










Services on Demand
Article
 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
Indicators

Related links
-
 Cited by Google
Cited by Google -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkSouth African Journal of Industrial Engineering
On-line version ISSN 2224-7890
Print version ISSN 1012-277X
S. Afr. J. Ind. Eng. vol.27 n.2 Pretoria Aug. 2016
http://dx.doi.org/10.7166/27-2-1119
GENERAL ARTICLES
Scheduling sequence-dependent colour printing jobs
J. Schuurman#; J.H. van Vuuren*
Department of Industrial Engineering Stellenbosch University, South Africa
ABSTRACT
A scheduling problem in the colour printing industry is considered in this paper. The problem is to find an optimal assignment of print jobs to each of a set of colour printers, as well as an optimal processing sequence for the set of jobs assigned to each printer. The objective is to minimise the makespan of the schedule to achieve a suitable balance between the workloads of the printers and the efficiencies of the job sequences assigned to the printers. A novel aspect of the problem is the way in which the printer set-up times associated with the jobs are job sequence-dependent - it is possible to exploit commonalities between the colours required for successive jobs on each machine. We solve this problem approximately by using a simple heuristic and three well-known metaheuristics. Besides colour printing, the scheduling problem considered here admits many other applications. Some of these alternative applications are also briefly described.
OPSOMMING
'n Skeduleringsprobleem uit die kleurdrukwerkbedryf word in hierdie artikel oorweeg. Die probleem vra vir 'n optimale toewysing van take aan elk van 'n versameling kleurdrukkers, sowel as die spesifikasie van 'n optimale volgorde waarin die take wat aan elke drukker toegewys is, uitgevoer moet word. Die doel is om die prosestyd van die drukker wat laaste klaarmaak te minimeer om sodoende 'n aanvaarbare balans tussen die werkladings van die drukkers en die taakvolgorde vir elke drukker te bewerkstellig. 'n Nuwe aspek van die probleem is die manier waarop die opsteltye van die drukkers vir die take volgorde-afhanklik is - dit is moontlik om gemeenskaplikhede tussen die kleure wat vir opeenvolgende take op elke masjien benodig word, uit te buit. Ons los hierdie probleem benaderd op deur gebruik te maak van 'n eenvoudige heuristiek asook drie bekende metaheuristieke. Behalwe vir kleurdrukwerk, het die skeduleringsprobleem wat hier beskou word vele ander toepassings. Sommige van hierdie toepassings word ook kortliks beskryf.
1 INTRODUCTION
Snack foods, such as candy bars and crisps, are usually packaged in convenient plastic or foil wrappers adorned with bold, colourful logos and other designs to draw the attention of consumers. In order to achieve the desired finish, colour overlay printing techniques are used. Fierce competition forces production facilities that specialise in this form of printing to improve the efficiency of their operations so that they can handle large printing volumes in a time-efficient and cost-effective manner. At the heart of realising this high level of efficiency at such a production facility lies a scheduling process in which print jobs have to be assigned to, and sequenced on, a collection of printers functioning in parallel and possibly at different speeds. This process aims to balance the workload among the printers to maximise print volume throughput.
Consider a collection of n printing jobs indexed by the set J = {1,...,n}. Associated with each job j e J is a colour set Cj, indicating which colours are required for the job, and the volume Wjof the job (usually measured in kilograms of printing material). The colour set of each job is typically a small subset of a larger universal set C of all possible colours at the disposal of the printing company. Each of the jobs in J requires processing on one of m parallel printers indexed by the set M = {1,...,m}. Printer k Є M operates at a printing speed of qk(measured in kilograms of printing material that can be produced per minute), and is equipped with a colour cartridge magazine of size bk(which is the number of colours that can be accommodated simultaneously in the printer).
Job j Є J can only be processed on printer k Є M if the magazine of printer k is large enough to accommodate all the colours in the colour set of job j - i.e., if |Cj| < bk. All the colours required for a job have to be loaded into the printer processing that job before beginning the print job. Furthermore, it is assumed that the printer magazine is empty at the start of the scheduling period, and that it should be empty again at the end of the printing schedule; but it typically remains fully-loaded throughout the duration of the scheduling period, because a fixed downtime is associated with reloading any colour cartridge.
Every job processed on one of the printers involves a production time consisting of two phases. The first of these is the printing phase, whose duration is both printer-dependent (because of possible variation in the processing speeds of the printers) and job-dependent (determined by the print volume of the job). The duration of the printing phase of job j Є J, also called its processing time, when performed by printer k Є M is therefore
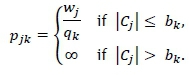
The second phase is the set-up phase. This involves removing from cartridges the ink colours not required for the next job scheduled for processing on that particular printer, to free up just enough space in the printer's magazine for colours that are indeed required for the next job but that are not present in the magazine. Each such colour change incurs a constant set-up time a (measured in minutes) that is required to empty, clean, and reload an ink cartridge, and is referred to as a Wash. If, however, a colour required for a specific job was also required for the previous job processed on a particular printer (and is therefore already in the printer's magazine when the reloading of cartridges for the next job takes place), then the above set-up time may be avoided for that colour. A sequence-dependent set-up time sijkis thus incurred when following up job i by job j on printer k. This set-up time can be calculated as a multiplied by the required number of colour changes in order to be able to process job j. Given a set of jobs to be processed by printer k Є M, the completion time Φkof the printer may therefore be reduced by a judicious choice of the sequence in which the jobs are to be performed on the printer.
