










Servicios Personalizados
Articulo
 Inglés (pdf)
Inglés (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
Indicadores

Links relacionados
-
 Citado por Google
Citado por Google -
 Similares en Google
Similares en Google
Compartir

 Permalink
PermalinkSouth African Journal of Industrial Engineering
versión On-line ISSN 2224-7890
versión impresa ISSN 1012-277X
S. Afr. J. Ind. Eng. vol.24 no.1 Pretoria ene. 2013
Solving a novel multi-skilled project scheduling model by scatter search
H. KazemipoorI, *; R. Tavakkoli-MoghaddamII; P. Shahnazari-ShahrezaeiIII
IDepartment of Industrial Engineering, Firoozkooh Branch, Islamic Azad University,Firoozkooh, Iran. parisa_shahnazari@iaufb.ac.ir
IIDepartment of Industrial Engineering, Parand Branch, Islamic Azad University, Tehran, Iran. h.kazemipoor@piau.ac.ir
IIIDepartment of Industrial Engineering,University of Tehran, Tehran, Iran. tavakoli@ut.ac.ir
ABSTRACT
A multi-skilled project scheduling problem (MSPSP) has generally been presented to schedule information technology projects in deterministic conditions. The contribution of this model is to consider the resources, called 'staff members'. These members are regarded as valuable, renewable, and discrete resources with different multiple skills. The different skills of staff members, as well as the project network's activity requirement of different skills, cause this problem to become a special type of multi-mode resource-constrained project scheduling problem (MM-RCPSP), with a huge number of modes. Taking into account the importance of this issue and the few studies performed on this problem, a novel mathematical model for the MSPSP is presented. Since the complexity of this problem is NP-hard, an efficient scatter search (SS) algorithm is developed to solve such a difficult problem. This proposed SS is capable of generating optimised solutions in small sizes, and the excellent solutions in large sizes are compared with the solutions reported by a proposed Tabu search (TS) algorithm.
OPSOMMING
'n Veeldoel projekskeduleringsvraagstuk (MSPSP) word voorgehou vir skedulering onder deterministiese toestande van inligtingstegnologieprojekte. Die model word aangewend vir hulpbronne genaamd "personeellede". Die bronne is waardevol, hernubaar, diskreet en beskik oor uiteenlopende vaardighede. Die eienskappe van die vraagstuk berus by uiteenlopendheid. Vir die voorafgaande omstandighede word 'n nuwe model geskep vir die hantering van eienaardighede. Aangesien die problem NP-moeilik is, word 'n doeltreffende spreisoek-algoritme gebruik met groot sukses.
1. INTRODUCTION
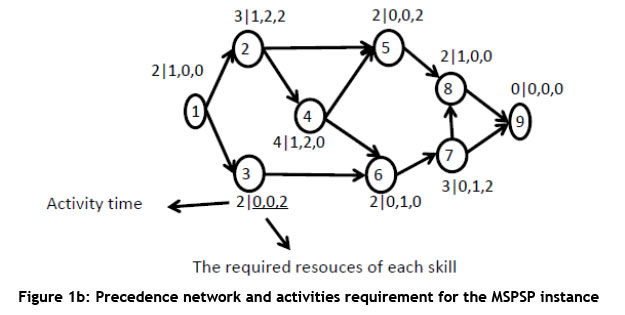
Blazewicz et al. [1] first considered a resource-constrained project scheduling problem (RCPSP) that belongs to the class of NP-hard optimisation problems. The RCPSP is one of the most complicated operations research problems. The way to solve it has been improved considerably through exact and heuristic methods in recent decades, and new optimisation techniques have been employed to solve the problem [2-4]. Recently, a multi-skilled project scheduling problem (MSPSP), which is a fairly new version of a project scheduling problem, has been presented by Neron and Boptista [5]. As a general rule, this problem is an extended model of the multi-mode RCPSP [6]. The main differences between the MSPSP and the MM-RCPSP are in the resources being considered and the type of requirement for each resource. In the MSPSP, the resources are staff members with different skills assigned to the activities of the project. A staff member can be assigned at most to one requirement for a specific time to perform an activity using one required skill. Different combinations of use of these staff members are determined during the project assignment on the basis of the skills required for each activity and the skills of the staff members. To accomplish each activity in any skill, the proper resources are selected from among a set of qualified resources. In other words, if all staff members in the whole project had a single skill, the MSPSP would be the same as a classic RCPSP. According to the expressions mentioned above, and to clarify the MSPSP, a problem with a feasible solution is illustrated in Figures 1(a), 1(b) and 1(c).
