Serviços Personalizados
Artigo
 Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
Indicadores

Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkLexikos
versão On-line ISSN 2224-0039
versão impressa ISSN 1684-4904
Lexikos vol.32 Stellenbosch 2022
http://dx.doi.org/10.5788/32-1-1727
ARTICLES
The Influence of Grammatical Gender on the Sequence of Near-synonyms in Serbian Dictionaries in Contrast to English Thesauri
Die invloed van grammatikale gender op die opeenvolging van ampersinonieme in Serwiese woordeboeke in teenstelling met Engelse tesourusse
Dragana Carapic
Faculty of Philology, University of Montenegro, Niksic, Montenegro (draganac@ucg.ac.me)
ABSTRACT
It has been noticed that Serbian dictionaries of synonyms do not provide a clear insight into the lexical relations among the words bearing similar meaning (Prcic 2010). Therefore, we have devised the multi-faceted approach to the research which incorporates the collocational, componential, and contrastive analysis of the descriptive adjectives hrabar, -a, -o, in Serbian, and its English counterpart brave. Specific emphasis has been given to the presence of grammatical gender (masculine, feminine, neuter) in Serbian in contrast to natural gender in English. Electronic databases and electronic corpora are used for the analysis of the most frequent collocational framework of the chosen samples. The results of the research employed illustrate how semantic (and grammatical) aspects of words are reflected onto and within their collocational range indicating idiomatic meaning of the adjectives analysed in both languages. Furthermore, the analysis applied has shown that the most frequent collocations of the adjective hrabar, -a, -o, have varied depending on the grammatical gender implied (masculine, feminine, neuter), as well as the sequence of its near-synonyms. The same changes have not occurred in English due to its lack of grammatical gender.
Keywords: near-synonyms, descriptive adjectives, collocational analysis, componential analysis, contrastive analysis
OPSOMMING
Daar is opgemerk dat Serwiese sinoniemwoordeboeke nie 'n duidelike insig verskaf in die leksikale verwantskappe tussen die woorde wat soortgelyke betekenisse dra nie (Prcic 2010). Daarom het ons die veelvlakkige benadering tot die navorsing gevolg wat die kollokasionele, kom-ponensiêle, en kontrastiewe analise van die deskriptiewe adjektiewe hrabar, -a, -o, in Serwies, en die Engelse ekwivalent daarvan, brave, inkorporeer. Spesifieke Idem is geplaas op die aanwesigheid van grammatikale gender (manlik, vroulik, onsydig) in Serwies in teenstelling met natuurlike gender in Engels. Elektroniese databasisse en elektroniese korpora word vir die analise van die mees frekwente kollokasionele raamwerk van die gekose voorbeelde gebruik. Die resultate van die navorsing wat gedoen is, illustreer hoe semantiese (en grammatikale) aspekte van woorde op en binne hul kollokasionele reeks gereflekteer word wat dui op die idiomatiese betekenis van die adjektiewe wat in albei tale geanaliseer is. Verder het die analise wat uitgevoer is, getoon dat die mees frekwente kollokasies van die adjektief hrabar, -a, -o, weens die geimpliseerde grammatikale gender (manlik, vroulik, onsydig), asook die opeenvolging van die ampersinonieme, gevarieer het. As gevolg van die afwesigheid van grammatikale gender het soortgelyke veranderings nie in Engels voorgekom nie.
Sleutelwoorde: ampersinonieme, deskriptiewe adjektiewe, kollokasionele analise, komponensièle analise, kontrastiewe analise
1. Introduction
The aim of this paper is to provide a multi-faceted method to analysing the proximity of meaning among near-synonyms in Serbian and English dictionaries. Presently, in Serbian and English dictionaries synonyms are listed either randomly or alphabetically without pointing out proximity of meaning among near-synonyms. Moreover, only adjectives in masculine gender are stated in Serbian dictionaries of synonyms and there is no insight into the specific semantic features of adjectives in female and neuter gender.1 Therefore, we have applied a specific approach to deal with the lack of nuances in meaning among synonyms in two Serbian dictionaries, namely Recnik sinonima i tezaurus srpskog jezika compiled by Pavle Cosic and Sinonimi i srodne reci srpskohrvatskoga jezika compiled by Miodrag Lalevic. The semantic analysis employed in this paper comprises the most frequent collocational range for the selected descriptive adjectives hrabar, -a, o in Serbian and brave in English and samples of their near-synonyms were proposed. The results of the research confirm previous findings that the semantic (and grammatical) aspects of a word are reflected in their most frequent collocational range (Harris (1954), Stubbs (2001), Sinclair (2004), Gries and Stefanowitsch (2004), Hoey (2005), Xiao and McEnery (2006), Turney and Pantel (2010), Liu (2020)).
The first dictionaries of synonyms emerged at the outset of the 17th century (Petrovic 2005: 65). Those were the dictionaries of Latin synonyms. In the 18th century dictionaries of French, German, English and Spanish synonyms were published, and in the 19th century Nikola Tomasseo compiled the first Italian dictionary of synonyms which can still be found in bookshops today. In this century the first Danish, Dutch and Swedish dictionaries of synonyms appeared. Petrovic (2005: 68) suggests that there have been no crucial advances in the area of the lexicography on synonymy. The first dictionary of synonyms of the Serbian language Sinonimi i srodne reci spskohrvatskog jezika was compiled by Lalevic in 1974. The photo type edition of this dictionary was published in 2004 (see Dragicevic 2010). Petrovic (2005: 73-83) acknowledges a difference between differential and cumulative dictionaries. Differential dictionaries of synonyms are characterized by stating the nuances in meaning among the synonyms. In this type of dictionary, an orderly cluster of synonyms is placed next to the node word which in certain cases may be set out in alphabetical order and in some cases is set out based on their proximity of meaning. On the other hand, a cumulative dictionary contains its node word, the orderly cluster of synonyms that it belongs to as well as examples of its use. The differences in meaning among synonyms are not explained (Dragicevic 2010: 261).
The lack of clear insight into the nuances in meaning among the near-synonyms renders impositions in other linguistic areas such as translation, especially when we need to decide whether a certain lexeme can be translated by a greater number of its synonymous equivalents. Bearing in mind all these issues, we can realize why certain European languages, such as Croatian, saw its first dictionary of synonyms published as late as 2008. A similar situation occurred in the Serbian language, with the latest dictionary of synonyms published in the same year, 2008, as a new supplemented edition when compared to the one compiled by M. Lalevic in 1974. Further to the aforementioned data, the following quotes account for the delay in the compilation of the dictionary of Croatian synonyms:
One of the possible reasons of the delayed publishing of the Thesaurus could stem out of lack of agreement among the Croatian linguists what could be considered under the very notion of synonymy. There are a few theoretical definitions of synonyms in research papers of the linguists, what is the least expected occurrence due to the complexity of this issue (Opasic 2010: 165).
The lexicographic relevance of our research study lies in proposing a specific method of presenting near-synonymous samples of descriptive adjectives in the future Serbian and English dictionaries of synonyms. The method was devised in an attempt to delineate fine boundaries in meaning among near-synonyms of the node word. A detailed account of the method applied and its results will be given in the subsequent sections of the paper.
2. Theoretical background
Lexicographical compilations of synonyms in the 18th century contained explanations related to the meaning of words and their nuances in meaning. Nevertheless, Miller and Charles (1991) noticed that the definitions of those words were so close in meaning that the words were frequently mixed and interchanged, e.g., austerity, severity and rigour. However, in these examples the existence of any absolute synonyms cannot be noticed, but relations among them would be rather defined as: "similarity of meaning", "semantic differential" and "semantic similarity". Introducing such expressions enhanced synonymy analysis as a constant variable, within which identity of meaning is defined through grading of meaning (Miller and Charles 1991).