A printing schedule for the parallel machine colour print scheduling problem (PMCPSP) described above therefore consists of an assignment of jobs to the various printers, and a processing sequence for the set of jobs assigned to each printer. The makespan Ωmaxof the printing schedule is the completion time of the printer that finishes last - i.e., Ωmax = max {(Φ1..,(Φm}, assuming that all printers start processing at time zero. The objective in the PMCPSP is to compute a printing schedule achieving the smallest possible makespan that will achieve a suitable balance between the workloads of the printers and the efficiencies of the job sequences assigned to the printers.
Even the special case of the PMCPSP, in which there is only m = 1 printer, is NP-hard [5,9]. Furthermore, it is difficult for even an experienced human operator to come up with high-quality solutions to the PMCPSP for the following reasons:
1. The duration of a print job only becomes known once it has been assigned to a printer. Moving a print job from one printer to another in a bid to balance the workload of printers in a schedule therefore requires non-intuitive calculations.
2. The set-up time associated with a print job only becomes known once the jobs assigned to the relevant printer have been sequenced, because it depends on the commonality of colours between a particular job and its predecessor.
For these reasons, it is desirable to aid production managers in the complex decisions associated with solving the PMCPSP by providing them with computerised decision support - based on mathematical modelling techniques - rather than requiring them to make scheduling decisions based purely on intuition or experience. Although the literature contains mathematical models for scheduling problems that conform to the particular structure and requirements of the PMCPSP, these models are solvable to optimality for only the tiniest of problem instances. Since realistic instances of the PMCPSP are well beyond the reach of exact solution methods within reasonable timeframes, our objectives in this paper are (1) to design a user-friendly decision support system (DSS) - based on various heuristic model solution approaches - that is capable of aiding production engineers to determine high-quality solutions to the PMCPSP; and (2) to demonstrate the practical workability of this DSS.
This paper is organised as follows. Section 2 contains a brief review of two approaches to modelling the PMCPSP mathematically, while the working of one heuristic and three metaheuristic solution procedures, which are applied in this paper to the PMCPSP, are outlined in Section 3. In Section 4, these approximate solution approaches are compared with respect to their execution times and the qualities of solutions they produce in the context of a number of small test instances, after which we turn our attention in Section 5 to the design of a user-friendly DSS for solving larger instances of the PMCPSP. This DSS is applied to a realistic instance of the PMCPSP in the form of a case study in Section 6 to demonstrate its workability. In Section 7 the paper ends with a number of conclusions, ideas for possible future work, and descriptions of alternative applications conforming to the requirements of the PMCPSP. Mathematical PMCPSP model formulations are presented in an appendix.
2 LITERATURE REVIEW
There are two formulations of parallel machine scheduling problems with sequence-dependent setup times in the literature that resemble the PMCPSP. The first was introduced by Helal et al. [8] in 2006. Avalos-Rosales et al. [2] proposed an improved reformulation of this original model in 2013 in response to a weakness discovered in the earlier formulation. To promote the general readability of the paper by non-mathematically-inclined readers, these two formulations are relegated to an appendix at the end of the paper.
In the model formulation proposed by Helal et al. [8], the makespan is linearised as the maximum of the completion times of all the jobs that have to be processed. Avalos-Rosales et al. [2] found, however, that the lower bound on the schedule's makespan produced by the linear relaxation of the model of Helal et al. [8] is very weak, and this prompted them to reformulate the model by linearising the makespan as the maximum of the spans of all the machines.
Alvalos-Rosales et al. [2] performed computational tests to compare the efficacy of a commercial solver to solve their model reformulation for a suite of test problem instances (available online [18]), as opposed to solving the original model formulation of Helal et al. [8]. They also used the results thus obtained to determine the dimensions (i.e., the values of the parameters m and n) of problem instances that are realistically solvable by exact methods.
Alvalos-Rosales et al. [2] generated two sets of test instances for this purpose: a set of small instances and a set of larger instances. The set of small instances involved m e {2,3,4,5} machines and n e {6,8,10,12} jobs. For each value of m, a total of ten instances of sets of n jobs were generated, with job durations drawn from uniform distributions with ranges 1-9, 1-49, 1-99, and 1-124. In all cases, the set-up times between jobs were drawn from a uniform distribution with range 1-99, thus giving rise to 4 χ 4 χ 10 χ 4 = 640 small problem instances. Using CPlex 12.2 on a Pentium dual core 2 GHz processor with 3Gb of RAM running in the operating system Ubuntu 11.1, they were able to solve only 565 (88.28 per cent) of these small instances to optimality within one hour when adopting the earlier model formulation of Hilal et al. [8], and all (100 per cent) of the small instances when using their own model reformulation. In fact, the average time required to solve the small instances to optimality with the latter formulation was only 0.625 seconds. This led Alvalos-Rosales et al. [2] to conclude that their formulation is superior from a practical perspective.
The set of larger instances again involved m Є {2,3,4,5} machines, but this time n Є {15,20,25,30,35,40} jobs. For each value of m, a total of ten instances of sets of n jobs were again generated, with job durations drawn from uniform distributions with ranges 1-49, 1-99, and 1 - 124. In all cases, the set-up times between jobs were again drawn from a uniform distribution with range 1-99, thus giving rise to 4 χ 6 χ 10 χ 3 = 720 larger problem instances. In view of the fact that not all small instances of the model formulation of Helal et al. [8] were solvable within one hour of computation time, Alvalos-Rosales et al. [2] elected to solve the larger instances using only their own superior formulation. Using the same computing platform as above, they were able to solve only 636 (88.33 per cent) of the larger instances to optimality within one hour. For the largest instances where m = 5 machines and n = 35 or 40 jobs, an average optimality gap of between 3.3 per cent and 3.8 per cent was achieved within one hour of computing time.