The fact that resources can be used to satisfy different requirements has been presented in the definition of job-shop scheduling. As a result, the MSPSP can be regarded as a combination of a classic RCPSP model and multi-process machines (MPM) [7,8]. Taking the related definitions with the given problem into account, and referring to Figure 1, the MSPSP can be classified in the category of the multi-mode RCPSP (MM-RCPSP) [5] with very large modes. In this case, the execution modes of an activity consist of a subset of qualified resources that can be assigned to that activity. Infinite execution modes of this problem originate from the different skill of each resource. As shown in the example in Figure 1, activity 2 can be executed by resources (i.e., R1, R2, R3, R6) in skill 1, by resources (i.e., R1, R3, R5) in skill 2, and by resources (i.e., R1, R2, R4, R6) in skill 3. So activity 2 can be executed in 48 different modes. If the entire network is investigated, the number of execution modes for activities will be huge. Hence, the MSPSP is a type of the MM-RCPSP with huge modes to execute each activity. This means that the MSPSp cannot be solved even in medium sizes by the presented solution methods for the MM-RCPSP, which are often based on the enumeration [5]. Taking these facts into consideration, new techniques have been proposed to solve this type of problem [9]. In general, three classes of solution methods have been developed to solve these problems: lower bound, branch-and-bound, and heuristic and meta-heuristic methods.
Bellenguez-Morineau [10] summarised some proposed methods. Another example in this direction is the work carried out by Kadro and Najid [11]. They extended a solution method by Tabu search, accompanied by strong local search, for a manpower constrained MM-RCPSP class. In order to exhibit the strength of the algorithm, they also found a lower bound for the problem and compared the generated solutions with this bound. Another example of research on solving a manpower scheduling problem in projects is that done by Valls et al. [12]. They recommended a hybrid genetic algorithm (GA) to solve a skilled manpower scheduling problem in computer centres. Heimerl and Kolisch [13] proposed a mixed-integer linear programming (MILP) model with hard constraints in order to minimise the manpower cost, considering the in-source and out-source manpower, for an information technology projects portfolio. Gutjahr et al. [14] took a project portfolio into account and introduced a non-linear MIP model on the basis of maximising the average economic income for selecting the projects, optimising the time, and assigning the persons to selected projects. They presented a heuristic process that included two components of a greedy heuristic algorithm to schedule and assign the persons, and a meta-heuristic algorithm to choose the project. Then they compared the obtained solutions with the bounds acquired by the exact solution of the simplified mathematical model, and proved the efficiency of their method. The MSPSP can have various applications, such as manpower scheduling in preventive maintenance. Since preventive maintenance is performed with human skills in the form of a project, Pessan [15] formulated it as an MSPSP. A significant point in these problems is the objective function. In most studies done in this area, the objective is to provide a schedule in order to minimise the project execution time [5,11]. Some researchers have also taken account of personnel costs in their model. Li and Womer [30] defined the minimum cost for staff members as an objective function. Heimerl and Kolisch [13] and Gutjahr et al. [14] entered these costs in the MSPSP in special cases as well.
This paper has been organised as follows. Section 2 deals with a novel mathematical model, the simplified model, the parameters used, and the decision variables. An efficient scatter search algorithm to solve the problem, and an elite Tabu search algorithm to compare the results, are presented in Section 3. Section 4 is allotted to computational results. Section 5 presents concluding remarks.
2. PRESENTING A NOVEL MATHEMATICAL MODEL FOR MSPSP
In the mathematical model for the MM-RCPSPs, two types of formulations are applied: sequence-based models, and time index formulation [9]. In this paper, the formulation is done with sequence-based models for the MSPSP. In this section, indices, parameters, and decision variables are presented first, and then the objective function and constraints of the mathematical model for developing the MSPSP are considered. Since this model is inspired by a real situation, the initial model is a mixed-nonlinear one that is converted to a linear model at the end of this section. It should be noted the network in question is defined as 'activity on node' (AON).
