










Serviços Personalizados
Artigo
 Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
Indicadores

Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkLexikos
versão On-line ISSN 2224-0039
versão impressa ISSN 1684-4904
Lexikos vol.31 Stellenbosch 2021
http://dx.doi.org/10.5788/31-1-1651
5. Data boxes as dictionary entries
5.1 Data boxes and addressing relations
The addressing structure and various addressing relations in dictionaries are important to identify the scope of each item in a dictionary article and the target of its treatment. According to Hausmann and Wiegand (1989: 328) a treatment unit results "when a form mentioned and information relating to that form are brought together. The relation of form and information is that of topic and comment." The "way in which a form and information relating to that form are brought together is the addressing procedure." Each information item is addressed to a form that is known as its address.
Data boxes are functional constituents of dictionaries and should not be employed as mere procedures of lexicographic face-lifting. They are included in dictionaries as part of the lexicographic treatment procedures. When allocating a data box to a specific search zone cognizance needs to be taken of the specific treatment contributed by the data box. Dictionary users should know exactly what constitutes both the address and the addressing relation of each data box.
To ensure an optimal comprehension of the relevant addressing relation, it is important that the notion of addressing has to be employed in an unambiguous way. In this article the procedures of addressing as discussed in Gouws (2014) will be employed. Wiegand and Gouws (2013) restrict addressing to relations within condensed articles where items display the addressing relations. Wiegand and Gouws (2013: 273) say that there are no addressing relations in non-condensed dictionary articles or in other non-condensed accessible entries. This implies that an item like a lemma sign cannot be addressed by an item text, even if the item text contributes to the treatment of the lemma. In contrast to this approach, Gouws (2014: 183) expands the application of the notion of addressing. The term addressing is used to incorporate both primary addressing which is the traditional procedure prevailing in condensed articles, and secondary addressing to go beyond textual condensation and item status as prerequisites for addressed entries. In accordance with this approach both items and item texts can participate in procedures of addressing. The addressing element and its address do not have to be in the same dictionary article and addressing can occur between different types of constituents of a word list, e.g. also between a phased-in inner text and an item in a dictionary article.
5.2 The position for data boxes and the different types of data box entries
In accordance with the data distribution structure of a specific dictionary the lexicographer has to allocate data-carrying segments to the different search positions in the dictionary. Where a dictionary displays a frame structure the positioning of data in the articles of the word list will be complemented by text constituents or other entries presented in the front and/or back matter sections of that dictionary. As a carrier of text types a dictionary could also include outer texts in its middle matter section.
Dictionaries have different search positions, traditionally ranging from a search zone within a dictionary article to the article as search area and the word list, the largest search position, as search field, cf. Wiegand, Beer and Gouws (2013: 63). Gouws (2018: 228) argued in favour of a further and more comprehensive search position, i.e. the search region. This search position is constituted by all the textual components of a dictionary as a text compound. For a single volume dictionary this is the most comprehensive search position. Although the outer texts of the front and back matter sections of a dictionary fall outside the domain of the search field they are part of the search region of a dictionary. Data boxes typically occur within a word list, that is a search field, of a dictionary. This could be within the central and only word list which is the most frequent occurrence of data boxes, or within any other word list that is part of a word list series of a given dictionary. Looking at data boxes in this article, the focus will only be on those data boxes occurring in a word list, i.e. within the search field of dictionaries. Data boxes in outer texts will not be discussed.
As entries in a search field the status of all data boxes is not the same. Data boxes could be phased-in inner texts, article-internal item texts or mere items occupying a search zone in a dictionary article. These different types of data boxes will be discussed in the subsequent sections.
5.3 Expanded word lists
The data distribution structure of any dictionary determines the way in which the lemmata presenting the macrostructural coverage of the dictionary have to be ordered within the word list of that dictionary. Whether it is a straight alphabetical ordering or an ordering with sinuous lemma files that enables the use of niched and nested lemmata, a word list will consist of a number of article stretches that accommodate articles with the lemmata as their guiding elements.
When planning the data distribution structure of a dictionary lexicographers need to make a decision regarding the type of word list the dictionary will display. This is determined by specific features of the nature of data allocated to the word list. In this regard a distinction is made between a single word list and an expanded word list, cf. Bergenholtz, Tarp and Wiegand (1999: 1766). A single word list contains article stretches but no inserts or phased-in inner texts, whereas an expanded word list also contains article stretches as well as inserts and/or phased-in inner texts. These inserts and phased-in inner texts split sequences of articles within partial article stretches. Therefore an expanded word list is also known as a split word list.
The distinction between inserts and phased-in inner texts is significant for the identification of data boxes.
5.3.1 Distinguishing between inserts and phased-in inner texts
5.3.1.1 Inserts
According to the Wörterbuch zur Lexikographie und Wörterbuchforschung/Dictionary of Lexicography and Dictionary Research (Wiegand et al. 2017), (henceforth abbreviated as WLWF) an insert is a text or text part that is inserted into the word list of a dictionary. It is an immediate constituent of the dictionary as a text compound. Inserts often are sections of photos, inserted between two article stretches or between two pages of an article stretch. In the Merriam-Webster's Advanced Learner's English Dictionary (Perrault 2008), (henceforth abbreviated as MWALD), the article stretch of the letter M is split between the lemmata mascot and masculine by an insert titled Color Art. This insert, with its own table of contents, contains pictures of themes like colours, vegetables, landscapes, gems and jewellery and clothing. These pictures do not adhere to the alphabetical ordering within the article stretch and although it splits the word list this insert is not an immediate constituent of either the specific article stretch or the word list. It is an immediate constituent of the dictionary as text compound and carrier of text types. Consequently inserts cannot be regarded as a type of data box or the type of data box discussed in this article.
The form of inserts sometimes resemble that of data boxes, e.g. the section on birds in an insert from the MWALD contains pictures of a variety of birds and the data box occurring in the article of the lemma deer, cf. figure 18 in paragraph 5.5.2.1, contains a number of pictures of different types of deer. Although both these text constituents are carriers of pictures, the insert is a different type of lexicographic text and will not be discussed any further in this article.


















5.3.1.2 Phased-in inner texts
Phased-in inner texts occur in expanded word lists where they split the article stretches, resulting in internally expanded article stretches (Bergenholtz, Tarp and Wiegand 1999: 1766). The phased-in inner texts typically contain data relevant to a lemma in close proximity within the same article stretch and often also to other lemmata occurring in remote articles. The data in the phased-in inner texts can also have a more general relevance to the specific lemma or might link thematically with it. Phased-in inner texts often have an inner text title that can concur, but not necessarily, with the lemma of an article in its proximity. This title could also identify the more general nature of the data in the specific text. These texts are usually typographically distinguishable from default articles as constituents of a word list by being framed or presented with a coloured background. Examples will be provided in a subsequent section of this article.
Article-internal data boxes and phased-in inner texts sometimes show strong resemblances but the nature of a specific box as a text constituent of the word list determines whether it has to be regarded as an article-internal box or a box presented as phased-in inner text.
5.4 Article-internal data boxes
5.4.1 Items and item texts
One of the most frequent occurrences of data boxes is within dictionary articles. As constituents of articles data boxes do not form part of the obligatory micro-structure but rather enrich the obligatory microstructure, resulting in an extended obligatory microstructure. Data boxes in dictionary articles mostly contain text data but they can also display non-textual data. Data boxes are not default entries in any article but their use can be regarded as an extended treatment procedure. They can either contain items or item texts. Wiegand and Smit (2013: 153) distinguish as follows between items and item texts:
An item is a functional text segment without the status of a sentence but with the status of a text segment which is given as a discernible item form assigned with at least one genuine function, the latter being precisely such that a user can obtain knowledge about the item's subject as lexicographical information.
An item text is a functional text segment with item function and text constituent status exhibiting a complete and distinct natural-language syntactical structure and consisting of at least one sentence.
As constituents of dictionary articles data boxes may contain data presented in either condensed or non-condensed format. The articles in figure 1, a partial article stretch from the monolingual Afrikaans learner's dictionary Basiswoordeboek van Afrikaans (Gouws et al. 1994), (henceforth abbreviated as BW) contain two data boxes with items giving the pronunciation of the word represented by the lemma of the specific article. This dictionary only gives pronunciation guidance for a limited number of selected lemmata. It is not part of the obligatory microstructure and when pronunciation guidance is regarded as necessary, it is presented in a data box accommodated in the final slot of the article. The entries "Uitspraak 'gemie'" (= Pronunciation 'gemie') and "Uitspraak 'sjirurg'" (= Pronunciation 'sjirurg') are condensed forms and thus items.
The data box in figure 2 from the Junior Tweetalige Skoolwoordeboek/Junior Bilingual School Dictionary, (Stoman et al. 2018), (henceforth abbreviated as JBS) contains a sentence which is an entry given in non-condensed form. This entry therefore is an item text.
Whether entries are items or item texts may have implications for the addressing relations in an article. This will be discussed in a further section of this article.
5.4.2 Positioning data boxes within dictionary articles
Data boxes are functional dictionary entries because they contribute to achieving the genuine purpose of the dictionary in which they occur. That implies that from the data on offer in a data box users must be able to retrieve information that can assist them in finding a solution to the problem that initiated the specific dictionary consultation procedure. Because data boxes result from extended treatment procedures and are usually not entries belonging to the obligatory microstructure of a dictionary, users will not know beforehand whether an article contains a data box. That is why it is important that these boxes need to be clearly marked as framed or coloured text constituents. Dictionary articles have no fixed slot reserved for data boxes. When planning the data distribution structure of a dictionary lexicographer's need to decide on the slots in dictionary articles that could accommodate search zones populated by data boxes. Data boxes could be placed in different text positions in dictionaries, cf. Taljard et al. (2014: 698). They could be included within the comment on form or comment on semantics or in an alternative position, e.g. as precomment or postcomment.
5.4.2.1 Data boxes at the end of an article
One of the most typical positions allocated to data boxes, cf. Gouws and Prinsloo (2010), is a slot at the end of the article. In such a position the data box often falls beyond the scope of either the comment on form or the comment on semantics. As postcomment the data box is in a position of salience - further accentuated by its frame or colouring. Figure 3 shows the article of the lemma sign especially in the Oxford Advanced Learner's Dictionary of Current English (Turnbull 2010), (henceforth abbreviated as OALD):
The obligatory microstructure ends with the items in the third subcomment on semantics. The lexicographers have felt the need to present the users with additional guidance regarding the use of the words especially and specially. The data box containing this data has the title "Which Word?" and is presented after the comment on semantics as a postcomment to the article. Another example of a box presented as postcomment in the same dictionary can be found in the article of the lemma sign restaurant, figure 4. A type of data box frequently given in this dictionary contains collocations, but not necessarily collocations in which the word represented by the lemma functions as either base or collocator, but rather collocations applicable in the semantic domain of the word represented by the lemma sign. The user gets assistance regarding typical collocations used when dining in a restaurant:
The OALD presents the entries in data boxes against a blue background. These data boxes can easily be identified by the users of this dictionary.
There is no restriction on the number of data boxes per article, but lexicographers need to be careful not to have a data box overload that could diminish the emphasis on these boxes. An inflation of data boxes should therefore be avoided, but even more than one clearly marked data box per article should still be in order, as seen in figure 5, the article of the lemma sign school in the OALD. The two boxes "British/American" and "Grammar Point" are clearly identifiable and can enhance the nature and extent of the lexicographic treatment in this article.
Where a data box is presented as postcomment in the article of a lemma representing a polysemous lexical item it is not always clear whether the treatment presented in the box is directed at only one or more senses or at all the senses of the word. This problem will be elaborated on in section 5.4.2.4.
5.4.2.2 Data boxes at the beginning of the article
The lemma sign of an article is part of the main outer access structure of the dictionary and a guiding element of the specific article. Irrespective of the type of information a user wants to retrieve from a dictionary article as search area the access to that item, especially in a printed dictionary, proceeds via the lemma sign onto the search paths of the inner access structure. Items positioned in search zones in close proximity of the lemma are in salient positions. The framed or coloured appearance of data boxes adds focus to their occurrence as text constituents of an article and if such a box is awarded a position close to the lemma sign it further elevates the salience of the data in the box.
The Macmillan Phrasal Verbs Plus (Rundell 2005), (henceforth abbreviated as MPVP) uses data boxes in a slot close to the beginning of an article, to provide an overview of the senses where the phrasal verb represented by the lemma sign has five or more than five senses. This box differs from other boxes because it does not contain the kind of data typically allocated to data boxes. It displays items conveying the menu of the comment on semantics and they function as navigational entries in this article. Alternative strategies for the provision of such navigational guidance could for instance be shortcuts, signposts and guidewords and will be discussed in detail in Part 2 of this series. The box as seen in figure 6 functions in such an article as a precomment.
Data boxes are also included as precomments of articles in the Macmillan English Dictionary (Rundell 2007), (henceforth abbreviated as MED). In figure 7, the article of the lemma sign above, the data box contains data regarding the use of the word above in its occurrence in different parts of speech. It makes the user aware of the differences between these uses.
To ensure that the target user of this learner's dictionary will focus on the differences between the uses of the word, this data can at best be presented in a precomment instead of being subsumed under the cotextual items in different comments or subcomments on semantics of one of the three partial articles of this twofold complex dictionary article, cf. Wiegand and Gouws (2011: 242).
Because the beginning of an article is a significant position of salience in a dictionary article lexicographers should carefully consider the type of data boxes to include in that search zone.
5.4.2.3 Data boxes as article windows
Lexicographers often have innovative ideas regarding the way of presenting data in their dictionaries. In the OALD several types of data boxes are used, with some types reserved for specific types of data. An article window is a type of data box reserved for a single type of data, i.e. word families, as seen in figure 8:
In the front matter text "Key to dictionary entries" it is said that: "Word families show words related to the headword." Although articles could in principle have windows in different article positions, e.g. top right, top centre, top left, middle right, middle centre, middle left, bottom right, bottom centre and bottom left, the OALD primarily uses the top right corner for its window data boxes. However, the layout of a dictionary article on the page could also have an influence on the position of the window. The editors of the OALD are consistent in always placing data boxes presented in article windows in the top right corner of a text block, albeit not necessarily of the article. Where an article commences at the bottom of a column there could be a lack of space for a window in the top right corner of the article, as seen in figure 9.
However, the window is then positioned in the top right corner of the text block, containing the remainder of the article, that starts in a new column, as seen in figure 10.
Technically such a window occupies the right centre of the article. From a layout perspective it could be argued that the OALD always presents its windowed data boxes in the top right corner of a text block, preferably but not always the top right corner of the article.
A brief identification of word families as found in the article windows can be valuable assistance to the target users of this dictionary. Users should be aware of this assistance but unfortunately the OALD does not provide an outer text in the front matter section with a list of articles that contain these windows. In spite of the focus that a data box puts on this data, there is no defined search path besides the main alphabetical outer access structure to guide users to these articles that contain article windows. This lack of predictable access impedes the added value of these article windows.
5.4.2.4 Data boxes within a comment of an article
Whether an article-internal data box contains an item or an item text, the contents of that data box is presented as part of a treatment procedure. This procedure is directed at one or more specific treatment units that constitute the address within this procedure of addressing. The positioning of article-internal data boxes directly reflects the relevant addressing relations in which data boxes can become involved.
Although lemmatic addressing, i.e. with the lemma as address, is the most frequently used addressing procedure in dictionaries, other types of addressing also prevail, especially non-lemmatic addressing. Various aspects of addressing are dealt with in Hausmann and Wiegand (1989), Louw and Gouws (1996), Gouws and Prinsloo (2005), Wiegand (2006; 2011) and Gouws (2014). Lexicographers utilise data boxes to emphasise certain entries not accounted for by items in search zones of the obligatory microstructure of a dictionary. These items or item texts do not always have the lemma as address, but often occur within one of the comments of an article, especially the comment on semantics or a subcomment on semantics, where they participate in relations of non-lemmatic addressing. A less optimal article-internal positioning of a box of which the entry or entries are not addressed at all the senses of the word represented by the lemma sign of the article may diminish the added value the data box is supposed to have. In figure 11 from the Handwoordeboek van die Afrikaanse Taal (HAT) (Odendal and Gouws 2005) the data box is included as postcomment at the end of the article. The contents of the box only applies to the use of the word instansie in its second and third senses. From this presentation it is not clear that the box is not addressed at the first sense.
Figure 12 is a partial article of the lemma open2from the Longman Exams Dictionary (Summers 2006), (henceforth abbreviated as LED). This article contains two data boxes, so-called study notes. Both these data boxes are presented within single subcomments on semantics for the first and the second sense of the polysemous word open. By positioning them there the lexicographer ensures that the user can know what the exact address of the data box is:
In the Longman South African School Dictionary (Bullon et al. 2007, (henceforth abbreviated as LSASD)) the article of the lemma sign name1has three subcomments on semantics. The thesaurus data box is positioned at the end of the first subcomment on semantics. The thesaurus guidance in the data box is only applicable to the first sense of the word name.
Figure 14 from BW shows a data box that only has the first sense of the word opmerking as its address. Such a procedure of immediate addressing is to the benefit of the target user of the dictionary and demands less dictionary using skills compared to correctly interpreting the address of a data box that is not positioned in close vicinity to its address, even if the user was able to identify the appropriate sense:
Where the treatment in a data box is directed at only one of the senses of a polysemous word or at only one of the items in the article and the data box is not positioned in such a way that an immediate addressing relation is possible, the lexicographer should clearly indicate what the address of the contents of the data box is. Such an approach is seen in figure 15, the article of the lemma mad in the Oxford Afrikaans-Engels/English-Afrikaans Skoolwoordeboek/School Dictionary (Pheiffer 2007), (henceforth abbreviated as OSD):
In this article with its four subcomments on semantics, the data box has been included as postcomment but it is clearly stated that it is addressed at the first sense.
Where a word can be used in more than one part of speech, the lexicographic treatment typically results in a complex article with a partial article for the occurrence of each of these parts of speech (Wiegand and Gouws 2011: 243). Data boxes could then be positioned in a search zone of one of the partial articles so that the other part of speech occurrence of the word falls beyond the scope of the data box. This can be seen in figure 16 from BW where the data box is positioned at the end of the first partial article of the article with the lemma smaak as guiding element.
5.5 Phased-in inner texts as data boxes
5.5.1 Article-external text boxes
Data boxes can also be accommodated in the word list of dictionaries as phased-in inner texts. These data boxes are immediate constituents of the article stretches of the word list and function as article-external data carriers. Data boxes presented as phased-in inner texts typically have a connection with a lemma that is the guiding element of an article occurring in the specific article stretch into which the data box is phased in. These data boxes can be items or item texts and participate in either primary or secondary addressing relations. In addition to having the lemma that is in close proximity as address, these data boxes can also participate in relations of remote addressing, cf. Louw and Gouws (1996), where one or more lemmata in the same or often in other article stretches can be the address. As is the case with article-internal text boxes, different types of data can be presented in these data boxes, cf. Wiegand et al. (2017: 140-144 (WLWF)).
Phased-in inner texts could be constituents of the word list of a dictionary with a single alphabetical macrostructure or constituents of different word lists of dictionaries with poly-alphabetical macrostructures with vertical or horizontal parallel alphabetical access structures, cf. Wiegand (1989: 402) and Wiegand and Gouws (2013: 88). In the remainder of this section the focus will primarily be on phased-in inner texts in single macrostructures but reference will briefly be made to their occurrence in dictionaries with poly-alphabetical macrostructures with vertical parallel alphabetical access structures.
5.5.2 Phased-in inner texts in the primary macrostructure
In an expanded word list different types of phased-in inner texts can be included to split the article stretches.
5.5.2.1 Data boxes phased out of the article
In paragraph 5.4.2.3 it was mentioned that the layout of a dictionary page could influence the positioning of text boxes presented as article windows. In a comparable way the structure and layout of a dictionary article and the physical size of a specific item could lead to such an item not being included as micro-structural constituent but rather in an article-external data box. This is where a phased-in inner text is the result of an item phased out of an article and phased into the article stretch as a data box.
Due to the position of an article in a column and on a page and due to their size pictorial illustrations do not always fit into the boundaries of an article as search area. The application of a well-defined data distribution structure may then lead to a situation where such a pictorial illustration is phased out of the article and presented within a data box included as phased-in inner text.
The MWALD often contains pictorial illustrations as items in its articles, as can be seen in figure 17, the article of the lemma glove:
No pictorial illustration is presented within the borders of the article of the lemma sign deer in the MWALD. However, an illustration does occur on the same page, in an article-external position, as can be seen in figure 18 where the illustration is entered across two columns and splits the partial article stretch between the articles of the lemmas defamatory and defame:
It could have been problematic for the lexicographers to fit this illustration into the article of the lemma deer. Consequently it has been phased out of the article and positioned as a phased-in inner text in the article stretch, where its title has the same form as the article of the lemma deer. Because the pictorial illustration is in close proximity of the article of the lemma deer, this article has no reference to the pictorial illustration.1
In dictionaries a distinction can be made between single and synopsis articles, cf. Bergenholtz, Tarp and Wiegand (1999: 1780). The treatment in a single article is directed only at the lemma of that article, whereas the treatment in a synopsis article also contains data relevant for the treatment of the lemmata of other articles. Data boxes also have a single or a synopsis character. This applies to article-internal as well as article-external data boxes. Figure 19, the article for the lemma lend in the Tweetalige aanleerderswoordeboek/Bilingual Learner's Dictionary (Du Plessis 1993), (henceforth abbreviated as TAW), has an article-internal data box presented as postcomment. The contents of this data box apply to the lemma lend but it is also remotely addressed at the lemma borrow. Figure 20 shows the article of the lemma borrow with an item giving a cross-reference to lend.


