.org/10.1007/s10559-013-9551-y [ Links ]
Palagin, O. V. (2016). An Introduction to the Class of the Transdisciplinary Ontology-controled Research Design Systems. Control Systems and Computers, 266(6), 3-11. https://doi.org/10.15407/usim.2016.06.003 [ Links ]
Palagin, O. V., Malahov, K., Velychko, V., & Shchurov, O. (2017). Designing and program implementation of the subsystem for creation and use of the ontological knowledge base of the scientific employee publications. Problems in Programming, (2), 72-81. https://doi.org/10.15407/pp2017.02.072 [ Links ]
Palagin, O. V., Malakhov, K. S., Velychko, V. Y., & Semykopna, T. V. (2022). Hybrid e-rehabilitation services: SMART-system for remote support of rehabilitation activities and services. International Journal of Telerehabilitation, Special Issue: Research Status Report -Ukraine. https://doi.org/10.5195/ijt.2022.6480
Palagin, O. V., Petrenko, M., Velychko, V., & Malakhov, K. S. (2014). Development of formal models, algorithms, procedures, engineering and functioning of the software system "Instrumental complex for ontological engineering purpose". CEUR Workshop Proceedings, 1843, 221-232. https://ceur-ws.org/Vol-1843/221-232.pdf [ Links ]
Palagin, O. V., & Petrenko, M. G. (2020). Knowledge-Oriented Tool Complex Processing Databases of Scientific Publications. Control Systems and Computers, 289(5), 17-33. https://doi.org/10.15407/csc.2020.05.017 [ Links ]
Palagin, O. V., Petrenko, M. G., & Malakhov, K. S. (2018). Information technology and integrated tools for support of the smart systems research design. Control Systems and Computers, 274(2), 19-30. https://doi.org/10.15407/usim.2018.02.019 [ Links ]
Palagin, O. V., Petrenko, M. G., Velychko, V. Y., & Malakhov, O., Kyrylo S.and Karun. (2011). Principles of design and software development models of ontological-driven computer systems. Problems of Informatization and Management, 2(34), 96-101. https://doi.org/10.18372/2073-4751.2.9214 [ Links ]
Palagin, O. V., & Petrenko, N. G. (2018). Methodological Foundations for Development, Formation and IT-support of Transdisciplinary Research. Journal of Automation and Information Sciences, 50(10), 1-17. https://doi.org/10.1615/JAutomatInfScien.v50.i10.10 [ Links ]
Palagin, O. V., Velychko, V. Y., & Malakhov, O. S., Kyrylo S.and Shchurov. (2020). Distributional semantic modeling: A revised technique to train term/word vector space models applying the ontology-related approach. Problems in Programming, (2-3), 341-351. https://doi.org/10.15407/pp2020.02-03.341 [ Links ]
Palagin, O. V., Velychko, V., & Malakhov, O., Kyrylo S. Shchurov. (2018). Research and development workstation environment: The new class of current research information systems. Problems in Programming, (2-3), 255-269. https://doi.org/10.15407/pp2018.02.255 [ Links ]
Schmuller, J. (1999). SAMS teach yourself UML in 24 hours. O'Reilly. https://www.oreilly.com/library/view/sams-teach-yourself/067232640X/
Velychko, V. Y., Malahov, K., Semenkov, V., & Stryzhak, O. (2014). Integrated tools for engineering ontologies. International Journal Information Models & Analyses, 3(4), 336-361. http://www.foibg.com/ijima/vol03/ijima03-04-p03.pdf [ Links ]
Velychko, V., Voinova, S., Granyak, V., Ivanova, L., Kudriashova, A., Kunup, T., Malakhov, K., Pikh, I., Punchenko, N., Senkivskyy, V., Sergeeva, O., Sokolova, O., Fedosov, S., Khoshaba, O., Tsyra, O., Chaplinskyy, Y., Gurskiy, O., Zavertailo, K., & Kotlyk, D. (2022). New information technologies, simulation and automation (S. Kotlyk, Ed.). Iowa State University Digital Press. https://doi.org/10.31274/isudp.2022.121
W3C. (2022). OWL - Semantic Web Standards. Retrieved August 30, 2022, from https://www.w3.org/OWL/
W3C. (2023a). RDF - Semantic Web Standards. Retrieved August 30, 2022, from https://www.w3.org/RDF/
W3C. (2023b). Semantic Web - W3C. Retrieved August 30, 2022, from https://www.w3.org/standards/semanticweb/
Received: 1 March 2023
Available online: 31 July 2023
A APPENDIX



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}