2.1 Indices
i, f : Activities counters (1,...,n)
k, k': Skills counters (1,...,K)
m,m : Resources counters (1,...,M)
2.2 Parameters and sets
A = {A1,..., An}: Non-preemptive executive activities set
S = {S1,...,SK}: Set of the existing skills for running the project
R = {R,...,Rm}: Resources set (staff members)
G : Precedence relations graph for the project
pi: Time of executing the activity Ai
bik: Number of required resources for doing skill Sk during the execution of activity Ai
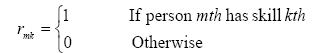
2.3 Decision variables
Two decision variables in this model are defined as follows:
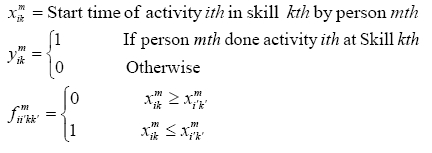
2.4 Novel linear mathematical model
Regarding the above-mentioned cases, a mathematical model for the MSPSP that is inspired by a real situation is presented below.
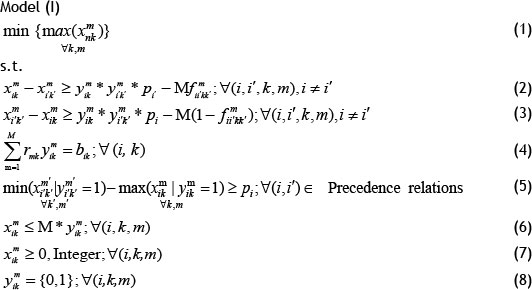
In the MSPSP, the objective function can be considered as the minimisation of the greatest start time of the last activity for different skills. Therefore, the finish time of the last activity will be minimised. Equation (1) describes this. One of the fundamental constraints in the MSPSP is the non-preemptive allocation of resources to the activities' skills. This constraint is expressed so that if a resource allocates to an activity at a special skill, this resource cannot be employed for another activity until it has finished the current activity. Eqs. (2)-(3) guarantee this constraint. It should be noted that M in Eqs. (2) and (3) shows big-M in big-M method [16]. The required amount of each activity at any skill is equal to bk
in terms of a resource per day that should be guaranteed for each activity at any skill until finishing the activity time at different skills. Eq. (4) accompanied by Eqs. (2) and (3) provides this constraint. Execution of each project activity involves taking account of the precedence network. In a precedence network, the succeeding activity can be started when all preceding activities of this activity have been finished at all skills. Eq. (5) takes this matter into account. It should be mentioned that the first and last activity in the precedence network are generally the starting and ending activities, which are sometimes defined as virtual activities. An activity in each skill can be started when enough resources are allocated to it. Eq. (6) expresses this constraint. In this equation, M is also big-M. Finally, Eqs. (7) and (8) explain the type of decision variables in the mathematical model. As seen, Model (I) is nonlinear. Using the property below from the operations research science [16], Model (I) can be converted to a linear model.
Property 1:
The objective function of Model (I) can take the linear form as follows:

Proof:
In this part, the standard linearisation methods of mathematical models [17] are applied. In fact, if 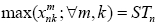 is defined, we have.
is defined, we have. 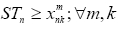 In this manner, the objective function will become linear.
In this manner, the objective function will become linear.
Property 2:
Eq. (5) is rewritten as follows:
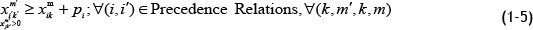
Proof:
It is obvious that: 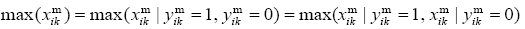
By considering Eq. (6), if 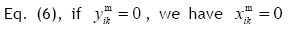
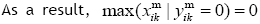
Thus:
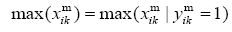
Consequently, we have:
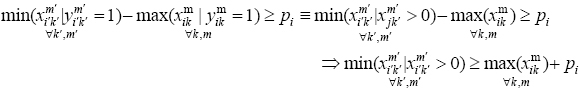
Now, the abovementioned equation can be easily rewritten as:
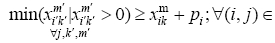 Precedence relations,
Precedence relations, 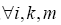
Regarding the above equation, the minimum of 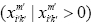 should be greater than
should be greater than 
Hence, the entire amounts of 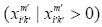 will be greater than
will be greater than 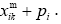 and:
and:
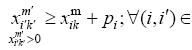 Precedence relations,
Precedence relations, 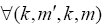
Property 3:
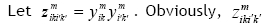 is a new 0-1 variable which is dependent on
is a new 0-1 variable which is dependent on 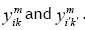
It can be proved that Eqs. (2) and (3) are converted to linear equations by changing and adding Eqs. (10)-(12):
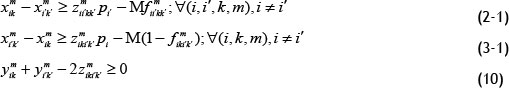

Proof:
Assuming that Eqs. (2) and (3) are equal to Eqs. (2-1) and (3-1), 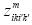 should be equal to 0, when
should be equal to 0, when 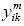 and
and 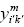 are 0 or alternatively are 0 and 1; else 1. It is clear that, when
are 0 or alternatively are 0 and 1; else 1. It is clear that, when 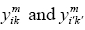 are 0 or alternatively are 0 and 1,
are 0 or alternatively are 0 and 1, 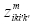 will get 0 in respect with Eqs. (10) and (12), and Eq. (11) will be redundant. In other words, if
will get 0 in respect with Eqs. (10) and (12), and Eq. (11) will be redundant. In other words, if 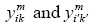 are equal to 1,
are equal to 1,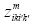 will get 1 with regard to Eqs. (9) to (11). Something like this proof,with minor changes, has been propounded in the quadratic assignment problem (QAP) [18].