Following the same approach to lexical semantics' analysis, Edmonds (Edmonds and Hirst 2002) concludes that synonymy relies on grading as the main issue underlining definitions of words and their slight differences in meaning, while investigating machine translation and having dealt with the near-synonymy analysis based on computer and corpus linguistics, e.g., if fir and pine can be defined as words denoting coniferous trees, in such case they can be considered absolute synonyms. Constant recognition of near-synonyms depends on the principle of meaning level, above which all words listed, are considered not to be synonyms, and on the opposite side of the same level near-synonyms can be found. Edmonds (Edmonds and Hirst 2002) suggests a model of lexical meaning, which consists of three levels:
- the ultimate level which includes a specific concept, converging with clusters of near-synonyms which, at the same time, belong to a different level. The concept contains essential content which is shared among all near-synonyms;
- at the second level near-synonyms differ in their semantic, stylistic and expressive features;
- whereas at the third level syntactic characteristics can be recognized.
Edmonds (Edmonds and Hirst 2002) shares the same opinion as Hirst (Edmonds and Hirst 2002) who states that the ultimate level can operationally be identified as the level highly dependent on a language: a concept which is lexicalized within different languages must be an ultimate concept. However, near synonymy is an increasingly changeable category in all languages. For example, an ultimate concept, known as a generic mistake is connected with an inconsistent cluster of near-synonyms in different languages: English error, blunder, slip, mistake, lapse, howler and so on; French faute, erreur, faux, pas, bévue, bêtise, bavure, imapir, and so on.; and German Irrtum, Fehler, Mißgriff, Versehen, Scnitzer, and so on.
Therefore, synonymy can be construed as the highest level of mutual substitution, without any crucial changes in the meaning of a certain statement within a context (Miller and Charles 1991; Miller 1999), by which the phenomenon of synonymy can be characterised as near-synonymy (or plesyonyms), which can be described as "contextually defined synonyms" (Miller 1999: 24).
By the application of lexical choices among semantically similar words, especially near-synonyms, in a theoretical approach which is based on computer linguistics, Edmonds and Hirst (2002) suggested at least three levels of meaning complexity, as follows:
(1) The Conceptual-semantic level;
(2) The Subconceptual/stylistic-semantic level;
(3) The Syntactic-semantic level.
All these levels are in accordance with far more detailed accounts of meaning, known as the granularity of word meaning (Edmonds and Hirst 2002: 117-124).
Divjak and Gries (2006) show how the internal structure of a group of near-synonyms can be revealed. Second, they deal with the problem of distinguishing the sub-clusters and the words in those sub-clusters from each other. Finally, they illustrate how these results identify the semantic properties that should be mentioned in lexicographic entries. They illustrate their methodology with a case study on nine near-synonymous Russian verbs that, in combination with an infinitive, express try. Their approach is corpus-linguistic and quantitative. Assuming a strong correlation between semantic and distributional properties, Divjak and Gries (2006) analyse 1,585 occurrences of these verbs taken from the Amsterdam Corpus and the Russian National Corpus, supplemented where necessary with data from the Web. They code each particular instance in terms of 87 variables (ID tags), i.e., morphosyntactic, syntactic and semantic characteristics that form a verb's behavioural profile (BP). Liu (2010, 2013) and Liu and Espino (2012) have conducted BP (behavioural profile) studies on English synonymous adjectives, nouns, and adverbs by focusing on key co-occurrents instead of all the contextual distribution patterns (Liu 2010: 80).
Inkpen and Hirst (2006) and Phoocharoensil (2020) support the idea that collocational patterns within structural variation can be an indicator for distinguishing near-synonyms. A collocation is defined as a co-occurrence of certain words (O'Dell and McCarthy 2008; Lewis 2000). In terms of collocational preference, near synonymous words may co-occur with different collocations from each other according to collocational restrictions (Palmer 1981). Edmonds and Hirst (2002) provide examples of the differences in collocational patterns of the synonym task and job in which one can face a daunting task but not a daunting job. This concept of collocational patterns is related to other criterion used to differentiate near- synonyms, namely semantic preference. While collocational patterns concern lexical restriction, the word's occurrence is defined within the semantic environment (Flowerdew 2012). For example, Edmonds and Hirst (2002) mention that the synonymous verbs die and pass away have a different semantic preference in which pass away is only used with people not with animals or plants.
There are a number of studies on synonym differentiation investigating their semantic preference based on data drawn from language corpora, e.g., the British National Corpus (BNC) or the Corpus of Contemporary American English (COCA). In these studies near-synonyms have been differentiated by examining their distribution across genre, collocations, and semantic preference within different parts of speech:
- nouns (Jirananthiporn (2018), Phoocharoensil (2020), Jarunwaraphan and Mallikamas (2020), Sumonsriworakun (2022));
- verbs (Gu (2017), Song (2021), Phoocharoensil (2021), Kruawong and Phoocharoensil (2022))
- adverbs (Desagulier (2014) Yang (2020), Stoyanova-Georgieva (2020) and Tao (2021));
- adjectives (Cai (2012), Crawford and Csomay (2016), Petcharat and Phoocharoensil (2017), Kamihski (2017), Sayyed and Al-Khanji (2019), Selmistraitis (2020) and Thongpan (2022).
In the collocational analysis of selected adjectives Cai (2012) examined the synonyms awesome, excellent, fabulous, fantastic, great, terrific, and wonderful based on the data drawn from COCA. The results of the study revealed that the most frequently occurring word is great which was also reported to be more general. Moreover, regarding the frequency distribution across genres, it was found that fabulous, fantastic, great, terrific, and wonderful occur more in the spoken genre, while awesome and excellent are prevailing in magazines. Collocation was also the major criterion used in distinguishing two adjective synonyms equal and identical in a study by Crawford and Csomay (2016). Generally, it was shown that both synonyms are interchangeable in certain contexts; however, in an analysis of collocations derived from COCA, different collocational behaviour was revealed in that there is more likelihood of abstract concepts such as opportunities, rights, and protection accompanying equal, and concrete nouns such as twins, copies, and houses co-occurring with identical. Such an observation is only possible by referencing large amounts of texts through corpus data, as it allows linguists and language researchers to access language use in authentic contexts.
Petcharat and Phoocharoensil (2017) examined three synonymous adjectives appropriate, proper and suitable based on their meaning, collocations, formality and grammatical patterns. The data were collected from three dictionaries, namely the Longman Dictionary of Contemporary English 6th edition (2014), Longman Advanced American Dictionary 3rd edition (2013), and Macmillan Collocations Dictionary (2010) and COCA. It was found that even though appropriate, proper and suitable shared the same core meaning, they differed in detailed meanings in which suitable tends to be used more with person. In addition, appropriate occurred more in formal context than suitable and proper. Moreover, by examining collocations and grammatical patterns, it was found that they shared only a small number of collocations and grammatical patterns in which they occur. This indicated that the three synonymous adjectives are not absolute synonyms as they cannot be used interchangeably in the same context. Kaminski (2017) explores the potential usefulness of two techniques that visualise collocational preference for the purpose of synonym discrimination. Given the fact that collocation is one of the most important markers of meaning difference, it is used as the criterion for distinguishing between near-synonyms. Collocational preferences for a set of near-synonyms (artificial, fake, false, and synthetic) were visualised using two techniques: correspondence analysis plot and collocational network. The collocations were retrieved from BNC corpus by using a distributional method. An advantage of the graphs is that they allow lexicographers to spot similarities and differences in collocational preference of several words in a single diagram. Sayyed and Al-Khanji (2019) investigated the similarities and differences that exist between afraid, scared, frightened, terrified, startled, fearful, horrified and petrified. Specifically, they compared and contrasted the words in terms of dialectal differences, frequency of occurrence, distribution in different genres and core meanings. The findings have shown that nearly all adjectives appear to be mostly used in fiction and spoken genres. Furthermore, the results also unveiled that both the Americans and the British tend to avoid using such adjectives of fear in academic contexts. In a more recent study, Selmistraitis (2020) examined semantic preference among three pairs of synonymous adjectives, namely succinct and concise, coherent and cohesive, and precise and accurate in the academic texts of COCA and found that succinct and concise are more similar in semantic preference than other two pairs of synonyms.
