










Services on Demand
Article
 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
Indicators

Related links
-
 Cited by Google
Cited by Google -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkSouth African Computer Journal
On-line version ISSN 2313-7835
Print version ISSN 1015-7999
SACJ vol.29 n.1 Grahamstown Jul. 2017
http://dx.doi.org/10.18489/saej.v29i1.436
RESEARCH ARTICLE
Feature-fusion guidelines for image-based multi-modal biometric fusion
Dane BrownI; Karen BradshawII
IDepartment of Computer Science, Rhodes University, Grahamstown, South Africa. p.dane49@gmail.com
IIDepartment of Computer Science, Rhodes University, Grahamstown, South Africa. k.bradshaw@ru.ac.za
ABSTRACT
The feature level, unlike the match score level, lacks multi-modal fusion guidelines. This work demonstrates a new approach for improved image-based biometric feature-fusion. The approach extracts and combines the face, fingerprint and palmprint at the feature level for improved human identification accuracy. Feature-fusion guidelines, proposed in our recent work, are extended by adding a new face segmentation method and the support vector machine classifier. The new face segmentation method improves the face identification equal error rate (EER) by 10%. The support vector machine classifier combined with the new feature selection approach, proposed in our recent work, outperforms other classifiers when using a single training sample. Feature-fusion guidelines take the form of strengths and weaknesses as observed in the applied feature processing modules during preliminary experiments. The guidelines are used to implement an effective biometric fusion system at the feature level, using a novel feature-fusion methodology, reducing the EER of two groups of three datasets namely: SDUMLA face, SDUMLA fingerprint and IITD palmprint; MUCT Face, MCYT Fingerprint and CASIA Palmprint.
Keywords: multi-modal biometrics, feature-level fusion, guidelines, face, fingerprint, palmprint
1 INTRODUCTION
Biometric systems often have to contend with degraded quality of the data being modelled as well as inconsistencies in data acquisition. Additionally, their widespread use has increased the risk of identity theft by forgers (Kaur & Kaur, 2013). In parallel to these developments, fusing multiple sources of biometric information has been shown to improve the recognition accuracy, security and robustness of a biometric system (Iloanusi, 2014).
Initially, development of multi-modal biometrics focused on fusing at the matching score level. Recently, biometric fusion at the feature level has been studied and shown to outperform the matching score level (Rattani, Kisku, Bicego, & Tistarelli, 2011). Feature-level fusion integrates feature sets corresponding to two or more biometric modalities. The widely used matching score-level fusion does not utilise the rich discriminatory information available at the feature level. Comprehensive studies have been conducted at the matching score level across most biometric modalities. These studies often compare the best fusion methods, forming fusion guidelines that can be used in future applications of a similar nature (Raghavendra, Dorizzi, Rao, & Kumar, 2011; Ribaric & Fratric, 2006). An example is the use of min-max normalization to achieve a low false acceptance rate (FAR) and Bayes-based normalization to achieve a low false rejection rate (FRR), in general. Additionally, the weighted sum rule is preferred for general fusion and the product rule is preferred for very high quality input data fusion. Feature-level fusion, on the other hand, is not only more complex, but also lacks guidelines, as it is a lesser studied problem. The general guideline for feature-level fusion is the use of uncorrelated feature sets among different modalities before fusion (Wang, Liu, Shi, & Ding, 2013). The opposite holds true when fusing multiple samples of the same modality.
It is unclear from the literature whether fusing the face, fingerprint and palmprint at the feature level before or after feature transformation is an important factor. However, it is often performed after transforming the feature space using linear or non-linear methods (Deshmukh, Pawar, & Joshi, 2013; Rattani et al., 2011; Yao, Jing, & Wong, 2007). In either case, transforming features to lower the dimensionality is an important factor in biometric feature-fusion. Additional factors include the size, quality and number of training samples used for effective data modelling of the dataset. Hence, determining an appropriate feature selection and transformation scheme is key when combining information at the feature level (Kaur & Kaur, 2013; Raghavendra et al., 2011). Raghavendra et al. (2011) also state that applying very similar feature selection and transformation to different modalities can yield a very efficient multi-modal biometric system. Biometric modalities are thus independent yet complementary.
The face, fingerprint and palmprint biometrics are combined at the feature level and the above factors will be investigated. The resulting combinations of feature processing modules are expected to produce an improved recognition performance compared with the individual modalities. Moreover, the interactions of the resulting combinations are expected to serve as guidelines for face, fingerprint and palmprint feature-fusion and other image-based multi-modal systems. Therefore, these guidelines are first determined based on comparisons with related studies using multiple datasets. There are limited studies that fuse the face, fingerprint and palmprint at the feature level for human identification. The proposed fusion methodology makes use of the guidelines to construct accurate multi-modal biometric human identification systems while correlating the performance to the number of training samples required.
This paper extends our SAICSIT 2016 paper (Brown & Bradshaw, 2016b) with additions to the feature-fusion guidelines and experiments section. Furthermore, a new face segmentation method is proposed and tested on multi-modal biometric fusion at the feature level for the first time.
The rest of the paper is organised as follows: Section 2 presents the related studies found in the literature. Section 3 discusses the different modules used at all image processing stages in this paper. Section 4 discusses the implemented face, fingerprint and palmprint fusion methodology. The experimental analysis and results are discussed in Section 5. In Section 6, conclusions are given and ongoing research is outlined.
2 RELATED STUDIES
Eskandari and Toygar (2015) designed a robust fusion scheme for the face and iris at the featurelevel. They emphasise that feature alignment plays a pivotal role during the pre-processing step. A comprehensive set of experiments show the effect alignment has on recognition accuracy relative to the biometric data. The face is segmented and aligned using the detected eye position as reference. The segmented iris is rotated for alignment based on texture patterns. Furthermore, their system is made robust to noise by applying a backtracking search algorithm.
The CASIA-Iris-Distance dataset, containing close-up near-infrared face images, was used for testing the importance of feature alignment. The iris benefited significantly from alignment with a 44% improvement to verification accuracy. Aligning the face improved verification accuracy by 7%.
Rattani et al. (2011) produced a multi-modal biometric system by fusing face, fingerprint and palmprint images. They showed that good dimension reduction and normalization algorithms allow feature-level fusion to produce a lower equal error rate (EER) than matching score-level fusion. Their feature-level fusion approach emphasises the extraction of image regions of both modalities.
The study concluded that fusing information from uncorrelated traits such as the face, fingerprint and palmprint at the feature-level increases human identification accuracy. Significantly better FAR and FRR (and ERR) were achieved at the feature level compared to the matching score level. Other face, fingerprint and palmprint studies include (Karki & Selvi, 2013) and (Sharma & Kaur, 2013), which both use a Curvelet transform followed by support vector machine (SVM) classification. However, these studies were tested using datasets that are not publicly available.
Yao et al. (2007) proposed an accurate multi-modal biometric system that fused the face and palmprint Four Eigen-based face and palmprint feature-fusion algorithms were compared. The proposed method filters the EigenFaces and EigenPalms with a Gabor filter followed by the weighted concatenation of the resulting feature vectors.
The AR Face dataset was organised into a face dataset, with a resolution of 60 χ 60, and limited to the first 20 images per 119 individuals. Images in the palmprint dataset, provided by Hong Kong Polytechnic University, were matched to those used in the face dataset with the same number of samples per individuals. The proposed fusion method obtained its highest accuracy of 95% with six training samples, but reached 91% with only one training sample. Ahmad, Woo, and Dlay (2010) proposed a similar system tested on ORL Face and Poly-U palmprint datasets. The resulting accuracy was a 99.5% genuine acceptance rate (GAR), with an unspecified FAR. The near-perfect accuracy is attributed to the use of the relatively small-scale ORL Face dataset, limiting the fused dataset to 40 individuals and 10 samples per individual.
Multi-modal biometric fusion at the feature level achieve similar accuracies in the literature and often use a similar algorithm such as Eigen, Fisher or a frequency domain approach. Baseline systems are constructed based on the best respective face, fingerprint and palmprint studies that perform feature-level fusion.