The data box in the article of the lemma lend is a synopsis data box. In a similar way the data box titled deer is a synopsis data box. The pictures are also relevant for the treatment of lemmata like moose, elk and caribou. Consequently the articles of these lemmata have an item giving a cross-reference "see picture at DEER".
Positioning the contents of the data box deer not within the article but as an article-external phased-in inner text, can probably best be motivated on article and page layout grounds. A similar use of data boxes where the data have been phased out of an article and into a data box functioning as phased-in inner text, is found in the Cambridge International Dictionary of English (Procter 1995), (henceforth abbreviated as CIDE). Figure 21 shows the framed data box Molluscs presented as a phased-in inner text. The contents of this box could have been included in the nearby article of the lemma mollusc. The layout of the column might have been disturbed by this illustration and consequently it was phased-out into a data box in the partial article stretch but still in close vicinity of the lemma sign. This is also a synopsis data box that functions as the cross-reference address for cross-reference items in the articles of lemmata like cuttle fish, octopus and snail:

Phasing-out procedures do not only target non-boxed data that could have been included in a search zone of an article and allocate them to an article-external data box. These procedures can also target data boxes that could have had an article-internal position and phase them out to function as article-external data boxes and phased-in inner texts. The OALD frequently includes a text box containing synonyms in a postcomment position of an article, as can be seen in figure 22, the article of the lemma painful:

This can be regarded as the default positioning of a data box that contains synonyms. The data box for synonyms is often phased out of the article and positioned as a data box and phased-in inner text in the textual position immediately preceding the article. This is probably due to article and page layout considerations, a column break and the approach not to allow column or page breaks to divide a data box into two sections but always to present such a data box as an uninterrupted text block. This can be seen in figure 23, the article of the lemma surprise:

The biggest section of the article of the lemma surprise appears in the left column with a brief section of this article continuing in the right column. Had this section also been included in the left column there would probably not have been room for an uninterrupted data box as postcomment in that column. Consequently the data box was phased out to an article-external position, preceding the article. This data box is not positioned as precomment because it lies outside the article borders.
Because the planned data distribution structure of a dictionary needs to be executed in a meticulous and consistent way, it is not plausible to deviate from such a structure for column or page break or article or page layout reasons. Such a deviation impedes the access of users to the required data. The structural inconsistency resulting from the phasing out of items to article-external data boxes can be seen in the treatment of the lemma save in the OALD. In the OALD synonyms are frequently provided in data boxes, as seen in the treatment of painful. Irrespective of the degree of complexity of an article (whether it is a single or an n-fold complex article) or the number of senses treated in one or more subcomments on semantics, article-internal data boxes containing synonyms are presented as postcomments. Although such a positioning of the data box may cause addressing uncertainty in complex articles or articles with polysemous lexical items as lemmata, knowledgeable users will become familiar with this positioning of data boxes if this execution of the data distribution structure is done in a consistent way.
Column and page breaks result in deviations of this execution of the default data distribution structure. The treatment of the lemma save is presented in a threefold complex article with partial articles for the use of the word save as different parts of speech, namely as verb, noun, preposition and conjunction. The partial article treating the occurrence of save as a verb accounts for eight polysemous senses of this word, presented in different subcomments on semantics. The treatment is interrupted by a column and page break within the eighth subcomment on semantics. For the senses presented in the first two subcomments on semantics synonyms are provided in data boxes. The data box containing the synonyms for the first sense is included article-internally, according to the default data distribution of this type of text constituent, as a postcomment. However, the data box containing synonyms for the second sense has been phased out to a position immediately preceding the article of the lemma save as an article external phased-in inner text. This can be seen in figure 24 that shows the article as it is spread over the right column of the first and the left column of the second page:

Successfully accessing this data will be challenging for even a knowledgeable user of this dictionary. This is a typical situation where procedures in the lexicographic practice, i.e. allowing column and page breaks to impede the execution of the default data distribution structure, has resulted in theory-determined dictionary structure problems. A more user-friendly way of dealing with these two data boxes would have been to either add them both as postcomments (reflecting the order of the senses at which they are addressed) or, even better, include each data box in a slot in the relevant subcomment on semantics. This would have enabled procedures of immediate addressing that would have assisted users in a quicker and better retrieval of information.
In some articles the inconsistency in the positioning of synonym data boxes in the OALD on column and page break grounds, results in such an article-internal data box not being included as the default postcomment but rather within the comment on semantics. The lemma reason has a single complex article with partial articles for its occurrence as noun and as verb. The article is interrupted by a column and page break, as seen in figure 25:

The comment on semantics of the partial article in which the occurrence as noun is treated, makes provision for four polysemous senses of this word. A data box is provided that contains synonyms for the first sense of this word. In order to present an uninterrupted text block the data box containing synonyms is positioned within the comment on semantics of the partial article in which the occurrence of reason as a noun is treated. It is positioned at the end of the first column on the first page on which the article is given. The data box occurs within the subcomment on semantics in which the second sense is treated, even though the synonyms are addressed at the first sense of the word. This positioning defies logical and consistent addressing relations.
5.5.2.2 Article-external data boxes resembling articles or article-internal items
Data boxes included in the word list as phased-in inner texts are often inserted between two other articles in a partial article stretch where it adheres to the alphabetical ordering. These data boxes typically have a guiding element that looks like a lemma and the box contains a rudimentary treatment of that word. In the TAW the word fridge had not been selected as a lemma candidate. However, the lexicographer must have felt the need to make the users of this learner's dictionary aware of that informal English word. Consequently, a data box was included as a phased-in inner text and inserted in its alphabetical position in the article stretch between the articles of the lemmata Friday and friend, as seen in figure 26, with the frame clearly identifying it as a data box and not a default article:

Figure 27, a partial article stretch from Groot Woordeboek/Major Dictionary (Eksteen et al. 1997); (henceforth abbreviated as GW), contains the data box with percentage point as its guiding element. This box follows the article niche attached to the article of the lemma percentage. This niche also contains the sublemma percentage point in a condensed format. In the niche the treatment of the lemma is restricted to an item giving a translation equivalent. The lexicographer wants to increase the assistance to users regarding this lemma and consequently employs the phased-in data box to supply the expression percentage point with a paraphrase of meaning.

Data boxes do not always look like articles but can occur in the alphabetical position of a word that has not been included as lemma, in order to make the user aware of some relevant feature of that word. In Afrikaans the word huidiglik (=presently) is often used. However, from a linguistic perspective the use of this word is not approved. The word does not qualify for inclusion as a lemma, but the lexicographers of the monolingual Afrikaans school dictionary the Oxford Afrikaanse Skoolwoordeboek (Louw 2012), (henceforth abbreviated as OSW) would like to make their users aware of the fact that the word should not be used. The word tans should rather be used. In the alphabetical slot where huidiglik would have been entered had it been a lemma in this dictionary, the lexicographers include an article-external data box, cf. figure 28, to sensitise users that they should not use the word huidiglik.

The data box in figure 28 is not a postcomment in the article of the lemma huidige but rather a phased-in inner text.
Article-external data boxes often include data that do not represent a data type that belongs to the default microstructural items but it does add to the treatment of a given lemma or lemma cluster. Figure 29 presents a partial article stretch from HAT:

In the comment on form of the article of the lemma horlosie (watch) it is indicated that oorlosie is a variant form of horlosie. Attached to the article of this lemma is a lemma cluster, presented as a first level nest that includes a condensed presentation of compounds with horlosie- as first stem. Between this nest and the following main lemma a data box has been inserted with guidance regarding the formation of compounds with horlosie- as first stem. Although this data is relevant to the main lemma horlosie- and to the sublemmata presented in the nest, the data box is positioned outside the article of the main lemma as well as the nest of sublemmata and therefore it is a phased-in inner text.
5.5.2.3 Other article boxes included as phased-in inner texts
A variety of other types of data boxes also function as phased-in inner texts in dictionaries. A typical feature of many of these data boxes is their synopsis character whilst the data presentation in others complements and expands the default data coverage of a specific lemma. These data boxes convey data regarded by the lexicographer as important enough to include them in salient search venues like data boxes. The added value of these data boxes is unfortunately too often impeded by insufficient access guidance.
In close proximity of the article of the lemma plural in CIDE one finds the data box titled "Plural of nouns", presented in figure 30:

The treatment in this data box is not addressed at any single lemma but it adds value to the treatment of all nouns that take plural. The problem is that it is very difficult for users in need of this guidance to know where to find the help. CIDE has a back matter text that provides an alphabetical index with relevant page numbers of all pictures, language portraits and lists of false friends included in the word list. The list includes an entry "Plurals" but no entry "Plural of nouns", the title of the data box in figure 30. It will remain a challenge for the target users of this dictionary to optimally benefit from this data box. They will probably only have access to this data box if they accidentally consult that page, seeing that the lemma plural is on the previous page and its article has no cross-reference to the data box.
Having consulted the lemmata meet and meeting in the CIDE a user has to turn the page to find the data box "Meeting someone", given in figure 31:

This data box contains pragmatic and cultural guidance that could assist the envisaged target users of this dictionary in their daily communication. Skilled users will be able to access this data box via the back matter list. However, for the user not aware of that list it would have been better if this data box could have been positioned on the same page where the lemmata meet and meeting appear.
On the same page in CIDE where the lemma dash is treated a data box has been presented that offers valuable complementary assistance regarding the use of a dash, cf. figure 32:

The contents of a data box like this one can hardly be included in the article of the corresponding lemma. Data boxes like these elevate the quality of the lexicographic treatment.
Even if an article in a learner's dictionary displays an extended obligatory microstructure lexicographers have to restrict the extent of the data presented in the different search zones and should refrain from procedures of data overload. If lexicographers want to respond to the needs of the users of a learner's dictionary, like CIDE, for some linguistic guidance typically contained in text books, they can use data boxes included as phased-in inner texts to convey this kind of data. Figure 33, a partial article stretch from CIDE, contains articles of the lemmata homograph and homophone. In each one of these articles there is an item giving a cross-reference to the language portrait (LP) Homophones and homographs.

This language portrait is presented as the data box seen in figure 34. This data box can also be accessed via the index in the back matter text. It has a synopsis character that could assist users in clearly distinguishing between homophones and homographs.

5.5.3 Phased-in inner texts in the secondary constituent of a parallel macro-structure
Dictionaries can have more than one word list and therefore more than one macro-structure. More than one macrostructure could prevail within the same alphabetical constituent of a dictionary. One such type identified by Wiegand (1989: 402) and Wiegand and Gouws (2013: 88) is the poly-alphabetical macrostructures with vertical parallel alphabetical access structures. The Reader's Digest AfrikaansEngelse Woordeboek/English-Afrikaans Dictionary (Grobbelaar 1987), (henceforth abbreviated as RWD), displays these macrostructures. The primary macrostructure of this dictionary is presented in two central columns on each page. An additional column on the left and an additional column on the right of the two central columns constitute a secondary macrostructure. The partial article stretch of the secondary macrostructure on each page falls within the alphabetical domain of the partial article stretch of the primary macrostructure on the same page. The RWD is an expanded version of a previously published bilingual dictionary. The primary macrostructure is an unchanged version of that of the previous dictionary. The secondary macrostructure is constituted by new text constituents. In the secondary word list there are articles that have a selection of lemmata from the primary macrostructure as guiding elements. A different and innovative treatment (not to be discussed here) has been executed in these articles. The secondary macrostructure displays an expanded word list with partial article stretches split by phased-in inner texts, as seen in figure 35:

The text boxes presented as phased-in inner texts are titled Words in action. They are addressed at some of the source and target language items in the articles of the primary macrostructure and they contain different types of data, e.g. pragmatic, usage, linguistic and lexical guidance.
The data boxes help to introduce new comments to enhance the quality of the original dictionary.
Conclusion
Data boxes occur frequently and in diverse ways in dictionaries. This is especially the case in printed dictionaries, although some electronic dictionaries, especially those that are based on printed dictionaries, also employ this type of lexicographic entry. Although various aspects of the use of data boxes have been discussed in metalexicographic literature, much still needs to be done in this regard. This paper focused on what data boxes are, identified them as a type of lexicographic entry and indicated where they are positioned in dictionaries and that they should be used in such a way that they add value to dictionaries. This can serve as an aid for future lexicographers who wish to employ data boxes in their dictionaries.
Endnote
1 The value of a picture presenting different types of deer (but not all types) is not discussed here. The decision to give a pictorial illustration rests with the lexicographer. Therefore it cannot be expected that a specific word will be illustrated or illustrated in the same way in all dictionaries. For example, the online version of the MED does not contain such an illustration.
Acknowledgement
This work is based on the research supported in part by the National Research Foundation of South Africa (Grant specific unique reference numbers (UID) 85434 and (UID) 8576). The Grantholders acknowledge that opinions, findings and conclusions or recommendations expressed in any publication generated by the NRF supported research are that of the authors, and that the NRF accepts no liability whatsoever in this regard.
References
Dictionaries
BW = Gouws, R., I. Feinauer and F. Ponelis. 1994. Basiswoordeboek van Afrikaans. Pretoria: J.L. van Schaik.
CIDE = Procter, P. (Ed.). 1995. Cambridge International Dictionary of English. Cambridge: Cambridge University Press.
GW = Eksteen, L.C. et al. (Eds.). 199714. Groot Woordeboek/Major Dictionary. Cape Town: Pharos.
HAT = Odendal, F.F. and R.H. Gouws. 20055. Verklarende Handwoordeboek van die Afrikaanse Taal. Cape Town: Pearson Education South Africa.
JBS = Stoman, A. et al. (Eds.). 2018. Junior Tweetalige Skoolwoordeboek/Junior Bilingual School Dictionary. Cape Town: Pharos.
LED = Summers, D. (Ed.). 2006. Longman Exams Dictionary. Harlow: Pearson Education.
LSASD = Bullon, S. et al. (Eds.). 2007. Longman South African School Dictionary. Harlow: Pearson Education.
MED = Rundell, M. (Ed.). 20072. Macmillan English Dictionary for Advanced Learners. Oxford: Macmillan.
MPVP = Rundell, M. (Ed.). 2005. Macmillan Phrasal Verbs Plus. Oxford: Macmillan Education. MWALD = Perrault, S.J. (Ed.). 2008. Merriam-Webster's Advanced Learner's English Dictionary. Springfield, Massachusetts: Merriam-Webster.
OALD = Turnbull, J. (Ed.). 20108. Oxford Advanced Learner's Dictionary of Current English. Oxford: Oxford University Press.
OSD = Pheiffer, F. et al. (Eds.). 2007. Oxford Afrikaans-Engels/English-Afrikaans Skoolwoordeboek/School Dictionary. Cape Town: Oxford University Press Southern Africa.
OSW = Louw, P. (Senior Editor). 2012. Oxford Afrikaanse Skoolwoordeboek. Cape Town: Oxford University Press Southern Africa.
RWD = Grobbelaar, P. 1987. Reader's Digest Afrikaans-Engelse Woordeboek/English-Afrikaans Dictionary. Cape Town. The Reader's Digest Association, South Africa (Pty) Ltd.
TAW = Du Plessis, M. 1993. Tweetalige aanleerderswoordeboek/Bilingual Learner's Dictionary. Cape Town: Tafelberg.
WLWF = Wiegand, H.E., M. Beißwenger, R.H. Gouws, M. Kammerer, A. Storrer and W. Wolski (Eds.). 2017. Wörterbuch zur Lexikographie und Wörterbuchforschung/Dictionary of Lexicography and Dictionary Research. Vol. 2. Berlin/New York: Walter de Gruyter.
Other references
Bergenholtz, H., S. Tarp and H.E. Wiegand. 1999. Datendistributionsstrukturen, Makro- und Mikrostrukturen in neueren Fachwörterbüchern. Hoffmann, L. et al. (Eds.). 1999. Fachsprachen. Ein internationales Handbuch zur Fachsprachenforschung und Terminologiewissenschaft/ Languages for Special Purposes. An International Handbook of Special-Language and Terminology Research, Bd./Vol. 2: 1762-1832. Berlin: De Gruyter. [ Links ]
Gouws, R.H. 2014. Expanding the Notion of Addressing Relations. Lexicography: Journal of ASIALEX 1(2): 159-184. [ Links ]
Gouws, R.H. 2018. Expanding the Data Distribution Structure. Lexicographica 34: 225-237. [ Links ]
Gouws, R.H. and D.J. Prinsloo. 2005. Principles and Practice of South African Lexicography. Stellenbosch: SUN PReSS, AFRICAN SUN MeDIA. [ Links ]
Gouws, R.H. and D.J. Prinsloo. 2010. Thinking out of the Box - Perspectives on the Use of Lexicographic Text Boxes. Dykstra, A. and T. Schoonheim (Eds.). 2010. Proceedings of the XIV Euralex International Congress, Leeuwarden, 6-10 July 2010: 501-511. Leeuwarden: Fryske Akademy. [ Links ]
Gouws, R.H. and S. Tarp. 2017. Information Overload and Data Overload in Lexicography. International Journal of Lexicography 30(4): 389-415. [ Links ]
Gouws, R.H. et al. (Eds.). 2013. Dictionaries. An International Encyclopedia of Lexicography. Supplementary Volume: Recent Developments with Focus on Electronic and Computational Lexicography. Berlin/New York: De Gruyter. [ Links ]
Hausmann, F.J. and H.E. Wiegand. 1989. Component Parts and Structures of Monolingual Dictionaries: A Survey. Hausmann, F.J. et al. 1989-1991: 328-360.
Hausmann, F.J. et al. (Eds.). 1989-1991. Worterbücher. Dictionaries. Dictionnaires. An International Encyclopedia of Lexicography. Berlin: Walter de Gruyter. [ Links ]
Louw, P.A. and R.H. Gouws. 1996. Lemmatiese en nielemmatiese adressering in Afrikaanse verta-lende woordeboeke. Suid-Afrikaanse Tydskrif vir Taalkunde 14(3): 92-100. [ Links ]
Taljard, E., D.J. Prinsloo and R.H. Gouws. 2014. Text Boxes as Lexicographic Device in LSP Dictionaries. Abel, A., C. Vettori and N. Ralli (Eds.). 2014. Proceedings of the 16th EURALEX International Congress: The User in Focus, Bolzano/Bozen, Italy, 15-19 July 2014: 697-705. Bolzano/ Bozen: EURAC. [ Links ]
Tarp, S. 2004. Basic Problems of Learner's Lexicography. Lexikos 14: 222-252. [ Links ]
Wiegand, H.E. 1989. Aspekte der Makrostruktur im allgemeinen einsprachigen Wörterbuch: alphabetische Anordnungsformen und ihre Probleme. Hausmann, F.J. et al. 1989-1991: 371-409.
Wiegand, H.E. 1996. Das Konzept der semiintegrierten Mikrostrukturen. Ein Beitrag zur Theorie zweisprachiger Printwörterbücher. Wiegand, H.E. (Ed.). 1996. Wörterbücher in der Diskussion II: 1-82. Tübingen: Max Niemeyer. [ Links ]
Wiegand, H.E. 2006. Adressierung in Printwörterbüchern. Präzisierungen und weiterführende Überlegungen. Lexicographica 22: 187-261. [ Links ]
Wiegand, H.E. 2011. Adressierung in der ein- und zweisprachigen Lexikographie. Eine zusammenfassende Darstellung. Kürschner, W. and M. Ringmacher (Eds.). 2011. Aus Ost und West: 109-234. Frankfurt: Peter Lang. [ Links ]
Wiegand, H.E., S. Beer and R.H. Gouws. 2013. Textual Structures in Printed Dictionaries. An Overview. Gouws, R.H. et al. (Eds.). 2013: 31-73.
Wiegand, H.E. and R.H. Gouws. 2011. Theoriebedingte Wörterbuchformprobleme und wörter-buchformbedingte Benutzerprobleme I: Ein Beitrag zur Wörterbuchkritik und zur Erweiterung der Theorie der Wörterbuchform. Lexikos 21: 232-297. [ Links ]
Wiegand, H.E. and R.H. Gouws. 2013. Addressing and Addressing Structures in Printed Dictionaries. Gouws, R.H. et al. (Eds.). 2013: 273-314.
Wiegand, H.E and M. Smit. 2013. Microstructures in Printed Dictionaries. Gouws, R.H. et al. (Eds.). 2013: 149-214.
* This is the first in a series of three articles dealing with various aspects of lexicographic data boxes.
^rND^sBergenholtz^nH.^rND^nS.^sTarp^rND^nH.E.^sWiegand^rND^sGouws^nR.H.^rND^sGouws^nR.H.^rND^sGouws^nR.H.^rND^nD.J.^sPrinsloo^rND^sGouws^nR.H.^rND^nS.^sTarp^rND^sLouw^nP.A.^rND^nR.H.^sGouws^rND^sTaljard^nE.^rND^nD.J.^sPrinsloo^rND^nR.H.^sGouws^rND^sTarp^nS.^rND^sWiegand^nH.E.^rND^sWiegand^nH.E.^rND^sWiegand^nH.E.^rND^sWiegand^nH.E.^rND^nR.H.^sGouws^rND^1A01^nXiqin^sLiu^rND^1A02^nJing^sLyu^rND^1A03^nDongping^sZheng^rND^1A01^nXiqin^sLiu^rND^1A02^nJing^sLyu^rND^1A03^nDongping^sZheng^rND^1A01^nXiqin^sLiu^rND^1A02^nJing^sLyu^rND^1A03^nDongping^sZhengARTICLES
For a Better Dictionary: Revisiting Ecolexicography as a New Paradigm
Vir 'n verbeterde woordeboek: 'n Herbesoek aan die ekoleksikografie as nuwe paradigma
Xiqin LiuI; Jing LyuII; Dongping ZhengIII
ISchool of Foreign Languages / Research Center for Indian Ocean Island Countries, South China University of Technology, Guangzhou, China (flxqliu@scut.edu.cn)
IISchool of Foreign Languages, South China Agricultural University, Guangzhou, China (Corresponding Author, jinglyu@qq.com)
IIIDepartment of Second Language Studies, University of Hawai'i at Mãnoa, Honolulu, USA (zhengd@hawaii.edu)
ABSTRACT
Driven by practical conundrums that users often face in maximizing (e-)dictionaries as a companion resource, this article revisits and redefines ecolexicography as a new paradigm that situates compilers and users in a relational dynamic. Drawing insights from ecolinguistics and cognitive studies, it appeals for rethinking the compiler-user relationship and placing dictionaries in a distributed cognitive system. A multidimensional framework of ecolexicography is proposed, consisting of a micro-level and a macro-level. To the micro-level, both symbolic and cognitive dimensions are added: (1) the dictionary can be symbolically viewed as a semantic and semiotic ecology; (2) dialogicality should be highlighted as an essential aspect of e-dictionary compilation/ design, and distributed cognition can be emancipatory for rethinking dictionary use. The macro-level concerns the obligations of lexicographers as committed to three interrelated ecologies or ecosystems: language, socio-culture and nature. Transdisciplinary in nature, ecolexicography involves a holistic, systematic and integrative methodology to nourish lexicographical practice and research. Corpus-based Frame Analysis is introduced to identify ecologically destructive frames and ideologies so that the dictionary discourse could be reframed. The study upgrades our understanding of the ontological, epistemological and methodological aspects related to ecolexicography, serving as a call for philosophical reflections on metalexicography. It is also expected to create an opportunity for lexicographers to examine problems with (e-)dictionaries in a new light and dialogue about how to find solutions.
Keywords: e-dictionary, learner's dictionary, semantic ecology, semiotic ECOLOGY, ECOLINGUISTICS, ECOLEXICOGRAPHY, DIALOGICALITY, DISTRIBUTED COGNITION, SOCIO-CULTURE, CORPUS-BASED FRAME ANALYSIS, METALEXICOGRAPHY
OPSOMMING
Voortgedryf deur praktiese probleme wat gebruikers dikwels ervaar in die maksimalisering van (e-)woordeboeke as 'n handboekhulpbron, word 'n herbesoek aan die ekoleksikografie gebring en word dit geherdefinieer as nuwe paradigma wat samestellers en gebruikers in 'n relasionele dinamika posisioneer. Uit insigte wat verkry is uit die ekolinguistiek en kognitiewe studies word daar gevra om 'n herbesinning van die samesteller-gebruikers-verhou-ding en om woordeboeke in 'n verspreide kognitiewe stelsel te beskou. 'n Multidimensionele raam-werk van die ekoleksikografie, wat bestaan uit 'n mikro- en makrovlak, word voorgestel. Tot die mikrovlak word beide simboliese en kognitiewe dimensies gevoeg: (1) die woordeboek kan simbolies beskou word as semantiese en semiotiese ekologie; (2) diskoers moet beklemtoon word as 'n essensiële aspek van die samestelling/ontwerp van die e-woordeboek, en verspreide kognisie kan bevrydend wees vir die herbeskouing van woordeboekgebruik. Die makrovlak is gemoeid met die verpligting van leksikograwe wat verbind is tot drie ekologieë of ekostelsels wat onderling aan mekaar verbonde is: die taal, sosiokultuur en natuur. Die ekoleksikografie, transdissiplinêr van aard, behels 'n holistiese, sistematiese en integrerende metodologie om die leksikografiese praktyk en navorsing te voed. Korpusgebaseerde Raamanalise word gebruik om ekologies destruktiewe raamwerke en ideologieë te identifiseer sodat woordeboekdiskoers geherdefinieer kan word. Hier-die studie verbeter ons begrip van die ontologiese, epistemologiese en metodologiese aspekte wat verband hou met die ekoleksikografie, en ontlok filosofiese denke rakende die metaleksikografie. Daar word ook verwag dat dit 'n geleentheid vir leksikograwe sal bied om probleme rakende (e-)woordeboeke in 'n nuwe lig te ondersoek en vir gesprekvoering oor hoe om oplossings vir hier-die probleme te vind.
Sleutelwoorde: e-woordeboek, aanleerderswoordeboek, semantiese ekoLOGIE, SEMIOTIESE EKOLOGIE, EKOLINGUISTIEK, EKOLEKSIKOGRAFIE, DISKOERS, VERSPREIDE KOGNISIE, SOSIOKULTUUR, KORPUSGEBASEERDE RAAMANALISE, METALEKSIKOGRAFIE
1. Introduction
Ecology refers to (the scientific study of) the relation of plants and living creatures to each other and to their surroundings. How organisms interact with one another and with their environment has become "a central question governing the survival and sustainability of human societies, cultures and languages" (Cronin 2017). Ecolinguistics (or ecological linguistics) investigates language in an ecological context. It explores the role of language in the human society and the ecosystem, and shows how linguistics can be used to address key ecological issues. This new branch of linguistics represents a turning point in language studies. Revolutionary in nature, it catalyzes the growth of many interdisciplinary fields of research. It distinguishes two positions for the ecological study of languages: one concerned with the relations between languages, and languages with the environment; the other investigating the interrelationships existing in a language (Albuquerque 2018). This distinction was first elaborated by Makkai (1993), who put forward the term "exoecological linguistics" for the former, and "endoecological linguistics" for the latter. They could be understood as the macro-level and the micro-level in the framework of ecolinguistics.
Originating from lexicography and ecolinguistics, ecolexicography was first proposed by Sarmento (2000) as a part of applied linguistics, with a focus on addressing the effects and results that each lexeme brings to dictionary users. Sarmento (2005) argues that the main issue of ecolexicography is what the role of words is in our world and how a word can create, maintain or destroy a world. Many scholars (e.g. Hoey 2001; Tsunoda 2005) resonate with this viewpoint, stressing the importance of dictionaries as a tool of promoting linguistic diversity, socio-cultural harmony, and environmental sustainability. However, Sarmento (2000, 2002, 2005) holds that ecolexicography does not deal with the elaboration of ecology dictionaries or ecological terms. This perspective may be too limited as ecolexicography unavoidably faces the treatment of ecological vocabulary.
Albuquerque (2018) describes ecolexicography as a new discipline in lexicography and explores what it could contribute to pedagogical lexicography, especially in the analysis of dictionaries and the microstructure, and in producing teachers with a different worldview and in environmental education for students. He argues that eco-lexicography as a science should assist lexicographers to: develop a new way of looking at the world (the ecological vision of the world) and the words; realize the power of the words of a language for its speakers and for the world; offer ways to identify the ecological factors in language; and propose a new structure of article and definition (ibid.). He also points out that research on ecolexicography regarding these aspects is only at an embryonic stage, and it is necessary to lay a foundation for the ecolexicography approach that needs more researchers, research and projects. There is actually significant potential for (re)discovering important inroads or beneficial outcomes.
To breathe new life into this field, we have to re-examine the lexicographical products seriously, and rethink the cognitive and socio-cultural processes of dictionary compilation and use from a novel perspective. This article is expected to create an opportunity for lexicographers to dialogue about the problems they encounter with (e-)dictionaries and communicate how our ecolexicography proposal can shed light on the solutions it can provide.
2. Rationale for revisiting ecolexicography
2.1 Practical problems: the necessity
Abundant literature (e.g. Hoey 2001; Tsunoda 2005) reveals that there are at least two kinds of problems with current dictionaries: anti-ecological language and destructive ideologies, and problematic (e-)dictionary design and use.
2.1.1 Anti-ecological language and destructive ideologies
Many dictionaries, including pedagogical dictionaries, are not ecologically oriented and do not pay enough attention to users' awareness of the importance of environmental protection and sustainable development of human society or cultures (Wang 2003).
Tian et al. (2016) find that some examples in The New Age English-Chinese Dictionary (NAECD) fail to adopt a positive attitude toward ecology. Four tendencies of lexicographers dealing with biological and ecological lexemes were identified by Trampe (2001): (1) reification, i.e. treatment of certain living beings as things (goods of production or consumption), e.g. "cow" is a commodity; (2) use of euphemism (and other language mechanisms) to hide certain facts that may be regarded as violent for the consumer or general public, e.g. "pesticide" is replaced by "plant protection tool"; (3) defamation of traditional/ subsistence agriculture, which are generally labeled as being "unproductive", "expensive", etc.; (4) use of slogans and phraseological elements to convince the population that the destruction of the ecosystem is something natural/inevitable or even to disguise such destruction, affirming it as something good, e.g. "to create more wealth for all". These four tendencies alert lexicographers to the anti-ecological language of the world economic vision that is fragmented, increasingly alienating the human being from other species and nature (Albuquerque 2018).
Furthermore, anti-sociocultural ideologies are found in dictionaries. Tenorio (2000) claims that some definitions in The Collins COBUILD English Language Dictionary (CCELD) are inaccurate and biased in gender representation, and ignore changes in society. Hu et al. (2019) assert that The Contemporary Chinese Dictionary (CCD) portrays men as valuable social members while overlooking the value of women.
We found similar results (see Appendices I and II) after examining three of the "Big Five" dictionaries1: Oxford Advanced Learner's Dictionary (OALD9), Longman Dictionary of Contemporary English (LDOCE5) and Collins COBUILD Advanced Learner's Dictionary (COBUILD8). To achieve representativeness and generalizability of our data and the outcomes, we retrieved 30 random pages from each dictionary and all the linguistic data in those pages were collected to create a corpus. Each text was annotated and analyzed to disclose the ecologically (non)destructive frames in dictionaries. Frames (also called schemas) are schematizations of our experience and knowledge of the world (Fillmore 1985), and description of word meanings must be associated with cognitive frames in the reader's mind2. In our survey, we adapted and integrated corpus-based discourse analysis (Baker 2006) into frame analysis (Fillmore and Baker 2009; Lakoff 2014). The procedure of frame analysis (Blackmore and Holmes 2013) is to ask the following questions for a particular frame: What values does the frame embody? Is a response necessary? Can the frame be challenged? If so, how? Can (and should) a new frame be created?
We compared the frames represented by the headwords in the dictionaries and those represented by the same words in Corpus of Contemporary American English (COCA). In the end, we identified over 30 potentially destructive instances (definitions and examples) from more than 30 entries of each of the three dictionaries. For instance, "He had abused his own daughter" and "The boy had been sexually abused" are used as illustrative examples in the entry of "abuse" in OALD9 (see Part A in Appendix I). In total, we found that 23 themes were disharmoniously framed, and many of them were beyond the traditional lexicographic attention because it seems that the top seven themes we have identified (violence, animal, drug, possession, pollution, sea and alcohol) have not been fully discussed in lexicography (Lyu and Liu, in preparation). Destructive frames and ideologies (e.g. "Children are the target of sexual harassment", see Part A in Appendix II) seem to be prevalent, largely due to lexicographers' choice in this challenging age of the Anthropocene (ibid.).
2.1.2 Problematic (e-)dictionary design and use
Researchers find that many lexicographic e-products were developed with little influence from innovative theoretical suggestions and, as a result, current e-dictionaries often do not live up to the expectations of users and are misused by their users (cf. Gouws 2014). Many of them have problems including definition insufficiency and inaccuracy (Zhang 2015: 79-82), lack of customization (Liu, Zheng and Chen 2019), information overload (Gouws and Tarp 2017; Huang and Tarp 2021) and lack of education in dictionary use (e.g. Winestock and Jeong 2014). For instance, dictionaries integrated into English learning applications produced in China were found to suffer from deficiencies such as "inconsistent treatment of words and senses, data overload, difficult access, and inconvenient location of the pop-up window that displays the lexicographical items", which may "impact negatively on the learners' motivation and the learning process in general" (Huang and Tarp 2021). In the digital revolution, the way of displaying data in e-dictionaries must be redefined (Gouws 2014), and semiotic resources (e.g. color, typography, and navigation devices) should be properly employed according to the context (Liu 2015, 2017; Farina et al. 2019).
Underlying reasons for the above problems are complex, and some may be ontological and epistemological. At the fundamental level, many lexicographers, perhaps indulged in Western analytical thinking, still hold a fragmented view, rather than a systematic view of the components in a dictionary and its microstructure. There lacks an awareness that a dictionary, comparable to ecology, is characterized by complexity, holism, diversity and dynamicity. For example, the lack of e-dictionary customization and individualization is against the principle of ecological diversity and dynamicity. The technical transition from paper-based to electronic layout demands different cognitive attention and visual engagement. Users' individual and collective needs should be considered by designers. From an ecological perspective of language learning, even if a universal dictionary could be made, the users would tailor its use (especially those with a high degree of literacy and computer skills). So, dictionary design should try to allow users to adapt the product to their needs, goals and values, to some extent (see Liu, Zheng and Chen 2019 for an example of varying types of motivation for smartphone dictionary use in China).
To make things even worse, the practice that one definition/example fits all, or lack of adaptability, may aggravate the problem of data overload. For instance, the word "pig" is defined as "An omnivorous domesticated hoofed mammal with sparse bristly hair and a flat snout for rooting in the soil, kept for its meat" in the Lexico.com (called Oxford Dictionaries English before 2019, https://www.lexico.com/definition/pig). This is a general dictionary (rather than a specialized one) and the definition is offered to users in general, but this is a very difficult technical definition. It is very likely that many users do not understand the difficult terminologies in the complicated explanation. Perhaps such information/data overload (Gouws and Tarp 2017), traceable to inconsideration of dictionary types and users, is against the principle of "ecological harmony" (cf. Zhou 2017). The idea that online dictionaries have unlimited space has furthered the often uncritical inclusion of too much data (Gouws and Tarp 2017).
In brief, the status quo highlights the importance of proper ontological and epistemological orientations for lexicography. With an ecological view, ecolexicography has the potential to offer a fresh set of theoretical-methodological contributions in dictionary research and compilation, especially in the proposal of a differentiated microstructure (Albuquerque 2018). Nevertheless, for systematic strategies to remedy the above problems, ecolexicography needs to be redefined as a new paradigm by drawing theoretical and methodological insights from related fields.
2.2 Theoretical underpinnings: the feasibility
2.2.1 Lexicographical theories
Three theories may shed new light on ecolexicography, the Communicative Theory of Lexicography (Yong and Peng 2007), the Function Theory of Lexicography (Bergenholtz and Nielsen 2006; Tarp 2007), and the Discourse Approach to Critical Lexicography (Chen 2019).
The first two theories are user-oriented and focus on the interactivity feature of dictionary compilation and use. The Communicative Theory of Lexicography views the dictionary as communication (instead of reference and text). Drawing insights from Systemic-Functional Linguistics (Halliday 1985), Yong and Peng (2007) assert that dictionary context encompasses three subcategories: field, mode and tenor. This communicative perspective inspires reconsideration of the interaction between dictionary compilers and users. According to the Function Theory of Lexicography (Bergenholtz and Nielsen 2006; Tarp 2007), dictionary functions are communication-orientated or cognition-orientated, and lexicographers must identify the relevant functions and select and present appropriate data so that the dictionary satisfies the needs of users in different situations.
Chen's (2019) Discourse Approach to Critical Lexicography, or Critical Lexicographical Discourse Studies (CLDS), offers both theoretical and methodological inspirations for ecolexicography. Responding to the call for lexicographers' social accountability, CLDS views the dictionary as discourse, and discourse is a three-tiered concept consisting of "a piece of text, an instance of discursive practice and an instance of social practice" (Fairclough 1992). To uncover the ideologies and power relations in dictionaries, CLDS analysts will first conduct an analysis of the dictionary as text, investigating, for example, the choice of vocabulary in explaining the meaning of a word, the choice of illustrative examples, and the order of senses (ibid.). Thereafter how the dictionary is produced, distributed and consumed will be examined, followed by a discussion of the social context in which the dictionary is produced and consumed (ibid.).
2.2.2 Ecolinguistic and cognitive theories
Two interrelated theoretical achievements in ecolinguistic and cognitive studies may offer nourishments for ecolexicography and help transform the discipline. The first is the "distributed language" and EDD (ecological, dialogical and distributed) theory (Van Lier 2002; Cowley 2011; Linell 2009, 2013; Zheng 2012; Steffensen 2015), and the second is Steffensen and Fill's (2014) redefinition of ecolinguistics by identifying the four ways in which the ecology of language is conceptualized.
Distributed language theory means that language is not an independent symbolic system used by individuals for communication but rather an array of behaviors that constitute human interaction. Language perception occurs in a context of activity and interactivity (Van Lier 2002). Permeating the collective, individual and affective life of living beings, language is a profoundly distributed, multi-centric activity as a part of our ecology, and it gives us an extended ecology in which our co-ordination is saturated by values and norms that are derived from our sociocultural environment (Cowley 2011). In brief, language (or language use) is ecological, dialogical (linked to others) and distributed (rather than located to any single place, such as the speaker's brain) (Zheng 2012).
In applied linguistics, Van Lier (2002) might be the first to have introduced an ecological perspective to language education. The ecological view has inspired a rethink of language and language acquisition/cognition from a socio-cultural perspective and boosted the development of such emerging theories as "the Complexity Theory" (see Larsen-Freeman 2011). Ecolinguists redefine language by dividing it into two different consensual domains: (1) first-order languaging (linguistic actions and activities in the communication); (2) second-order sociocultural inscriptions and norms (Kravchenko 2009). Following this theoretical vein, Zheng (2012) proposed her ecological view of language learning and use which highlights the dialogicality and distributed cognition of participants in communication. Distributed cognition means that cognition is spread in and reliant on different contexts. Traditional cognition is redefined as an activity "distributed" in the physical and socio-cultural environment. In cultural ecologies, resources like a dictionary can link people in practices that enable the accomplishment of tasks.
In ecological terms, agents' languaging behaviors are caused not by stimuli but the affordances, opportunities for action and coaction motivated by the ecosocial environments (Zheng et al. 2012). Language is embodied (not merely abstractly procedural), embedded (shaping and shaped by social systems in a cultural world), enacted (living in or realized in and through action), extended, situated, and multi-scalar (existing on different time-scales) (Cowley 2011; Linell 2013).
Based on the communication models of semiotic activity by Zheng (2012) and Linell (2009), we build an ecological model of lexicographical interaction (see Figure 1).
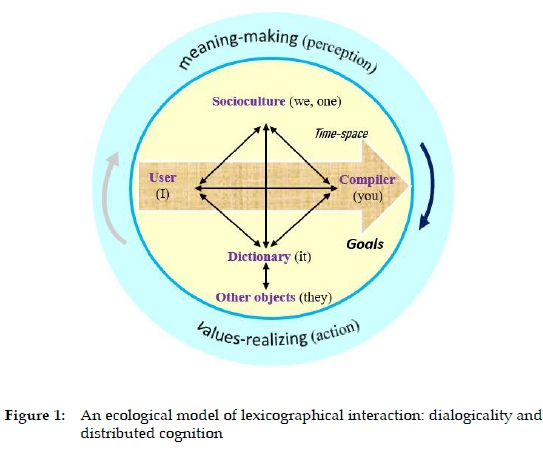
In the outer layer of the model, there are two concepts from ecological psychology, meaning-making (perception system) and values-realizing (action system). Values-realizing means that an individual agent makes "a conscious choice among multiple values at play in any given moment of action and interaction" (Zheng et al. 2012). It is values that "guide the selection and revision of goals across diverse time-space scales, under which the sociocultural norm 'we' (laws or rules of phonology, syntax, or semantics) are nested" (Zheng 2012). There are interactions among the dictionary user (I), compiler (you), sociocultural norm (we), dictionary (it) and other objects (they) in the real world or virtual space.
Based on the model (Figure 1), the relationship between the dictionary (it) and its user (I) should be rethought. The dictionary should be a friend that is always there, so faithful, helpful and thoughtful. This means that it should have such qualities as accuracy, functionality and adaptability. In addition, the interaction between the dictionary (it) and the other objects (they) in the physical environment is also meaningful. To improve its adaptability and customization, an e-dictionary is often embedded in or fused with the interfaces of learning activities like those of reading or writing software. Meaning-making and values-realizing are in the cycle of perception and action involving dictionary compilation and use.
Another illuminating insight that ecolexicography can gain from ecolinguistics contributes to an upgraded understanding of its overall framework. Steffensen and Fill (2014) point out four ways the language ecology has been conceptualized as a symbolic ecology, a cognitive ecology, a natural ecology, and a sociocultural ecology. Similarly, in terms of ecolexicography, a symbolic ecology can be understood as the semantic and semiotic ecology in a dictionary. A cognitive ecology of lexicography involves dictionary compilation/ design as dialogism and dictionary use as distributed cognition. The two constitute the microlevel of ecolexicography. At the macrolevel, ecolexicography should be committed to serving the linguistic, natural and sociocultural ecologies. The differentiation (and complementarity) between the microlevel and the macrolevel of ecolexicography mirrors the exoecological vs. endoecological division in ecolinguistics.
The endoecological position or the microlevel of ecolexicography, an obvious lacuna in literature, needs to be delineated to form a complete framework. This article aims to take a small step toward addressing the gap by revisiting ecolexicography as a new paradigm.
3. Ecolexicography at the micro-level
3.1 The semantic and semiotic ecology in a dictionary
Some scholars (e.g. Liu 2015) hold that the dictionary as a complex system can be symbolically compared to an ecology in two senses, semantic and semiotic.
First and foremost, the complicated semantic system of a dictionary is comparable to an ecology where meaning is like energy. Meaning flows and expands (Liu 2017), just as energy flows and circulates. As an ecological system, an e-dictionary is even more open and dynamic than a paper dictionary. There are interactions among the diverse members in this ecology, including cooperation and competition. Its components or communities are conceptually linked together as an integrated whole in a hierarchy. This organic whole is served by the dictionary macrostructure, mediostructure and microstructure as well as other information components that are themselves reciprocally conditioned. The macrostructure is the form and size of a dictionary, the medio-structure refers to its system of cross-referencing which can create textual cohesion, and the microstructure means its lexical entries or articles. Figure 2 roughly illustrates a pyramid of the dictionary semantic(-functional) ecology.
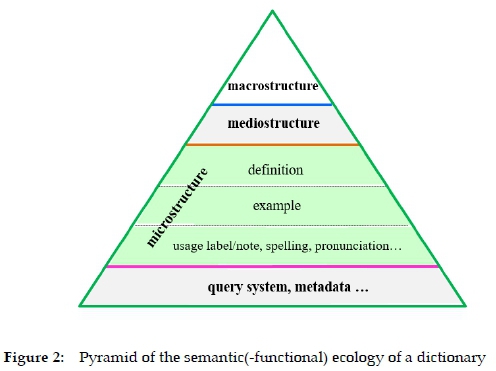
The macrostructure of a dictionary is like an overall guide or a head that leads the whole semantic ecology on the top. The mediostructure is a network under the macrostructure. In the digital era, cross-references between words by hyperlinks easily connect entries and reinforce the mediostructure. The microstructure is the main body of a dictionary where definition acts as the core of meaning representation, playing a key role in stating or explaining the meaning of a word or phrase. A definition is often complemented by the illustrative examples ("examples" hereafter) under the same sense. Examples can reinforce meaning explanations, illustrate collocations and colligations, and contextualize for cultural, stylistic and pragmatic implications (Xu 2009: 12, 26-29). Many examples are transformed (i.e., simplified for children) from authentic sentences to meet the particular purposes of a dictionary, a lexicographical process like crop improvement in the biological ecology. Other microstructure components, such as spelling, pronunciation, usage notes and labels, also participate in the co-construction of meaning, serving behind as a guide to the microstructure. Other information components (query system, metadata etc.) are backgrounded on the bottom of the ecology. They act as the supporting system.
Furthermore, the semiotic system in a dictionary can be regarded as an ecology that is increasingly diversified in the digital era. In an e-dictionary, there are three major categories of multimodal meaning-making devices: written language, audio presentation of the verbal elements, including human voice recordings and synthesized speech, and other devices (Lew 2010), like pictures, silent animations, video clips, hyperlinks, floating tips and typography. Based on Multimodal Discourse Analysis (Kress and Van Leeuwen 2006) the choice of semiotic modes, and the cooperation and interaction among different modes are important for the dictionary ecology (Liu 2015).
If the semiotic ecology is examined hierarchically from a Systemic-Functional perspective, it can be stratified into three levels by following Rossi and Sindoni (2017): (1) semiotic systems (i.e. ideational, interpersonal and textual metafunctions or meaning potentials); (2) semiotic resources (i.e. instance or realization); (3) semiotic components (i.e. elements that can be unpacked from a resource and that concur to the instantiation of texts). They represent different levels of abstractions. Figure 3 illustrates the different strata proposed in our analysis.
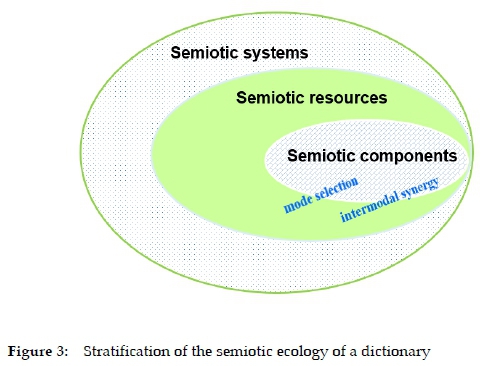
In brief, the semantic ecology is organized holistically by the synergy of multimodal devices, so that the whole is more than the sum of its parts.
3.2 The dialogicality in (e-)dictionary compilation/design
Dialogicality means the dynamic abilities of human beings to take part in interactions with others and with sociocultural contexts as well as physical environments (Linell 2009: 368). Meaning or sense is co-constructed by dictionary compilers/designers and users, and it is not local. In the era of Web 2.0 and Web 3.0, there are more chances for them to have dialogues to make meaning/ sense. Problems such as lack of customization and information overload in dictionaries (Gouws and Tarp 2017) can be alleviated with a dialogical perspective.
Compared with paper dictionaries, e-dictionaries provide users with more chances of participation and interaction, facilitating compiler-user or even user-user dialogues and greater flexibility in use (cf. Liu 2017). Many e-dictionaries invite users to contribute entries or make comments on them (Granger 2012). They afford user customization. To take a previous version of Jinshan Ciba English Dictionaries (iCIBA) as an example, classified information was provided and its users could choose the type of examples they wanted. There were also buttons users could click to report a wrong example to the designer, praise a good one "in public" and save a useful one for his or her own use. Figure 4 is a screenshot of its entry of "ecological" (captured on Jan. 20, 2018)3. We have added English translations for its customization and interaction buttons.