Thongpan (2022) analyses the similarities and differences between the three synonymous adjectives far, distant, and remote, concentrating on the degree of formality in their distribution across eight genres, as well as their collocations with the semantic preference combination. The data for this study was drawn from COCA. The results revealed that the word remote has the most formal degree, followed by distant and far, respectively, since it is most commonly used in academic texts. In terms of collocations and semantic preference, the data pointed out that the three synonyms share only a few collocates and, as a result, they vary in semantic preference.
investigating possibilities of determining proximity in meaning among near-synonyms, various scholars have proposed specific methods of quantifying near-synonymy relations among selected words. Cappelli (2011) presented a cluster analysis approach to quantify near-synonymy relations and compare non-parametric and parametric methods. The first approach is model free since it does not assume an underlying model of lexical knowledge but it uncovers the group structure in the set of near synonyms of a target word by comparing the list of synonyms of the given entry with those of its near synonyms as contained in available thesauri. Then, in order to validate the results provided by the cluster analysis, a statistical model is introduced for analyzing human judgments of perceived degree of synonymy, also by a relationship with the subjects' characteristics. Piits (2013) carried out a comparative study on words for human beings and their Estonian collocates. The study was inspired by the distributional hypothesis by Zellig Harris (1957), which states that words occurring in similar contexts tend to have a similar meaning. The word collocate is used in a neo-Firthian sense, covering all the words that co-occur with the node word the most often. The comparison involved the 30 most frequent collocates for each node word. Assuming that a bigger number of shared collocates means a greater semantic closeness, intersections of collocates of the Estonian words for 'human being' were computed. it turned out that antonymous words had the highest number of collocates in common, which indicates that syntag-matic relations of words may also reflect some of their paradigmatic relations. As antonymy is interpreted as a similarity relation (which is quite natural considering that the opposite value applies to just one semantic component out of several), Piits (2013: 157) agreed with Harris (1957) that similarity between words is manifested in their contextual coincidence. Fachrutdinov, Khisamova and Khismatullina (2017) conducted a comparative analysis of semantic distinctions between synonymous adjectives in Tatar and English. Herda (2020) contrasted the near-synonymous Polish classifiers kupa 'heap', sterta 'pile', and stos 'stack', all of which encode upward-oriented arrangements of objects or substances and thus prototypically combine with concrete inanimate nouns, by means of a collocational analysis conducted on naturally-occurring data derived from the National Corpus of Polish. As part of a larger research project on expert assessment of synonymic rows in RuWordNet thesaurus, Gimaletdinova, Khalitova, Solovyev and Bochkarev (2021) pointed out that the problem of determining semantic similarity between words affects the understanding of synonymy and creates obstacles to the work of lexicographers.
In the present study we have analysed descriptive adjectives hrabar, -a, -o in Serbian and brave in English within their most frequent collocational framework using different corpora: Corpus of the Contemporary Serbian language, Faculty of Mathematics and Natural Sciences, University of Belgrade, SrWac (Serbian Web), the British National Corpus (BNC) and ukWac (British Web). The results of the collocational analysis of these adjectives were the basis for proposing their near-synonymy samples while investigating their proximity in meaning. We have noticed that grammatical gender influences the sequence of near-synonymy samples in Serbian, but not in English. The approach to the lexical-semantic analysis employed in this paper relies on the idea of the granularity of word meaning applying corpus analysis. This idea is relevant to the present study because it explains the nature of the complexity of near-synonymy as a lexical relation. It points to the way in which near-synonymy affects the structure of the lexicon and lexicographic representation as both fine-grained aspects of near-synonymous adjectives and their collocational patterns are significant for discerning their subtle nuances in meaning.
3. Methodology of the research
The starting hypothesis of this paper rests on the agreement among the majority of semanticists that absolute synonymy is rare, while in the opinion of certain linguists it is in fact non-existent (Quine (1951); Palmer (1981: 59)). In the opinion of philosophers such as Quine (1951) and Goodman (1952) absolute synonymy is impossible, though it may be limited to mostly technical terms (distichous, two-ranked; groundhog, woodchuck) (Hirst 1995: 51). Cruse (1986: 270) claims that "natural languages abhor absolute synonyms just as nature abhors vacuum," as the meanings of words are constantly changing.
The multi-faceted approach applied in this paper features the use of the collocational approach to lexical analysis and componential analysis (Nida (1975); Bendix (1996); Zhang (2002)) of the collocates of the extracted descriptive adjectives, and as the final step of the research, applying contrastive analysis.
The results of the analysis should prove another hypothesis, namely that the collocational framework is a better generator of the precise meaning of a word than can be inferred through its denotation. These results will indicate findings that the semantic (and grammatical) aspects of words are reflected onto and within their own collocational framework. It is expected that the collocational framework (the most frequent collocates) of the adjective hrabar, -a, -o in Serbian will change depending on the grammatical gender implied (masculine, feminine, neuter), as well as the sequence of its near-synonyms. It is claimed that there are inflectional selectional differences among synonyms in a morphologically rich language such as Serbian. The same changes are not expected in the English language due to its lack of grammatical gender.
Componential analysis is carried out to show that the denotational meaning of the lexemes is not enough to illustrate the comprehensive scale of the meaning of lexemes analysed within context. In dictionaries of synonyms mentioned earlier in this paper, mainly the denotational meaning of the lexemes is presented. It is essential to point out how much denotational meaning is insufficient and how much other aspects of the meaning of the lexeme are dependent upon the collocational range.
Consequently, componential analysis has been applied to look for the semantic features of the descriptive adjectives analysed within their most frequent collocational framework. This approach appears very similar to the profile-based usage-feature analysis (Geeraerts et al. (1994), Gries (2006), Arppe (2008), Divjak (2010), Glynn (2014)).
Certain authors, like Taylor (1991), have a very negative attitude towards componential analysis, which they consider an outdated and obsolete method. In contrast, Geeraerts (2010: 4) claims that: "there can be no semantic description without some sort of decompositional analysis".
The process of contrasting (or analysing) presupposes the comparison of nominal collocates of descriptive adjectives. For the analysis of synonyms within the most frequent collocational framework, electronic dictionaries and electronic databases, such as the corpus of the Contemporary Serbian language, Faculty of Mathematics and Natural Sciences, University of Belgrade, SrWac (Serbian Web), the British National Corpus (BNC), and ukWac (British Web), are used.
4. Analysis
In the analysis undertaken we have applied a collocational method aiming at determining the proximity of meaning among the samples of near synonyms. First, we extracted the most frequent collocations of the node word hrabar, -a, -o. We then have selected the first 10/15 synonyms of the adjective hrabar, -a, -o from the Dictionary of synonyms by Pavle Cosic and his assistants (2008) (see Addendum 1). In the next phase of analysis we analysed co-occurrences of the extracted samples of synonyms within the most frequent collocational framework of the adjective hrabar while using the SrWac Corpus (554.627.647 tokens) (see Addendum 2). The co-occurrences and concordance of the near synonymy samples within the most frequent collocational framework of the node word implied the proximity of meaning of near-synonyms to the node word.
4.1 The analysis of the descriptive adjectives hrabar, -a, -o and their near-synonyms in Serbian
After analyzing the first ten synonyms2 (extracted from the dictionary of synonyms: Recnik sinonima, Pavle Cosic et al. (2008: 293)) through their co-occurrences within the most frequent nominal collocations of the node word hrabar ~covek (eng. man), ~potez (eng. move), ~korak (eng. step), ~cin (act)3 the following four synonyms can be considered to be near-synonyms of the descriptive adjective hrabar, -a, -o (eng. brave): herojski (eng. heroic), odvazan (eng. bold), junacki (eng. stout), smeo (eng. courageous), (Recnik sinonima, Pavle Cosic i saradnici 2008: 659).