Comparing face, fingerprint and palmprint feature-fusion systems under identical conditions is a non-trivial task for the following reasons:
1. Availability of multi-modal biometric datasets is relatively low.
2. Private uni-modal datasets are used extensively in the literature.
3. Some feature-fusion systems perform human verification only.
4. The lack of EER, FAR and FRR metrics in most related studies limits a direct comparison to only system accuracy.
In the preliminary experiments in Section 4.1, we reimplement Ahmad et al. (2010)'s algorithm and compare it with various combinations of feature processing modules. These combinations consist of feature selection, transformation and classification algorithms that constitute our proposed systems.
3 FEATURE PROCESSING MODULES
This section discusses the relevance of various feature processing modules used in the preliminary and proposed multi-modal biometric systems.
3.1 Feature Selection
Feature selection is used to choose or find appropriate features to allow a certain objective function to be optimised. The objective function typically aims to reduce the feature space by removing unwanted features, while retaining features that are highly representative of the underlying image class (Bovik, 2010). The entire image can be considered and contained within the results. However, based on the biometric, specific regions contain less noise and more discriminatory information. Considering the entire image during fusion, rather than core regions, can lead to the phenomenon known as "the curse of dimensionality problem" (Raghavendra et al., 2011). These regions are typically centred around the core for alignment during image registration.
In the case of fingerprints the texture pattern is known to contain richer information than singular points and minutiae (Maltoni, Maio, Jain, & Prabhakar, 2009). The texture patterns consist of ridges and valleys on the surface of the finger and are known as global features. The local features are points on the fingerprint known as minutiae and singular points. Global features can be extracted for use in biometric fusion at the feature level, while local features can be used to help align the global features. These features can also be extracted from palmprints as they share many characteristics of the fingerprint.
Facial texture patterns consist of global contour and pore features in higher resolution data. Local features, known as facial landmarks, consist of the eyes, nose and mouth. These landmarks can be used to align global features in a similar way to fingerprints and palmprints.
Texture patterns can be classified to evaluate the recognition performance of biometrics. Numerous texture classification methods can be used, such as Eigen, Fisher and Local Binary Pattern Histograms (LBPH). Performing a comparison on these texture classification methods can form the basis for finding optimal feature selection and transformation schemes to classify different biometric modalities.
Global and local features often require algorithms to improve their clarity and consistency over multiple samples. This is particularly the case with contours and pores in face images, principal lines in palmprint images, and ridges and valleys in fingerprint images (Porwik & Wrobel, 2005). The biometric recognition process is often initiated by aligning the input image before other feature selection techniques are performed for improved feature discrimination (Bovik, 2010; Feng & Jain, 2011; Peralta, Triguero, Sanchez-Reillo, Herrera, & Benitez, 2014; Zou, Feng, Zhang, & Ding, 2013).
3.2 Automated Image Registration
Image registration is an important first step in biometric recognition. At the local level, there are unique points within biometric data depending on the considered biometric modality. These points are determined for automated image registration based on the modality.
The fingerprint contains such points, located on ridge curvatures, that are either unique or sharper than those in other areas. The core point, also known as the reference point, is often defined as the sharpest concave ridge curvature based on the orientation field of the fingerprint image (Jain, Prabhakar, Hong, & Pankanti, 2000). This point is especially useful as it serves as a guide during image registration, which is important for normalising features. The core point is used to allocate a region of interest (ROI), which minimises the discrepancy of stretch and alignment differences among multiple fingerprint samples of the same finger. Many previous approaches to reference point determination critically rely on the local features such as Poincaré index or other properties of the orientation field (Jain et al., 2000). Poincaré works well in good quality fingerprint images, but fails to correctly localise reference points in poor quality fingerprints such as partials or fingerprints with poor ridge and valley contrast. The solution used in this paper applies an edge preserving non-local means (NL-means) filter (Buades, Coll, & Morel, 2005) and a 9 χ 9 inverted Gaussian filter before applying Poincaré. The fingerprint is aligned using the closest two minutiae - ridge endings or bifurcations - and the core point for a shear transformation.
The sise of the fingerprint ROI is determined by cropping two thirds of the boundaries of the fingerprint. Fingerprint registration is illustrated in Figure 1. Partial fingerprints are considerably less trival to segment and are dealt with using the LBPH texture classifier, explained later. An example of a partial is shown in Figure 2.

A ROI can also be determined for facial images. The key points are the eyes, nose and mouth, which are used during facial image registration. These points are used to create a border around the face, centred at the nose, which helps to avoid typical changes to the face such as different hair, occluded ears and neck. A large number of Haar-like features are organised to create a classifier cascade. Haar cascading is a popular method for detecting features that are used as key points. Multiple Haar cascades are iterated when the selected one fails to detect a key point. This method is often employed in feature-level literature for cropping frontal faces.
This method works well for frontal faces with viewing angles close to zero degrees. In Figure 3, a near-ideal frontal face is cropped.
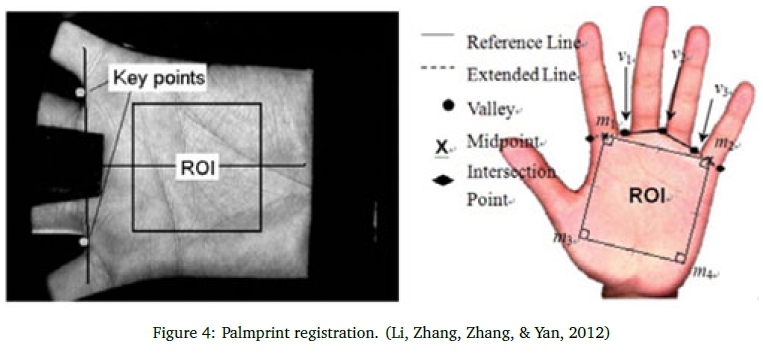
The ROI for palmprint images is determined by extracting the principal lines and applying the iterative closest point method, which estimates the translation and rotation parameters between the input and test image by minimising the distance between the two sets of correspondence points (Li, Zhang, Zhang, & Yan, 2012). This method ensures that the key points between the index (m1) and little fingers (m2), used as a boundary for the ROI, correspond between the two images. The ROI for palmprint images are often consistent. On the other hand, the texture distorts when the fingers are not fully spread.
Fingerprint registration is illustrated in Figure 4.
The face, fingerprint and palmprint image registration methods each use a fall-back mechanism in case their respective key point detectors fail for a fully automatic multi-modal biometric system. This is determined based on the confidence score of the LBPH texture classifier.
3.3 Feature Normalization and Discrimination
The following three feature selection algorithms are particularly useful at reducing the differences among multiple same-class data or improving the discrimination among different classes of data.
3.3.1 Pixel Normalization
The pixel values of an image or certain image regions are set to a constant mean and variance to compensate for slight inconsistencies in lighting and contrast. This is essential for normalising image biometric data.
3.3.2 Histogram Equalization
Histogram equalization is an effective way of automatically setting the illumination across a dataset as a consistent amount (Bovik, 2010). The greyscale range is distributed uniformly by applying a non-linear transformation with a slight side effect on the histogram shape. Histogram equalization is often more effective than pixel normalization, but should be avoided in most histogram-based matching methods. Both pixel normalization and histogram equalization improve the consistency among multiple data samples.
3.3.3 Frequency Filtering
The quality of the input image plays an important role in the performance of the feature extraction and matching algorithm (Chikkerur, Cartwright, & Govindaraju, 2007). A bandpass filter can be used to increase the amplitude of the mean component of the image. This has the effect of increasing the dominant spectral components while attenuating the weak components.
The Gabor filter is often used to filter frequencies based on the texture of the face, fingerprint and palmprint. It is constructed using a special short-time Fourier transform by modulating a two-dimensional sine wave at a particular frequency and orientation with a Gaussian envelope. A Gabor filter requires much tuning for specific orientations and frequencies to isolate the undesired noise while preserving the structure of a particular biometric (Budhi, Adipranata, & Hartono, 2010).