In view of these results and the NP-hardness of even the special case of the PMCPSP with m = 1 machine [6,13], the portion of instances that are solvable to optimality within one hour (or even a few hours, for that matter) is expected to decrease exponentially as m and/or n increases. Because realistic instances of the PMCPSP are expected to contain well in excess of n = 100 jobs, we conclude that realistic instances of the PMCPSP are not solvable within a realistic timeframe using exact methods. Instead, therefore, we consider one heuristic and three metaheuristic solution approaches in the next section to solve the PMCPSP approximately.
3 APPROXIMATE SOLUTION METHODOLOGIES
The four approximate methods considered in this paper to solve the PMCPSP are the largest-processing-time-first rule, a local search, the method of tabu search, and simulated annealing, all described in more detail below.
3.1 Largest-processing-time-first rule
The largest-processing-time-first (LPTF) rule is a well-known scheduling heuristic [15] that aims to minimise the makespan of a production schedule on parallel machines by scheduling shorter jobs towards the end of the scheduling period where they can be used to balance the production load of the various machines. According to the LPTF rule, the m largest jobs are scheduled first on the m machines, one job per machine. Afterwards, whenever a machine is freed, the largest of those jobs not yet scheduled is processed on that machine. Due to its inflexibility, the LPTF rule is rarely used in isolation; instead, it is often used as a starting point for more advanced scheduling metaheuristics.
3.2 Improving local search
An improving local search is an iterative metaheuristic that moves from one candidate solution to a neighbouring solution of higher quality in solution space during every iteration [5,17]. The quality of a solution is measured in terms of the objective function of the optimisation problem at hand. To search within the solution space in a systematic manner, a problem-specific neighbourhood structure is induced around the current solution by a set of so-called moves (perturbations performed with respect to the current solution). Solutions in this neighbourhood are evaluated, and the highest-quality solution is adopted as the next current solution, provided that this solution is of better quality than the current solution. If there is no improving solution in the neighbourhood of the current solution, then the search terminates and the current solution is reported as the (locally) optimal solution to the optimisation problem. A major disadvantage of an improving local search is, of course, that it may easily become trapped at an inferior locally optimal solution, and hence the procedure is sensitive to the candidate solution chosen to initiate the search.
In this paper, we generate the initial (or first current) solution either randomly or by using the LPTF rule. The neighbourhood of the current solution results from applying so-called displacement moves [17] to the current solution. In the context of the PMCPSP, a displacement move consists of moving some job j from its current position in the production sequence of some printer k to any position in the production sequence of any printer k (allowing for the possibility that perhaps k = k'). All combinations of j and k are considered in turn, resulting in a potentially large neighbourhood for each candidate solution and a search procedure that is essentially deterministic from the initial solution onwards.
3.3 Tabu search
Introduced by Glover [7] in 1986, the tabu search method is a metaheuristic inspired by the mechanisms of human memory. In contrast with an improving local search, the tabu search method - which is also an iterative search procedure - allows for the escape from locally optimal solutions by (possibly) accepting non-improving moves when moving from the current solution to the next solution. To avoid cycling, a so-called tabu list of a fixed number of the most recent moves performed during the search is maintained, and the reversal of any move in this list is (temporarily) forbidden when deciding on the next move to perform. The tabu list is managed as a first-in-first-out queue of fixed length, called the tabu tenure, by removing the oldest entry from the list when a new entry is inserted into the list. The tabu tenure - denoted by τ- is an important parameter that affects the efficiency of the search, is problem-specific, and is usually determined empirically by prior experimentation [7]. Because the search does not necessarily terminate at a locally optimal solution (as is the case in an improving local search), a pre-specified, fixed number Imax of search iterations is usually performed before terminating the search. Furthermore, since the last current solution is not necessarily the best candidate uncovered during the search, a record is maintained of the best solution found during the entire search. This solution is called the incumbent, and it is reported as the approximately optimal solution to the optimisation problem at hand at termination of the search.
In this paper, we generate the initial (or first current) solution either randomly or by using the LPTF rule, and again we employ displacement moves as described in Section 3.2, but with the added provision that the move should not be the reversal of any move recorded in the tabu list.
On experimentation with randomly-generated instances of the PMCPSP, it was found that an effective choice of values for the tabu tenure τand number of search iterations Imax is the easily extendable trend shown in Table 1. These values seem to deliver good results.
3.4 Simulated annealing
The method of simulated annealing was first proposed by Kirkpatrick et al. [9] in 1983 as a simulation model to describe the physical process of annealing condensed matter within the realm of metallurgy. This method is also an iterative search procedure in which a single, current solution is maintained during each iteration. In contrast with the deterministic method of tabu search, however, simulated annealing is a stochastic search process. Non-improving moves are also allowed - as in the method of tabu search. However, such moves are only accepted with probability