It is advisable for e-dictionary designers to consider the user's ecological niche and allow co-selectivity and co-creation of meaning and value4. Learners' goals and needs could be scaffolded and transformed by design. This suggestion is broadly informed by distributed language, in that first-order dynamic action should be at the fore of second-order static prescription (Cowley 2011). The design based on the traditional concept that, on one hand, there is an objective, absolute authority of dictionary meaning, and on the other, there are users who use this absolute value-free tool, should be rethought (Liu, Zheng and Chen 2019). From the ecological psychological perspective (Gibson 1979), dictionaries can be considered having affordances for certain actions, such as for supporting enjoyment of reading, and for clarifying a statement. The ways in which actions connect dictionaries and users should result in changes in both artifacts and the agent (cf. Zheng 2012). Therefore, how dictionaries are designed can have a direct influence on learner behaviors.
Besides having more dialogues between dictionary compilers/designers and users, the ecology of an e-dictionary is filled with more different voices than that of a paper dictionary. Pop-up windows, for example, are used for projecting the voices of advertisers. With the social force of marketization, dictionary companies have to attract funding from advertisements to maintain the dictionary. Creating a more heteroglossic and noisy atmosphere, advertisements add to the complexity of the semantic ecology and may often distract users' attention in their cognitive processes. By heteroglossia, we mean a diversity or hybridity of voices and styles of discourse in the dictionary ecology as an extension from lexicographical dialogism5.
3.3 The distributed cognition in (e-)dictionary use
In ecolexicography, "distributed cognition" can be understood in both narrow and broad senses. In a narrow sense, the page layout of e-dictionaries usually looks less cluttered and the user's cognition involved in consultations is not restricted in a fixed manner. In a broad sense, cognition is distributed over different systems, such as brain, body, computers, instruments, aspects of the environment at large (Steffensen 2015).
The digital revolution of dictionaries "has removed constraints on size and format, paving the way for multi-faceted, flexible and rich representations of word meaning and use" (Fellbaum 2014). In densely printed pages of text, reading is often linear and strictly coded (Van Leeuwen 2005: 204). The onetime display in a fixed order might leave the users in a passive state of reception (Liu 2017). Large bands of space can be found in contemporary designs, suggesting the lightness of the reading experience. Spatial resource competition is less fierce.
In an e-dictionary, individual examples are often placed in separate paragraphs, and this makes them more readable than those densely printed in paper dictionaries. A distinctive type of vertical composition for examples in smartphone or tablet dictionary applications (apps) has been identified from Fayu Zhushou French Dictionaries (a most popular French dictionary app in China), where elements are mostly placed into equally sized tiles which could be swiped across to see more (Liu 2017). This way of organizing information allows contents to be textually linked as choices of the same order since tiles of the same size also achieve textual linking or rhyming, alongside that accomplished by color and fonts (Zhang et al. 2015). This creates visual harmony in the dictionary ecology, decreasing the difficulty of reading on a small screen. Also, there is added convenience of the ability to zoom in and out, not to mention the possibility to blend with other assistive technology to aid the visually impaired and those with poor eyesight. Users can make use of the convenient features of copying entries and exporting to other applications, or sending selected text through messenger applications.
E-dictionary information can be presented in an array of interlinked web pages and media networks, enabling e-dictionary users to navigate and choose their own pathways through this semantic ecology. Users can change dictionary settings (like interface style6), and make bookmarks, tailoring the use according to their own needs (ibid.). For instance, as shown by Figure 4, the "Learn" button at the end of each example can be clicked to start a timed activity of memorizing an example, inviting the user to put the disordered words of an example sentence in good order. In the online Longman Dictionary of Contemporary English (LDCE), a collocation in its examples is highlighted with an underline and boldface font when the user's mouse cursor hovers over it (Liu 2017). During such human-computer interactions, a solid line emerges, giving readers a sense of the formation of the bundle/collocation (ibid.). This certainly involves distributed cognition.
In addition, because cognition is distributed across different places and contexts, effective lexicographic solutions should be suited to the needs of a particular user in a particular situation (Lew 2012), especially outside the classroom. For example, smartphone dictionary apps, due to the nature of portability, can work as flashcards for learners to carry with them. The smartphone can be used to scan an unfamiliar word for its meaning or translation and the user can add it to a wordlist for learning. Learning becomes more contextualized and meaningful when tied to learners' lives outside academia, and mobile devices help achieve that goal (Godwin-Jones 2011). Dictionary use, in turn, can transform language learning behavior as distributed cognition.
Furthermore, education in e-dictionary use can be provided from an ecological-dialogical perspective. This means that learning happens in an ecology with interactions between dictionary users and designers, between learners and teachers, and among learners (Liu, Zheng and Chen 2019). Dictionary use can be a result of a meaningful situated activity in which users need to consult a dictionary to understand meaning (Zheng 2012). Action-based activities can be better realized if instant support can be provided in a specific situation (Zheng et al. 2015) with a smartphone dictionary. Also, situated and action-based activities can integrate with dictionary user training in a natural way.
In brief, with the proper use of semiotic resources, e-dictionaries can facilitate distributed cognition effectively. As a result, the role of the dictionary user changes from a passive receiver of meanings to an active explorer of senses. Users are unable to maximize a dictionary as a companion resource because dictionaries are conceptualized as an object that supplies predefined meanings. This article explores rethinking that a dictionary is a relational component of a distributed cognitive system along with users and compliers. Thus, the use of a dictionary in this new thinking helps make meaning with the distributed system.
4. Ecolexicography at the macro-level
4.1 Lexicography and the ecology of language
A dictionary is a good tool for outsiders (non-native speakers) to learn the language, and for insiders to document their language (Lee 2017: 5). The dictionary community is situated in its language habitat, and provides a prerequisite for the recording and development of natural language life. Etymology dictionaries play a most important role in documenting the minority languages which could be endangered because these languages contain and offer unique experiences of nature and knowledge, which have to be saved for future generations - especially in the sense of sustainability (cf. Bang and Trampe 2014). An average of 6 languages are disappearing from this world every year, and 1,531 languages among 7,102 are classified as threatened or shifting (Lee 2017: iii), so there is much work to do to revitalize endangered languages. If possible, a holistic approach (Tsunoda 2005: 231-233) may be the best way to document one language, covering various aspects of a language, including phonology, morphology, syntax, discourse, semantics, and vocabulary.
Methodologically, compiling dictionaries for endangered languages is different from that for languages that are not under the threat of extinction (ibid.). For the former, lexicographers should highlight the changes in the manner in which it is used, the reduction of the number of its different registers, as well as changes and simplifications in its structure, and lexical composition, and semantic changes in its lexicon, with all this resulting from a linguistically-oriented endangerment of its traditional form (Wurm 2007). At the same time, they should be aware of the sociolinguistic aspects, like the declining use of the language by shrinking numbers of its speakers, and the reasons, and circumstances of such events (ibid.).
Although some dictionaries documenting endangered languages are products of individual or community efforts, like Buk Bang Sinda (Bidayuh-Malay-English Dictionary), most of them result from a "top-down" process. Lexicography can be regarded as a part of the language planning of state agencies. Language planning was first introduced in 1959 by the ecolinguistic forerunner, Einar Haugen, and the subject has become increasingly important as awareness of the socio-political nature of language choices in multilingual/ multi-dialectal communities has grown (Jones 2015: xiii). The ideologies underlying language planning strategies are often, at least partly, attributable to what has been described as language policy (ibid.). The first step in saving dying languages is to persuade the world's majorities to provide opportunities for the minorities among them to speak with their own voices. Compiling dictionaries of minority languages may need teamwork among lexicographers, sociolin-guists, ethnographers and anthropologists. An ecological perspective would be preserving not only languages but also the social group. Without people and community, what would language be for?
Bosch and Griesel (2020) proposed an innovative way of documenting and preserving nine African languages in a digital lexical database, the African Wordnet. They claim that such a database becomes a useful resource for natural language processing, consolidating dispersed indigenous knowledge collected from a variety of sources in a digitized hierarchical wordnet structure.
4.2 Lexicography and the ecology of socio-culture
It is generally acknowledged that dictionaries are not value-free representations of languages and the world. Illustrative examples, for instance, are imbued with lexicographic intentions and "constitute a repository of the common values and interests of the society whose language is described" (Béjoint 2010: 202). Dictionaries should convey ideologies in such a way as to promote the positive development of human society, including peace, justice, equality and sustainability. Unavoidably, social learning must be moral learning (Hodges and Baron 2007), and values are not properties of persons or objects, but relationships and the demands that the ecosystem places on those relationships (Zheng 2012). As frames are mental structures that shape the way we see the world and we know frames through language, morally based framing7 is everybody's job (Lakoff 2014: 116), including lexicographers.
In the field of critical lexicography, scholars have examined such issues as gender (e.g. Hoey 2001; Moon 2014), racism and religion (e.g. Willinsky 1994; Ogilvie 2013), and politics and class (e.g. Ezquerra 1995). Previous studies (e.g. Benson 2002; Hornscheidt 2008) reveal how imperialism, racism and colonialism are naturalized in dominant monolingual dictionaries, such as the Oxford English Dictionary. Chen (2015, 2017) argues that bilingual lexicography is a complex site of ideological struggle and recontextualization of lexicographical discourse across cultures and contexts, resulting in the transformation and transfer of meaning. Recontextualizers of A New English-Chinese Dictionary (NECD), for instance, attempt to de-politicize the words and examples in the source dictionary by using such discursive strategies as deleting, replacing, and re-signifying (ibid.). When we successfully reframe dictionary discourse, we change the way the user sees the world. Because language activates frames, new language is required for new frames (Lakoff 2014: 15).
Many examples in Big Five dictionaries are found to embody ideas and values which are biased or politically wrong. For instance, COBUILD8 presents "Possession of cannabis will no longer be an arrestable offence" for the entry of "arrestable", "I started smoking grass when I was about sixteen" for "grass" (= marijuana), and "Up to two thirds of 14 to 16 year olds admit to buying drink illegally ... " for "admit" (see Part A in Appendix II). These examples, scattered in different entries, could co-build a harmful frame of drugs in the user's mind: Using drugs is a good experience; People can legally be drug abusers. Furthermore, a 2020 slang phrase, "Funny mud pee" (Go fuck yourself), included in the crowdsourced Urban Dictionary (https://www.urbandictionary.com/define.php?term=Funny%20mud%20pee), is an example of racism recontextualized from the Chinese-speaking to English-speaking world. It is a Chinglish curse created by Chinese social media users posting on Twitter extensively amid the global outbreak of COVID-19 in response to those tweets labeling COvID-19 as "Chinese virus" or "Wuhan virus". The lexeme is used in the media as something bad and must be eliminated or annotated properly to avoid harm or destruction of the global community.
Information in dictionaries should be selected and presented in such a way as to respect various cultures. In LDCE, the word "pig" is defined as "a farm animal with short legs, a fat body, and a curved tail. Pigs are kept for their meat, which includes pork, bacon, and ham" (https://www.ldoceonline.com/dictionary/pig). From a socio-cultural perspective, this definition is incomplete since it is not true that pigs are kept for their meat by all communities. In some cultures, pigs are kept as pets. Muslims don't eat pork and they would feel uncomfortable when reading such a definition.
In sum, the relationship between ideology and dictionary compilation is not a new topic in lexicographical studies, but most previous research has explored the topic from the perspective of dictionary compilers or designers. Attempts should be made to study the relationship from the perspective of the response of users regarding monolingual and bilingual/multilingual dictionaries. Users have the power to accept or reject a dictionary or a definition or example in an entry that is ideologically similar to or different from their own thinking, and ideology-oriented dictionaries can only realize their purpose in the right place at the right time (cf. Li 2012). After all, dictionary use - as a part of languaging - can promote "individualized values-realization" (Zheng 2012). That is a new research orientation that macro-ecolexicography can explore.
4.3 Lexicography and the ecology of nature
Language can inspire us to destroy or protect the ecosystems that life depends on. For example, the language of advertising can encourage us to desire unnecessary and environmentally damaging products, while nature writing can inspire respect for the natural world (Stibbe 2015: 174). Dictionaries are committed to the task of ecosystem protection, and help address such overarching ecological challenges as biodiversity loss, food security, climate change, water depletion, energy security, and chemical contamination. At the very beginning of dictionary design, the headwords which are closely related to the ecosystem can be selected in a separate list and given special attention. Wordsmyth Kids Dictionary (WILD, a popular children's dictionary) offered to guide children to explore words about the world, putting them in two modules: those about the city and those about nature. It seems that WILD embodies such a destructive frame: It is normal that urban residents stay away from nature since they don't belong to it. In other words, an implied contrast between city and nature may convey ideological ideas against human-nature oneness.
In writing definitions, lexicographers can implicitly or explicitly reinforce the users' awareness of environmental protection. This educational function of dictionaries can never be underscored enough. Take the word "ermine" as an example, in Cambridge English Dictionary (CED), it is defined as "expensive white fur with black spots that is the winter fur of the stoat (= a small mammal) and is used to decorate formal clothes worn by kings, queens, judges, etc." (https://dictionary.cambridge.org/dictionary/english/ermine). This definition has connotations of the merciless killing of the animal, and it implies the glory of wearing ermine clothes with a focus on the economic benefits from ermine trade. There are similar definitions in LDOCE5, e.g. "the skin or fur of some types of seal, used for making leather or clothes" for the entry of "sealskin", and "strong soft leather made from the skin of a deer or goat" for "buckskin" (see Part B in Appendix II). This "reification" (Trampe 2001: 1) of animals may constitute biased representation. The embedding of humans in the larger systems that support life is forgotten or overlooked (Stibbe 2014: 585), making it possible to treat animals as commodities at the service of human needs (Fusari 2018). This makes the dictionary evade its function of environmental protection, similar to or perhaps even worse than "animal erasure" (Stibbe 2015: 155). Lexicographers should be aware that dichotomic representations opposing animals to humans are deeply rooted in language, and make use of lexical or grammatical devices to create public consensus in favor of effective conservation of biodiversity (cf. Fusari 2018).
While choosing examples for an entry from the corpus, lexicographers could zoom in on the texts and discourse of ecological importance, and then choose and adapt examples carefully. In Merriam-Webster's Learner's Dictionary (MLD), examples are creatively designed for the first sense of the headword "nature" (http://www.learnersdictionary.com/definition/nature). As Figure 5 shows, the six examples are coherently organized and the second ("She is a real nature lover.") aims to cultivate love of nature in particular. The way the examples are ordered is carefully chosen. As their linguistic difficulty increases, they loom progressively into an integrated discourse that communicates important educational messages: nature is beautiful, it deserves our love and study, we can explore it (including its color) by taking photos, and we should conserve nature. The examples construct a harmonious semantic ecology, embodying human-nature oneness with schematic experience and knowledge8.