The Laplacian of Gaussian (LoG) filter can remove unwanted features on the high frequency spectrum before enhancing the remaining features, effectively increasing the DC component. However, a side effect can occur when applying the filter to badly aligned images. This side effect is also prevalent in images with inconsistent lighting. The increased feature discrimination of LoG further highlights the difference among multiple samples, leading to bad training and testing sets and consequently a lower recognition accuracy. The image registration procedure, in Subsection 3.2, as well as lighting normalization is thus imperative to the success of an image-based feature-fusion biometric system.
3.4 Feature Transformation for Reduction and Classification
Image classification algorithms aim to express the most relevant image properties. Feature transformation is used to express a feature vector in an alternate space to improve discrimination. This often allows for a reduction in dimensionality and intra-class variation - multiple samples contain near-identical information. The implementations of the image texture classification methods considered are more biased to the overfitting than underfitting of data.
3.4.1 Eigen
Statistical classifiers can be used to maximise inter-class variation to discriminate effectively between different individuals.
The Eigen classifier uses Principal Component Analysis (PCA) to represent statistically key features that define a given feature set. An efficient model can be constructed from principal components, retaining key features of samples in one class. The distances among Eigenvalues are compared between the trained model and the model to be tested during matching.
Given N sample images x, the total scatter matrix is defined as (Belhumeur, Hespanha, & Kriegman, 1997):

where 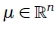 is the mean image obtained from the samples.
is the mean image obtained from the samples.
3.4.2 Fisher
PCA is a powerful technique to maximise total scatter of data and lower the dimensionality of a dataset, but it does not effectively consider the rest of the classes within a particular class. This can lead to a loss of some discriminative information, on an inter-class level. On the other hand, Linear Discriminant Analysis (LDA) performs extra class-specific dimensionality reduction and is referred to as the Fisher classifier. Fisher classification clusters same class data tightly and maximises the separation of different classes in a lower-dimensional representation.
Given C classes the between-class scatter matrix is defined as (Belhumeur et al., 1997):
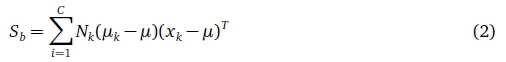
and the within-class scatter matrix is defined as:
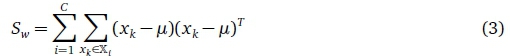
The dimensionality is lower than the Eigen method as C -1 is the maximum number of non-zero generalised Eigenvalues.
The Fisher classifier learns a highly discriminative class-specific transformation matrix, but inconsistent data within classes, caused by, for example, varying illumination, has a greater negative impact on class separation performance compared with the Eigen method. The Fisher method is more likely to underfit data than the Eigen method. However, the reduced dimensionality that LDA offers allows for the Fisher method to have a lower training and a substantially lower testing time compared with the Eigen method. This is especially prevalent when using larger datasets.
3.4.3 Support Veetor Maehines
The SVM is a supervised statistical learning model that has been used extensively in pattern recognition problems (Brown, 2013). Its advantage over many other classifiers is that the training time is almost unaffected by the high dimensionality of feature vectors from images. SVMs were originally used to solve binary class problems, but are easily extended to support multi-class problems. In a binary class problem, SVMs aim to maximise a mathematical function given a collection of data points that consist of two classes that can be separated by a decision boundary.
Consider that the two classes S+ = {x¡ | y¡ = 1} and S- = {x¡ | y¡ = -1} are linearly separable (Brown, 2013). This results in at least one boundary that can be formed between them. The data points of sets S + and S- that are located on the boundaries of the margin are known as the support vectors. A simple rescale of w for all x¡ that are support vectors holds that:

The distance d between the decision boundary and the margin can be expressed as:

In higher-dimensional space, the decision boundary that achieves the maximum margin between sets S+and S-is known as the optimal hyperplane, which allows an SVM to model new data points more accurately.
3.4.4 Spatially Enhaneed Histogram Matehing
Regular histogram matching is one of the simplest image matching methods. LBPH is another texture feature descriptor for images. A basic local binary pattern operator assigns a label to every pixel of an image by thresholding the 3 χ 3 pixel neighbourhood, consisting of a centre pixel value that is compared to its neighbours, resulting in a binary representation of the neighbourhood. The comparison transforms the neighbour pixel to a 1 if it is larger than the centre pixel and a 0 if it is smaller than the centre pixel. The transformed neighbourhoods are uniform such that the histogram has a separate bin for every pattern neighbourhood. The result is a concatenated histogram consisting of all the neighbourhoods.
In this paper a special kind of LBP operator called extended LBP (ELBP) is used. Instead of being limited to directly adjacent neighbours, the neighbourhood is extended to include interpolated pixels, based on a circular mask, that capture fine texture. This operator uses spatially enhanced histogram matching that enables partial matching and automatic pixel normalization on a pixel level, circular neighbourhood level and image level. This results in the distinct advantage of illumination, scale and rotation invariant texture classification compared with Eigen and Fisher (Ahonen, Hadid, & Pietikainen, 2006).
Training the advanced histogram model is also significantly faster than the former two methods. Furthermore, the training time is independent of the image resolution and it produces the smallest model size. However, testing time is significantly higher than Eigen and Fisher and is directly proportional to the number of circular neighbourhoods. Given m circular neighbourhoods, their corresponding spatially enhanced histograms are determined, with a sise of m χ n, where n is the length of a single histogram.
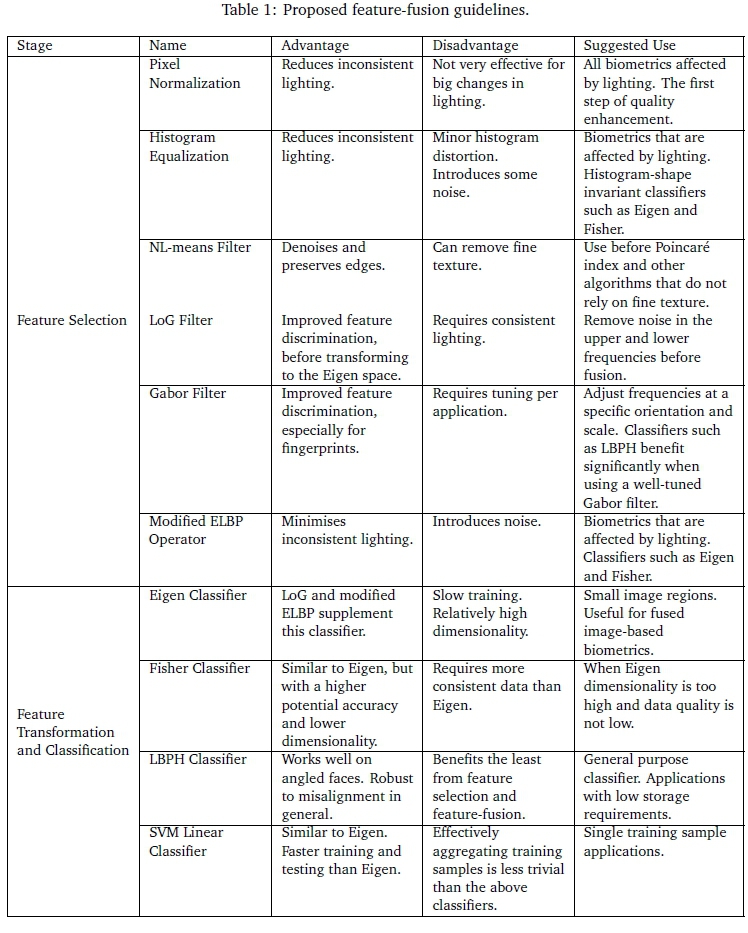
4 FEATURE-FUSION GUIDELINES
This section discusses the development and use of guidelines for biometric feature-fusion by utilising the feature processing modules discussed in the previous section.
4.1 Preliminary Experiments for Developing the Guidelines
Feature-fusion guidelines determined in this subsection are limited to the feature processing modules discussed in Section 3. The datasets that were used in the preliminary experiments are also discussed. The guidelines were determined by analyzing the results of the following preliminary experiments.