where Δobjdenotes the absolute value of the amount by which the objective function would deteriorate when moving from the current solution to the non-improving solution, and where Tw is the value of a parameter - called the temperature - during temperature stage w e {0,1,2,...}, which controls the search progression. The acceptance probability in (1) is known as the Metropolis acceptance criterion and decreases as Δobj increases or as Twdecreases. The initial temperature T0 is selected relatively large, and is then decreased in stages according to a so-called cooling schedule to allow the search to initially explore the solution space (much as a random search would do), but so that it becomes gradually harder to accept non-improving moves later during the search (i.e., so that it resembles a randomised improving local search more towards the end of the search, thereby exploiting the vicinity of high-quality solutions) [17].
Busetti [4] states that a good value for the initial temperature is such that approximately 80 per cent of all non-improving moves are accepted at the start of the search. Such an initial temperature may be estimated by conducting a trial search during which all non-improving moves are accepted. The initial temperature for the full search may then be taken as

where Δ+OBJ denotes the average of the changes in objective function values as a result of accepting non-improving moves during the trial search.
The number of iterations spent by the search in temperature stage w is determined by a Markov chain of length Lw. As Busetti [4] states, the value of Lw (= L, say) should ideally depend on the optimisation problem at hand, rather than being a function of w. It would, in fact, make sense to require a minimum of Amin move acceptances during any temperature stage before lowering the temperature, where Amin is a pre-specified parameter. As Twapproaches zero, however, non-improving moves are accepted with decreasing probability and so the number of trials expected before accepting Amin moves is expected to increase without bound as the search progresses, no matter the value of the positive integer Amin. A suitable compromise is, therefore, to terminate the search once L moves have been attempted or Amin moves have been accepted (whichever occurs first), for some positive integers L and Amin satisfying L > Amin. Following the rule of thumb proposed by Dreo et al. [5], we take L = 100 N and Amin = 12 N, where N is some measure of the number of degrees of freedom in the optimisation problem. Based on numerical experimentation involving random instances of the MPCPSP, we choose N = n in this paper, since this value seems to yield relatively good results.
The well-known geometric cooling update rule

is adopted in this paper, where the cooling parameter ß is required to assume a value close to, but smaller than, one. As originally proposed by Kirkpatrick et al. [9], we employ the value ß = 0.95 here.
According to Busetti [4], the final temperature for the cooling schedule should be taken as that temperature at which the search ceases to make significant progress. We adopt the approach suggested by Dreo et al. [5], where the search is considered to have ceased making significant progress when it has failed to accept any moves during three consecutive temperature stages, at which point the search is terminated.
Finally, the same incumbent solution reporting protocol is adopted for the method of simulated annealing in this paper as that described for the method of tabu search above.
4 TEST RESULTS
As described in Section 2, the set-up times in the PMCPSP test instances of Avalos-Rosales et al. [2] are uniformly distributed and were drawn independently of one another. These set-up times, therefore, do not possess the special colour commonality characteristic, which is inherent to the PMCPSP. Hence we cannot reliably use their test instances for comparing the efficacies of the (meta)heuristic solution methods described in Section 3 in the context of the PMCPSP.
We consequently generated ten instances of print job sets for the PMCPSP, each containing 24 jobs and each job requiring at least two, and at most four, colours from the universal colour set