In the second stage of the research, frequency analysis of the four most recurrent collocates of the adjective hrabar (~potez (eng. move), ~covek (eng. man), ~korak (eng. step), ~cin (eng. act)) was carried out within the collocational framework of the suggested near synonyms (herojski, odvazan, smeo, junacki) (see Table 1).
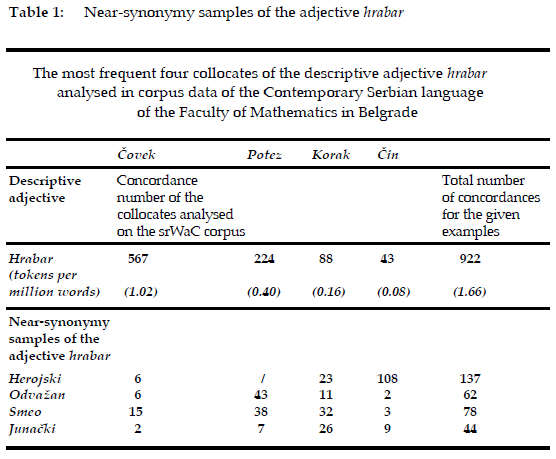
Having examined the results, we can conclude that the near synonyms of the adjective hrabar are: herojski (137) smeo (78), odvazan (62), junacki (44) (srWaC corpus, taken on July 28, 2022).
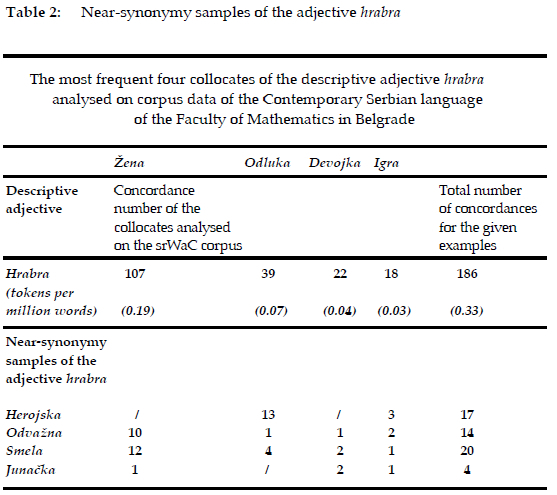
The third stage of the research includes frequency analysis of the four most recurrent collocates of the adjective hrabra (~zena (eng. woman), ~odluka (eng. decision), ~devojka (eng. girl), ~igra (eng. play)) within the collocational framework of the suggested near synonyms (herojska, odvazna, smela, junacka) (see Table 2). The results of the analysis suggest that the near synonyms of the adjective hrabra are: smela (20), herojska (17), odvazna (14), junacka (4) (srWaC corpus, taken on July 28, 2022) (see Table 2).
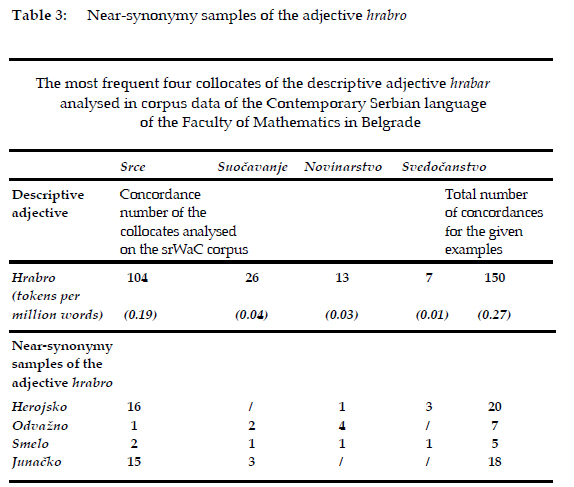
The final stage of the research involves frequency analysis of the four most recurrent collocates of the adjective hrabro (~srce (eng. heart), ~suocavanje (eng. confrontation), ~novinarstvo (eng. journalism), svedocanstvo (eng. testimony)) within the collocational framework of the suggested near-synonyms (herojsko, odvazno, smelo, junacko) (see Table 3). The results of the analysis suggest that the near synonyms of the adjective hrabro are: herojsko (20), junacko (18), odvazno (7), smelo (5) (srWaC corpus taken on July 28, 2022).
4.2 The analysis of adjective brave and its near synonyms in English
The most frequent collocations of the node word brave were extracted from the corpus data of the website www.just-the-word.com. In the next phase of analysis we analysed co-occurrences of the extracted samples of synonyms within the most frequent collocational framework of the adjective brave while using the ukWac Corpus (2.135.658.231 tokens).
A frequency analysis of the four most recurrent collocates of the adjective brave (man, face, attempt, fight) was carried out within the collocational framework of the suggested near synonyms (courageous, bold, fearless, dauntless) (see Table 4). The results of the analysis suggest that the near synonyms of the adjective brave are: bold (326), courageous (176), fearless (26), dauntless (4) (ukWaC corpus, taken on July 28, 2022).
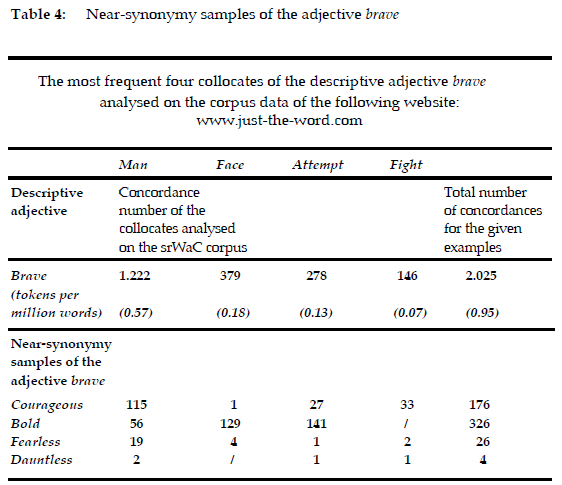
5. Contrastive analysis4
In the process of contrastive analysis application the semantic features of the adjective hrabar, -a, -o and its near-synonyms herojski (eng. heroic), odvazan (eng. audacious), smeo (eng. bold), junacki (eng. stout) have been compared according to the frequency of their appearance with their most recurrent collocates ((~potez, ~covek, ~korak, ~cin, ~zena (eng. woman), ~odluka (eng. decision), ~devojka (eng. girl), ~igra (eng. play), (~srce (eng. heart), ~suocavanje (eng. confrontation), ~novinarstvo (eng. journalism), svedocanstvo (eng. testimony)).