Fingerprint and face pseudo multi-modal datasets were formed by pairing SDUMLA Fingerprint right index fingers (Yin, Liu, & Sun, 2011) with ORL Face (Samaria & Harter, 1994), limiting the individuals to 40. Palmprint and face and palmprint and fingerprint pseudo multi-modal datasets were similarly formed, by pairing Poly-U palmprints (Zhang, Kong, You, & Wong, 2003) with the above face and fingerprint datasets, respectively. The interactions of the feature processing modules were investigated by conducting preliminary experiments on the organised pseudo multi-modal datasets, summarised in Table 1.
The SDUMLA fingerprint dataset consists of fingerprint images that vary in quality, from partials with absent core points to fingerprints with average quality ridges. The ORL Face dataset is of average quality with images captured from various angles. Poly-U palmprints consists of very high quality images, captured in a controlled environment with hand restricting user-pegs.
Ahmad et al. (2010)'s best method, as reimplemented in this paper, was compared with preliminary systems that exhausted the combinations of feature processing modules discussed in Section 3. The face and fingerprint achieved their best EERs at 8% and 6%, respectively. Their system was extended to include a fingerprint version - aligned using the automated approach described in 3.2. Using one training sample, their system achieved an EER of 26.71% when fusing the face and fingerprint, 11.77% when fusing the palmprint and fingerprint, and 7.33% when fusing the palmprint and face, using five training samples. Their system achieved an EER of 6.5% when fusing the face and fingerprint, 1.77% when fusing the palmprint and fingerprint, and 0.77% when fusing the palmprint and face. Their reimplemented system was verified to be a true representation of the original system. Moreover, both the original and the reimplemented systems achieved a 99.5% system accuracy for palmprint and face fusion using the same dataset.
The next set of experiments were performed on our proposed systems. Preliminary test results showed LBPH to be the best performing classifier when no feature discrimination algorithms were used. LBPH achieved an EER of 19.64% when fusing the face and fingerprint, using one training sample. Moreover, it achieved an EER of 0% when fusing the face and fingerprint, using five training samples. This is attributed to its robustness to bad alignment and lighting even with a bad training set. On the other hand, Eigen and Fisher classifiers performed poorly with EERs higher than 31% for one training sample in both cases. Eigen and Fisher achieved a 7.5% EER and 6.67% EER, respectively using five training samples. However, by adding the feature selection algorithms discussed in Section 3.3, which significantly improved discrimination, the accuracy of Eigen and Fisher increased, although there was little improvement for LBPH. Upon individual observation, the LoG filter caused inconsistent improvements across test subjects.
Both palmprint combinations achieved 0% EER when using histogram equalization. Additionally, the ORL Face and Poly-U palmprint dataset were tested on their own using histogram equalization and both achieved 5% EER, when using five training samples.
The best performing preliminary system used histogram equalization followed by LoG and the Eigen or Fisher classifier. Furthermore, feature-fusion, by column concatenation of images, after feature selection and before feature transformation was found to be most effective and outperformed the feature averaging method. The resulting EERs, when using a single training sample, were 14.67% and 16.89% for Eigen and Fisher, respectively. Both Eigen and Fisher achieved 0% EERs when using five training samples. Furthermore, Eigen and Fisher always achieved 0% EER when fusing the palmprint with either the face or the fingerprint, regardless of the number of training samples. The results also confirmed Raghavendra et al. (2011)'s assertion - the same feature transformation should be applied to different modalities.
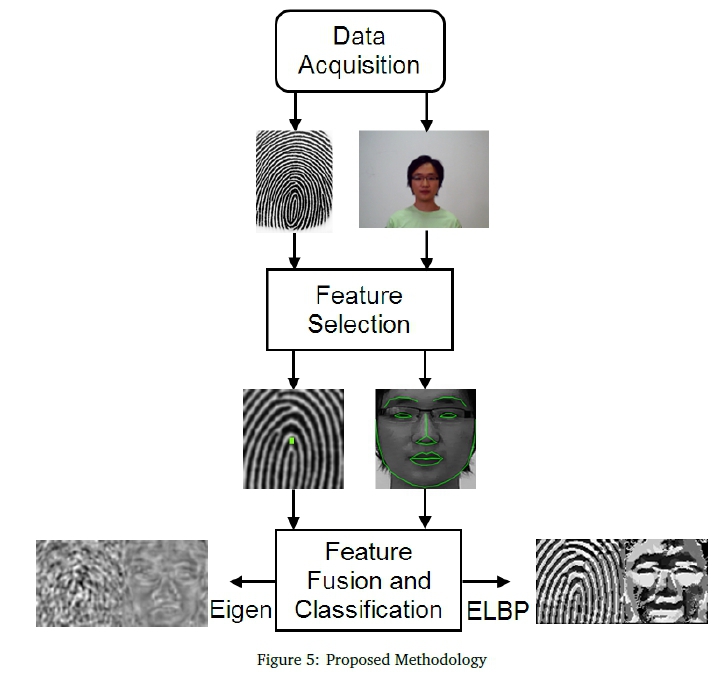
4.2 Methodology for Applying Guidelines
The following subsections detail the proposed multi-modal biometric solution, based on the guidelines determined in the previous subsection, and illustrated in Figure 5. The figure provides an overview specific to face and fingerprint fusion. A similar process would be followed in the case of other image-based modality combinations - as determined in previous work (Brown & Bradshaw, 2015, 2016a, 2016b). The popular Poly-U palmprint dataset resulted in perfect accuracy across all preliminary systems that fused palmprints with the face, fingerprint or both. Furthermore, when increasing the number of individuals from 40 to 106, a near-perfect accuracy was recorded when using only the palmprint with histogram equalization followed by LoG and the Eigen or Fisher classifier. Therefore, two challenging palmprint dataset were used in the final experiments.
4.2.1 Data Aequisition
Two groups of larger datasets were used in the final experiments discussed in Section 5. The first group of datasets consisting of 106 classes - SDUMLA multi-modal (face and fingerprint) (Yin et al., 2011) and the IITD Palmprint (Kumar, 2008) - are summarised as follows:
1. Face - Eight samples of frontal faces were selected. The samples consisted of different poses and props, namely, normal, hat and glasses, look down, smile, frown, surprise and shut eyes.
2. Fingerprints - Eight samples of the left thumbprint were selected from the fingerprint images consisting of partials with absent core points, poorly-defined ridges and well-defined ridges.
3. Palmprint - Eight samples of the left palmprint were used. Since only six samples exist per individual's hand, two extra samples with added noise were generated by performing 30% contrast reduction and a random four point affine transformation within 15 degrees and 5 pixel units on the last test sample for each individual. The challenging IITD palmprint was captured with a touchless sensor without user-pegs, thus resulting in wrinkle and scale variations.
The second group of datasets consisting of 200 classes - MUCT Face (Milborrow, Morkel, & Nicolls, 2010), MCYT Fingerprint (Ortega-Garcia et al., 2003) and CASIA Palmprint (Sun, Tan, Wang, & Li, 2005) - were generally of higher quality than the first group, based on sharpness and resolution. The second group of datasets are summarised as follows:
1. Face - Eight samples consisting of three horizontal-left viewing angles averaged at 0°, 25° and 50°, respectively, and one vertical-up viewing angle averaged at 25°, each taken at two different lighting conditions and an image resolution of 480 χ 640. This dataset is considered challenging when used for identification without manual landmarks and three-dimensional (3D) modelling, but can be consistently segmented using a recent automated landmark detection algorithm.
2. Fingerprints - Eight samples of the left and right thumbprint images were used from 100 individuals. This constituted 200 classes consisting of well-defined fingerprint ridges with consistent lighting in the majority of the samples; no partial fingerprints were recorded.
3. Palmprint - Eight samples of the left palmprint were used from 200 individuals. This palmprint dataset was also captured with a touchless sensor without user-pegs similar to the first palmprint dataset. However, the individuals were instructed to rest their hand on a uniform background and spread their fingers, resulting in reduced wrinkling.