For each job, a print volume was drawn from a uniform distribution in the range 1-1000 kg. These job sets are listed in Table 2. From these ten instances of job sets, we created twenty hypothetical instances of the PMCPSP by supposing that three printers are available to process the jobs in each case, one operating at a speed of 4.5 kg/min and two operating at a speed of 8 kg/min, with all three printers having either bk = 4 or bk = 6 colour cartridges, for k = 1,2,3. Finally, we assumed that it takes a = 30 minutes to empty, wash, and refill a single colour cartridge.
The results in Table 3 were obtained on implementation of the three metaheuristic solution procedures of Section 3 (improving local search, tabu search, and simulated annealing) for the PMCPSP instances described above. The first twenty lines of the table contain results for the case where each printer has only bk = 4 colour cartridges and the metaheuristics are either initialised according to the LPTF rule (lines 1-10) or randomly (lines 11-20). The last twenty lines of the table similarly contain results for the case where each printer has bk = 6 colour cartridges and the metaheuristics are either initialised according to the LPTF rule (lines 21-30) or randomly (lines 31-40).
Based on the results in Table 3, the method of simulated annealing clearly outperforms the other two algorithms, yielding the best results in 33 out of the 40 cases (82.5 per cent). The method of tabu search yields the best results in five out of the 40 cases (12.5 per cent), while the improving local search yields the best results in only two out of the 40 cases (5 per cent). The method of tabu search is the next-best method, because it yields the second-best results in 29 out of the 40 cases (72.5 per cent). The method of simulated annealing yields the second best results in seven out of the 40 cases (17.5 per cent), while the improving local search yields the second-best results in only four out of the 40 cases (10 per cent).
The advantage of the improving local search, however, is that it yields results in a fraction of the execution time required by the methods of both tabu search and simulated annealing (but often becomes trapped at an inferior, locally optimal solution).
An advantage of the tabu search method is its remarkable consistency in execution times (an average of 43,651.4 seconds with a standard deviation 6.0 per cent of this value). This is due to the stopping criterion adopted (/max = 300 and τ= 20 according to Table 1). In contrast, the improving local search exhibits the superior average execution time of 7273.9 seconds, but with a standard deviation 38.6 per cent of this value, while the method of simulated annealing achieves an average execution time of 73903.0 seconds with a standard deviation 160.4 per cent of this value.
Finally, use of the LPTF rule as initialisation procedure seems to yield better results than a random initialisation for the improving local search and tabu search; but for the method of simulated annealing, the opposite is true.
5 DECISION SUPPORT SYSTEM
We designed a DSS in Microsoft Excel to solve instances of the PMCPSP approximately. Although the execution times typically achieved by Excel macros are far inferior to what can be achieved, for example, in C or C++, Microsoft Excel was nevertheless chosen as the computing platform because it was anticipated that production engineers - tasked with solving instances of the PMCPSP in practice - will typically have access to, and be familiar with, this environment. Moreover, it would be very easy for such engineers to provide input data directly into Excel, rather than having to create text files or files in other formats containing these data.
Although the results of the previous section indicate that the method of simulated annealing initialised randomly seems to be the best algorithm and initialisation mechanism combination for finding high-quality solutions to the PMCPSP, we decided, for the sake of flexibility, to incorporate all three metaheuristics of Section 3 into our DSS implementation, along with both initialisation mechanisms (random initialisation and initialisation by the LPTF rule). The DSS user has the freedom to choose the algorithm and initialisation mechanism (s)he would like to use when solving an instance of the PMCPSP.
The user is presented with the input screen shown in Figure 1 on initialisation of the DSS in Excel. In this screen, the user is required to provide input values in the fields labelled Search code, Initial sequence code, Number of print jobs, Set-up time, and Number of printers. The first two fields have to be populated with the letters L/S/T (representing the three solution methods of local improving search, simulated annealing, and tabu search, respectively) and R/L (representing the method of initialisation as either random or by the LPTF rule, respectively).

The four buttons labelled Steps 1-4 then have to be selected (in that order) to solve an instance of the PMCPSP. On selection of the Step 1 button, the user is presented with the input matrix in Figure 2 where the speeds (in kg/min) and cartridge magazine sizes of the printers can be specified. The number of printer columns in this matrix corresponds to the number of printers specified by the user in the initialisation window.
On selection of the Step 2 button, the user is presented with the job set input matrix shown in Figure 3. In this matrix, each job must be assigned a number or unique identifier, and be associated with a string of characters representing colours required for the job as well as the print volume of the job (in kg).