Compilers of ecologically-minded dictionaries can construct subcorpora of texts about the ecosystem and environmental protection, like personal virtual corpora based on the Wikipedia Corpus on the platform of Brigham Young University (https://corpus.byu.edu/wiki/). Based on such ecologically-oriented corpora, lexical databases can be constructed and shared by world lexicographers. EcoLexicon is such a terminological knowledge base on the environment (http://ecolexicon.ugr.es) with terms in six languages: English, French, German, Modern Greek, Russian, and Spanish. It is the practical application of Frame-based Terminology to configure specialized domains on the basis of definitional templates and create situated representations for specialized knowledge concepts. We should develop an awareness of green lexicographical technology and improve ecological efficiency in the ecosystem of lexicography. Then the dictionary discourse can be reframed effectively, eliminating destructive frames systematically. For instance, the frame of "Animals are resources for human abuse" (see Part B in Appendix II) seems prevalent and deeply entrenched in "Big Five" dictionaries, and this systematic problem could be solved with the help of ecologically-oriented databases.
Definitions and examples should try to reflect the reality and dynamism of bio-ecology. Take the headword "romaine" as an example, it is defined as "a type of bitter-tasting lettuce with long leaves" in LDCE (https://www.ldoceonline.com/dictionary/romaine). But in actual fact, this vegetable sold in the supermarket now is not bitter at all, perhaps as a result of long-time crop improvement. So, this definition may either be against the reality of bio-ecology or fail to reflect its changes.
Proper notes or labels concerning ecosystem protection could be added to an entry of ecological importance. In general-purpose dictionaries, encyclopedic information could be added by referring to specialized dictionaries on ecology, such as Dictionary of Environment and Ecology. This integration of linguistic and non-linguistic information corresponds with the holistic view of meaning and the functional theory of lexicography (Tarp 2007).
Serious ecological destruction has already occurred and more would be inevitable, so resilience to further environmental changes is necessary for finding new forms of society (Stibbe 2015: 15). This resilience can be properly embodied in lexicography, which connects the natural and social layers around dictionaries.
5. Discussion
5.1 A unified framework of ecolexicography
Based on Steffensen and Fill's (2014) conceptualization of the language ecology as a symbolic, cognitive, sociocultural and natural ecology, we have identified five new dimensions that an ecological perspective can add to lexicography: symbolism, cognition, language, socio-culture and nature. These dimensions fall into two levels of ecolexicography: microlevel and macrolevel. The first two dimensions (symbolism and cognition) constitute the microlevel of ecolexicography. The other three dimensions (language, socio-culture and nature) form the macrolevel. The two levels can be regarded as two domains of the area, micro-ecolexicography and macro-ecolexicography. We tentatively propose a framework of ecolexicography unifying the two levels or domains (see Figure 6).
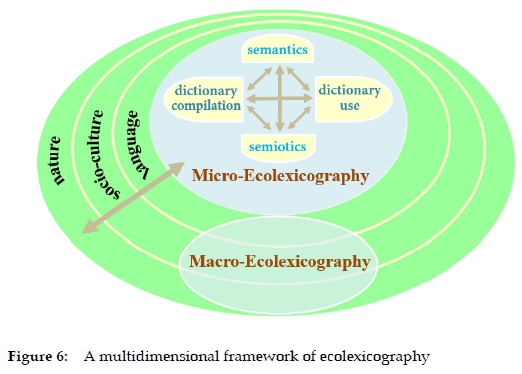
We may draw insights from multimodal discourse analysis to interpret the layout of Figure 6. According to the information value principles for visual composition proposed by Kress and Van Leeuwen (2006: 197), it is fundamentally a structure of "Center and Margin". In this model, micro-ecolexicography is the Center and it forms the nucleus of the space. Three outer layers (the Margins), language, socio-culture and nature, "wrap" or contextualize the cognitive processes of dictionary compilation/design and use as well as the dictionary itself. These layers create a gradual and graded distinction between Center and Margin. In micro-ecolexicography, dictionary compilation is on the left denoting the Given (i.e. old information) while dictionary use is on the right denoting the New (i.e. new information). Semantics is on the top representing the Ideal while semiotics is on the bottom representing the Real. For something ideal means that it is presented as the idealized or generalized essence of the information while the Real presents more specific information (e.g. details), more down-to-earth or practical information (ibid.: 186-187).
The framework represents an interactive ecology, and it refreshes our understanding of the major tenets of ecolinguistics through a lexicographical lens. Micro-ecolexicography is the origin and prime mover of communication. The double-headed arrows in Figure 6 indicate dialogues and interactions among communicative participants or affordances as well as ecologies, symbolizing dynamism or circulation of the ecosystem. There are underlying linkages and interactions between every two of the four "layers" (dictionary, language, socio-culture and nature).
Micro-ecolexicography may focus on e-dictionary design and use in the digital era while macro-ecolexicography highlights dictionaries' educational function and lexicographers' commitment to three interrelated ecologies (nature, socio-cultural and language) and can be attentive to various types of dictionaries.
5.2 Rethinking the methodology of ecolexicography
The methodology of ecolexicography should be reconsidered as a new paradigm. Ecolexicographic thinking is concerned with complex systems and diverse situations. It is arguable to place dictionaries within a distributed cognitive system and view them as such a system. Holistic, systematic and integrative methodology is essential to ecolexicographical practice and research.
Micro-ecolexicography could benefit a lot from the following methodologies: (1) multimodal discourse analysis for building a semiotic and semantic ecology of the dictionary; (2) information technology (e.g. data mining for tracking user feedback) and transdisciplinary approaches to user research for enhancing dialogicality and distributed cognition.
User research should be a key theme of micro-ecolexicography. It can be done before a dictionary is compiled so that preventive measures could be taken by its designer. A statistical method widely used in psychometrics, latent class modeling, should be a useful tool for investigating user intentions and attitudes. It identifies the underlying or invisible subgroups/categories (e.g. motivation) in the population, and can be introduced to large-scale surveys (see Liu, Zheng and Chen 2019 for an example). Surveys with latent class modeling could offer more important pointers for dictionary customization than traditional surveys that are generally based on visible subgroups (e.g. gender) of dictionary users.
However, when investigating socially sensitive attitudes like racial prejudice through a survey or interview, one should be aware that people are often motivated to self-report unprejudiced and egalitarian beliefs. To bypass social-desirability bias, an experimental paradigm of cognitive psychology, the Implicit Association Test (IAT), is recommended. As an influential measure of people's unconscious attitudes, IAT is less subject to deliberate control and potential distortion than interviews or focus groups. Such interdisciplinary methods have advantages over traditional approaches in exploring underlying values and frames in the minds of dictionary users and even dictionary designers.
Macro-ecolexicography could be nourished by: (1) Critical Lexicographical Discourse Studies for globally critiquing the dictionary discourse; (2) Corpus-based Frame Analysis (CFA) is recommended for revealing ecologically (non)destructive ideologies and frames in dictionaries specifically (cf. Lyu and Liu, in preparation); (3) ways of reframing the dictionary discourse.
Chen's (2019) Critical Lexicographical Discourse Studies (CLDS) not only offers a theoretical rationale for revisiting ecolexicography (see Section 2.2.1), but also specifies how to critique the dictionary discourse. With a focus on inter-discursivity, it compares the dictionary discourse with other types of texts. According to Chen (2019), analysis of the order of discourse is first done to disclose the latent social rules that govern the production of discourse. Then an interactional analysis is made, which consists of interdiscursive analysis, and linguistic/semiotic analysis (e.g. identifying how the lexicographic discourse is interdiscursively related to other discourses and genres, and analyzing lexis and clauses). Such an integrated analysis of textual and social structures helps uncover the internal relationship between them, with the situated contexts of dictionaries taken into consideration (ibid.).
If CLDS provides a macroscopic view for reframing the dictionary discourse, frame analysis, a common tool for critiquing or promoting ecological discourse, is perhaps more microscopically oriented. Corpus-based Frame Analysis could be more reliable than traditional frame analysis since it exploits objective evidence of corpus data for comparative analysis of ideologies and frames. Examining the semantic roles and their interrelations within a text or across texts via corpus analysis can reveal the ideologies and cognitive frames behind them. We also draw insights from previous scholars (Blackmore and Holmes 2013: 42; Stibbe 2015: 46-61) who have introduced the social-values-oriented frames to ecolinguistic research from the perspectives of cognitive semantics and discourse studies.
Corpus-based Frame Analysis consists of four main steps (see a more detailed illustration in Lyu and Liu, in preparation):
(1) randomly sampling definitions and/or examples from a dictionary and building them into a mini-corpus of dictionary discourse (D-corpus in short);
(2) identifying destructive discourse and analyzing frames behind the sample data (see Endnote 2 for the procedure of frame analysis), examining their relations and classifying them into a hierarchical network when necessary;
(3) using keywords to extract relevant discourse and analyze frames from an authoritative (and presumably balanced) corpus (namely B-corpus) or the corpus the dictionary claims to be based on (if available), and comparing the B-corpus frames with the D-corpus frames;
(4) based on the features and distribution of destructive frames, exploring the possible reasons for their existence with contextual factors considered, and rethinking its social accountabilities and possible solutions.
A keyword may have numerous frames in the B-corpus, and only those reflected by the most frequent collocations are considered. For example, for the patterns "A motivate B to do" and "A lead B to do" in the dictionary, the most frequent collocations in COCA turn out to be: factors motivate/lead somebody (sb) to do something (sth); sth motivate students to do sth; sth lead people to do sth; sth motivate sb to develop sth; sth lead sb to believe sth else. As Part A of Appendix II shows, LDOCE5, backdropped against COCA, creates a spouse killing frame through these examples: "We may never know what motivated him to kill his wife" and "What led him to kill his wife?". This is a biased representation of both real life and language use.
Destructive frames have their own linguistic and distributional features as they may be reflected by different (numbers of) definitions and examples in the dictionary discourse. The reasons for their existence can be traced to these features. Some frames are widely distributed and may form a complicated network. According to Appendix II, the frame of animal abuse seems far more complex (divisible into four subtypes in this case) and perhaps more severe than the frame of plant abuse, so the former may deserve more attention and a systematic solution is necessary.
The ultimate purpose of CFA is to reframe the dictionary discourse to avoid biased representations of reality. Dictionaries are supposed to capture the most typically shared values and ethics of a community to represent them in the definitions and illustrative examples (see Figure 5 for an example). At least, such problems as Trampe (2001) identified (e.g. reification, defamation, disguise) should be rectified. We'd like to recommend five ways of reframing the dictionary discourse: warning, commenting, refining, questioning and neutralizing.
The most straightforward way of reframing is to give a warning against immoral and illegal practices. For instance, a definition of "crocodile" in LDOCE5 ("the skin of this animal, used for making things such as shoes", see Part B in Appendix I) may be inadequate because it seems to ignore that crocodile is a species at risk of extinction. This definition could be refined to reveal the fact, or a note/warning could be added (e.g. "The crocodile is an endangered animal and should not be killed at will for profits). Another direct way is to enhance existing linguistic data by commenting on immoral values and improper behaviors. For instance, one could present "Experimentation with cannabis is illegal", rather than "experimentation with cannabis" as found in LDOCE5 (see Part B of Appendix I).
The third way of reframing, refining, means changing the current definitions or examples moderately, often by adding modifiers or other descriptions of details. Take the OALD9's entry "hashish" as an example, it is good to end with a warning ("Use of the drug is illegal in many countries", see Part A in Appendix I). However, its definition ("a drug made from the resin of the hemp plant, which gives a feeling of being relaxed when it is smoked or chewed") may embody a problematic positive attitude to drug use, and one could refine it by adding words like "misleading" or "dangerous" before "feeling". This is an implicit and subtle way of reframing.
The last two ways of reframing, questioning and neutralizing, concern controversial or sensitive issues. Questioning means asking a yes-no or rhetorical question. For instance, for the entry of "nature", one could use the question "Do you think man is good or evil by nature?" rather than a statement "She is evil by nature". Neutralizing refers to adopting a neutral stance when dealing with conflicting definitions by different communities and cultures. When dominant voices in society have dictated meanings of concepts/words at the expense of other social beliefs, it is advisable to listen to different voices with an ecological view. For instance, hunting is considered differently between wildlife conservatories (and governments) and local communities in Africa. The former only restrict it to the tracking and subsequent killing of game by "licensed" parties (usually foreigners), typically with rifles, all-terrain vehicles and professional trackers/rangers, and regard the same activity by members of local communities (usually with dogs, snares, spears and bows and arrows) as "poaching" (notwithstanding that the locals consider their own activities as hunting too). Besides giving a neutral definition (e.g. "go after wild animals to kill or catch them"), an African-oriented dictionary could point out the different understandings of the government and local communities to avoid biased representations of socio-cultural reality. The inclusion of conflicting definitions, as a way of dictionary customization in this case, may lead the government to rethink their policies, and at the same time enhance local communities' awareness of the divergence. Most importantly, the entry should give a warning against the brutal killing of animals at will, and clarify the differences in semantic prosody among hunting (neutral), poach (negative) and cull (positive). We do not mean that lexicographers should be preoccupied with providing only entries that are ecologically friendly. Sometimes, an eclectic and holistic approach is necessary for rebalancing cultural values for a sustainable society.9
5.3 Limitations and future research
Although the article offers refreshing insights into lexicographical research and practice, it is not free from limitations. The proposed approaches and models are still not substantiated with adequate empirical data from different types of dictionaries. The survey into "Big Five" dictionaries only covered 30 random pages from each of them. It was not an exhaustive retrieval of information for identifying all the destructive ideologies and frames. No investigation has been conducted into the intentions, attitudes and values of both dictionary users and designers. Furthermore, the five ways of reframing the dictionary discourse are far from enough to cover all the anti-ecological and anti-sociocultural problems.
There are theoretical and practical orientations for future research. Theoretically, eco-lexicographers still have to identify the principles similar to the succession and evolution of ecosystems, perhaps fruitful for illustrating the dynamism of different types of dictionaries. We need to reconsider, first, the values and concerns of traditional lexicography and, second, a context where ecologically oriented dictionaries compete with resources sustaining ideologies of consumption. Practically, more evidence should be collected to support the new paradigm of ecolexicography. Systematic investigations into dictionary discourse and dictionary use are needed by using techniques of data mining, machine learning and natural language processing. Different types or genres of dictionaries should be examined from an ecological perspective, and respective solutions can be found to improve them. A set of practical guidelines and methods for reframing the dictionary discourse should be developed.
Philosophically, we think that ecolexicography can gain inspiration from ancient Chinese worldviews of holism (focusing on the larger world than the body - the universe), interconnectedness, eclecticism and harmony (between the human and the cosmic, within society, and within the self). Although they might include "anthropocentric" interventions that entail ecologically constructive ideologies and practices, on the whole, they can help us engage in ecological awareness and deal with ecological crises. Different from the scientific tradition of viewing the world as separated physical parts and encouraging competitions (e.g. Darwinism), the Chinese cultural concept of "human-nature oneness" advocates altruism and tolerance (Lyu and Liu, in preparation). A harmonious view of language, mind and the world, and a new harmony of science, axiology and aesthetics are crucial (Huang and Zhao 2017; Zhou 2017) for a rebirth of lexicography in the digital era, an epoch of Anthropocene.
6. Conclusion
To conclude, ecolexicography can be redefined as a new paradigm by adding symbolic and cognitive dimensions to the microlevel of a unified framework, and by upgrading the ontological, epistemological and methodological aspects related to this field. A redefined ecolexicography raises interesting questions. Besides proposing new terms including macro-ecolexicography and micro-ecolexi-cography, we have enriched the meaning of at least three groups of old theoretical terms or practices: (1) dictionary in/as a distributed cognitive system, distributed cognition, dictionary user identity, lexicographical interaction, dialogism and heteroglossia; (2) exoecological/endoecological position, values realizing, recontextualization; (3) frame analysis, user research, and lexical database construction. Ecolexicography as a novel paradigm is emancipatory, and could be a fruitful alternative to traditional practice and research, opening fresh paths and insights in an era of big data. It may help lexicographers solve the current problems with e-dictionaries in a new light, contributing to their role of serving the ecologies of language, socio-culture and nature. Additionally, it would be conducive to philosophical reflections on metalexicography.
Nevertheless, there is still a long way to go because there are many challenging issues. E-dictionary customization, for instance, is dependent on not only users' computer skills but also financial support for lexicographical projects. Dictionary compilation is limited primarily by the time and money available to do it.
Endnotes
1 "Big Five" refers to the five best-known English learners' dictionaries: OALD, LDOCE, COBUILD, CALD (Cambridge Advanced Learners' Dictionary) and MED (Macmillan English Dictionary).
2 As words are defined relative to frames, hearing/reading a word can activate its frame and the frames in its system in the brain (Lakoff 2010). Represented in syntactic patterns, frames involve semantic roles and their relations which are ultimately connected with people's cognitive frames (ibid.).
3 With over 20 million users, iCIBA is said to be the second most popular dictionary app in China. Unfortunately, its latest version has no customization and interaction buttons as shown in Figure 4. Due to lack of data, we cannot find out if its designers would alter the entry in light of user feedback. We agree with one of the reviewers that designers' response to user feedback needs investigation because it enriches the meaning of dictionary editing/ revision as another potential basis for in-depth discussion under ecolexicography.
4 One of the reviewers suggested considering "the possibility of enhanced methodologies incorporating advanced online reach at the data-gathering stage of compiling the dictionary" to make potential users participate in the creation (rather than revision) of the dictionary. We think that it is a promising area of research. Additionally, we agree with the reviewer that "not all users will have the magnanimity to participate constructively" - some would condemn the whole dictionary just because of one entry they dislike, and "instead of co-creating meaning and value, they set out to defame the entire product and, thus, engage in 'destructive' tendencies against the dictionary". This proves the importance of ecolexicography in inculcating a sense of responsibility and correct values in dictionary users.
5 One reviewer holds that there may be ironic cases where an anti-ecological advertisement pops up ahead of ecologically sensitive entries, like dirty money sponsoring charity programs. This is one of the challenges eco-lexicography faces. Considering the varied nature and themes of advertisements, we suggest that dictionary developers be selective and refuse anti-ecological advertisements (see Dziemianko 2020 for the effect of advertising on online dictionary usefulness).
6 Customization of the interface style is important especially for the visually impaired or people with low vision who may wish to change the background color and light contrast (e.g. night theme) to adjust glare to read comfortably. We owe this idea to one of the reviewers.
7 Framing is the use of a story from one area of life (a frame) to structure how another area of life is conceptualized. Reframing is the act of framing a concept in a way that is different from its typical framing in a culture (Stibbe 2015: 47). A discourse can be reframed with concepts redefined for communicating new values.
8 One of the reviewers asked us to think of "he is evil by nature" as an illustrative example which may create a negative frame in the user's mind. One solution is to change the statement into a question (see Section 5.2).
9 We are thankful to one of the reviewers for the examples in this paragraph. S/he also mentioned the case of sanctioned culling of wildlife to reduce ballooning population sizes of specific species that threaten the environment. This kind of anthropocentricity, if unavoidable, may be justified. After all, humans form part of the ecosystem with other members of nature. Sanctioned culling of wildlife is different from animal abuse and killing at will. An ecological dictionary may allow for some flexibility and inclusiveness in treating entries that border on "ecologically (non)destructive ideologies". Eclecticism is a wise policy.
Acknowledgments
This work was supported by: the Philosophy and Social Science Fund of the 13th Five-year Plan of Guangdong Province of China [GD18XWW14]; the Philosophy and Social Science Fund of the 13th Five-year Plan of Guangzhou City of China [2019GZGJ24]; the Fundamental Research Fund for the Central Universities of China [XYZD201919, ZDPY202036] and the Double First-Class Construction Project [K5200690] of South China University of Technology; the MOE Project of Center for Linguistics and Applied Linguistics, Guangdong University of Foreign Studies. We'd like to express our deep gratitude to the editors and the reviewers for their constructive comments and suggestions.
References
A. Dictionaries
A New English-Chinese Dictionary (Century edition). 2003. NECD Compilation Group. Shanghai: Shanghai Translation Publishing House.
Buk Bang Sinda (Bidayuh-Malay-English Dictionary). 2013. Kuching, Malaysia: Dayak Bidayuh National Association.
Cambridge English Dictionary. Cambridge: Cambridge University Press. https://dictionary.cambridge.org/dictionary/english/. Accessed on 28 Jan. 2020.
Collins COBUILD Advanced Learner's Dictionary (8th edition, COBUILD8). 2014. Glasgow: HarperCollins. Dictionary of Environment and Ecology (5th edition). 2004. Collin, Peter H. (Ed.). London: Bloomsbury.
Fayu Zhushou French Dictionaries. Shanghai Qianyan Network Technology Corporation. An app downloaded from https://www.francochinois.com/v4/fr/app/download#mobile. Accessed on 20 Jan. 2020.
Jinshan Ciba English Dictionaries (iCIBA). Jinshan Software Corporation. http://cp.iciba.com. Downloaded and consulted on 20 Jan. 2018.
Lexico.com (Oxford Dictionaries English). Dictionary.com and OUP. https://www.lexico.com/. Accessed on 12 Apr. 2020.
Longman Dictionary of Contemporary English. Pearson Education. http://www.ldoceonline.com/. Accessed on 25 Jan. 2020.
Longman Dictionary of Contemporary English (5th edition, LDOCE5). 2009. Mayor, Michael and Chris Fox (Eds.). London: Pearson Education.
Merriam-Webster's Learner's Dictionary. http://www.learnersdictionary.com. Merriam-Webster, Incorporated. Accessed on 12 Apr. 2020.
Oxford Advanced Learner's Dictionary (9th edition, OALD9). 2015. Deuter, Margaret, Jennifer Bradbery and Joanna Turnbull (Eds.). Oxford: OUP.
Urban Dictionary. https://www.urbandictionary.com. Accessed on 12 Apr. 2020.
Wordsmyth Kids Dictionary (WILD). https://kids.wordsmyth.net/wild/. Accessed on 13 Feb. 2018.
B. Other literature
Albuquerque, Davi B. 2018. As relações entre Ecolexicografia e Lexicografía Pedagógica (The Relations between Ecolexicography and Pedagogical Lexicography). Domínios de Lingu@gem 12(4): 20662101. [ Links ]
Baker, Paul. 2006. Using Corpora in Discourse Analysis. London: Continuum. [ Links ]
Bang, Jargen Chr. and Wilhelm Trampe. 2014. Aspects of an Ecological Theory of Language. Language Sciences 41(A): 83-92. [ Links ]
Béjoint, Henri. 2010. The Lexicography of English: From Origins to Present. Oxford: Oxford University Press. [ Links ]
Benson, Phil. 2002. Ethnocentrism and the English Dictionary. London: Routledge. [ Links ]
Bergenholtz, Henning and Sandro Nielsen. 2006. Subject-Field Components as Integrated Parts of LSP Dictionaries. Terminology 12(2): 281-303. [ Links ]
Blackmore, Elena and Tim Holmes (Eds.). 2013. Common Cause for Nature: Values and Frames in Conservation. Machynlleth, Wales: Public Interest Research Centre.
Bosch, Sonja E. and Marissa Griesel. 2020. Exploring the Documentation and Preservation of African Indigenous Knowledge in a Digital Lexical Database. Lexikos 30: 1-28. [ Links ]
Chen, Wenge. 2015. Bilingual Lexicography as Recontextualization: A Case Study of Illustrative Examples in a New English-Chinese Dictionary. Australian Journal of Linguistics 35(4): 311-333. [ Links ]
Chen, Wenge. 2017. Lexicography, Discourse and Power: Uncovering Ideology in the Bilingualization of a Monolingual English Dictionary in China. Pragmatics and Society 8(4): 601-629. [ Links ]
Chen, Wenge. 2019. Towards a Discourse Approach to Critical Lexicography. International Journal of Lexicography 32(3): 362-388. [ Links ]
Cowley, Stephen J. 2011. Distributed Language. Cowley, Stephen J. (Ed.). 2011. Distributed Language: 1-14. Amsterdam/Philadelphia: John Benjamins. [ Links ]
Cronin, Michael. 2017. Eco-Translation: Translation and Ecology in the Age of the Anthropocene. Abingdon/ New York: Routledge. [ Links ]
Dziemianko, Anna. 2020. Smart Advertising and Online Dictionary Usefulness. International Journal of Lexicography 33(4): 377-403. [ Links ]
Ezquerra, Manuel A. 1995. Political Considerations on Spanish Dictionaries. Kachru, Braj B. and Henry Kahane (Eds.). 1995. Cultures, Ideologies and the Dictionary: Studies in Honor of Ladislav Zgusta: 143-152. Tübingen: Max Niemeyer. [ Links ]
Fairclough, Norman. 1992. The Appropriacy of "Appropriateness". Fairclough, Norman (Ed.). 1992. Critical Language Awareness: 33-56. London: Longman. [ Links ]
Farina, Donna M.T.Cr., Marjeta Vrbinc and Alenka Vrbinc. 2019. Problems in Online Dictionary Use for Advanced Slovenian Learners of English. International Journal of Lexicography 32(4): 458-479. [ Links ]
Fellbaum, Christiane. 2014. Large-scale Lexicography in the Digital Age. International Journal of Lexicography 27(4): 378-395. [ Links ]
Fillmore, Charles J. 1985. Frames and the Semantics of Understanding. Quaderni Di Semantica 6(2): 222-254. [ Links ]
Fillmore, Charles J. and Collin F. Baker. 2009. A Frames Approach to Semantic Analyis. Heine, Bernd and Heiko Narrog (Eds.). 2009. The Oxford Handbook of Linguistic Analysis: 313-339. Oxford: Oxford University Press. [ Links ]
Fusari, Sabrina. 2018. Changing Representations of Animals in Canadian English (1920s-2010s). Language & Ecology: 1-32.
Gibson, James J. 1979. The Ecological Approach to Visual Perception. Boston: Houghton Mifflin. [ Links ]
Godwin-Jones, Robert. 2011. Emerging Technologies: Mobile Apps for Language Learning. Language Learning & Technology 15(2): 2-11. [ Links ]
Gouws, Rufus H. 2014. Article Structures: Moving from Printed to e-Dictionaries. Lexikos 24: 155-177. [ Links ]
Gouws, Rufus H. and Sven Tarp. 2017. Information Overload and Data Overload in Lexicography. International Journal of Lexicography 30(4): 389-415. [ Links ]
Granger, Sylviane. 2012. Electronic Lexicography: From Challenge to Opportunity. Granger, Sylviane and Magali Paquot (Eds.). 2012. Electronic Lexicography: 1-11. Oxford: Oxford University Press. [ Links ]
Halliday, Michael A.K. 1985. An Introduction to Functional Grammar. London: Edward Arnold. [ Links ]
Hodges, Bert H. and Reuben M. Baron. 2007. On Making Social Psychology More Ecological and Ecological Psychology More Social. Ecological Psychology 19(2): 79-84. [ Links ]
Hoey, Michael. 2001. A Clause-Relational Analysis of Selected Dictionary Entries: Contrast and Compatibility in the Definitions of 'Man' and 'Woman'. Caldas-Coulthard, Carmen Rosa and Malcolm Coulthard (Eds.). 2001. Texts and Practices: Readings in Critical Discourse Analysis: 178-190. London: Routledge. [ Links ]
Hornscheidt, Antje. 2008. A Concrete Research Agenda for Critical Lexicographic Research within Critical Discourse Studies: An Investigation into Racism/Colonialism in Monolingual Danish, German, and Swedish Dictionaries. Critical Discourse Studies 5(2): 107-132. [ Links ]
Hu, Huilian, Hai Xu and Junjie Hao. 2019. An SFL Approach to Gender Ideology in the Sentence Examples in The Contemporary Chinese Dictionary. Lingua 220: 17-30. [ Links ]
Huang, Fang and Sven Tarp. 2021. Dictionaries Integrated into English Learning Apps: Critical Comments and Suggestions for Improvement. Lexikos 31: 68-92. [ Links ]
Huang, Guowen and Ruihua Zhao. 2017. On the Origin, Aims, Principles and Methodology of Eco-Discourse Analysis. Modern Foreign Languages 40(5): 585-596. [ Links ]
Jones, Mari C. (Ed.). 2015. Policy and Planning for Endangered Languages. Cambridge: Cambridge University Press. [ Links ]
Kravchenko, Alexander V. 2009. The Experiential Basis of Speech and Writing as Different Cognitive Domains. Pragmatics & Cognition 17(3): 527-548. [ Links ]
Kress, Gunther and Theo van Leeuwen. 2006. Reading Images: The Grammar of Visual Design. 2nd edition. London: Routledge. [ Links ]
Lakoff, George. 2010. Why It Matters How We Frame the Environment. Environmental Communication 4(1): 70-81. [ Links ]
Lakoff, George. 2014. Don't Think of an Elephant! Know Your Values and Frame the Debate. 2nd edition. Vermont: Chelsea Green Publishing. [ Links ]
Larsen-Freeman, Diane. 2011. Complex, Dynamic Systems: A New Trandisciplinary Theme for Applied Linguistics? Language Teaching 45(2): 202-214. [ Links ]
Lee, Sang Yong. 2017. A Theoretical Model for a Dictionary of the Endangered Sherpa Language. Unpublished M.A. thesis. Stellenbosch: Stellenbosch University. [ Links ]
Lew, Robert. 2010. Multimodal Lexicography: The Representation of Meaning in Electronic Dictionaries. Lexikos 20: 290-306. [ Links ]
Lew, Robert. 2012. How Can We Make Electronic Dictionaries More Effective? Granger, Sylviane and Magali Paquot (Eds.). 2012. Electronic Lexicography: 343-361. Oxford: Oxford University Press. [ Links ]
Li, Ping. 2012. Ideology-oriented Translations in China: A Reader-Response Study. Perspectives 20(2): 127-137. [ Links ]
Linell, Per. 2009. Rethinking Language, Mind, and World Dialogically: Interactional and Contextual Theories of Human Sense-Making. Charlotte, NC: Information Age Publishing.
Linell, Per. 2013. Distributed Language Theory, with or without Dialogue. Language Sciences 40: 168-173. [ Links ]
Liu, Xiqin. 2015. Multimodal Definition: The Multiplication of Meaning in Electronic Dictionaries. Lexikos 25: 210-232. [ Links ]
Liu, Xiqin. 2017. Multimodal Exemplification: The Expansion of Meaning in Electronic Dictionaries. Lexikos 27: 287-309. [ Links ]
Liu, Xiqin, Dongping Zheng and Yushuai Chen. 2019. Latent Classes of Smartphone Dictionary Users among Chinese EFL Learners: A Mixed-Method Inquiry into Motivation for Mobile Assisted Language Learning. International Journal of Lexicography 32(1): 68-91. [ Links ]
Lyu, Jing and Xiqin Liu. In preparation. For a Better World: Revealing Ecology-destructive Frames in English Learner's Dictionaries.
Makkai, Adam. 1993. Ecolinguistics: Towards a New Paradigm for the Science of Language? London/ New York: Pinter Publishers. [ Links ]
Moon, Rosamund. 2014. Meanings, Ideologies and Learners' Dictionaries. Abel, Andrea, Chiara Vettori and Natascia Ralli (Eds.). 2014. Proceedings of the XVIEURALEX International Congress: The User in Focus, EURALEX 2014, Bolzano/Bozen, Italy, July 15-19, 2014: 85-105. Bolzano/ Bozen: Institute for Specialised Communication and Multilingualism.
Ogilvie, Sarah. 2013. Words of the World: A Global History of the Oxford English Dictionary. Cambridge: Cambridge University Press. [ Links ]
Rossi, Fabio and Maria Grazia Sindoni. 2017. The Phantoms of the Opera: Toward a Multidimensional Interpretative Framework of Analysis. Sindoni, Maria Grazia, Janina Wildfeuer and Kay L. O'Halloran (Eds.). 2017. Mapping Multimodal Performance Studies: 61-84. New York/ Abingdon: Routledge. [ Links ]
Sarmento, Manoel Soares. 2000. Ecolexicography: Words and Expressions We Should Live By. Österreichische Linguistiktagung Graz, 8.-10. Dezember 2000. Akten des Symposiums 30 Jahre Sprache und Ökologie - Errungenschaften, Visionen. Graz: Graz University.
Sarmento, Manoel Soares. 2002. Ecolexicography: Ecological and Unecological Words and Expressions. Fill, A., H. Penz and W. Trampe (Eds.). 2002. Colourful Green Ideas: Papers from the Conference 30 Years of Language and Ecology (Graz, 2000) and the Symposium Sprache und Ökologie (Passau, 2001): 487-492. Viena: Peter Lang. [ Links ]
Sarmento, Manoel Soares. 2005. Por Uma Ecolexicografia. Confluências 2: 84-97. [ Links ]
Steffensen, Sune Vork. 2015. Distributed Language and Dialogism: Notes on Non-Locality, Sense-Making and Interactivity. Language Sciences 50: 105-119. [ Links ]
Steffensen, Sune Vork and Alwin Fill. 2014. Ecolinguistics: The State of the Art and Future Horizons. Language Sciences 41: 6-25. [ Links ]
Stibbe, Arran. 2014. Ecolinguistics and Erasure: Restoring the Natural World to Consciousness. Hart, Christopher and Piotr Cap (Eds.). 2014. Contemporary Critical Discourse Studies: 583-602. London: Bloomsbury Academic. [ Links ]
Stibbe, Arran. 2015. Ecolinguistics: Language, Ecology and the Stories We Live By. Abingdon/New York: Routledge. [ Links ]
Tarp, Sven. 2007. Lexicography in the Information Age. Lexikos 17: 170-179. [ Links ]
Tenorio, Encarnación Hidalgo. 2000. Gender, Sex and Stereotyping in The Collins Cobuild English Language Dictionary. Australian Journal of Linguistics 20(2): 211-230. [ Links ]
Tian, Yu, Xiao-wei Wang and Xin-qi Guo. 2016. On Ecological Views in Texts of Learner's Dictionaries and Their Educational Functions: A Text Analysis of New Age English-Chinese Dictionary. Journal of Shanxi Datong University (Social Science Edition) 30(6): 73-75, 79. [ Links ]
Trampe, Wilhelm. 2001. Language and Ecological Crisis: Extracts from a Dictionary of Industrial Agriculture (Translated by Peter Mühlhäusler). Fill, Alwin and Peter Mühlhäusler (Eds.). 2001. The Ecolinguistics Reader: Language, Ecology and Environment: 232-240. London/New York: Continuum. [ Links ]
Tsunoda, Tasaku. 2005. Language Endangerment and Language Revitalization. Trends and Linguistics Studies and Monographs 148. Berlin/New York: De Gruyter. [ Links ]
Van Leeuwen, Theo. 2005. Introducing Social Semiotics. London/New York: Routledge. [ Links ]
Van Lier, Leo. 2002. An Ecological-Semiotic Perspective on Language and Linguistics. Kramsch, Claire (Ed.). 2002. Language Acquisition and Language Socialization: Ecological Perspectives: 140-164. London/New York: Continuum. [ Links ]
Wang, Ning. 2003. On the Educational Function of Dictionaries: Comments on New Century Modern Chinese Dictionary by Tongyi Wang. Lexicographical Studies 1: 1-5. [ Links ]
Willinsky, John. 1994. Empire of Words: The Reign of the OED. Princeton, N.J.: Princeton University Press.
Winestock, Christopher and Young-kuk Jeong. 2014. An Analysis of the Smartphone Dictionary App Market. Lexicography: Journal of ASIALEX 1(1): 109-119. [ Links ]
Wurm, Stephen A. 2007. Threatened Languages in the Western Pacific Area from Taiwan to, and Including, Papua New Guinea. Brenzinger, Matthias (Ed.). 2007. Language Diversity Endangered: 374-390. Berlin/New York: Mouton de Gruyter. [ Links ]
Xu, Hai. 2009. Towards Prototypical Exemplification in English Dictionaries for Chinese EFL Learners. Beijing: Science Press. [ Links ]
Yong, Heming and Jing Peng. 2007. Bilingual Lexicography from a Communicative Perspective. Amsterdam/Philadelphia: John Benjamins. [ Links ]
Zhang, Yihua. 2015. Second Language Acquisition and Learner's Dictionaries. Beijing: The Commercial Press. [ Links ]
Zhang, Yiqiong, David Machin and Tao Song. 2015. Visual Forms of Address in Social Media Discourse: The Case of a Science Communication Website. Journal of Multicultural Discourses 10(2): 236-252. [ Links ]
Zheng, Dongping. 2012. Caring in the Dynamics of Design and Languaging: Exploring Second Language Learning in 3D Virtual Spaces. Language Sciences 34(5): 543-558. [ Links ]
Zheng, Dongping, Kristi Newgarden and Michael F. Young. 2012. Multimodal Analysis of Language Learning in World of Warcraft Play: Languaging as Values-Realizing. ReCALL 24(3): 339-360. [ Links ]
Zhou, Wenjuan. 2017. Ecolinguistics: Towards a New Harmony. Language Sciences 62: 124-138. [ Links ]