4.2.2 Improved Faee Registration
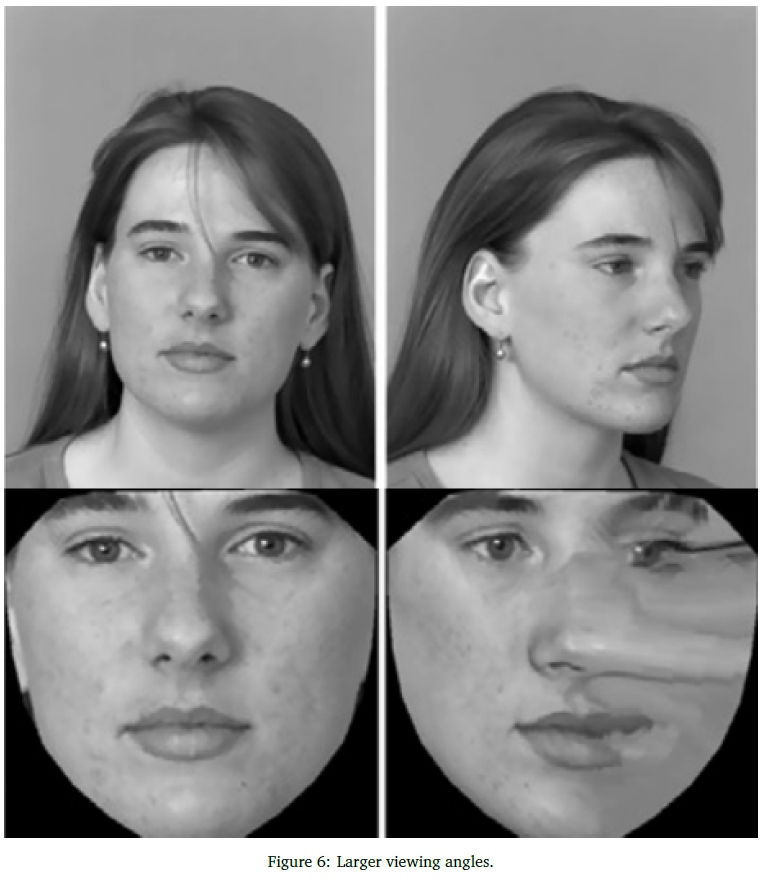
The face second dataset consists of viewing angles as large as 70°. The popular face segmentation method proposed in Subsection 3.2 is thus not adequate.
Face viewing angles that are not frontal poses require a normalization process that is robust, fast and reliable. Haghighat, Abdel-Mottaleb, and Alhalabi (2016) recently proposed such a normalization method, requiring only a single training sample. Their method aligns the face by automatically detecting landmarks using Histograms of Oriented Gradients (HOG) with an ensemble of regression trees for matching. A face mesh is created using Delaunay triangulation. Each triangle is warped using an affine transformation according to a reference frontal face mesh, resulting in only frontal faces.
Their method was compared to advanced 3D face modelling and performed similarly for viewing angles smaller than 45°. This proves their method is ideal for fast face alignment without requiring various viewing angles for building a 3D model. Although, all faces are normalised to 0°, a significant amount of frontal face information is lost at angles larger than 45°, as illustrated in Figure 6.
This paper modifies their method as follows. Initial alignment uses a similarity transform with point pairs corresponding to the eyes and nose to reduce the complexity of triangle warping. Viewing angles larger than 30° are handled differently than in the original method. Both the training and the testing image are warped to their between viewing angle. Since the between angle is often less than 30°, distortion is minimised and more of the training and testing image overlap. Furthermore, the testing image is mirrored when an angle difference of greater than 45° is detected. The improvement is evident in Figure 7, where the left image is the training image and the right image is the testing image. The original and improved versions were tested on 200 individuals of the FERET dataset. The improved version lowered the EER by 5% to 10%, depending on the magnitude of the viewing angle.
4.2.3 Feature Selection
The face, fingerprint, and palmprint datasets were automatically cropped to 75 χ 75 using multiple Haar cascades, Poincaré index with NL-means, and the iterative closest point, respectively. The Haar cascades were used to align the face based on the detected landmarks as outlined in Figure 5. LBPH served as both a fall-back mechanism and a final stage of alignment, for face, fingerprint and palmprint datasets.
Histogram equalization was applied to the Eigen and Fisher methods to reduce their shared weakness of dynamic lighting. Pixel normalization was instead applied to LBPH as histogram equalization caused negative effects on the spatial histogram. The ELBP operator was considered due to the inconsistent results achieved in preliminary experiments across test subjects when using the LoG filter. The ELBP operator was found to outperform histogram equalization and pixel normalization in terms of dynamic lighting in the preliminary experiments. However, this resulted in increased noise in the Eigen space, causing a reduction in accuracy compared with histogram equalization and pixel normalization. ELBP especially increased the noise when combined with LoG.
The ELBP operator was modified to improve Eigen and Fisher without increasing noise as follows: The typical parameters of ELBP used for LBPH texture classification - one pixel radius and eight neighbour pixels - were multiplied by four and averaged with the normalised original image to enable its use as a standalone feature selector. This reduced the variation in data of multiple samples across individuals and enabled its use with the LoG filter. This combination of the modified ELBP operator and LoG filter was chosen based on the guidelines, and thus two novel feature selectors are included in the final results in Section 5.
4.2.4 Feature-fusion and Classifieation
The enhanced face, fingerprint and palmprint feature vectors were combined using serial vector fusion. The fused vector is transformed to the Eigen feature space in the case of Eigen or Fisher. When the LBPH classifier is used, the feature vector is transformed to the spatial-histogram feature space. The classifiers divide the fused dataset into classes as explained in Section 3.4. The Eigen representation is reconstructed using only five principal components in Figure 5, for visualization. The ELBP image is also shown in the figure instead of the spatial histogram, for visualization. Both of these visualizations are produced using the baseline system.
5 RESULTS
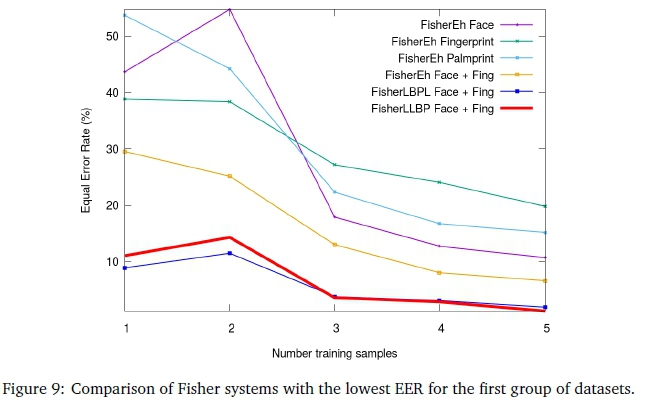
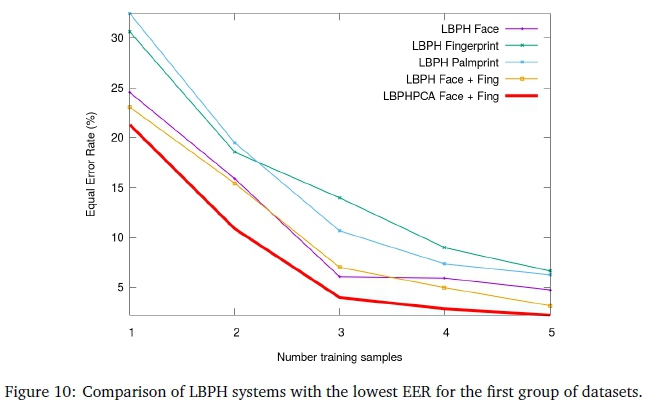
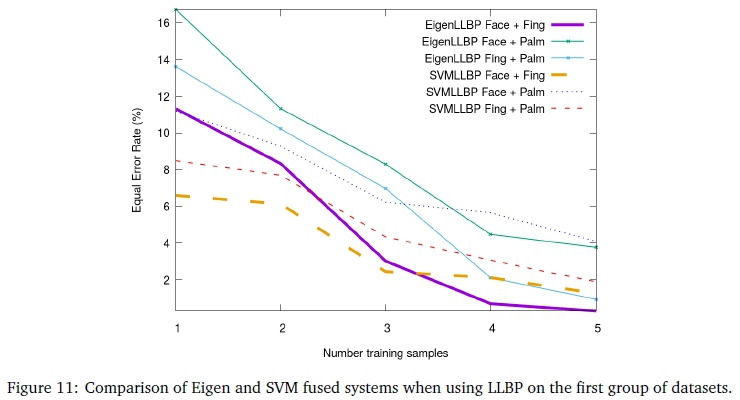
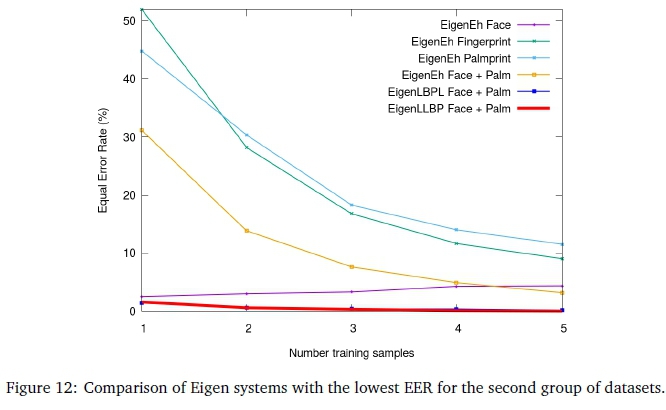
The final experiments using the proposed fusion methodology are presented in this section. Figures 8, 9, 10 and 11 illustrate the best performing bi-modal fusion combination for the first group of datasets (the fingerprint and face in all three cases). These results are discussed in Subsections 5.1 and 5.2. The second group of datasets are similarly illustrated in Figures 12, 13, 14 and 15. These results are discussed in Subsections 5.3 and 5.4.