will get 1 with regard to Eqs. (9) to (11). Something like this proof,with minor changes, has been propounded in the quadratic assignment problem (QAP) [18].
Thus the NLMIP (i.e., Model (I)) is converted to the LMIP (i.e., Model (II)) including Eqs. (11), (2-1), (3-1), (4), (5-1), and (6) to (13). Although this simplification makes the model more efficient, Model (II) is also placed on the class of NP-Hard problems and cannot be solved in the real sizes at a limited time. As a result, the scatter search and Tabu search algorithms are used to solve the model in large sizes. In the next part of this paper, the details of the proposed methods are presented.
3. TWO META-HEURISTICS
3.1 Proposed scatter search
Scatter search (SS), which is one of the evolution methods to solve NP-hard problems, was first presented by Glover [19] to solve integer programming problems. Afterwards, Glover [20-22] examined different aspects of the scatter search algorithm and compared it with the genetic algorithm. In the original proposal, Glover explained scatter search as a method that uses a succession of coordinated initialisations to generate solutions. He introduced the reference set (RefSet) of solutions and several guidelines - including that the search occurs in a systematic way, as opposed to the random designs of other methods (such as GAs). The approach was conceived to begin by identifying a convex combination of the reference points. This central point, together with subsets of the initial reference points, was then used to define new sub-regions. Consequently, analogous central points of the sub-regions were examined in a logical sequence. At the end, these latter points were rounded (in a broad sense, depending on the solution representation) to acquire the desired solutions.
The general pattern of this method is used for the majority of the SS executions. There are five general stages in the main pattern of SS [23,24]: generation of various solutions, improving the generated solutions, generation of a reference set, the method of choosing subsets from the reference set, and the subsets' solutions combination method. In this paper, the proposed SS is designed on the basis of the five above-mentioned stages to solve the MSPSP in accordance with Figure 2. Then the details of Figure2 are described as follows.
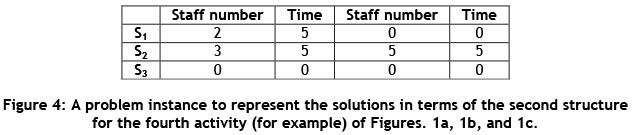
In this paper, two structures are used to represent the solutions obtained by the proposed algorithms. The first structure, which is used to represent the order in which the activities are completed, is a one-dimensional matrix. The second structure is a three-dimensional matrix that indicates the allocation and start time of the required skills of all project activities in the MSPSP. In this matrix, the number of rows is equal to the number of all the required skills for the project; each column expresses the assigned resource's number to each skill and its start time; and the third dimension of the matrix represents each activity's number. The first and second structures are shown in Figures3 and 4, based on Figures 1a, 1b, and 1c.
In fact, Figure 3 is a representation method for a feasible sequence of the completion of the project activities in Figure 1.b, which has been previously shown in Figure 1.c. In addition, Figure4 illustrates the representation method of allocation and the start time of the required skills of the fourth activity in Figure 1 .b, which can also be seen in Figure 1 .c. In other words, in accordance with Figure 4, the second resource (staff member with number 2) has been assigned to the first skill of the fourth activity at time 5, and the third and fifth resources (staff members with numbers 3 and 5) have been assigned to the second skill of the fourth activity at time 5. As Figure 1.b shows, this activity does not require the third skill to be completed.