Once all the input data have been provided by the user, the Step 3 button may be selected. The specified solution procedure is then launched, yielding an approximate solution in a print schedule output window, as shown in Figure 4. The columns of this output window contain the jobs to be sequenced (in that order) on the various printers.
Associated printing-schedule performance-measure statistics - such as the total processing time of jobs assigned to each machine, the number of ink cartridges that have to be washed for each machine, the total set-up time incurred on each machine, and the completion time of each machine - are also returned in a final results window, as shown in Figure 5.
Although the user is also able to specify algorithmic parameters (such as the number of iterations Imax and tabu tenure τfor the tabu search, or the cooling parameter β, and the number of moves to be attempted L and/or accepted Aminduring each temperature stage of the method of simulated annealing), it is not necessary here to set out in detail how this is done in the DSS.
6 REALISTIC CASE STUDY
In this section we apply the DSS of Section 5 to a case study involving real PMCPSP data obtained from a printing company in the Western Cape Province of South Africa to demonstrate the practical workability of our approximate solution approaches to realistic instances of the problem.
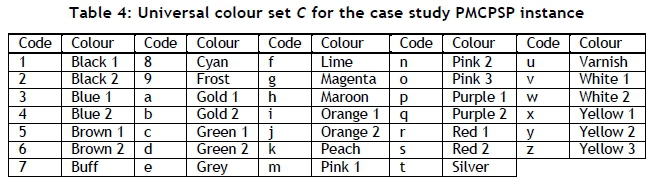
An industrial data set comprising 149 printing jobs - each requiring (at most) eight colours from a universal colour set containing the 34 colours in Table 4 - was obtained. This data set is shown in Table 5.
The printing company has five high-speed printers at its disposal: one that can accommodate eight colours simultaneously and print at a speed of 5.833 kg/min, two that can each accommodate six colours simultaneously and print at a speed of 4.722 kg/min, and two that can each accommodate four colours simultaneously and print at a speed of 3.514 kg/min. The fastest of these machines may be seen in Figure 6. It takes approximately a = 30 minutes to empty, wash, and refill a single ink cartridge. At the time of initiating this research project, the company made no attempt to schedule print jobs in advance. Instead, jobs were processed in the order in which they were received from customers. We were informed, however, that - since they battled to balance the workload of machines and thought that they were incurring excessively large set-up times due to the essentially random sequencing of jobs on the five printers - the company wished, in future, to schedule print jobs in advance on a weekly basis. The reason for this was that the rate at which they received orders for print jobs would justify a weekly schedule.