The following suffixes identify the applied feature selection and transformation schemes that were combined with the Eigen, Fisher or LBPH classifier: Histogram equalization is the baseline system, referred to as Eh; LoG is referred to as L; Modified ELBP is referred to as LBP; LoG followed by modified ELBP is referred to as LLBP; and PCA reduction (1%) is referred to as PCA.
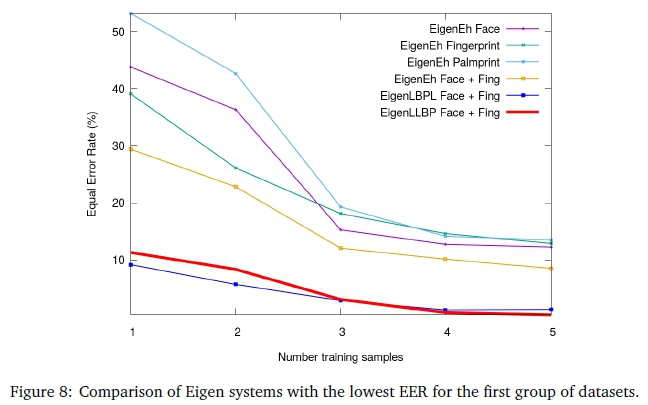
5.1 Experiment 1
Referring to Figure 8, the baseline fusion always outperforms the face, fingerprint and palmprint. LBPL is the best performer for one training sample with an EER of 9.16% while LLBP yields an EER of 0.31% with five training samples.
Referring to Figure 9, the Fisher classifier performs similarly to Eigen, but with a noticeably weaker performance when using two training samples. The confusion matrix was consulted and upon manual inspection of the face images, training samples two and three consisted of severe occlusions caused by the props on faces as well as greater downward pose angles.
Referring to Figure 10, the baseline fusion produces a lower accuracy than the face when using three training samples. Moreover, LBPH is a good face texture classifier. LBPH does not respond well to any of the feature processing modules described in Section 3. However, removing 1% variance of the least significant principal components improved the EER by 3% on average, indicating overfitting of the spatial histogram.
Table 2 focuses on the best accuracies achieved by the various Eigen, Fisher and LBPH methods, using five training samples. These results include the baseline, LBPL and LLBP methods for the individual biometrics. LBPHPCA produces the best face EER, 4.77% lower than EigenLLBP and FisherLLBP face methods, which share an EER of 8.49%. The fingerprint accuracies are similar, but EigenLBPL is slightly better with an EER of 5.35%. LBPHPCA produces the best palmprint accuracy at 5.71% EER. The results show that LBPH does not benefit from fusion as greatly as Eigen and Fisher. The fused EigenLLBP method achieves a 1.58% lower EER than FisherLBPL. The LBPL and LLBP methods for Eigen and Fisher produced very similar accuracies in all cases, except for EigenLLBP, which achieved a 0.95% lower EER than EigenLBPL.
5.2 Experiment 2
Referring to Figure 11, various fusion combinations that use EigenLLBP and SVMLLBP methods are compared. The face and fingerprint combination outperformed the rest, on average, in the case of both Eigen and SVM with a lowest EER of 0.31% and 1.26%, respectively. This is significant when compared with the face and palm fused systems, which achieved the lowest accuracies. However, this result is expected due to the challenging nature of the IITD palmprint dataset. The SVM achieves the lowest EER for one training sample regardless of modality, but does not significantly improve when using more than three training samples.
Fusing all modalities resulted in a 0.27% and 0.13% EER for EigenLLBP and SVMLLBP when using a single training sample, respectively. Using two or more training samples resulted in a perfect accuracy for both methods. None of the other methods achieved a perfect accuracy except for the standard linear SVM - when using three or more samples. The standard linear SVM achieved a similar improvement in accuracy as Eigen did when applying the LLBP algorithm.arison of Eigen and SVM fused systems when using LLBP on the first group of datasets.
5.3 Experiment 3
Due to many near-zero error rates, the reader is encouraged to focus on the various shapes of points that depict the different systems in the following results.
Referring to Figure 12, the baseline fusion again outperforms the fingerprint and palmprint individual modalities, in this second group of datasets. However, the face surpasses the baseline fusion method. This change in trend is discussed in the next paragraph. Another outlier for face is the decreasing accuracy with more training data. This overfitting problem is due to not being able to increase inter-class scatter. Manual inspection revealed individuals with similar faces to be the cause. Eigen achieves very similar results for the Face + Fing and Face + Palm fused datasets, but Face + Palm achieves a 0.05% better accuracy on average. Consistency of the best results are sustained as LBPL is the best performer for one training sample at 1.42% EER compared to the 1.57% EER of LLBP On the other hand, LLBP yields a perfect accuracy for five training samples, that is a 0.17% improvement compared with LBPL.
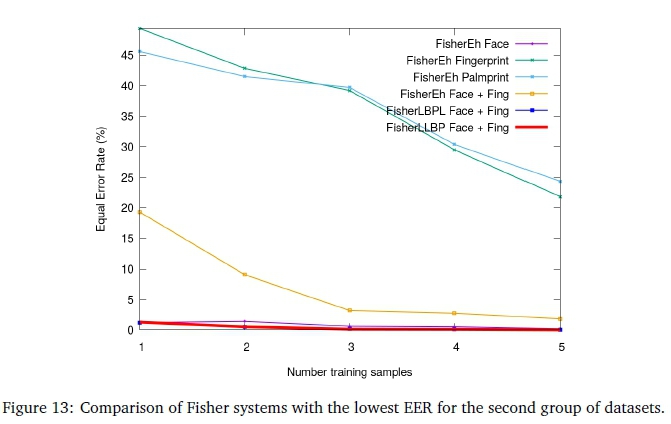
Referring to Figure 13, the Fisher classifier further improves the face accuracy beyond Eigen, due to improved class separation and dimensionality reduction after achieving maximum scatter. This is particular to individuals with similar faces. As expected, this is limited to the face due to well-segmented features of a high quality dataset. In fact, it achieves a maximum and minimum EER of only 1.21 and 0.17% for one and five training samples, respectively. A 10% better EER is observed over the best baseline fusion for Fisher. This is an example of the importance of selecting an appropriate fusion scheme at the feature level.
Trends in the LBPL and LLBP methods are again similar to Eigen and promising as they both surpass the face. Face + Fing is the best performing fused dataset. LBPL and LLBP achieve 1.21% and 1.29% EER respectively for one sample. LLBP surpasses LBPL with 0.10% EER compared with 0.20% EER, at three samples. Both methods achieve a zero EER at five samples. The consistency of the features are attributed to the use of the new face alignment algorithm instead of frontal face segmentation described in Section 3.2.