3.1.2 Generation of initial solutions
In this research, the initial solutions were firstly generated by stochastic procedures. After evaluating the quality of the generated initial solutions, it was specified that they are not acceptable for use. Hence, a bi-directional scheduling generation scheme [25] is used to generate initial solutions. In this method, a forward and backward partial scheduling is regarded simultaneously; and at any iteration, an activity can be scheduled when it is just schedulable in one direction. In this process, three sets of activities are defined: 1) the set of activities whose precedent activities have been scheduled (ready for forward scheduling); 2) the set of activities whose succeeding activities have been scheduled (ready for backward scheduling); and 3) the set of activities whose precedent and succeeding activities have been scheduled (ready for forward and backward scheduling). At any iteration, the activities that are forward schedulable are transferred to set1, the activities that are backward schedulable are transferred to set 2, and the activities that are both forward and backward schedulable are transferred to set3 and removed from sets 1 and 2. After defining the sets, an activity is selected randomly from set1, and in one of the random possible modes is scheduled at the earliest time and removed from the related set; and then all sets are updated. In set 2 too, an activity is selected randomly and a random possible mode is assigned to it; and it is scheduled at the latest time on the condition that it does not violate the precedence activities and resources. This activity is removed from set 2, and then all sets are updated. This process is continued until no activity is schedulable in one direction. In this case, just the activities of set 3 have not been scheduled. The activities of set 3 are also selected randomly, and are scheduled in random directions byassigning random possible modes to them. Afterwards set 3 is updated. This process is continued until all activities of set 3 are assigned. At present, two lists of forward and backward scheduling are provided. Thereafter, to determine the final scheduling list, the activities of set 2 are added to set 1 ,in the reverse order of selecting them.
3.1.3 Diversification method for the current solution
In this paper, each existing solution is entered into the diversification method, and is scattered by the multi-start Tabu search method as much as is possible, according to Figure 5.
The move procedure and Tabu list are described as follows:
- Move procedure: In this procedure, two indices of activities that can be started simultaneously are selected randomly and displaced according to the precedence relations. The resources assignment to the relevant skills of these activities are also changed randomly by checking the feasibility conditions.
- Tabu list: The abovementioned move procedure employs an intelligent TS strategy, based on avoiding a return to the solutions just visited, using an adaptive memory that is called a Tabu list. This Tabu list depends on the search direction and avoids repeating a move in the Tabu tenure. For example, if an obtained solution is accepted in a move, the move of the two mentioned points is added to the Tabu list. The forbidden moves remain inthe list in the Tabu tenure, and then exit the list.
3.1.4 Solutions improvement procedure
According to Figure 6, two parallel move procedures are used in order to improve the quality of the solutions.
Structures 1 and 2 are explained as follows:
- Move structure 1: This structure is the same as the move approach in the solutions diversification procedure.
- Move structure 2: Index a is generated randomly in the interval [1,.., n-1] (n is the number of activities). B is the index of the first preceding activity existing in the ath cell, and c is the index of the last precedence activity existing in the ath cell index d is also generated randomly in the interval [b,...., c].
○ If d<a, the activity existing in the ath cell is inserted in the dth cell.
○ If d>a, the activity existing in the ath cell is inserted in the (d-1)th cell.
3.1.5 Updating the reference set
The reference set is formed of two subsets, Refset1 (the solutions of quality) and Refset2 (diversified solutions). The maximum capacity of these subsets is b1 and b2 respectively. In other words, | refset |= b 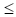 b1 + b2. To make the reference set, the subset Refset1 is first formed. To do this, at most b1 non-repetitive solutions are selected from among the best solutions and added to Refset1. Among the remaining solutions, b2 non-repetitive solutions with the maximum Euclidean distance1 from Refset1 are selected and added to Refset2.
b1 + b2. To make the reference set, the subset Refset1 is first formed. To do this, at most b1 non-repetitive solutions are selected from among the best solutions and added to Refset1. Among the remaining solutions, b2 non-repetitive solutions with the maximum Euclidean distance1 from Refset1 are selected and added to Refset2.
3.1.6 Formation of the subsets
In this section, the subsets are formed from the solutions of the reference set in order to combine the solutions and generate the new ones. Hence, three types of pair subsets (S1, S2, S3) are formed from the solutions of the reference set:
- S1: All pair subsets of Refset1 that have at most b1 -1 members.