ARTICLES
Lexicographic Data Boxes. Part 2: Types and Contents of Data Boxes with Particular Focus on Dictionaries for English and African Languages*
Leksikografiese datakassies. Deel 2: Tipes datakassies en hulle inhoud, met spesifieke verwysing na woordeboeke vir Engels en die Afrikatale
D.J. PrinslooI; Rufus H. GouwsII
IDepartment of African languages, University of Pretoria, South Africa (danie.prinsloo@up.ac.za)
IIDepartment of Afrikaans and Dutch, Stellenbosch University, South Africa (rhg@sun.ac.za)
ABSTRACT
This article, the second in a series of three on lexicographic data boxes, focuses primarily on the types and contents of data boxes with particular reference to dictionaries for English and African languages. It will be proposed that data boxes in paper and electronic dictionaries can be divided into three categories and that a hierarchy between these types of boxes can be distinguished, i.e. (a) a bottom tier - data boxes used as mere alternatives to other lexicographic ways of presentation such as the bringing together of related items and/or to make entries visually more attractive, (b) a middle tier - addressing more salient features e.g. range of application, contrast, register, restrictions, etc. and (c) a top tier - vital salient information, e.g. warnings, taboos and even illegal words. A distinction is made between data boxes which are universal in nature, i.e. applicable to any language, data boxes pertaining to a language family and data boxes applicable to a specific language.
Keywords: dictionaries, lexicographic data boxes, text boxes, shaded BOXES, AFRICAN LANGUAGES, SEPEDI, ISIZULU
OPSOMMING
Hierdie artikel, die tweede in 'n reeks van drie oor leksikografiese datakassies, fokus hoofsaaklik op die tipes datakassies en hulle inhoud, met spesifieke verwysing na woordeboeke vir Engels en die Afrikatale. Daar sal voorgestel word dat datakassies in papier- en elektroniese woordeboeke in drie kategorieë verdeel kan word en dat 'n hiërargie tussen hierdie tipes kassies onderskei kan word, d.w.s. (a) 'n onderste vlak - datakassies wat slegs as alternatiewe vir ander leksiko-grafiese aanbiedingsmetodes gebruik word soos die bymekaarbring van verwante items en/of om inskrywings visueel aantrekliker te maak; (b) 'n middelvlak - om meer opvallende kenmerke aan te spreek, bv. die reikwydte, kontras, register, beperkings, ens. en (c) 'n hoogste vlak - essensiële inligting, bv. waarskuwings, taboes en selfs onwettige woorde. Daar word onderskei tussen data-kassies wat universeel van aard is, dit wil sê van toepassing op enige taal, datakassies wat ter sake is vir 'n taalfamilie en datakassies wat van toepassing is op 'n spesifieke taal.
Sleutelwoorde: woordeboeke, leksikografiese datakassies, tekskassies, SKADU-DATAKASSIES, AFRIKATALE, SEPEDI, ISIZULU
1. Introduction
Data boxes are commonly used in paper and electronic dictionaries to convey a variety of data not typically catered for by, what could be called standard presentation procedures that employ for example items giving the paraphrase of meaning (definitions), translation equivalents, examples of usage, pictorial illustrations, pronunciation guidance, and frequency indicators. Data boxes are used in cases where data entries are required to improve the lexicographic presentation and treatment - they add value to the default treatment. They typically include a variety of data types such as guidance in terms of grammar, pronunciation, sense distinction, contrasting related words, restrictions on the range of application, register, pronunciation, etc. Gouws and Prinsloo (2005: 133) state that:
... text boxes are put to good use to convey relevant data which falls outside the scope of the default categories presented in the normal search fields of the article.
Oxford Bilingual School Dictionary: Zulu and English (OZSD) and Oxford Bilingual School Dictionary: Northern Sotho and English (ONSD) refer to their shaded boxes as usage notes and describe their nature as follows.
Usage notes guide learners on potential areas of difficulty, helping them avoid common mistakes. Usage notes are also used to give additional information on how and when to use a headword (OZSD and ONSD: vi).
In the section "using your dictionary", Macmillan English Dictionary for Advanced Learners (MED) distinguishes between three types of shaded boxes, i.e. "information to learn more about how a word is used", "hints to avoid common errors" and notes that tell you about the origin of a word". Oxford Advanced Learner's Dictionary of Current English (OALDC) (Appendix 9: 1414) provides notes on usage of various types, e.g. clarification of grammar aspects, British and American usage or dealing with differences between words with similar meanings. Reader's Digest Afrikaans-Engelse Woordeboek / English-Afrikaans Dictionary (RWD) (page 5) informs the user about shaded boxes announced as "understand the other language as never before".
... there are always problems that constantly trip one up. In order to help you overcome the trickier points of style and usage we have included hundreds of 'words in action' ...
However, in spite of the frequent occurrence of data boxes in a variety of dictionary types, relatively little has been done to analyse data boxes with regard to the data types included in these boxes or the typological range of data boxes. This article embarks on an effort to identify different types of data found in data boxes of existing paper and electronic dictionaries and suggests that these boxes can be divided into three categories based upon type and content. it will be proposed that a hierarchical ordering between these categories can be distinguished, i.e. (a) a bottom tier - data boxes used as mere alternatives to other lexicographic ways of presentation, e.g. mere groupings or bringing together of related items. This is often done to make an entry visually more attractive; (b) a middle tier - giving more data, comparable to the type of additional data often found through cross-references, but addressing more salient features and (c) a top tier - vital salient data, e.g. warnings, taboos and even illegal words. Any attempt at the classification of data boxes is, however, arbitrary - no water tight classification is possible since a single data box often deals with a variety of issues as in figure 1. This data box primarily displays words and expressions semantically related to the word mad, but it also conveys other types of usage guidance. A number of bullets deal with register, i.e. formal versus informal use of the word, the third and fifth bullets deal with offensive use, the sixth bullet gives grammatical restrictions, and bullets 2, 3, 4, and 7 contrast language variations i.e. British English versus American English in this case.

Different scopes of application can also be distinguished, i.e. data box types which are (a) general in nature and not restricted to any specific language; (b) data box types pertaining to a language family and (c) data box types applicable to a specific language. Typical examples of the general utilization of data boxes are specifying semantic and syntactic restrictions, contrasting related words, warning against improper use, etc. Data boxes applicable to a language family deal with data that members of a specific language family have in common. Typical examples, given in a next section, of data boxes pertaining to a language family are those dealing with nominal classes, concords and pronouns. For a specific language it would, e.g. be data boxes giving syntactic restriction for specific words, e.g. question particles afa and afaeya in Sepedi.
This article does not take a critical approach to either the contents and presentation of data boxes or whether a specific entry that might perhaps be regarded as a data box in a current dictionary actually qualifies to be called a data box. Criteria for data boxes have yet to be formulated and it will not be done in this article. Data boxes are typically presented as frames or as a coloured background to one or more items in a dictionary. For the purpose of this article the occurrence of frames as a slot for the accommodation of certain items or of a coloured section functioning as highlighting background to certain items will be regarded as data boxes. A critical assessment with proposals for what should actually qualify as a data box is envisaged for the last article in this trilogy.
A topic not discussed in this article regards the metalanguage used in data boxes in bilingual dictionaries. Arguments could be offered that the metalanguage should be the source language of a monodirectional or of a specific component of a bidirectional bilingual dictionary, but equally compelling arguments could be offered that it should be the target language in both these dictionary types. The decision regarding the metalanguage should not be done in a haphazard way. Lexicographers need to determine the needs and reference skills of their target users and the lexicographic functions to be satisfied by a given dictionary. These matters should be considered when making a decision regarding the metalanguage to be used in the data boxes of any given bilingual dictionary, but space constraints do not allow a full investigation into this aspect in this article.
Updating both printed and online dictionaries inevitably leads to changes that can also influence their use of data boxes. The data boxes discussed in this paper come from specific editions and versions of the respective printed or online dictionaries. Some of these data boxes no longer appear in the most recent editions or versions. The authors of the article are aware of this situation but still use these examples due to their applicability to the discussion of specific contents or type of data box.
2. Proposed hierarchy of data boxes as found in current dictionaries
2.1 A bottom tier of data boxes
In this category data boxes are utilized for mere groupings, bringing together of related items, and to make entries visually more attractive. The first type of data box in the bottom tier that could be distinguished is a box containing a list that brings together the different senses in a menu that provides a quick overview, as in figure 2 in MED.

The boxed senses in figure 2 could as well be presented in an alternative way, consider the same lemma in the paper version versus the Macmillan Dictionary (OMD) in figure 3.

The menu in figure 3 is a mere summary of the senses that will be presented and this form of assistance is useful especially in the case of articles of words with multiple senses. By looking at this menu the user who is interested in sense 5, for example, can save time by skipping the subcomments on semantics in which senses 1-4 are presented and go directly to the subcomment on semantics containing sense 5.
A second approach to boxing different senses is to box sense headings separately as in Cambridge Dictionary (CD) in figure 4.

In figure 4 in comparison to figure 2 the headings are not numbered nor given together but separately boxed at the start of each subcomment on semantics. The boxed information in figure 4 can be regarded as navigational devices, i.e. guide words. Taken at face value, words such as TEDIUS, UNINTERESTING, CLOUDY and STUPID in figure 5, are comparable to the boxed sections in figure 4 but words given in capital as well as lower case letters in figure 5 could be viewed as definitions.
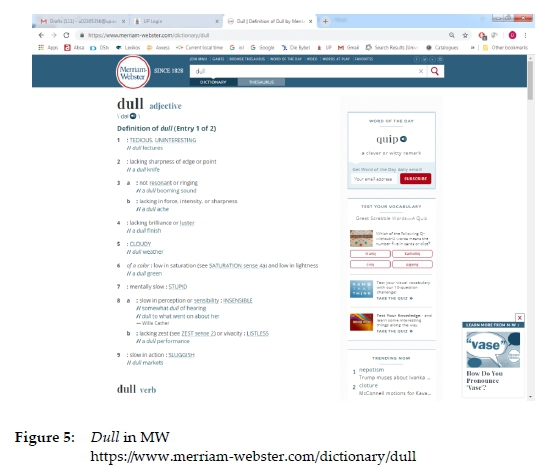
A third type of proposed low level data boxes is collocation boxes. The aim is to provide or bring together collocations of the lemma or derivatives and phrases in which it occurs in a data box as in figure 6.

The data box in figure 6 is useful to the reader looking up the word listen since it provides the typical collocations attentively, carefully, etc. in a box with the default treatment of listen.
Once again, the possible gain is on visibility - these collocations could be unboxed and presented, e.g. at the end of the article or in a search zone allocated to collocations.
A fourth type can be regarded as mere note boxes as appropriately labelled as such in (OALD). Consider figure 7 as a typical example for the data boxes linked to be2in OALD. The entry brings together the different forms of the present and past tenses of the verb be under the heading "NOTE".

Figure 7 indicates what could be called note data boxes. The presentation starts with a horizontal line, followed by a white-on-black background capitalised label "note" and the present and past tenses boxed with full borders inside the note box amidst additional text. The note box as a whole does not have vertical lines on the left and right sides but is concluded by another horizontal line.
The Oxford Dictionary of English (ODE) uses data boxes for phrases and derivatives as in figure 8.

MW uses data boxes for navigation as in figure 9.
The guidance given in bottom tier boxes can also be conveyed by other means that are employed in various dictionaries. These means, which will not be discussed here, include shortcuts, as found in the OALD, signposts, as used in the LDOCE, and guide words, as presented in the Cambridge Advanced Learner's Dictionary (CALD).
2.2 A middle tier of data boxes
This type of data box gives salient information that is not conveyed by items in the default search zones of the articles of a specific dictionary such as items giving the paraphrase of meaning, translation equivalent paradigms and examples of usage. Typical boxes deal with guidance in terms of grammar, pronunciation, sense distinction, contrasting related words, restrictions on the range of application, register, spelling, pronunciation, etc.
2.2.1 Data boxes used to contrast related words
Typical of this type of data box is contrasting two or more words or different senses of the same word in variations of the language as in figure 10.
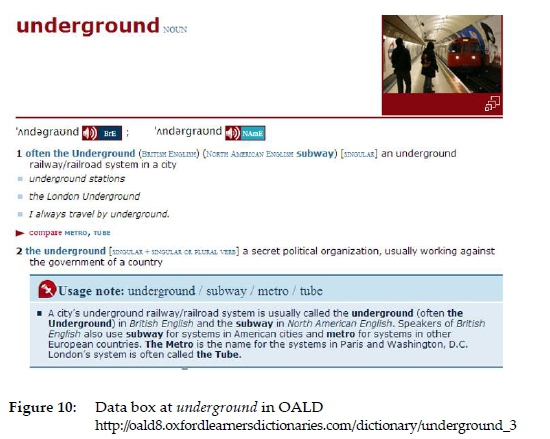
In figure 10 a data box linked to the first sense of underground nicely contrasts underground, subway, metro and tube in a very economical way. The same data box content is presented in the online Oxford Learners Dictionaries (https://www.oxfordlearnersdictionaries.com) but under the clickable menu item "+ British/ American underground / subway / metro / tube" as in figure 11.

This databox is repeated at metro, tube and subway.
In figure 12 the data box for pavement contrasts British versus American English.

Consider also an isiZulu example for kungathi versus sengathi in figure 13.

Once again, it has to be stated that lexicographers are under no obligation to provide data boxes for contrasting words - they could opt for alternative strategies or even not to contrast the words at all. Pharos Major Dictionary (PMD) treated percentage point as a sublemma in an article niche attached to the article of the main lemma percentage and provides a data box at the end of the article niche as in figure 14. The data box gives valuable additional information on percentage point and contrasts percentage and percentage point very well. In the presentation and treatment of percentage point in this case the compilers opted for a single subarticle where the default data type, i.e. a translation equivalent. is given but it is supplemented by an article-external data box. MED, however, takes a different approach by lemmatising and treating percentage and percentage point in two separate main articles without a data box or any effort to relate them as in figure 15.


2.2.2 Data boxes focused on application range or restrictions
This type of data boxes guides the user in terms of the contexts in which a word can be used as well as instances where the use of such a word would be inappropriate. Consider figure 16.

in figure 16 the data box for maritime explains the meaning of maritime as 'adjacent to the sea' but that it should not be used to refer to a house at the seaside.
2.2.3 Data boxes providing grammar information
Data boxes giving guidance to correct grammatical use cover a variety of aspects such as the use of singular versus plural forms, tense forms of verbs, translations, abbreviated and irregular forms, etc. Consider figures 17 and 18:


The use of wish in figure 17 is restricted on grammatical grounds, i.e. in terms of tense and nature of the following verb.
in figure 18 the data box for lefase indicates its use without the prefix. Consider also the data boxes for student/studente and neither in figure 19. It indicates that the form studente- is required for use as the first part of a compound and that neither should be followed by a singular noun, etc.

Finally the data boxes in figures 20 and 21 deal with the important issues, i.e. (a) that the, a and an do not have translation equivalents in isiZulu; (b) in certain cases subject concords are not translated [di1and le3] and (c) providing grammatical information on tense form of an irregular verb [-shongo].


2.2.4 Data boxes for pronunciation guidance
Pronunciation guidance is usually given in the default treatment of the lemma by means of descriptions, respelling or phonetic symbols, but specific pronunciation issues such as pronunciation comparison with other words can be given in data boxes. In figure 22 the "o" in brons is described in terms of the basic characteristics of "short" and "long".

In figure 23 guidance in pronunciation of words ending in -et, presented in the partial article stretch between the articles of et al. and etc. in Cambridge International Dictionary of English (CIDE), is given by means of phonetic transcriptions and stress on syllables.

2.2.5 Data boxes indicating register
Data boxes on register deal with issues such as formal/informal and written versus spoken language.
In figure 24 the data box reflects on change of meaning and connotations of the Afrikaans word dame compared to its English equivalent lady, and the contexts in which the use of this word is acceptable or not. The data box for optrek gives guidance on formal versus informal use as well as mentioning antiquation in certain senses.

In figure 25, among other aspects, guidance is given on the use or omission of that in spoken language.

2.2.6 Data boxes dealing with spelling
This type of data boxes mainly deals with spelling variants, capitalization and word divisions.
In figure 26 the data box indicates that both spelling variants, i.e. China and Sjina, are acceptable in Afrikaans.

In figure 27 the data box deals with word division, i.e. that this nominal suffix is written separately.

2.2.7 Data boxes indicating syntactic restrictions.
This type of data boxes mainly gives guidance on syntactic positions of words in sentences. Consider the following examples that are only relevant for Sepedi and isiZulu respectively in figures 28 and 29.