The most frequent semantic features of the adjective hrabar, -a, -o in Serbian and the adjective brave in English, as well as their near synonyms analysed in the range of their most frequent collocates are as follows:
(a) the most frequent semantic components of the adjective hrabar and its near synonyms (herojski (eng. heroic), odvazan (eng. audacious), smeo (eng. bold), junacki (eng. stout)) analysed in the following collocational framework (~potez, ~covjek, ~korak, ~cin):
[+MALE±ANIMATE±ADULT]
[+KURAZAN+NEPOKOLEBLJIV+VITESKI] 4:Eng. [+COURAGEOUS + UNDAUNTED+CHIVALROUS]
(b) the most frequent semantic components of the adjective hrabra and its near synonyms (herojska, odvazna, smela, junacka) analysed within the given collocational framework (~zena (eng. woman), ~odluka (eng. decision), ~devojka (eng. girl), ~igra (eng. play)):
[-MALE±ANIMATE±ADULT]
[+SRCANA+KURAZNA+NEUSTRASIVA] 5: Eng. [+BOLD+COURAGEOUS+DAUNTLESS]
(c) the most frequent semantic components of the adjective hrabro and their near synonyms (herojsko, odvazno, smelo, junacko) analysed in the range of the following collocates (~srce (eng. heart), ~suocavanje (eng. confrontation), ~novinarstvo (eng. journalism), svedocanstvo (eng. testimony)):
[±MALE±ANIMATE±ADULT]
[+NEUSTRASIVO+NEPOKOLEBLJIVO+VITESKO] 10: Eng. [+DAUNTLESS+UNDAUNTED+CHIVALROUS]
(d) the most frequent semantic components of the adjective brave and their near synonyms (courageous, bold, fearless, dauntless) analysed in the following collocational framework: (man, face, attempt, fight):
[-MALE±ANIMATE±ADULT]
[+NEUSTRASIV+SRCAN+NEPOKOLEBLJIV] 8: Eng. [+DAUNTLESS+UNDAUNTED+CHIVALROUS]
The most frequent semantic components of the adjective hrabar, -a, -o in Serbian and the adjective brave in English are as follows:
[-MALE±ANIMATE±ADULT]
[+NEUSTRASIV+SRCAN+NEPOKOLEBLJIV]: Eng.
[+DAUNTLESS+BOLD+UNDAUNTED]
In the next stage of our analysis the frequency of use of the descriptive adjective hrabar, -a, -o was analysed within the collocational framework of the descriptive adjective brave (its English counterparts) (see Table 5).
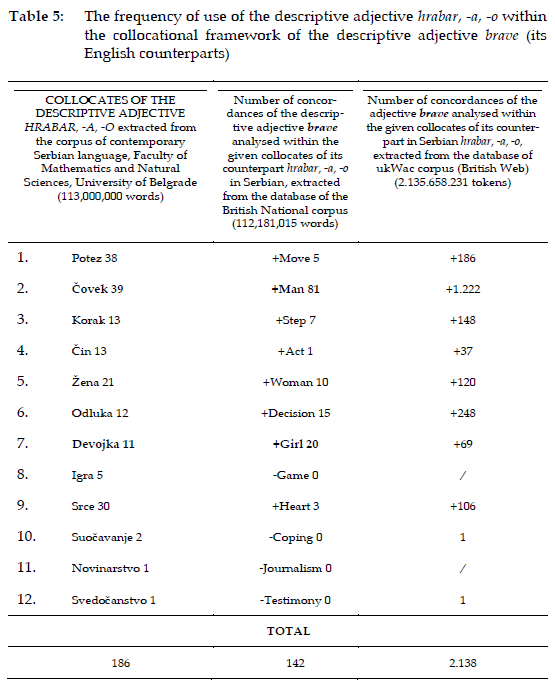
The frequency of the use of the descriptive adjective brave in the most frequent collocational framework of the adjective hrabar, -a, -o (move, man, step, act, woman, decision, girl, game, heart, coping, journalism, testimony) was carried out (Table 5).
After the analysis, it is determined that there is similarity in the collocation framework of the most common collocations of the adjectives hrabar, -a, -o (186), and its translation equivalents, analyzed in the collocation framework of the adjective brave (142). After carrying out the same analysis based on the larger corpus ukWac (2.135.658.231 tokens), the number of concordances increased to 2.138 (Table 5).
In the continuation of the analysis, the frequency of using the adjectives hrabar, -a, -o in the collocation framework of the descriptive adjective brave (its translation equivalents in the Serbian language) was compared (Table 6).

The results of the analysis indicate that the collocational framework of the adjective brave (its most frequent collocates) is more specific and in a very small number (30) comparable to the collocational framework of the adjective hrabar, -a, -o (361). However, the results are different when the analysis is performed on a larger corpus, such as the SrWac (554.627.647 tokens) (869 concordances) (Table 6).
In the next stage of the analysis a specific collocational framework of both the adjectives brave and hrabar, -a, -o was contrasted in order to reveal whether there are the same collocates among them, i.e., their counterparts (see Table 7). Therefore, we have applied contrastive analysis in both directions (Serbian to English and English to Serbian).

The results of the analysis imply the existence of two mutual most frequent collocates of the adjective hrabar, -a, -o and the most frequent collocates of the adjective brave (see Table 7).
Throughout this analysis it has been noticed that there are the following mutual collocates: covek/man and devojka/girl, which are the translation equivalents of the descriptive adjectives brave and hrabar, -a, -o.
The most frequent collocates of the near-synonyms of the adjective brave were also analyzed on the basis of data taken from the British National Corpus (112,181,015 words) (Table 8).

The analysis has shown that the mutual collocates of the adjective brave and its near-synonyms are as follows:
courageous/brave man bold/brave attempt
Among the most frequent collocates of the adjective brave and its near-synonyms the following ones have a transferred meaning:
courageous decision/effort bold move/step/statement/attempt fearless inventory/creativity dauntless conversation brave face/world/attempt
We have performed an analysis of the most frequent collocates of near-synonyms of the adjective hrabar, -a, -o (herojski, -a, -o, junacki, -a, -o, odvazan, -a, -o, smeo, -la, -lo) endorsing the corpus data of the Contemporary Serbian language, Faculty of Mathematics, University of Belgrade (113,000,000) (see Table 9).
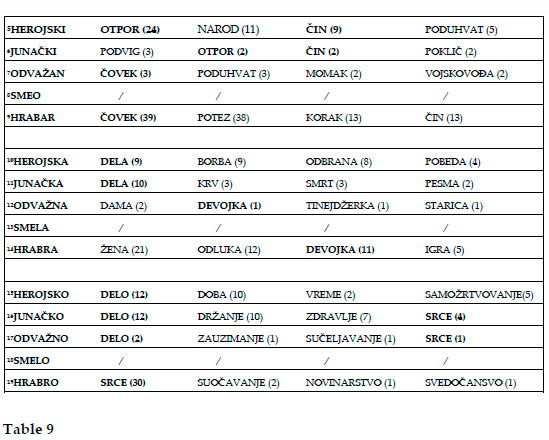
The mutual collocates of the adjective hrabar, -a, -o and its near-synonyms are as follows:
herojski/junacki otpor (Eng. heroic/stout resistance);
herojski/junacki cin (Eng. heroic/stout act);
odvazan/hrabar covek (Eng. audacious/brave man);
herojska/junacka dela (Eng. heroic/stout deeds);
odvazna/hrabra devojka (Eng. audacious/brave girl);
herojsko/junacko/odvazno delo (Eng. heroic/stout/audacious deed);
odvazno/hrabro srce (Eng. audacious/brave heart);
While analysing the most frequent collocates of the adjective hrabar, -a, -o and its near-synonyms it has been noticed that the following ones have the transferred meaning:
herojski otpor/cin/poduhvat (Eng. heroic/resistance/act/achievement);
junacki otpor/cin/poklic (Eng. heroic resistance/act/cry);
odvazan poduhvat (Eng. audacious achievement);
hrabar potez/korak/cin (Eng. brave move/step/act);
herojska dela/borba/odbrana/pobeda (Eng. heroic deeds/battle/defence/victory);
hrabra odluka/igra (Eng. brave decision/game);
junacka krv/smrt (Eng. stout blood/death);
herojsko delo/doba/vreme/samozrtvovanje (Eng. heroic deed/age/time/self-sacrifice);
junacko delo/drzanje/zdravlje/srce (Eng. stout deed/holding/health/heart);
odvazno delo/zauzimanje/suceljavanje/srce (Eng. audacious deed/advocating/confrontation/heart);
hrabro srce/suocavanje/novinarstvo/svedocanstvo (Eng. brave heart/confrontation/journalism/testimony)
The analysis employed has shown that in addition to the denotative meaning of steadfastness, heartiness, fearlessness, as human characteristics, this adjective, as well as its near synonyms, indicate the heartiness, fearlessness and steadfastness of certain inanimate concepts (resistance, act, endeavor, shout, step, move, deeds, fight, defense, victory, decision, game, blood, death, time, heart, journalism, confrontation ...). The analysis of the adjective brave and its near-synonyms in the stated collocational framework: courageous decision/effort; bold move/step/statement/attempt; fearless inventory/creativity; dauntless conversation; brave face/world/ attempt also shows that some traits characteristic of human beings have been attributed to certain objects and phenomena in English. The conducted research indicates prevailing idiomatic meaning of the adjectives analysed in both languages.