We were informed that supervisors operating the printers worked in around-the-clock shifts from Monday to Saturday (hence a work week of 24 χ 6 = 144 hours = 8640 minutes, which is, therefore, an upper bound on the makespan of a feasible weekly printing schedule), and that a separate work crew performed maintenance on the printers on a Sunday.
We solved this instance of the PMCPSP (approximately) using the DSS described in Section 5, selecting simulated annealing (with parameter values as described in Section 3.4) and random initialisation as our solution methodology combination, based on the superior performance of this combination observed in the results of Section 4.
The search was initiated with a random solution exhibiting a makespan of 16053 minutes ≈ 11.15 days, and ran for 39572 seconds ≈ 11 hours (just over 900000 iterations) before reaching a state of thermal equilibrium. The progression of the various schedule makespans over the course of the search is shown in Figure 7. The incumbent solution, shown in Table 6, has a makespan of 8371 minutes ≈ 5.8 days, which is comfortably within the 6-day feasibility limit for a one-week schedule.
7 CONCLUSION AND APPLICATION EXTENSIONS
A scheduling problem from the colour printing industry was considered in this paper. The problem, here called the parallel machine colour print scheduling problem, is to find an optimal assignment of print jobs to each of a set of colour printers, and a processing sequence for the set of jobs assigned to each printer. The objective is to minimise the makespan of the schedule to achieve a suitable balance between the workloads of the printers and the efficiencies of the job sequences assigned to the printers. A novel aspect of the problem is the way in which the printer set-up times associated with the jobs are job sequence-dependent: it is possible to exploit commonalities between the colours required for successive jobs on each machine.
Any PMCPSP model is, however, rich in application possibilities, in the sense that it admits a large variety of applications that, when first encountered, seem to be vastly different from decisions related to colour print scheduling. We mention four such application extensions in closing, but many others may also be found in the literature on flexible manufacturing systems.
An alternative application that fits naturally into the modelling framework of this paper is the problem of mailroom insert planning [1]. In this application, a number of lines of feeders are used to insert various pre-determined sets of distinct advertising brochures into envelopes destined for various categories of clients. Since each client category requires a different subset of brochures in their envelopes, the problem can be modelled as an instance of the PMCPSP in which each client required subset of brochures corresponds to a print job, each brochure corresponds to a different ink colour, each line of feeders corresponds to a printer, and each individual brochure feeder corresponds to an ink cartridge. Each brochure type change incurs a constant set-up time that is required to empty, clean, and reload a feeder; but if a brochure required for a specific client category were also required for the previous client category processed on a particular line of feeders, then the above set-up time could be avoided for that brochure. This gives rise to the same type of sequence-dependent set-up times that was encountered in the PMCPSP.
A further application alternative is encountered in a pharmaceutical packaging facility [10,13] where different types of pills are bundled together into patient- or region-specific boxes by flexible packaging units. Different types of pills are stored in containers and can be hooked up to the feeding holes of a packaging unit. The different pill combinations required by the patient types or regions correspond to a print job of the PMCPSP, each type of pill corresponds to a different ink colour, each packaging unit corresponds to a printer, and each individual pill container corresponds to an ink cartridge. There is an advantage to be gained in saved set-up time if two consecutively-processed pill combinations share the same type of constituent pill: this gives rise to a multiple-machine scheduling problem with sequence-dependent set-up times for which the models considered in this paper are applicable.
Our next example of an alternative application of PMCPSP models occurs in the assembly of printed circuit boards (PCBs) [16]. Flexible component placement machines are used to mount various electronic components, stored in large containers, on to a bare PCB. These machines typically contain a number of task-specific tools in a magazine. Since the machines are highly automated, configurable, and suitable for the assembly of a wide variety of PCB product types, the problem can be modelled as an instance of the PMCPSP in which each PCB product corresponds to a print job of the PMCPSP, each type of electronic component corresponds to a different ink colour, each component placement machine corresponds to a printer, and each electronic component container corresponds to an ink cartridge. In this context, the problem is known as the Tool Switching Problem, and again, the exploitation of tool commonality requirements for consecutive jobs is a central feature of the application.
As a last application extension, we mention a scheduling problem in the chemical manufacturing industry where various chemicals, each consisting of a particular set of constituents, are produced by feeding these constituents from containers to a number of mixing and reaction chambers via supply pipes [10,13]. Set-up cost is incurred by retooling and cleaning a pipe whenever a chemical constituent is changed. Here the various constituent combinations required for a specific chemical correspond to a print job of the PMCPSP, each constituent corresponds to a different ink colour, each mixing and reaction chamber corresponds to a printer, and each constituent container corresponds to an ink cartridge. In this case, the sequence-dependent set-up times between jobs are incurred as a result of having to fit new constituent containers and having to clean the feeding pipes. PMCPSP models are clearly also applicable in this case.
The three metaheuristics (a local improving search, a tabu search, and simulated annealing) designed, implemented, and tested in this paper for their ability to uncover high-quality (approximate) solutions to small instances of the PMCPSP are therefore also applicable to the application extensions mentioned above. It was found that the method of simulated annealing is the best of the three approximate solution approaches. An automated decision support tool for solving the PMCPSP approximately was also designed and implemented in Microsoft Excel [12]. This tool uses all three of the above metaheuristics to find good approximate solutions to the scheduling problem. Finally, it was demonstrated that the decision support tool developed here is capable of uncovering high-quality solutions to industrial-size instances of the PMCPSP. Although the local search metaheuristics were able to uncover satisfactory solutions to the problem instances considered in this paper, it would be interesting to investigate whether superior solutions might be uncovered for even larger problem instances by incorporating population-based metaheuristics (such as a genetic algorithm or a particle swarm optimisation algorithm), or purpose-built heuristics within a branch-and-bound scheme, or a dynamic programming solution approach in the DSS.
REFERENCES
[1] Adjiashvili, D., Bosio, S. & Zemmer, K. 2015. Minimizing the number of switch instances on a flexible machine in polynomial time, Operations Research Letters, 43(3), pp 317-322. [ Links ]
[2] Avalos-Rosales, O., Alvarez, A.M. & Angel-Bello, F. 2013. A reformulation for the problem of scheduling unrelated parallel machines with sequence and machine dependent setup times, Proceedings of the Twenty-Third International Conference on Automated Planning and Scheduling, pp 278-282. [ Links ]
[3] Bruckner, P. 2007. Scheduling algorithms, 5th edition, Springer. [ Links ]
[4] Busetti, F. 2003. Simulated annealing overview. Online reference available at: http://www.cs.ubbcluj.ro/-csatol/mestint/pdfs/Busetti_Annealingintro.pdf [ Links ]
[5] Dreo, J., Petrowski, A., Siarry, P. & Taillard, E. 2006. Metaheuristics for hard optimization: Methods and case studies, Springer. [ Links ]
[6] Gray, A.E., Seidmann A. & Stecke, K.E. 1993. A synthesis of decision models for tool management in automated manufacturing, Management Science, 39, pp 549-567. [ Links ]
[7] Glover, F. 1986. Future paths for integer programming and links to artificial intelligence, Computers & Operations Research, 13, pp 533-549. [ Links ]
[8] Helal, M., Rabadi, G. & Al-Saken, A. 2006. A tabu search algorithm to minimize the makespan for unrelated parallel machines scheduling problem with setup times, Operations Research, 3, pp 182-192. [ Links ]
[9] Kirkpatrick, S., Gelatt, C.D. & Vecchi, M.P. 1983. Optimization by simulated annealing, Science, 220, pp 671-680. [ Links ]
[10] Laarhoven, P. & Zijm, W. 1993. Production preparation and numerical control in PCB assembly, International Journal of Flexible Manufacturing Systems, 5(3), pp 187-207. [ Links ]
[11] Hertz, A., Laporte, G., Mittaz, M. & Stecke K. 1998. Heuristics for minimising tool switches when scheduling part types on a flexible machine, IIE Transactions, 30(8), pp 689-694. [ Links ]
[12] Microsoft Office Products. 2016. Download Center. Online reference available at: https://www.microsoft.com/en-za/download/details.aspx?id=10 [ Links ]
[13] Mütze, T. 2014. Scheduling with few changes, European Journal of Operational Research, 236, pp 37-50. [ Links ]
[14] Oerlemans, A.G. 1992. Production planning for flexible manufacturing systems, PhD Dissertation, University of Limburg, Maastricht. [ Links ]
[15] Pinedo, M. 2002. Scheduling: Theory, algorithms and systems, 2nd edition, Prentice-Hall. [ Links ]
[16] Raduly-Baka, C. & Nevalainen, O.S. 2015. The modular tool switching problem, European Journal of Operational Research, 242, pp 100-106. [ Links ]
[17] Rardin, R. 1998. Optimisation in operations research, Prentice-Hall. [ Links ]
[18] Sistemas de Optimización Aplicada, 2011. Problem instances for unrelated parallel machines with sequence-dependent setup times and makespan criterion. Online reference available at: http://soa.iti.es/problem-instances [ Links ]
Submitted by authors 2 Jan 2015
Accepted for publication 5 Apr 2016
Available online 12 Aug 2016
# Author was enrolled for a B Eng (Industrial) degree in the Department of Industrial Engineering at Stellenbosch University, South Africa
* Corresponding author vuuren@sun.ac.za
APPENDIX: MODEL FORMULATIONS
For the sake of completeness, this appendix contains the mathematical formulations of the 2006 PMCPSP model by Helal et al. [8] and the 2013 PMCPSP model by Avalos-Rosales et al. [2], starting with the earlier formulation.
Let Ωj denote the completion time of job j Є J and define the decision variables