In Sepedi, the question particles afa and afaeya in contrast to the question particle na are restricted to the sentence-initial position. The auxiliary verb stem -kilego, which is in the relative mood is followed by the consecutive.
Consider also the data boxes given for the isiZulu words ngabe and lena in figure 29. These boxes indicate that na cannot be used sentence-initially but that it is permissible for ngabe and that the demonstrative pronoun lena has to be used post-nominally.
These are also good examples of a language specific issue for an African language not applicable to other members of the language family as mentioned above.
2.2.8 Data boxes dealing with obsolete, archaic and antiquating words
This type of data box has its finger on the pulse of a language in terms of language change. We regard "obsolete" and "archaic" in terms of MED as "no longer used" and "antiquating" as becoming obsolete, cf. figure 30.

In figure 30 it is indicated that although origens and owerigens have the same meaning, owerigens became archaic. The same holds true for afgelas in the sense of the intended cancellation of, e.g. a meeting, which is antiquating in favour of aflas.
2.3 A top tier of data boxes
The proposed top tier of data boxes is distinguished for providing users with indispensable salient data of a serious nature regarding warnings, taboos and even illegal words. Even inside the category of top tier, a hierarchy can be distinguished ranging from mere recommendation in the sense of 'often considered insulting' to 'avoid using this word' to 'absolutely forbidden to use', i.e. of which the use is a criminal offence and punishable by law.
In figure 31 the data box at umfazi in OZSD is an example of a mere recommendation, i.e. where a better option is suggested.

The data boxes in figures 32, 33 and 34 suggest a stronger condition, i.e. avoidance of the words crazy, old and deaf mute when referring to a person.



In the (South) African context a number of words, mostly words insulting black people, exist that are considered to be so offensive that it is illegal even to say or write these words. Aliases have to be used if reference to such words are absolutely necessary e.g. in media reports or the judicial system e.g. the k-word, n-word, h-word, m-word etc.
In 1994 the Bureau of the Woordeboek van die Afrikaanse Taal (WAT) made a sincere attempt to address this issue by organising an international conference on the handling of insulting and sensitive lexical items in order to formulate a policy on the handling of such lexical items in the WAT. Harteveld and Van Niekerk (1995: 233) report on the outcome of this conference and state that the point of departure of the WAT was to fulfil its ideal of comprehensiveness but also to follow a policy of sensitive handling of lexical items.
Die Buro van die WAT wil in sy strewe na omvattendheid nie aandadig wees aan die vestiging of bestendiging van rassistiese leksikale items deur die opname daarvan in die WAT nie, maar hy het wel 'n verantwoordelikheid om gebruikers te waarsku teen die rassistiese aard van sekere leksikale items. Dit kan hy slegs doen as hy hierdie leksikale items identifiseer en op een of ander wyse onder die aandag van die gebruiker bring. (Harteveld and Van Niekerk 1995: 235) (The Bureau of the WAT, in its pursuit of comprehensiveness, does not want to be complicit in the establishment or perpetuation of racist lexical items by including them in the WAT, but it does have a responsibility to warn users against the racist nature of certain lexical. items. He can only do this and if he identifies these lexical items and somehow brings them to the attention of the user.)
The dilemma of lexicographers is clear - on the one hand they do not want to contribute to the use of offensive lexical items by including them in the dictionary but on the other hand feel a strong responsibility to reflect the lexicon of the specific language and, especially, to warn their users against the use of offensive terms.
3. A summary of data box types in RWD, ONSD and OZSD
The final section of this article reflects a survey that was made of all data boxes in the Afrikaans to English side of RWD as well as the Sepedi to English and English to Sepedi side in ONSD and the isiZulu to English and English to isiZulu sides of OZSD.
In the Afrikaans to English side of RWD no less than 2,000 data boxes were provided as broken down in descending order in terms of type and given per alphabetical stretch in table 1.
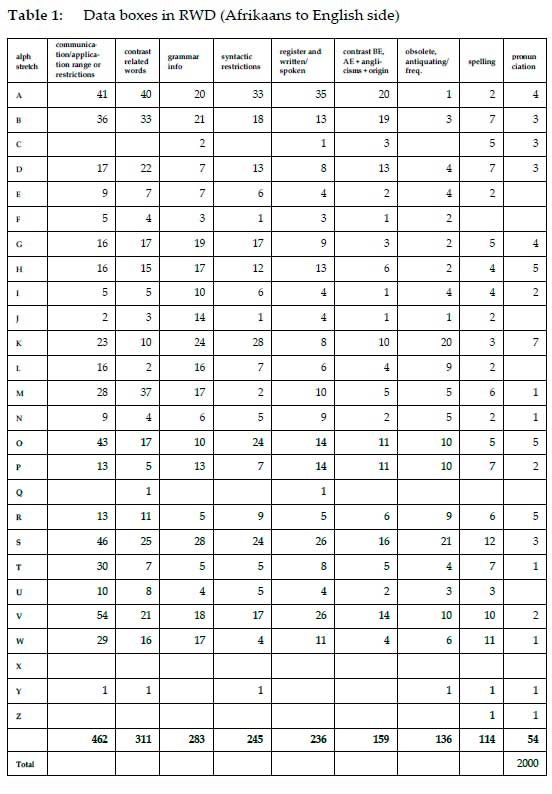
From table 1 and figure 35 it is clear that the top five types of data boxes deal with issues related to range of application, restrictions, contrast, grammar, syntactic restriction and register. The 2,000 data boxes presented in 639 pages give an average of approximately 3 boxes per page.
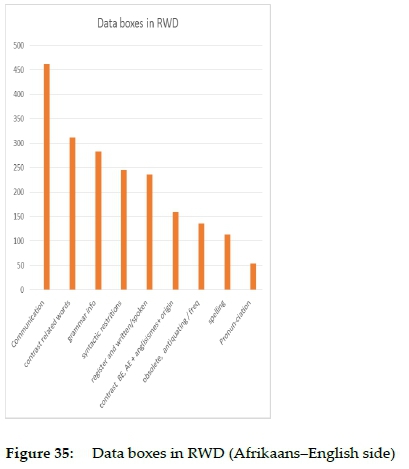
Consider the content summary of data boxes in the alphabetical stretches for M in RWD (Gouws and Prinsloo 2010: 507) in table 2 with rank comparisons of these categories between the two sides in table 3.
From the rank comparisons in table 3 it is clear that the average rank difference is very small indicating similarity in the types and contents of data boxes in the Afrikaans-English and English-Afrikaans sides.
The types of data boxes used in the Sepedi to English and English to Sepedi sides of ONSD are given in table 4 and graphically illustrated in figure 36. The data types indicated in boldface in table 4 indicate the types of data boxes that occur on both sides of the dictionary.
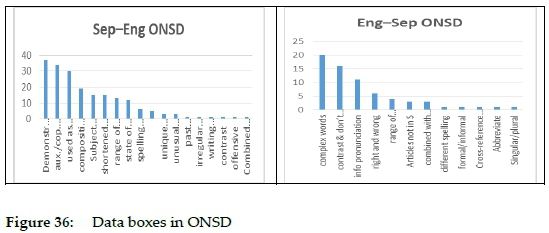
Most of the data boxes in the Sepedi to English side give guidance on the nature and use of demonstratives while most data boxes on the English to Sepedi side deal with complex words.
Data boxes giving guidance on equivalents and ways to express concepts top the list of data box contents in the English to isiZulu side and data boxes dealing with grammatical issues pertaining to syntax, tense and extended or shortened forms being the most frequent in the isiZulu to English side, cf. table 5 and figure 37.
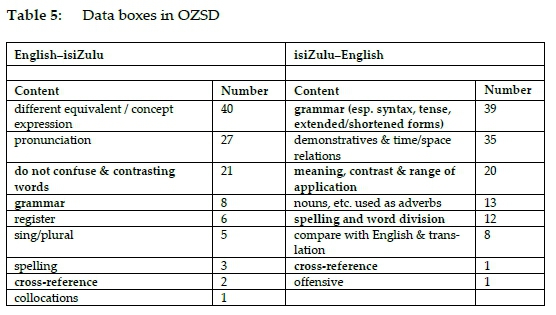
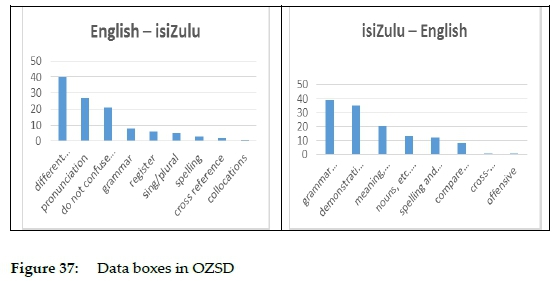
4. Conclusion
In Part 1 (this volume) the focus was on data boxes as text constituents. This article focused on the types and contents of data boxes and in Part 3 guidance will be offered for prospective compilers on data boxes of the future. In Part 2 it was emphasized that no structural planning of data boxes nor specific user-guidance on the nature and use of data boxes or distinction between different types of data boxes was observed in the dictionaries studied. Data boxes are presented in a haphazard way without any clear treatment convention and conformity. What lies beyond doubt, however, is that all the sources quoted above express a need for a lexicographic strategy to help users to avoid common mistakes, get additional information, learn more about the word and its origin, etc. The focus was on the analysis of data boxes in existing dictionaries to determine the nature of data presented in boxes and a three-part hierarchy was suggested. The first type was labelled as the mere bringing together and highlighting of aspects such as menus for the different senses of the word and lists of typical collocations. The second type, a much larger and more diverse category dealt with data boxes providing salient information which falls outside the default lexicographic treatment devices such as paraphrase of meaning, translation equivalent paradigms and examples of use. The final category represents the top tier in the proposed hierarchy namely data boxes for restricted words in terms of warnings and alerts to their use or avoidance.
Acknowledgement
This research is supported in part by the South African Centre for Digital Language Resources (SADiLaR). Findings and conclusions are those of the authors.
References
Dictionaries
CALD = Mcintosh, Colin (Ed.). 2013. Cambridge Advanced Learner's Dictionary. 4th edition. Cambridge: Cambridge University Press.
CD = Cambridge Dictionary. https://dictionary.cambridge.org/dictionary/english/. [Accessed 1 August 2020.]
CIDE = Procter, P. (Ed.). 1995. Cambridge International Dictionary of English. Cambridge: Cambridge University Press.
COD = Thompson, Della (Ed.). 1995. The Concise Oxford Dictionary. 9th Edition. Oxford: Clarendon Press.
LDOCE = Procter, P. (Ed.). 1978. Longman Dictionary of Contemporary English. Harlow: Longman. MED = Rundell, M. (Ed.). 2002. Macmillan English Dictionary for Advanced Learners. Oxford: Macmillan Education.
MW = Merriam Webster. https://www.merriam-webster.com. [Accessed 1 August 2020.]
OALD = Turnbull, J. (Ed.). 2010. Oxford Advanced Learner's Dictionary of Current English. 8th edition. Oxford: Oxford University Press. [Accessed 24 December 2013.]
OALDC = Crowther, Jonathan (Ed.). 1995. Oxford Advanced Learner's Dictionary of Current English. 5th edition. Oxford: Oxford University Press.
ODE = Oxford Dictionary of English. http://www.oxfordreference.com.
OMD = Macmillan Dictionary - British English Edition. https://www.macmillandictionary.com/dictionary/british/. [Accessed 2 August 2020.]
ONSD = De Schryver, G.-M. (Ed.). 2007. Oxford Bilingual School Dictionary: Northern Sotho and English / Pukuntsu ya Polelopedi ya Sekolo: Sesotho sa Leboa le Seisimane. E gatisitswe ke Oxford. Cape Town: Oxford University Press Southern Africa.
OZSD = De Schryver, G.-M. (Ed.). 2010. Oxford Bilingual School Dictionary: Zulu and English / Isichazamazwi Sesikole Esinezilimi Ezimbili: IsiZulu NesiNgisi, Esishicilelwe abakwa-Oxford. Cape Town: Oxford University Press Southern Africa.
PMD = Pharos Major Dictionary. Eksteen, L.C. (Ed.). 1997. Groot Woordeboek Afrikaans-Engels/Engels-Afrikaans / Major Dictionary Afrikaans-English/English-Afrikaans. 14th expanded edition. Cape Town: Pharos.
RWD = Grobbelaar, P. et al. (Eds.). 1987. Reader's Digest Afrikaans-Engelse Woordeboek /English-Afrikaans Dictionary. Cape Town: The Reader's Digest Association, South Africa (Pty) Ltd.
Other references
Gouws, R.H. and D.J. Prinsloo. 2005. Principles and Practice of South African Lexicography. Stellenbosch: SUN PReSS. [ Links ]
Gouws, R.H. and D.J. Prinsloo. 2010. Thinking out of the Box - Perspectives on the Use of Lexicographic Text Boxes. Dykstra, A. and T. Schoonheim (Eds.). 2010. Proceedings of the XIV Euralex International Congress, Leeuwarden, 6-10 July 2010: 501-511. Leeuwarden: Fryske Akademy. [ Links ]
Harteveld, P. and A.E. van Niekerk. 1995. Beleid vir die hantering van beledigende en sensitiewe leksikale items in die Woordeboek van die Afrikaanse Taal (as formulated by the authors). Lexikos 5: 232-248. [ Links ]
* This is the second in a series of three articles dealing with various aspects of lexicographic data boxes.
^rND^sGouws^nR.H.^rND^nD.J.^sPrinsloo^rND^sHarteveld^nP.^rND^nA.E.^svan Niekerk^rND^1A01^nJoy Oluchi^sUguru^rND^1A01^nJoy Oluchi^sUguru^rND^1A01^nJoy Oluchi^sUguruARTICLES
A Lexico-phonetic Comparison of Olukumi and Lukumi: A Procedure for Developing a Multilingual Dictionary
Une comparaison lexico-phonétique d'Olukumi et de Lukumi: une procedure pour développer un dictionnaire multilingue
Joy Oluchi Uguru
Department of Linguistics, University of Nigeria, Nsukka, Nigeria (joy.uguru@unn.edu.ng)
ABSTRACT
Generally, most multilingual dictionaries do not give adequate lexical and phonetic information (like contrasts and distributions). This could delay language learning (particularly among second language learners). This study demonstrates a comparative display of lexico-phonetic features of Lukumi and Olukumi in a proposed multilingual dictionary. The study, based on cognitive semantics and variation theories, proves that this display reveals how the user can distinguish the lexical and phonetic details within and across the languages. Downloaded Lukumi wordlists (132 words) were used to elicit information on Olukumi equivalents through an oral interview conducted in Ukwunzu, a major Olukumi speaking community in Delta state, Nigeria. However, 74 words were purposefully selected for comparative analysis while 23 words were used to demonstrate dictionary compilation. Through comparative analysis, free variants, synonymous and polysemous words were discovered and displayed in the dictionary. The study concludes that adequate lexical and phonetic comparison (and analysis) of words is vital in compiling a multilingual dictionary and will facilitate dictionary usage and language learning.
Keywords: lexico-phonetic, olukumi, lukumi, multilingual dictionary, COGNITIVE SEMANTICS, VARIANTS, FREE VARIATION
RÉSUMÉ
En général, la plupart des dictionnaires multilingues ne donnent pas d'informations lexicales et phonétiques adéquates (comme les contrastes et les distributions). Cela pourrait retarder l'apprentissage des langues (en particulier chez les apprenants de langue seconde). Cette étude démontre un affichage comparatif des dispositifs phonétiques lexico de Lukumi et d'Olukumi dans un dictionnaire multilingue proposé. L'étude, basée sur la sémantique cognitive et les théories de la variation, prouve que cet affichage révèle comment l'utilisateur peut distinguer les détails lexicales et phonétiques dans et entre les langues.Les listes de mots Lukumi téléchargées (132 mots) ont été utilisées pour obtenir des informations sur les équivalents Olukumi grâce à une interview orale menée à Ukwunzu, une importante communauté parlant olukumi dans l'État du Delta, au Nigeria.Cependant, 74 mots ont été délibérément sélectionnés pour l'analyse comparative tandis que 23 mots ont été utilisés pour démontrer la compilation du dictionnaire. Grâce à l'analyse comparative, des variantes libres, des mots synonymes et polysémiques ont été découverts et affichés dans le dictionnaire. L'étude conclut qu'une comparaison (et une analyse) lexicales et phonétiques adéquates des mots est essentielle à la compilation d'un dictionnaire multilingue et facilitera l'utilisation des dictionnaires et l'apprentissage des langues.
Mots-clés: LEXICO-PHONETIQUE, OLUKUMI, LUKUMI, DICTIONNAIRE MULTILINGUE, SÉMANTIQUE COGNITIVE, VARIANTES, VARIATION LIBRE
1. Introduction
According to Rundell (2012) all linguistic procedures play important and key roles in dictionary compilation. This is so because all aspects of language are interconnected and these aspects, manifested through linguistic procedures, are displayed in the dictionary. Hence it is necessary to adopt the right linguistic procedures in order to have a good and reliable dictionary. In this paper, the procedures of phonetic transcription, procedures involving the determination of phonemic variants, procedures of parts of speech classification and procedures of meaning analysis through cognitive semantics are some of the procedures undertaken in the sample compilation of Lukumi and Olukumi (with English gloss) multilingual dictionary.
Schierholz (2015) shows that different methods and phases are involved in dictionary compilation. He cites Wiegand (1998) as outlining the following phases: the preparation phase, the phase of acquiring the material and the data, the phase of treating the material and the data; the evaluation phase and the phase of preparing the material for printing.
This study defines lexico-phonetic comparison as one of these phases that are necessary for compiling a good multilingual dictionary; it could be categorized under the phases of treating and evaluating the data. Lexico-phonetic comparison is important because the proposed dictionary is a new project; hence adequate information about the languages is necessary. According to Schierholz, the lexicographer should determine the type of project being undertaken (old or new). This will go a long way to help him or her know what steps to take.
Thus this study stands at a good pedestal to produce a reliable dictionary because the necessary linguistic procedures and lexicographic methods have been adopted. For such linguistic systems (as Lukumi and Olukumi) that are largely unwritten and without standard forms, good procedures are necessary to avoid producing a dictionary that may not effectively capture their lexicon. The display of pronunciation and phonetic variables in dictionaries on African languages, particularly, is rare (Uguru and Okeke 2020; Stark 1999). This study is geared towards performing this rare and difficult task since; presently, the use of Lukumi and Olukumi is mainly oral.
In Delta state of Nigeria, a number of linguistic systems with unique features abound. These include Ika which manifests intonation and tone (Uguru 2015) unlike other Igbo dialects. Olukumi is another unique system, being a Yoruboid language spoken in an environment where Igbo is predominantly spoken (in Oshimili Local Government Area). It has high similarities with Lukumi, also a Yoruboid language spoken in Cuba (Uguru and Okeke 2020). Both varieties are in the New Benue Congo subgroup of the Niger Congo family. Lukumi has the code, ISO 639-3 luq while that of Olukumi (spelt Ulukwumi by Ethnologue) is ISO 639-3 ulb. Both are spoken by Yoruba descendants. These varieties resulted from slavery and migration respectively. Scholars have shown that Olukumi is highly related to Yoruba (Arokoyo 2012; Okolo-Obi 2014). Also, Lukumi is highly related to Yoruba (Ayoh'Omidire 2017).
Lukumi speakers are descendants of Yoruba slaves taken to Cuba. Olukumi is spoken by descendants of Yorubas who migrated from Western Nigeria to Eastern Nigeria; it is spoken in Ugbodu, Ukwunzu, Ubulubu, Idumu-ogo and Inyogo. See fig. 1 below.
According to Mason (1997) in Cuba, Lukumi (also spelt as Lucumi, Ulcumi or Ulcami) refers to Africans of Yoruba descent as well as their language. He further reveals that in the United States, Lukumi is synonymous with Orisha worship because it is basically used for traditional Yoruba religion.
Both Olukumi and Lukumi are largely unwritten and not studied in schools. Therefore, the compilation of a dictionary is a good way of enhancing their development and usage for both oral and literary purposes. In this study therefore, we show how their lexical items can be compiled, displaying their lexical and phonetic features comparatively to enable language users and learners to easily capture their similarities and dissimilarities. This research therefore, will aid their documentation and preservation.
According to Mason (1997) Yoruba descendants are called by different names in various countries: in Brazil, they are known as the Nago or the Jeje while in Haiti they are known as the Nago. In Trinidad, they are called Sango/ Shango and in Cuba, they are known as the Lukumi. Hence Lukumi designates both the language and the Yoruba descendants.
Mason (1997) further shows that Lukumi was preserved due to Africans' resistance to whites' cultural oppression. It is closely tied to the Yoruba traditional religion. In fact, Mason (op cit.) shows that in the United States, Lukumi does not refer to the descendants of Africans from Nigeria or Cuba but rather to people (irrespective of ethnicity) who practise the Yoruba traditional religion.
According to Brandon (1993) Lukumi is a sacred ritual language. Santeria worshippers are forced to use Lukumi; many worshippers could not understand the language. Olmsted (1953) therefore shows that Lukumi is a highly conservative language; worshippers believe that they can go on with worship whether they understand the language or not. According to Brandon (1993) it is acquired in adolescence and adulthood, some people learning from copyings in notebooks; thus they have limited knowledge. Furthermore, Brandon reveals that the pronunciation and spelling of Lukumi are not uniform; the variety is known by several names like Lukumi, Ulcami, Lucumi and so on. This can be confusing. Hence, studying and documenting the language in a multilingual dictionary will aid in having uniform pronunciation and spelling for its name.
Ayoh'Omidire (2003) published a book, Àkògbádün: ABC da Língua, Cultura e Civilização Iorubanas, for students in Brazil. It contains information about Orisha and Yoruba culture, poetries, songs and comparison of Brazilian Orishá traditions and Yorúbá customs. Arokoyo and Mabodu (2017) compiled Olukumi-English bilingual dictionary. However, it has some flaws as some of the lexical items were not well documented. For instance, aso (cloth) was not documented yet aso abe (under cloth), aso erefuná (curtain) and aso oyin (bee wax) were included. Also, though pronunciation was indicated, the IPA symbols were not strictly followed; this could be confusing to readers. Furthermore, phonetic features like allophonic variants were not shown. Most importantly, the information supplied is on one language; the English equivalents are just the gloss of the headwords. Also, Anderson, Arokoyo and Harrison (2012) compiled a talking dictionary. This also had lapses as many words were omitted in addition to the fact that the variants and other phonetic information necessary for effective language learning were not included.
There are concerns of imminent death of Olukumi due to the influence of Igbo language spoken in neighbouring communities (Onwueme 2015). Lukumi retains Yoruba features because it is solely used for religious purposes (Ayoh'Omidire 2017). Albeit, its survival is also threatened since it is not used for everyday communication; hence the necessity of compiling a dictionary on the two varieties. The lexico-phonetic comparison carried out in this study includes the procedures of phonetic and phonological analyses, classification of parts of speech; and analysis of the meanings of lemmas. These will be aligned comparatively between the varieties and compiled for easy identification.
Lexico-phonetic information in dictionaries
While it is more straightforward, and perhaps, easier to reflect lexical information (particularly meaning and grammar) in dictionaries, it appears somewhat more tasking to indicate phonetic information of headwords in dictionaries (Sobkowiak 2000). This may be why most dictionaries, particularly those on African languages do not contain phonetic information (Uguru and Okeke 2020; Mbah et al. 2013). This is more so because the common goal in dictionary compilation is mainly meaning (Jain 2003).
The tendency for lexicographers to focus on meaning may be the reason why pronouncing dictionaries are necessary. In pronouncing dictionaries, the pronunciation and phonetic details of lemmas are displayed for language users. Such dictionaries display the pronunciation and variants to which language users can make reference. However, though these may be beneficial, they may not be easily available. Furthermore, they are not convenient to use; hardly could a language user obtain a pronouncing dictionary in addition to a learner's or general dictionary. Hence it is wiser to include phonetic information in the widely used types of dictionaries so that greater number of people will be conversant with the pronunciation of the language. Stark (1999) in his study of about fifty research works on dictionary usage, laments that only a few was centred on learners' pronunciation. Rather, the studies showed that learners neglect the phonetic aspect of language but are prone to looking up information on meaning, spelling and grammar. He summarizes this gap with the following excerpt from Sobkowiak (2000: 244):
The place of phonetics in dictionaries generally, and in learners' dictionaries in particular, its role in the composition of the macro- as well as the microstructure of the dictionary, the wonder and challenge of multimedia in machine-readable dictionaries, the psycholinguistic issues of pronunciation look-up, and many others are all waiting to be researched.
Based on the foregoing, the present study recommends that the proposed Lukumi/Olukumi dictionary, which is a learner's dictionary, include phonetic information in addition to lexical/ semantic information. This will enable foreign learners, native learners and other users have detailed information about the spoken form of the language. Hence, theories that can adequately account for, analyse and reflect both lexical and phonetic information about the varieties under study are necessary.
Booij (2003) laments that traditional dictionaries tend to emphasize written language. He shows that this ought to be corrected since information about the phonetic features of words is part of lexical information; hence it should not be ignored in the compilation of a dictionary. In giving the phonetic information, the variants of phonemes (if any) are also displayed to enable the users of the dictionary to be conversant with all the available usage featuring in the linguistic system. For instance, a Yoruba dictionary with phonetic information should give the user information about the status of [ã] in Yoruba. It should show that it is not phonemically contrastive but rather in free variation relationship with [5]. Jain (2003) has argued that each variation should be entered separately in the dictionary. We, however, argue against this because it will not only be confusing to the dictionary user, but will also make the document to be too voluminous. Rather, we propose that each variant should be attached to its headword. This way, the dictionary user knows alternating pronunciations to a given lemma. It has been shown that the pronunciation of a headword, given in International Phonetic Association symbols, should be clearly indicated in a dictionary (Jain 2003). The pronunciation of the symbols can also be simplified in the preliminary pages of the dictionary.
Sobkowiak (2000) reveals that there should be more research on the phonetic structure and choice of keywords so that the dictionary user can be well guided when looking up phonetic information. According to him, this task of phonetic look-up is difficult; hence the lexicographer needs to simplify it by making descriptions with the right choice of words and key phonetic structures. Also, words and phonetic transcriptions should be listed in such a way that they are easy to pronounce.
In giving lexical information in dictionaries, Booij (2003) opines that the emphasis should not be on giving all the possible meanings of a lemma; rather focus should be on showing its function and usage in the language. The part of speech of the lexical entry is also very vital information to be included in the dictionary. The meaning of the word, preferably given in one word, is the central information given about the lexical entry. It is however important to consider the type of dictionary and its users in giving information about headwords.
Theories for analyses
Linguistic and lexicographic theories enable the lexicographer to adequately analyse and synthesise linguistic data for dictionary compilation (Swanepoel 1994). The theories of variation and that of cognitive semantics form the base of this study. Cognitive semantics shows that language is acquired through cognition; that is, it is based on the conception of its speakers (how they conceive the world). Hence, each language will be made up of the concepts and objects around its speaker. Language is therefore, culture-bound. The concepts and objects first exist in the mind as thought patterns before being named. Hence it is only natural that people may not be able to have a lexical item for a concept or object that is not in their immediate environment, particularly if they do not have access to them. Thus though concepts are not tied to particular languages, they are influenced by environments and culture; this is why there are varied categorizations of lexical items for concepts. Hence the data used for this study are concepts that Lukumi speakers are familiar with.
The variation theory enables us to examine, explain and link the variations between the linguistic varieties. Variation means saying the same thing in different ways (Meechan and Rees-Miller 2001). It means representing a concept or object with different words. It also includes the use of varying symbols in the lexical item to represent the same object or concept (Jarrar 2018). The latter definition is the main focus of this paper. Phonology appears to be a prominent domain in which variation features (Guy 2007).
Indicating linguistic variation in a dictionary will not only avail users with alternative usages, but also aid in informing them about the origins and etymology of the variable/variant. All languages have variations; these may originate from dialects, social groups, professions and so on. Hence linguistic variation is a natural phenomenon that should not be neglected in pursuit of a standard. In the case of Lukumi and Olukumi which are still undergoing development, without any standard, it is important to include their linguistic variables (particularly phonetic variables) in their documentation. This will aid in any future development of a standard form.
According to Lanwermeyer et al. (2016) dialect variation influences phonological and lexical-semantic word processing in sentences. In their lexico-phonological comparison of lexical items in two dialect areas (Central Bavarian and Bavarian-Alemannic transition zone) they discover that /oa /oa-oa-/ and /ou - ou -/ are used variously in the two dialects. For instance, the word for straw is /Jtroa -oa -/ in BA, but in CB it is pronounced as /Jtrou-ou-/. This kind of variation, if not explained to language learners, could lead to difficulties in form-meaning associations in the dialect areas. Hence a dictionary such as the one this study projects, is very necessary. When these sound variations do not yield meaning differences, then the varying sounds are allophones and this must be pointed out in the dictionary. Information to be given includes whether occurrence is conditioned as well as the environments in which they occur. If they are not conditioned, then they are free variants (in free variation). Free variation is a situation where two or more sounds or forms occur in the same environment without a change in meaning. Alternating variants occur in regular patterns (Guy 2007).
Hence, it is significant that Olukumi and Lukumi, which are spoken by people in different continents, have a lot of lexical and phonetic similarities. Going by the cognitive semantic interpretation of their word meanings, lexical and phonetic similarities portray the fact that they have the same origin. There can be no other plausible explanation for this high degree of similarities.
Hence it is important to indicate the phonetic features of words in a dictionary since it will not only make for ease of usage, but will also reveal the relationship (that is, similarities or otherwise) between the concerned languages. Dellert et al. (2020) assert that most grammar books contain general information about the phonology of languages, and that languages, particularly less documented ones, rarely have phonetic transcriptions for individual words. They show that this causes people to depend on the written forms which could be problematic if the orthography does not fully represent pronunciation.
Adda-Decker and Lamel (2006) reveal that even in the use of speech recognizing systems, indicating phonetic features in multilingual dictionaries, particularly, helps to reduce poor performance since multilingual dictionaries contain non-native speech forms. However, most lexicographers de-emphasize phonetic features and that has resulted in its non-reflection in most dictionaries. Cermák (2010) in discussing steps in dictionary compilation, de-emphasizes pronunciation, showing that it is used only for distinction and for foreign words. This view is erroneous since anybody can benefit from the indication of the phonetic features of entries in any dictionary because both native and second language speakers (and also learners) can have access to the dictionary.
2. Methods
Lukumi word lists were downloaded from some websites (cf. references) because Lukumi is not spoken in the environment of research. Seventy four words were purposefully selected for comparative analysis and twenty three words were used to demonstrate dictionary compilation. An Olukumi native speaker supplied the Olukumi equivalents of the downloaded words during an oral interview. The equivalents in Olukumi and Lukumi were compared with words bearing similar concepts. Cognitive theory was used to analyse lexical meaning and variation theory was used to determine the phonetic variables in the two varieties. The effect of these phonetic variables on the meanings of lemmas was examined in the varieties.
Additionally, similarities and differences in the occurrence and distribution of Lukumi and Olukumi phonemes were determined. Based on this, a sample compilation of the proposed dictionary was done.
3. Lexico-phonetic comparison of Lukumi and Olukumi
In this section, the words are analysed in terms of their meanings and parts of speech and the phonemes are analysed in terms of their similarities, variation and distribution.
3.1 Phonetic comparison of the speech sounds of Lukumi and Olukumi
In this section, phonemes and lexical items that made up the sample wordlist are displayed in the following tables.