6. Conclusion
The multi-faceted approach to the research employed in this paper incorporates the collocational, componential, and contrastive analysis of the adjectives' extracted collocates and the semantic content of their near synonyms in English and Serbian.
The first significant result of the approach applied in this paper is related to the specific method of selecting near synonyms that consists of four stages of the analysis:
(1) After analyzing the first ten synonyms (extracted from the dictionary of synonyms; see Addendum 2) through their co-occurrences within the most frequent nominal collocations of the node word (corpus-based analysis; see Addendum 1) four synonyms were considered to be near synonyms of the selected descriptive adjective.
(2) In the second stage of the research, frequency analysis of the four most recurrent collocates of the adjective hrabar (masculine gender) was carried out within the collocational framework of the suggested near synonyms.
(3) The third stage of the research includes frequency analysis of the four most recurrent collocates of the adjective hrabra (female gender) within the collocational framework of the suggested near synonyms.
(4) The final stage of the research involves frequency analysis of the four most recurrent collocates of the adjective hrabro (neuter gender) within the collocational framework of the suggested near synonyms.
Within this frequency-based approach to entrenchment within the usage-based understanding of language (Glynn 2014: 15) the following valid result of the analysis highlights the influence of grammatical gender (masculine, female, neuter) on the various most frequent collocates of the analysed descriptive adjective when seen from the perspective of each gender:
For example:
hrabar (masculine gender): potez (567); covek (224); korak (88); cin (43) (see Table 1) hrabra (female gender): zena (107); odluka (39); devojka (22); igra (18) (see Table 2) hrabro (neuter gender): srce (104); suocavanje (26); novinarstvo (13); suceljavanje (7) (see Table 3)
In the research undertaken it has been found that besides the influence of the most frequent collocational framework of the adjective on the choice of its near synonyms, this interrelation depends on the adjective's grammatical gender and also the near synonymy choice, especially regarding the near-synonyms' proximity-of-meaning order.
Namely, it has been noticed that this proximity-of-meaning order of near synonyms varies with the gender implied (masculine, feminine, neuter):
For example:
Near-synonyms of the adjective hrabar (masculine gender): herojski (137) smeo (78), odvazan (62), junacki (44) (see Table 1)
Near-synonyms of the adjective hrabra (female gender): smela (20), herojska (17), odvazna (14), junacka (4) (see Table 2)
Near-synonyms of the adjective hrabro (neuter gender): herojsko (20), junacko (18), odvazno (7), smelo (5) (see Table 3)
The same interrelation between the word order of near-synonyms' proximity-of-meaning and grammatical gender was not noticed in the English language featuring natural language.
In this respect, the importance of the research lies in emphasizing the disparity between the English and Serbian language in the issues of grammatical gender.
An analysis of the descriptive adjective and its near-synonyms carried out within the most frequent collocational framework reveals a great number of samples implying idiomatic meanings in English and Serbian. The stated result is in line with the conclusion drawn by Firth (1957) claiming that: "you shall know the word by the company it keeps" and Dragicevic (2010: 156) saying that: "the meaning of the lexemes is determined and shaped by the context, thus each new context features new semantic components of the lexeme, while the other components are shadowed." Therefore, this result proves that the collocational framework of the lexeme determines the meaning of the lexeme with more precision than its denotational meaning does.
The samples of collocates indicate a prevailing idiomatic meaning of the adjective hrabar, -a, -o and its near-synonyms while being analysed in the most frequent collocational framework. It can be concluded that besides a denotational meaning, this adjective and its near-synonyms imply other nuances of transferred meaning indicating the heartiness, fearlessness and steadfastness of certain inanimate concepts (resistance, act, endeavor, shout, step, move, deeds, fight, defense, victory, decision, game, blood, death, time, heart, journalism, confrontation ...).
As a result of the contrastive analysis applied it has been noticed that the collocational framework of the descriptive adjectives in Serbian is more comparable to the collocational framework of the analysed adjectives in English (see Table 5), whereas the most frequent collocational framework of the descriptive adjective in English is rather specific and a lot less comparable to the collocational framework (of its Serbian counterparts) in Serbian (see Table 6):

This result is in accordance with the further analysis which showed a small number of mutual collocates (their counterparts) in both English and Serbian. These results confirm the starting hypothesis of this paper that the collocational frameworks of words are highly dependent on the semantic-syntactic specificity of the language.
However, contrastive analysis of the most frequent semantic features of descriptive adjectives and their near-synonyms in Serbian and English showed that there are a great number of their most frequent semantic features (see Table 7). This finding poses an interesting question: "How can it be possible that in the analysis of the most frequent collocational frameworks of the adjectives analysed in Serbian and its counterparts in English, a small degree of mutual comparability has been noticed, and on the other hand, a separate analysis showed a great number of their most frequent semantic features? The answer to this question is related to the specific way of classifying semantic features into primary semes, and distinctive and peripheral features, as presented by Dragicevic (2010).
Applying this method in future thesauri of English and Serbian dictionaries of synonyms would undoubtedly improve their quality by making differences in the meaning of near-synonyms more transparent, taking into account the obvious lack of presentation of the nuances in meaning among the given synonyms of the selected node word. At present, synonyms in the English and Serbian dictionaries are listed either in alphabetical order or randomly without paying attention to their proximity in meaning. Therefore, it has been proposed that list of synonyms be included next to the node word following the principle of proximity of meaning, not randomly or alphabetically. More precisely, the most frequent collocational framework of the node word should be extracted, within which the near-synonymy samples should be analysed, thus measuring their proximity of meaning to the node word. Moreover, alongside the suggested method, the use of synonyms within example sentences should be added, showing the nuances of their meaning within the context. In addition, as only adjectives in masculine gender are stated in Serbian dictionaries of synonyms and there is no insight into the specific semantic features of adjectives in female and neuter gender, these samples of the adjectives analysed should be included.
Endnotes
1 Fuertes-Olivera and Tarp (2022), Ledinek and Michelizza (2021), Norri (2019), Mathiasen (2017), Westveer, Sleeman and Aboh (2018) investigated issues of gender-biased dictionaries.
2 Method of choosing the first four near-synonymy samples has been presented in Addendum 2.
3 Method of choosing the most frequent collocational framework of the adjective analysed has been presented in Addendum 1.
4 See Fisiak (1971); Filipovic (1984); Mair and Markus (1992); Hawkins (1986); House (1996); Johansson (2007); Xiao and McEnery (2006).
5 Eng. HEROIC (male) RESISTANCE (24); PEOPLE (11); ACT (9); ENDEAVOUR (5)
6 Eng. STOUT (male) ACHIEVEMENT (3); RESISTANCE (2); ACT (12) CRY (2)
7 Eng. AUDACIOUS (male) MAN (3); ENDEAVOUR (3); BOY (2); MILITARY LEADER (2)
8 Eng. BOLD (male)
9 Eng. BRAVE (male) MAN (39); MOVE (38); STEP (13); ACT (5)
10 Eng. HEROIC (female) DEEDS (9); BATTLE (9); DEFENSE (8); VICTORY (4)
11 Eng. STOUT (female) DEEDS (10); BLOOD (3); DEATH (3); POEM (2)
12 Eng. AUDACIOUS (female) LADY (2); GIRL (1); TEENAGER (1); OLD WOMAN (1)
13 Eng. BOLD (female)
14 Eng. BRAVE (female) WOMAN (21); DECISION (12); GIRL (11); GAME (5)
15 Eng. HEROIC (neuter) DEED (12); AGE (10); TIME (2); SELF-SACRIFICE (5)
16 Eng. STOUT (neuter) DEED (12); HOLDING (10); HEALTH (7); HEART (4)
17 Eng. AUDACIOUS (neuter) DEED (2); ADVOCATING (1); CONFRONTATION (1); HEART (1)
18 Eng. BOLD (neuter)
19 Eng. BRAVE (neuter) HEART (30); CONFRONTATION (2); JOURNALISM (1); TESTIMONY (1)
References
Dictionaries
Cosic, P. 2008. Recnik sinónima i tezaurus srpskog jezika. Beograd: Kornet.