- S2: All pair subsets of Refset2 that have at most b2 -1 members.
- S3: A pair subset including Refset1 and Refset2 solutions whose members are made as succeeding. The first element of S3 is each member of Refset1 that is selected in order. The second element is also one of the members of Refset2 that has the greatest euclidean distance from the first selected element. This subset contains b1members.
3.1.7 Subsets combination method
In this paper, a single-point crossover operator is used to combine each generated subset with the SS algorithm. The first and second members of each generated subset in the previous section are considered as parent1 and parent2. To generate offspring, one index i is generated randomly in the interval [1...n] (n is the number of activities) at first, and from the first to the ith cell of parent1 is assigned to the first to the ith cell of offspring1. The rest of the sequence of offspring1 is obtained from parent2 in the order of their appearance in this parent, for the activities that have not yet been selected in offspring1. Like offspring1, offspring2 is also generated by displacing the parents.
3.2 Tabu search (TS)
The Tabu search was first developed by Glover [26]. In his ongoing research, Glover [27,28] explained the details of the TS algorithm. TS and Simulated Annealing (SA) algorithms have in common the fact that they guide the applied local search algorithm to avoid bad and low quality local optimum solutions by creating a Tabu list and supervising the examined solutions. A Tabu list stores the characteristics of examined solutions and prevents their being re-examined. Although the TS algorithm permits moves that make the objective function worse, in spite of the SA algorithm, it uses an exact acceptance criterion rather than a probable one. The TS chooses these moves around a corrected neighborhood structure. While running the algorithm, and based on the Tabu list, the neighborhoods are corrected and improved and lead to new neighborhoodsthat are in fact the original ones that have been improved. The improved neighborhoods can give rise to better solutions. The Tabu list has a size, and can store a determined number of characteristics. These characteristics are stored in the Tabu list according to the 'earliest in / earliest out' system. Therefore, characteristics are added to the beginning of the Tabu list and exit from the end of it (finishing the Tabu tenure) [28]. In order to investigate the quality of the solutions generated by the proposed SS, the MSPSP is also solved by using the TS algorithm [29], as in Figure 7:
The details of Figure 7 can be described as follows:
- Initial solution: In order to generate an initial solution, the same procedure used in the SS algorithm is employed.
- Move procedure: To compare the SS and TS algorithms, the move structures1 and 2 in the improvement procedure of SS are applied for the neighborhood operator of the TS algorithm. In this procedure, an intelligent TS strategy based on avoiding a return to generated solutions in the previous iterations is used by an adaptive memory called the Tabu list.
- Tabu list: The Tabu list depends on the search direction, and avoids the repetition of a move in the Tabu tenure. For instance, if index/ is generated in a move and the obtained solution is accepted, its change move is added to the list. The forbidden moves remain in the list in the Tabu tenure, and after finishing Tabu tenure they exit the list.
○ Search direction: In order to determine the acceptance criterion of a new solution, the variable η is expressed by: 
where/4 is the current solution and B is a solution that has been generated by the TS method and by applying the move procedure. Therefore, the acceptance criterion is as given in one of the cases illustrated in Figure 8.

4. COMPUTATIONAL RESULTS
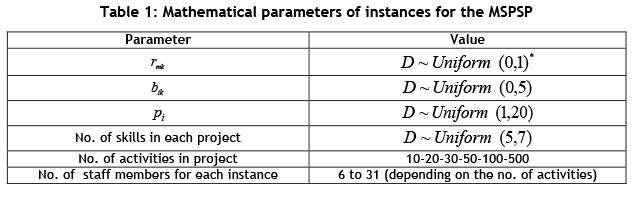
Since there is no special problem instance in the field of the MSPSP [6,9,12], some reasonable instances are generated randomly with a different number of activities and features,as listed in Table 1.
In order to analyse the developed algorithms further, the problem is solved in small stepsby the Lingo 9 software to find the exact solution. It should be noted that, in order to determine the parameters of the proposed algorithms, a trial and error method has been used in this paper. These parameters have been chosen so that the solutions acquired by the proposed algorithms are veryclose to the optimum solutions of the mathematical model for small-sized problems. These parameters are shown in Table 2. In this paper, the MSPSP is coded by the Matlab R2009a software, and all computational experiments are run on a Pentium 4 PC with 4 GB of memory and 2.20 GHz of CPU. The results of the small-sized problem after ten executions (in second) are shown in Table 3.