The face experiment conducted in Subsection 5.1 was thus retested using the new face alignment algorithm, achieving a 10% reduction in average EER. Another manual inspection revealed that the improvement was prevalent in samples consisting of variations in frontal pose angles. Improving face segmentation under severe facial occlusions is considered for future work.
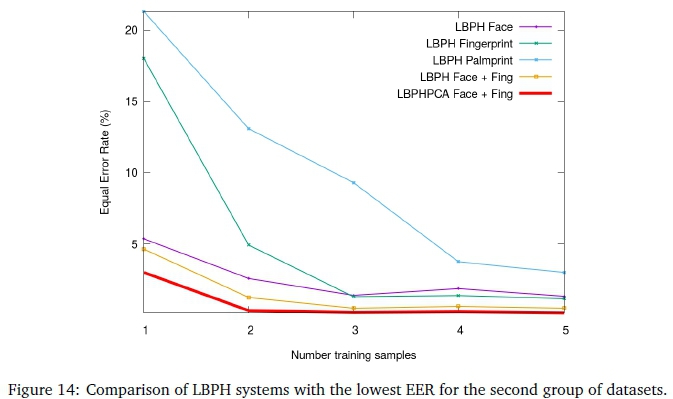
Referring to Figure 14, the baseline fusion produces a lower accuracy than the individual biometric modalities. The fingerprint surpassing the face at three and more training samples is an unexpected result. This warrants future investigation as it could contain key factors that point to the "best features" for LBPH. The palmprint has a significantly higher EER than the face and fingerprint. The Face + Fing achieving the best accuracy is thus expected. LBPH fused datasets once again underperformed compared with Eigen and Fisher. It achieves 3% and 0.17% EER for one and five training sample, respectively. PCA reduction improved the accuracy by 1% on average, again indicating overfitting.
Table 3 focuses on the best accuracies for the second group of datasets; similar to Table 2 this includes LLBP and LBPL for individual modalities. FisherLLBP produces the only perfect accuracy for an individual modality, namely face. The fingerprint accuracies are similar, but EigenLBPL is slightly better with an EER of 5.35%. The palmprint accuracies are similar, but EigenLBPL produces the best palmprint accuracy at 1.67% EER. The results reiterate that LBPH does not benefit from fusion as greatly as Eigen and Fisher. The fused EigenLLBP and FisherLLBP methods both achieves a perfect accuracy. The results indicate that FisherLLBP has the highest potential accuracy, but requires data with low intra-class variation.
5.4 Experient 4
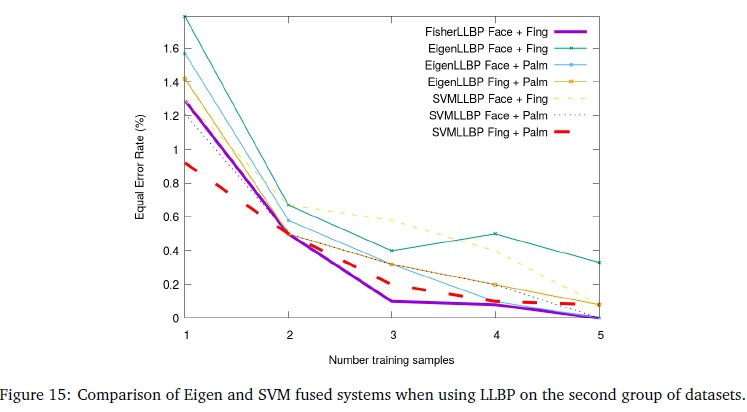
Referring to Figure 15, various fusion combinations that use EigenLLBP and SVMLLBP methods are compared. The face and fingerprint fused systems outperformed the other combinations, on average, with an exception of EigenLLBP Face + Fing, which achieved the worst average accuracy. SVMLLBP achieves the lowest EER for one training sample regardless of modality, again with an exception of Face + Fing.
Fusing all modalities resulted in a perfect EER for EigenLLBP and SVMLLBP, regardless of the number of training samples. Bigger or more challenging datasets are required to assess the fusion of three or more modalities.
5.5 Summary of Results
Both the preliminary and final results confirm that the modified ELBP operator was successfully used together with the LoG filter to significantly improve feature discrimination and verify the hypothesis of requiring guidelines, presented in this paper. The LBPH method did not improve significantly from fusion or the feature processing modules described in Section 3. However, LBPH proved to be a robust classifier and was thus used in the proposed systems for improved image registration and as a fall-back mechanism, preventing system failure. On the other hand, the Eigen classifier showed the most significant improvement. This is due to the benefit of increased feature discrimination on a classifier that relies on maximising total scatter. Fisher has an even higher potential accuracy, but relies on low intra-class variation in order to effectively maximise inter-class scatter. Both EigenLLBP and FisherLLBP achieve the highest recognition accuracy of all the fusion schemes when using five samples. SVMLLBP achieved the best EER on fused datasets, on average, when using one to three training samples. Furthermore, the SVM classifier is consistently the best performer when limited to one training sample. This is of particular benefit to applications that require low training time and data.
6 CONCLUSION AND ONGOING RESEARCH
A comparison was performed on the face, fingerprint, palmprint and their fused combinations. The comparison was extended to include two combinations of the modified ELBP operator with the LoG filter, applied to the Eigen, Fisher and SVM classifier. This extended comparison is an effort to improve the recognition performance of feature-fusion achieved in our previous work and suggest more guidelines for future systems. An improved face segmentation algorithm was also implemented and reduced the information loss between training and testing face images with viewing angles larger than 45°. The contribution of extended feature-fusion guidelines and improved face segmentation are particularly promising and encourages further improvements in respective fields.
The LBPH classifier achieved the best accuracy before feature selection and showed promise regarding its robustness to misalignment, dynamic lighting and scaling. Eigen in particular, showed substantial improvement when applying the two novel feature selection combinations before feature transformation. More fusion combinations were compared in the case of the Eigen and SVM classifiers. The face and palm fused systems performed the best when using Eigen and SVM. Face and fingerprint fused systems achieved the best result when using Fisher and was also the best performing combination across all systems. At the feature level, well-known techniques often form the basis of these systems without reasoning. Moreover, multi-modal biometric studies often propose recognition systems that integrate many feature processing modules, such as quality enhancement and image registration during pre-processing, as well as feature selection, feature transformation and post-processing techniques. Thus, isolating the contributions that measure progress in the state-of-the-art is a time consuming and non-trivial problem. However, this research serves as a foundation for selecting appropriate features for image-based multi-modal fusion as it contributes more guidelines to the research area.
Specifying a complete set of formal guidelines for multi-modal biometric fusion at the feature level requires covering a substantial series of experiments. Therefore, a comprehensive review of the important factors covered in this paper is being further investigated with additional experimentation on more image-based biometric modalities, datasets and feature processing modules. This ongoing research will form the basis for implementing optimal feature-fusion schemes, given a particular application in future.
ACKNOWLEDGEMENTS
The authors would like to thank the CSIR, Information Security department for their financial support. Thank you to the authors of the publicly available datasets used in this paper: Poly-U Palmprint (Zhang et al., 2003), ORL Face (Samaria & Harter, 1994), SDUMLA-HMT (Yin et al., 2011), IITD Palmprint (Kumar, 2008), MCYT Fingerprint (Ortega-Garcia et al., 2003), MUCT Face (Milborrow et al., 2010) and CASIA Palmprint (Sun et al., 2005).
References
Ahmad, M. I., Woo, W. L., & Dlay, S. S. (2010). Multimodal biometric fusion at feature level: Face and palmprint. In 2010 7th International Symposium on Communication Systems Networks and Digital Signal Processing (CSNDSP) (pp. 801-805). IEEE.
Ahonen, T., Hadid, A., & Pietikainen, M. (2006). Face description with local binary patterns: Application to face recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 28(12), 2037-2041. https://doi.org/10.1109/TPAMI.2006.244 [ Links ]
Belhumeur, I? N., Hespanha, J. I?, & Kriegman, D. (1997). Eigenfaces vs. Fisherfaces: Recognition using class specific linear projection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 19(7), 711-720. https://doi.org/10.1109/34.598228 [ Links ]
Bovik, A. C. (2010). Handbook of image and video processing. Academic Press.