Lalevic, M.S. 1974. Sinonimi i srodne reci srpskohrvatskoga jezika. Beograd: Leksikografski zavod Sveznanje.
Electronic corpora
British National Corpus (BNC). www.natcorp.ox.ac.uk [Accessed on October 2, 2021].
Corpus of Contemporary Serbian language, Faculty of Mathematics and Natural Sciences, University of Belgrade. korpus.matf.bg.ac.rs [Accessed on July 28, 2022].
SrWac (Serbian Web). https://www.clarin.si/noske/run.cgi/corp_info?corpname=srwac&struct_attr_stats=1 [Accessed on July 28, 2022].
ukWac (British Web). https://www.clarin.si/noske/run.cgi/corp_info?corpname=ukwac&struct_attr_stats=1 [Accessed on July 28, 2022].
Other literature
Arppe, A. 2008. Univariate, Bivariate, and Multivariate Methods in Corpus-based Lexicography-A Study of Synonymy. Doctoral Thesis. Helsinki: University of Helsinki. [ Links ]
Bendix, E.H. 1996. Componential Analysis of General Vocabulary. The Semantic Structure of a Set of Verbs in English, Hindi and Japanese. Bloomington: Indiana University Press. [ Links ]
Cai, J. 2012. Is it "great" Enough? A Corpus-based Study of "great" and its Near Synonyms. Master Thesis. Muncie, Indiana: Ball State University. [ Links ]
Cappelli, C. 2011. Grouping Near-synonyms of a Dictionary Entry: Thesauri and Perceptions. Quaderni di Statistica 13: 53-67. [ Links ]
Crawford, W.J. and E. Csomay. 2016. Doing Corpus Linguistics. London, UK: Routledge. [ Links ]
Cruse, A. 1986. Lexical Semantics. Cambridge: Cambridge University Press. [ Links ]
Desagulier, G. 2014. Visualizing Distances in a Set of Near-synonyms. Corpus Methods for Semantics: Quantitative Studies in Polysemy and Synonymy 43: 145-178. [ Links ]
Divjak, D. 2010. Structuring the Lexicon. A Clustered Model for Near-synonymy. Cognitive Linguistics Research 43. Berlin/New York: Mouton de Gruyter. [ Links ]
Divjak, D. and Stefan Th. Gries. 2006. Ways of Trying in Russian: Clustering Behavioural Profiles. Corpus Linguistics and Linguistic Theory 2(1): 23-60. [ Links ]
Dragicevic, R. 2010. Leksikologija srpskog jezika. Beograd: Zavod za udzbenike. [ Links ]
Edmonds, P. and G. Hirst. 2002. Near-synonymy and Lexical Choice. Journal of Computational Linguistics 28(2): 105-144. [ Links ]
Fachrutdinov, R.R., V.N. Khisamova and L.G. Khismatullina. 2017. Comparative Analysis of Semantic Distinctions between Synonymous Adjectives in Tatar and English European Research Studies Journal XX, Special Issue: 447-457. [ Links ]
Filipovic, R. 1984. What are the Primary Data for Contrastive Analysis. Fisiak, J. (Ed.). 1984. Contrastive Linguistics: 107-108. Berlin: Mouton de Gruyter. [ Links ]
Firth, J.R. 1957. A Synopsis of Linguistic Theory 1930-1955. Studies in Linguistic Analysis. Special Volume of the Philological Society: 1-32. Oxford: Blackwell. [ Links ]
Fisiak, J. 1971. The Poznan Polish-English Contrastive Project. Filipovic, R. (Ed.). 1971. Zagreb Conference on English Contrastive Projects: 87-96. Zagreb: Institute of Linguistics, University of Zagreb. [ Links ]
Fuertes-Olivera, P.A. and S. Tarp. 2022. Critical Lexicography at Work: Reflections and Proposals for Eliminating Gender Bias in General Dictionaries of Spanish. Lexikos 32(2): 105-132. [ Links ]
Geeraerts, D. 2010. Theories of Lexical Semantics. New York/Oxford: Oxford University Press. [ Links ]
Geeraerts, D., S. Grondelaers and P. Bakema. 1994. The Structure of Lexical Variation. Meaning, Naming, and Context. Berlin: Mouton de Gruyter. [ Links ]
Gimaletdinova, G., L. Khalitova, V. Solovyev and V. Bochkarova. 2021. Lexicographic Study of Synonymy: Clarifying Semantic Similarity Between Words. Computacion y Systems 25(3): 667-675. [ Links ]
Glynn, D. 2014. Corpus-driven Lexical Semantic Evidence for Conceptual Structure of ANGER. Novakova, I., P. Blumenthal and D. Siepmann (Eds.). 2014. New Directions in Lexical Semantics and Discourse Organization: 69-83. Frankfurt: Peter Lang. [ Links ]
Gries, Stefan Th. 2006. Corpus-based Methods and Cognitive Semantics: The Many Senses of to run. Gries, Stefan Th. and A. Stefanowitsch (Eds.). 2006. Corpora in Cognitive Linguistics. Corpus-based Approaches to Syntax and Lexis: 57-99. Berlin/New York: Mouton de Gruyter. [ Links ]
Gries, Stefan Th. and A. Stefanowitsch. 2004. Extending Collostructional Analysis: A Corpus-based Perspective on 'alternations'. International Journal of Corpus Linguistics 9(1): 97-129. [ Links ]
Gu, B.J. 2017. Corpus-Based Study of Two Synonyms Obtain and Gain. Sino-US English Teaching 14(8): 511-522. [ Links ]
Harris, Z.S. 1954. Distributional Structure. Word 10(2-3): 146-162. [ Links ]
Harris, Z.S. 1957. Co-occurrence and Transformation in Linguistic Structure. Language 33(3): 283-340. [ Links ]
Hawkins, J.A. 1986. A Comparative Typology of English and German: Unifying the Contrasts. London: Croom Helm. [ Links ]
Herda, D. 2020. Arrangement Classifiers, Collocations, and Near-synonymy: A Corpus-based Study with Reference to Polish. Studia Linguistica Universitatis lagellonicae Cracoviensis 137(4): 245-258. [ Links ]
Hirst, G. 1995. Near-synonymy and the Structure of Lexical Knowledge. Papers from the 1995 AAA Symposium on Representation and Acquisition of Lexical Knowledge: Polysemy, Ambiguity, and Generativity, 27-29 March 1995, Stanford University: 51-56. Stanford, CA: Stanford University.