As shown in Table 2, the exact solution of the mathematical model takes a long time to produce the optimised solutions in small sizes. The proposed SS produces the same results, but taking less time than Lingo 9. The proposed TS achieves feasible solutions in very short times, which can be considered as an upper bound to solve the given problem. The results of Table 2 show that the designed SS algorithm produces excellent solutions.
It should be mentioned that the model presented in this paper defines the variables and parameters from a different point of view, despite the approach of other papers [6, 13, 15, and 30]; and that the defined problem has many parameters. Note that, there is a final answer in all existing papers. These matters make it impossible to draw any exact comparisons among the existing papers.
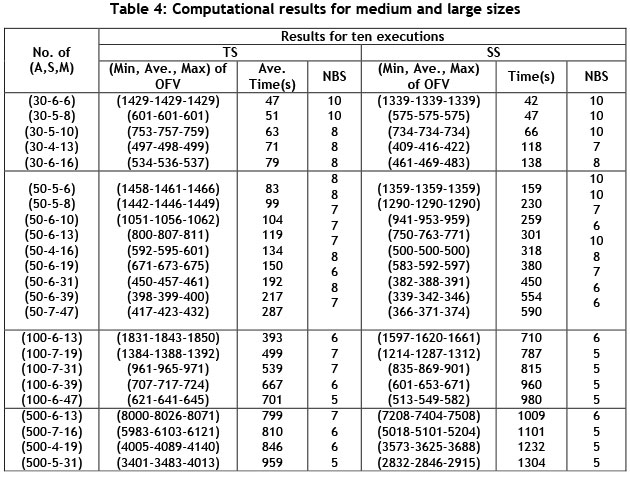
In connection with these comments, the problem in larger and more real sizes is presented in Table 4. In fact, excellent procedures have been created to solve the MSPSP in the real sizes by mathematical programming, and by exact and meta-heuristic solutions in this paper.
5. CONCLUSION
In many projects (such as information technology projects, research projects, engineering activities, preventive maintenance activities, and the like) staff members should be assigned to project activities in accordance with their skills and taking into consideration the precedence network of projects. As mentioned before, this problem has become well-known as the multi-skilled project scheduling problem (MSPSP). Since the MSPSP is a special type of the multi-mode resource-constrained project scheduling problem (MM-RCPSP) with infinite modes, which has received less attention from researchers, a novel linear mixed-integer programming (LMIP) model has been presented for the MSPSP in this paper, and solved by an efficient scatter search (SS) algorithm. To verify the efficiency of the proposed SS, the generated random problems have been compared with the optimised solutions obtained by the Lingo 9 software in small sizes, and with the solutions obtained by the proposed elite Tabu search (TS) algorithm in medium and large sizes.
REFERENCES
[1] Blazewicz, J., Lenstra, J.K. & Rinnooy Kan, A.H.G. 1983. Scheduling subject to resource constraints: Classification and complexity, Discrefe Applied Mafhemafics, 5, pp 11-24. [ Links ]
[2] Herroelen, W. & Leus, R. 2005. Project scheduling under uncertainty: Survey and research potentials, European Journal of Operafional Research, 165, pp 289-306. [ Links ]
[3] Hartmann, S. & Briskorn, D. 2010. A survey of variants and extensions of the resource-constrained project scheduling problem, European Journal of Operafional Research, 207, pp 1-14. [ Links ]
[4] Demeulemeester, E.L. & Herroelen, W.S. 2002. Projecf scheduling: A research handbook, Kluwer Academic Publisher. [ Links ]
[5] Neron, E. & Boptista, D. 2002. Heuristics for the multi-skill project scheduling problem, Infernafional Symposium on Combinaforial Opfimizafion, Paris. [ Links ]
[6] Bellenguez-Morineau, O. & Neron, E. 2005. Lower bounds for the multi-skill project scheduling problem with hierarchical levels of skills, in: E.K. Burke and M. Trick, eds, Practice and theory of automated timetabling, Lecfure Nofes in Compufer Science, Vol. 3616, Springer-Verlag, pp 229243. [ Links ]
[7] Dauzere-Peres, S., Roux, W. & Lassere, J.B. 1996. Multi-resource shop scheduling with resource flexibility, European Journal of Operafion Research, 107, pp 289-305. [ Links ]
[8] Jurish, B. 1992. Scheduling jobs in shops with multi-purpose machines, PhD Thesis, University of Osnabruck, Germany. [ Links ]