Brown, D. (2013). Faster upper body pose recognition and estimation using Compute Unified Device Architecture (Doctoral dissertation, University of Western Cape). [ Links ]
Brown, D. & Bradshaw, K. (2015). An investigation of face and fingerprint feature-fusion guidelines. In Beyond databases, architectures and structures. advanced technologies for data mining and knowledge discovery (pp. 585-599). Springer.
Brown, D. & Bradshaw, K. (2016a). A multi-biometric feature-fusion framework for improved unimodal and multi-modal human identification. In Technologies for Homeland Security (HST), 2016 IEEE Symposium on (pp. 1-6). IEEE. https://doi.org/10.1109/ths.2016.7568927
Brown, D. & Bradshaw, K. (2016b). Extended feature-fusion guidelines to improve image-based multi-modal biometrics. In Proceedings of the Annual Conference of the South African Institute of Computer Scientists and Information Technologists (p. 7). ACM. https://doi.org/10.1145/2987491.2987512
Buades, A., Coll, B., & Morel, J.-M. (2005). A non-local algorithm for image denoising. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2005. CVPR 2005. (Vol. 2, pp. 60-65). IEEE. https://doi.org/10.1109/evpr.2005.38
Budhi, G. S., Adipranata, R., & Hartono, F. J. (2010). The use of Gabor filter and back-propagation neural network for the automobile types recognition. In 2nd International Conference SIIT 2010.
Chikkerur, S., Cartwright, A. N., & Govindaraju, V. (2007). Fingerprint enhancement using STFT analysis. Pattern Recognition, 40(1), 198-211. https://doi.org/10.1016/j.pateog.2006.05.036 [ Links ]
Deshmukh, A., Pawar, S., & Joshi, M. (2013). Feature level fusion of face and fingerprint modalities using Gabor filter bank. In 2013 IEEE International Conference on Signal Processing, Computing andControl (ISPCC) (pp. 1-5). IEEE. https://doi.org/10.1109/ISPCC.2013.6663404
Eskandari, M. & Toygar, Ö. (2015). Selection of optimized features and weights on face-iris fusion using distance images. Computer Vision and Image Understanding, 137, 63-75. https://doi.org/10.1016/j.eviu.2015.02.011 [ Links ]
Feng, J. & Jain, A. (2011, February). Fingerprint reconstruction: From minutiae to phase. IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(2), 209-223. https://doi.org/10.1109/TPAMI.2010.77 [ Links ]
Haghighat, M., Abdel-Mottaleb, M., & Alhalabi, W. (2016). Fully automatic face normalization and single sample face recognition in unconstrained environments. Expert Systems with Applications, 47, 23-34. [ Links ]
Iloanusi, O. N. (2014). Fusion of finger types for fingerprint indexing using minutiae quadruplets. Pattern Recognition Letters, 38, 8-14. https://doi.org/10.1016/j.patree.2013.10.019 [ Links ]
Jain, A. K., Prabhakar, S., Hong, L., & Pankanti, S. (2000). Filterbank-based fingerprint matching. IEEE Transactions on Image Processing, 9(5), 846-859. https://doi.org/10.1109/83.841531 [ Links ]
Karki, M. V & Selvi, S. S. (2013). Multimodal biometrics at feature level fusion using texture features. Internationaljournal of Biometrics and Bioinformatics, 7(1), 58-73. [ Links ]
Kaur, D. & Kaur, G. (2013). Level of fusion in multimodal biometrics: A review. International Journal of Advanced Research in Computer Science and Software Engineering, 3(2), 242-246. [ Links ]
Kumar, A. (2008). Incorporating cohort information for reliable palmprint authentication. In Computer Vision, Graphics & Image Processing, 2008. ICVGIP'08. Sixth Indian Conference on (pp. 583-590). IEEE. https://doi.org/10.1109/ICVGIP.2008.73
Li, W., Zhang, B., Zhang, L., & Yan, J. (2012). Principal line-based alignment refinement for palmprint recognition. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 42(6), 1491-1499. https://doi.org/10.1109/TSMCC.2012.2195653 [ Links ]
Maltoni, D., Maio, D., Jain, A. K., & Prabhakar, S. (2009). Handbook of fingerprint recognition. Springer Science & Business Media. https://doi.org/10.1007/978-1-84882-254-2
Milborrow, S., Morkel, J., & Nicolls, F. (2010). The MUCT Landmarked Face Database. Last accessed 05 Jul 2017. Retrieved from http://www.milbo.org/muet
Ortega-Garcia, J., Fierrez-Aguilar, J., Simon, D., Gonzalez, J., Faundez-Zanuy, M., Espinosa, V, ... Vivaracho, C., et al. (2003). MCYT baseline corpus: A bimodal biometric database. IEE Proceedings-Vision, Image and Signal Processing, 150(6), 395-401. https://doi.org/10.1049/ip-vis:20031078 [ Links ]
Peralta, D., Triguero, I., Sanchez-Reillo, R., Herrera, F., & Benitez, J. (2014, February). Fast fingerprint identification for large databases. Pattern Recognition, 47(2), 588-602. https://doi.org/10.1016/j.pateog.2013.08.002 [ Links ]
Porwik, P & Wrobel, K. (2005). The new algorithm of fingerprint reference point location based on identification masks. In Computer recognition systems (pp. 807-814). Springer. https://doi.org/10.1007/3-540-32390-2_95
Raghavendra, R., Dorizzi, B., Rao, A., & Kumar, G. H. (2011). Designing efficient fusion schemes for multimodal biometric systems using face and palmprint. Pattern Recognition, 44(5), 1076-1088. https://doi.org/10.1016/j.pateog.2010.11.008 [ Links ]
Rattani, A., Kisku, D. R., Bicego, M., & Tistarelli, M. (2011). Feature level fusion of face and fingerprint biometrics. In Biometrics: Theory, Applications and Systems (BTAS) (pp. 1-5).
Ribaric, S. & Fratric, I. (2006). Experimental evaluation of matching-score normalization techniques on different multimodal biometric systems. In Electrotechnical Conference, MELECON 2006. IEEE Mediterranean (pp. 498-501). IEEE.
Samaria, F. S. & Harter, A. C. (1994). Parameterisation of a stochastic model for human face identification. In Proceedings of the Second IEEE Workshop on Applications of Computer Vision (pp. 138-142). IEEE.
Sharma, P & Kaur, M. (2013). Multimodal classification using feature level fusion and SVM. International Journal of Computer Applications, 76(4), 26-32. https://doi.org/10.5120/13236-0670 [ Links ]
Sun, Z., Tan, T., Wang, Y., & Li, S. Z. (2005). Ordinal palmprint represention for personal identification [represention read representation]. In 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05) (Vol. 1, pp. 279-284). IEEE.
Wang, Z., Liu, C., Shi, T., & Ding, Q. (2013). Face-palm identification system on feature level fusion based on CCA. Journal of Information Hiding and Multimedia Signal Processing, 4(4), 272-279. [ Links ]
Yao, Y.-F., Jing, X.-Y., & Wong, H.-S. (2007). Face and palmprint feature level fusion for single sample biometrics recognition. Neurocomputing, 70(7), 1582-1586. [ Links ]
Yin, Y., Liu, L., & Sun, X. (2011). SDUMLA-HMT: a multimodal biometric database. In Biometric recognition (pp. 260-268). Springer. https://doi.org/10.1007/978-3-642-25449-9_33
Zhang, D., Kong, W.-K., You, J., & Wong, M. (2003). Online palmprint identification. IEEE Transactions on pattern analysis and machine intelligence, 25(9), 1041-1050. https://doi.org/10.1109/TPAMI.2003.1227981 [ Links ]
Zou, J., Feng, J., Zhang, X., & Ding, M. (2013). Local orientation field based nonlocal means method for fingerprint image de-noising. Journal of Signal and Information Processing, 4, 150.https://doi.org/10.4236/jsip.2013.43B026 [ Links ]
Received: 25 November 2016
Accepted: 19 June 2017
7 Available online: 9 July 2017


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}