Hoey, M. 2005. Lexical Priming: A New Theory of Words and Language. London/New York: Routledge. [ Links ]
House, J. 1996. Contrastive Discourse Analysis and Misunderstanding: The Case of German and English. Hellinger, M. and U. Amon. 1996. Contrastive Sociolinguistics: 345-361. Berlin/New York: Mouton de Gruyter. [ Links ]
Inkpen, D. and G. Hirst. 2006. Building and Using a Lexical Knowledge Base of Near-synonym Differences. Computational Linguistics 32(2): 223-262. [ Links ]
Jarunwaraphan, B. and P. Mallikamas. 2020. A Corpus-based Study of English Synonyms: 'chance' and 'opportunity'. REFLections 27(2): 218-245. [ Links ]
Jirananthiporn, S. 2018. Is this Problem Giving you Trouble? A Corpus-based Examination of the Differences between the Nouns 'problem' and 'trouble'. Thoughts 2018(2): 1-25. [ Links ]
Johansson, S. 2007. Seeing through Multilingual Corpora: On the Use of Corpora in Contrastive Studies. Facchinetti, R. (Ed.). 2007. Corpus Linguistics 25 Years On: 51-71.Amsterdam/NewYork: Rodopi. [ Links ]
Kaminski, M.P. 2017. Visualisation of Collocational Preferences for Near-Synonym Discrimination. Lexikos 27: 237-251. [ Links ]
Kruawong, T. and S. Phoocharoensil. 2022. A Genre and Collocational Analysis of the Near-Synonyms teach, educate and instruct: A Corpus-Based Approach. TEFLIN Journal 33(1): 75-97. [ Links ]
Ledinek, N. and M. Michelizza. 2021. Gender in Slovenian Monolingual General Explanatory Dictionaries. Collegium antropologicum 45(4): 329-339. [ Links ]
Lewis, M. 2000. There is Nothing as Practical as a Good Theory. Lewis, M. (Ed.). 2000. Teaching Collocation: Further Developments in the Lexical Approach: 10-27. Hove, UK: Language Teaching Publications. [ Links ]
Liu, D. 2010. Is it a Chief, Main, Major, Primary, or Principal Concern: A Corpus-based Behavioral Profile Study of the Near-synonyms. lnternational Journal of Corpus Linguistics 15(1): 56-87. [ Links ]
Liu, D. 2013. Using Corpora to Help Teach Difficult-to-distinguish English Words. English Teaching 68(3): 27-50. [ Links ]
Liu, D. and M. Espino. 2012. Actually, Genuinely, Really, and Truly: A Corpus-Based Behavioral Profile Study of Near-synonymous Adverbs. lnternational Journal of Corpus Linguistics 17(2): 198-228. [ Links ]
Liu, W. 2020. A Corpus-Based Study of Semantic Prosody and Semantic Preference of "seem". Open Journal of Social Sciences 8: 282-291. [ Links ]
Mair, C. and M. Markus (Eds.). 1992. New Departures in Contrastive Linguistics. Proceedings of the Conference Held at the Leopold-Franzens-University of Innsbruck, Austria, 10-12 May 1991. 2 Vols. Innsbruck: University of Innsbruck Press.
Mathiasen, E.J. 2017. A Study of Gender in a Bilingual Law Dictionary (English/Spanish). Revista Española de Lingüística Aplicada 30(1): 370-394. [ Links ]
Miller, G.A. 1999. On Knowing a Word. Annual Review of Psychology 50(1): 1-19. [ Links ]
Miller, G.A. and W.G. Charles. 1991. Contextual Correlates of Semantic Similarity. Language and Cognitive Processes 6(1): 1-28. [ Links ]
Nida, E.A. 1975. Componential Analysis of Meaning. The Hague/Paris: Mouton. [ Links ]
Norri, J. 2019. Gender in Dictionary Definitions: A Comparison of Five Learner's Dictionaries and Their Different Editions. English Studies 100(7): 866-890. [ Links ]
O'Dell, F. and M. McCarthy. 2008. English Collocations in Use: Advanced. Cambridge: Cambridge University Press. [ Links ]
Opasic, M. 2010. Hrabar, odvazan, izazovan ... pothvat Ljiljane Saric i Wiebke Wittschen. Fluminensia: casopis za filoloska istrazivanja 22(2): 175-180 (review). [ Links ]
Palmer, F.R. 1981. Semantics. Cambridge: Cambridge University Press. [ Links ]
Petcharat, N. and S. Phoocharoensil. 2017. A Corpus Based Study of English Synonyms: appropriate, proper and suitable. LEARN Journal: Language Education and Acquisition Research Network 10(2): 10-24. [ Links ]
Petrovic, B. 2005. Sinonimija i sinonimicnost u hrvatskome jeziku. Zagreb: Hrvatska sveucilicna naklada. [ Links ]
Phoocharoensil, S. 2020. A Genre and Collocational Analysis of Consequence, Result, and Outcome. 3L: Southeast Asian Journal of English Language Studies 26(3): 1-16. [ Links ]
Phoocharoensil, S. 2021. Semantic Prosody and Collocation: A Corpus Study of the Near-synonyms persist and persevere. Eurasian Journal of Applied Linguistics 7(1): 240-258. [ Links ]
Piits, L. 2013. Distributional Hypothesis: Words for 'human being' and their Estonian Collocates. Trames 17(2): 141-158. [ Links ]
Prcic, T. 2010. Sinonimija u teoriji i praksi: isto ali ipak razlicito. Jezik danas. Available at: www.gewi.uni-graz.at/gralis/Liguistikarium/Lexikologie/BKS/Lexikologie_BKS/Prcic_Sinonimija.htm [Last accessed 10 March 2021].
Quine, W.v.O. 1951. Two Dogmas of Empiricism. The Philosophical Review 60: 20-43. (Reprinted in Quine, W.v.O. 1953. From a Logical Point of View. Cambridge: Harvard University Press.)
Sayyed, S.W. and R.R. Al-Khanji. 2019. A Corpus Based Analysis of Eight English Synonymous Adjectives of Fear. International Journal of Linguistics 11(1): 111-138. [ Links ]
Sinclair, J. 2004. Trust the Text: Language, Corpus and Discourse. (Edited with Ronald Carter.) London/New York: Routledge. [ Links ]
Song, Q. 2021. Effectiveness of Corpus in Distinguishing Two Near-Synonymous Verbs: 'Damage' and 'Destroy'. English Language Teaching 14(7): 8-20. [ Links ]
Stoyanova-Georgieva, I. 2020. Expressing Attitude and Evaluation through Intensifiers Examined through the Prism of Semantic Prosody. Knowledge - International Journal 38(6): 1403-1408. [ Links ]
Stubbs, M. 2001. Words and Phrases: Corpus Studies of Lexical Semantics. Oxford: Blackwell. [ Links ]
Sumonsriworakun, P. 2022. A Corpus-based Investigation of English Synonyms: Disadvantage, Downside and Drawback. LEARN Journal: Language Education and Acquisition Research Network 15(2): 649-678. [ Links ]
Thongpan, N. 2022. A Corpus-Based Study of English Synonyms of the Adjectives 'Far', 'Distant' and 'Remote'. Journal of Positive School Psychology 6(6): 3986-4001. [ Links ]
Turney, P.D. and P. Pantel. 2010. From Frequency to Meaning: Vector Space Models of Semantics. Journal of Artificial Intelligence Research 37: 141-188. [ Links ]
Westveer, T., P. Sleeman and E.O. Aboh. 2018. Discriminating Dictionaries? Feminine Forms of Profession Nouns in Dictionaries of French and German. International Journal of Lexicography 31(4): 371-393. [ Links ]
Xiao, R. and T. McEnery. 2006. Collocation, Semantic Prosody and Near Synonymy: A Cross-linguistic Perspective". Applied Linguistics 27(1): 103-129. [ Links ]
Yang, B. 2020. A Corpus-based Study of Synonymous Epistemic Adverbs Perhaps, Probably, Maybe and Possibly. Research Journal of Education 6(8): 158-168. [ Links ]
Tao, Y. 2021. Study of Near Synonymous Mental-State Verbs: A MARVS Perspective. Proceedings of the 35th Pacific Asia Conference on Language, Information and Computation: 432-441. Shanghai, China: Association for Computational Linguistics.
Zhang, F. 2002. Componential Analysis Method. Munich: GRIN Publishing GmbH. [ Links ]