[9] Artigues, C., Demassey, S. & Neron, E. 2008. Resource consfrainf projecf scheduling problem, John Wiley and Sons. [ Links ]
[10] Bellenguez-Morineau, O. 2008. Methods to solve multi-skill project scheduling problem, 4OR, 6, pp 85-88. [ Links ]
[11] Kadrou, Y. & Najid, N.M. 2006. Tabu search algorithm for the MRCPSP with multi-skilled personnel, Compufafional Engineering in Sysfem Applicafion, IMACS Mulfi Conference, Vol. 2(4-6), pp 1302-1309. [ Links ]
[12] Valls, V., Perez, A. & Quintanilla, S. 2009. Skilled workforce scheduling in service centres, European Journal of Operafional Research, 193, pp 791-804. [ Links ]
[13] Heimerl, C. & Kolisch, R. 2009. Scheduling and staffing multiple projects with a multi-skilled workforce, OR Specfrum, 32 (2), pp 343-368. [ Links ]
[14] Gutjahr, W.J., Katzensteiner, S., Raiter, P., Stummer, C. & Denk, M. 2008. Competence-driven project portfolio selection scheduling and staff assignment, Central European Journal of Operation Research, 16, pp 281-306. [ Links ]
[15] Pessan, C., Bellenguez-Morineau, O. & Neron, E. 2007. Multi-skill project scheduling problem and total preventive maintenance, MultidisciplinaryInt. Conf. onScheduling: Theory and Applications (MISTA), pp 608-610. [ Links ]
[16] Taha, H.A. 2011. Operations research: An introduction, Prentice Hall, 9th edition. [ Links ]
[17] Bazaraa, M.S. & Sheraly, H.D. 1993. Nonlinear programming, 2nd edition, John Wiley and Sons. [ Links ]
[18] Lawler, E.L. 1963. The quadratic assignment problem, Management Science, 9, pp 586-599. [ Links ]
[19] Glover, F. 1977. Heuristics for integer programming usingsurrogate constraints, Decision Sciences, 8, pp 156-166. [ Links ]
[20] Glover, F. 1994. Genetic algorithms and Scatter Search: Unsuspected potentials, Statistics and Computing, 4, pp 131-140. [ Links ]
[21] Glover, F. 1994. Tabu Search for nonlinear and parametric optimization (with links to genetic algorithms), Discrete Applied Mathematics, 49, pp 231-255. [ Links ]
[22] Glover, F. 1995. Scatter Search and star paths: Beyond the genetic metaphor, OR Spektrum, 17, pp 125-137. [ Links ]
[23] Glover, F. 1998. A template for scatter search and path relinking, in: J.K. Hao, E. Lutton, E. Ronald, D. Snyers (eds), Lecture Notes in Computer Science, 1363, Springer, pp 13-54. [ Links ]
[24] Laguna, M. 2002. Scatter Search,in: P.M. Pardalos& M.G.C. Resende (eds), Handbook of applied optimization, Oxford University Press. [ Links ]
[25] Seifi, M. &Tavakkoli-Moghaddam, R. 2008. A new bi-objective model for a multi-mode resource-constrained project scheduling problem with discounted cash flows and four payment models, Int. J. of Engineering, Transaction A: Basic, 21(4), pp 347-360. [ Links ]
[26] Glover, F. 1986. Future paths for integer programming and links to artificial intelligence, Computer and Operations Research, 13(5), pp 533-549. [ Links ]
[27] Glover, F. 1989. Tabu search-Part I, INFORMS Journal on Computing, 1 (3), pp 190-206. [ Links ]
[28] Glover, F. 1989. Tabu search-Part II, INFORMS Journal on Computing, 2 (1), pp 4-32. [ Links ]
[29] Tavakkoli-Moghaddam, R., Azarkish, M. & Sadeghnejad, A. 2010. Solving a multi-objective job shop scheduling problem with sequence-dependent setup times by a Pareto archive PsO combined with genetic operators and VNS, Int. J. of Advanced Manufacturing Technology, Article in Press, DOI:10.1007/s00170-010-2847-4. [ Links ]
[30] Li, H. & Womer, K. 2009. Scheduling projects with multi-skilled personnel by a hybrid MILP/CP benders decomposition algorithm, Journal of Scheduling, 12 (3), pp 281-298. [ Links ]
* Corresponding author
1 The Euclidean distance between two points p and q is the length of the line segment connecting them.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}