for all i,j Є J0 and k Є M, where J0 = J U {0}. Here the dummy job 0 denotes the empty magazine state of a printer and the variables v0jkand vi0krepresent jobs that are to be processed on printer k Є M at the start and end of the printing schedule, respectively. Similarly, s0jk denotes the set-up time incurred when processing job j e J first on machine k Є M. Then the objective in the PMCPSP formulation of Helal et al. [8] is to

subject to the constraints
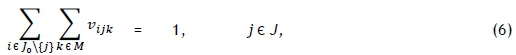
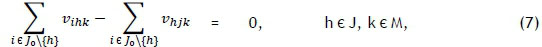
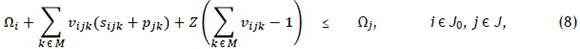
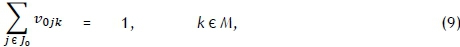



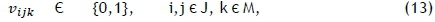
where Z is a large positive constant. The objective in (5) is to minimise the makespan of the schedule. Constraint set (6) ensures that each job is scheduled for processing exactly once, on one machine, while constraint set (7) ensures that each job is neither preceded nor succeeded by more than one other job. Constraint set (8), in which Z is a large positive integer, ensures that the job completion times are calculated correctly as the various jobs follow one another on each machine. Constraint set (9) ensures that exactly one job is scheduled first on each machine, while constraint sets (10)-(12) guarantee that the makespan of the schedule is calculated correctly. Finally, constraint set (13) enforces the binary nature of the decision variables.
In the model formulation (5)-(13), the makespan is linearised as the maximum of the completion times of all the jobs, as specified by constraint set (10). Avalos-Rosales et al. [2] found, however, that the lower bound on Umax produced by the linear relaxation of (5)-(13) is very weak. This prompted them to reformulate the model by linearising the makespan as the maximum of the spans of all the machines. Using the same notation as above, together with the additional symbol <Dk denoting the completion time of printer k Є M, the objective in the model of Avalos-Rosales et al. [2] is again to

but this time subject to the constraints
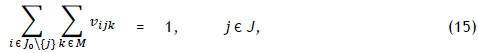
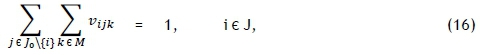
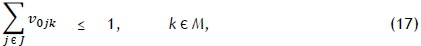
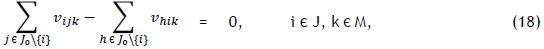
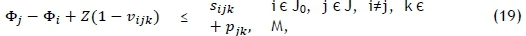

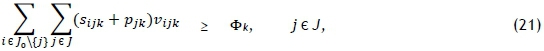

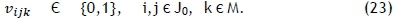
Constraint sets (15) and (16) respectively ensure that each job has exactly one predecessor and one successor. Furthermore, constraint set (17) specifies that at most one job should be scheduled first on each printer, while constraint set (18) embodies a collection of conservation of flow constraints that ensure that if a job is scheduled for processing on some printer, then a predecessor and a successor must exist for that job on the same printer. Constraint set (19) determines the correct processing order by establishing that, if vijk= 1, then the completion time of job j must be greater than the completion time of job i on machine k. Whenever vijk= 0, however, the corresponding constraint in (19) is redundant in view of the magnitude of Z. Constraint set (20) fixes the completion time of the dummy job (job 0) as zero and further serves, in conjunction with constraint set (19), to guarantee that the completion times of all jobs are positive. Constraint set (21) computes the completion time of the last job scheduled for processing on printer k, while constraint set (22) ensures a valid makespan for the schedule.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}