Phonetic comparison of Lukumi and Olukumi
Phonetic similarity is concerned with articulatory, acoustic, and perceptual similarities between vowels and consonants (Schepens et al. 2013).
In terms of the phonetic details, it can be observed that some Yoruba phonemes which do not exist in Lukumi exist in Olukumi. Hence Lukumi speakers replace the phonemes with those nearest to them in articulation. For instance /gb/ is replaced with /b/ in Lukumi since the former does not feature in the variety.
3.2 Prosody
The analysis of the prosodic features in the varieties is shown below.
3.2.1 Tone
Adeshokan (2018) reveals that just like in Spanish, accents feature in Lukumi words. Tone, a feature of Yoruba, the parent language, does not feature in Lukumi but it exists in Olukumi.
3.2.2 Stress and syllabic structure
Lukumi words are not tone marked but rather accents (typical of Spanish) are used to indicate stressed syllables and they usually occur in word final position (Ramos 2012; Concordia 2012). As can be observed from the data, Lukumi and Olukumi have CV syllable structure. Hence they do not have closed syllables. Spanish has a closed syllable structure but that did not influence Lukumi.
Also there are some linguistic processes that occur in both Lukumi and Olukumi varieties. For instance, syllabic repetition as a way of expressing colour is evident in the expression of dudu (Lukumi for dark) and okwukwu (Olukumi for the same colour). Similarly, funfun (white) for both varieties has syllabic repetition. Furthermore, syllable elision is observed in Olukumi. Observe the examples below.
Lukumi Olukumi
Baba ba
Babalawo awo
Yeye ye
3.3 Lexical comparison of Lukumi and Olukumi
Vowel nasality appears to be a common feature in both varieties as seen in funfun, nwun, eyin and so on. Thus the varieties share some phonetic features in addition to lexical and semantic similarities.
These can be clearly shown in lexical items in Lukumi and Olukumi which appear below.
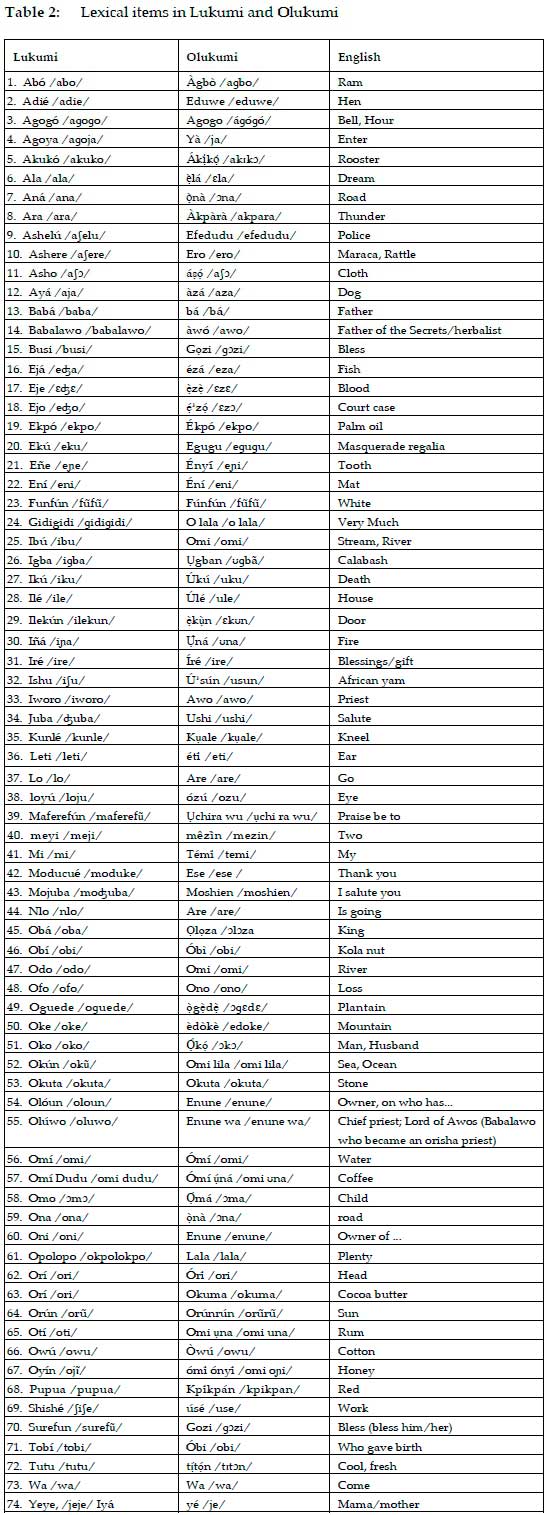
From the data above, some distribution of phonemes can be seen. These are shown in table 3.
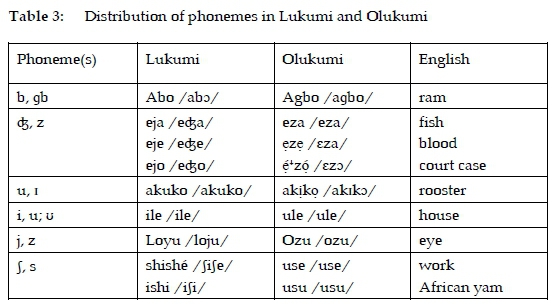
3.4 Discussion
From Tables 2 and 3, it can be observed that many of the concepts in the two varieties have the same form units. Also, some allophones exist in the varieties.
That is, some words have varying phonemes without such variations yielding changes in meaning. The allophones can be proposed to be used as free variants by language users/learners since the lemmas do not have any change of meaning when the allophones are interchanged; more so, their occurrence does not appear to be conditioned by any environment/phoneme. This is similar to what operates in the English language where either British or American spellings can be used by writers. Just as American spelling and pronunciation are indicated in dictionaries of English language, and users are free to use any one, in the proposed dictionary, Lukumi and Olukumi allophonic variations are indicated for users. Consequently, dictionary users are free to adopt anyone they feel like using since the lexical meanings are not changed by the use of varied allophones. This is what this study is all about: to display these allophonic variations and show their impact on lexical meanings.
Indicating the free variation existing between the two varieties will go a long way to help speakers and dictionary users alike. This is so because, since the variations are not complementary, grammar books alone cannot adequately be used to explain their usage to users of the languages. The variations must necessarily be pointed out in the dictionary and this is what the projected dictionary will do. This will go a long way to help learners, particularly those who use Lukumi mainly for religious purposes.
The meaning analysis of the words used for the study portrays that there are some synonymous and polysemous words in the varieties. It takes lexical analysis of meaning, using cognitive semantics, to arrive at this. These are pointed out for learners as shown in our sample compilation below. The Olukumi word for water omi for instance, is used for water, stream/river; and indicates it in its equivalent for ocean/sea 'omi lila' ocean. On the contrary, furthermore, the word 'omi' is used to show a sense of liquid as seen in omi una (rum; Olukumi data 65) (hot drink - literal translation). The same expression is also used synonymously with the equivalent for coffee (see data no. 57). Omi dudu (Lukumi data 57) and efe dudu (Olukumi data 9) reflect that both varieties make use of description in naming some concepts. Lukumi has the following words for these concepts: omi, (water), ibu (stream), okun (ocean). Similarly, Lukumi has a number of synonyms as shown in Table 2. While Olukumi has only one word, gozi, for bless, in Lukumi, both busi and surefun mean bless. All these could be confusing for a language learner hence it should be the duty of the lexicographer to reduce ambiguity by accurate indication of these features in the dictionary. These can be seen in the sample compilation below.
4. Sample compilation of lemmas for the multilingual dictionary
In a previous paper, a certain form of compilation was adopted because three languages were involved; also, free variants and detailed lexical information as well as cross references were not included. An excerpt from that paper is shown below (Uguru and Okeke 2020).
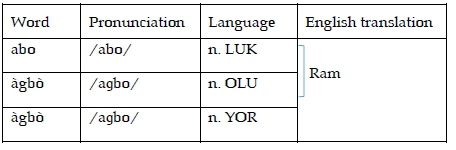
Hence, still maintaining space economy as was done in the previous paper, a new compilation method is adopted here to create room for more information that this study sets out to display in the dictionary.
In the proposed dictionary, it will be clearly pointed out at the preliminary pages, that since most head words have the same meanings in both varieties, indication of variety will only be made in cases of sound and meaning differences. That is, where there is a difference in form units. The preliminary pages will also contain the phonemes of the varieties as well as the sounds involved in free variation. Below, demonstration is made, showing sample compilation of the dictionary. The compilation shows how lemmas with the same form units can be entered, how those with varying phonemes can be entered, and how those that differ in form units can be represented in the dictionary. In addition, lexical and meaning information is given, pointing out synonymous and polysemous headwords.
4.1 The Sample Dictionary Compilation
4.1.1 Preliminary page information
Outline of phonemic distributions: In most cases, sound distribution in both varieties is as follows: in most environments where Lukumi would use the following sounds - /b, e, c%, i, j, J/ Olukumi would use the following: / gb, e, z, u, z and s/. Hence the following sounds could be used interchangeably, in the varieties, for some headwords which have the same meaning but vary in one or two phonemes: b/gb, e/e, ct;/z, i/u, j/z and J/s.
1. Abo /abo/ (ram) N; àgbò /agbo/ (Oluk) [b] / [gb] (free variants)
2. Agogó /agogo/ (bell) N.
3. Akuko /akuko/ (rooster) N. akiko /akik5/ (Oluk) u / i (free variants)
4. Babalawo (herbalist; keeper of secrets) N; Awo /awo/ (Oluk): OLUWO; IWORO
5. Busi /busi/ (bless) V; gozi /gozi/ (Oluk): SUREFUN
6. Eja /ecfea/ (fish) N; eza /eza/ (Oluk) [d3] / [z] free variants
7. Eje /ecfee/ (blood) N; eze /eze/ (Oluk)
[e] / [e]; [ct;] / [z] free variants
8. Ejo /ect;o/ (court case) N; é4,zO /ezo/ (Oluk)
[e] / [e]; [ct;] / [z] free variants
9. Ibú /ibu/ (stream, river) N; omi /omi/ (Oluk) - COMPARE OKUN, ODO, OMI
10. Ile /ile/ (house) N; ule /ule/ (Oluk)
[i] / [u] free variants
11. Ishi /ijï/ (African yam) N; usu /usu/ (Oluk)
[i] / [u]; [J] / [s] free variants
12. Iworo (chief priest) N; awo /awo/ (Oluk): BABALAWO, OLUWO
13. Iyá /ija/ (fight) N; úzà /uza/ (Oluk)
[i] / [u]; [j] / [z]; free variants
14. Loyu /loju/ (eye) N; Ozu /ozu/ (Oluk)
[j] / [z] free variants
15. Odo /odo/ (river) N; omi /omi/ (Oluk): COMPARE IBU, ODO, OMI
16. Okun /oku/ (ocean) omi lila /omi lila/ (Oluk): COMPARE IBU, ODO, OMI
17. Oluwo /oluwo/ (chief priest, lord of Awos) N; Enune wa (Oluk): BABALAWO, IWORO
18. Omi /omi/ (water) N.
19. Owó /owo/ (money) N. éghó /eyo/ (Oluk)
20. Pupua /pupua/ (red) Adj; Kpikpán /kpikpan/ (Oluk)
[p] / [kp] free variants
21. Shishé /JiJe/ (work) N; use /use/ (Oluk)
[i] / [u]; [J] / [s] free variants
22. Surefun /surefu/ (bless him) V; gozi /gozi/ (Oluk): BUSI
23. Tutu /tutu/ (cool, fresh) Adj.; títOn /titon/ (Oluk)
Key of abbreviations used in the sample:
Adj. - adjective
N. - noun
Oluk. - Olukumi
Key of abbreviations:
Adj - adjective
N - noun
Oluk. - Olukumi
V - verb
Many phonemes, words and concepts in Lukumi and Olukumi are similar despite the distance separating the locations where they are spoken. Above, we have shown these lexical and phonetic similarities in a sample Lukumi-Olukumi multilingual dictionary (with English gloss). For the entries where free variants have been indicated for instance, either of the pronunciation is acceptable as seen in economics in English which can be pronounced /eknomiks/ or / iknomiks/. It is also applicable to Igbo language where the word for ground can be pronounced as /ala/, /ali/, /ana/ or /ani/. Hence the pronunciation for the word for ram can either be pronounced as /abo/ or /agbo/. As the features of these varieties are maintained this way, they will not die; this will particularly benefit the Nigerian variety, Olukumi, whose existence is said to be threatened (Onwueme 2015).
4.2 Discussion
There are lots of similarities in the phonemes and lexical items of Lukumi and Olukumi. Interestingly, lexical similarity appears to align with phonetic/phonemic similarity in these varieties. They have mainly phonetic spelling; that is, most of their phonemes bear the same symbols as the letters of their alphabet. This is because according to Coulmas (1996) alphabets for African languages were influenced by the work of phoneticians at the International Institute of African Languages and Cultures in London. They established the Practical Orthography of African Languages; it was influenced by the International Phonetic Association, thus being based on the principle of one letter corresponding to one sound.
4.2.1 Implications of the phonetic and lexical similarities for a multilingual dictionary
Showing the phonetic and lexical similarities of entries, as done in our sample compilation in this paper, equips the dictionary user (especially language learners) adequately to undertake the use of the dictionary with ease, being able to distinguish the sounds and entries that are peculiar to a variety and the ones they share. This reduces errors in language use.
Indicating the phonetic components of words in a dictionary makes the dictionary effective for comprehension (reading and listening) and production (writing and speaking) Mdee (1997).
4.3 The significance of the multilingual dictionary in Lukumi and Olukumi conservation
In line with Kroskrity (2015) this work has documented the lexical items of two varieties, Olukumi and Lukumi and compiled them, providing their English gloss. The study reveals their lexical and phonetic features and displays these in the sample dictionary compiled in section 4.1. This will help to preserve Olukumi (spoken in Delta state, Nigeria) which is largely endangered as well as Lukumi (spoken in Cuba) which is not used for everyday activities but rather solely for religious purposes. This step will preserve these varieties, spoken in diaspora, from going into extinction. Dictionaries are of obvious importance to endangered language communities, being learning resources to speakers, including those who are acquiring their heritage languages as second languages (Haviland 2006: 129).
The use of Lukumi solely for religious purposes cannot guarantee its maintenance. For instance the sole use of Latin as a religious language has not enhanced its survival or evolution into a modern language. Hence the documentation and compilation of these varieties (alongside English translations in a multilingual dictionary) as exemplified in this paper, will go a long way to ensure their regular and wider usage, thereby preserving them from imminent death.
5. Conclusion
In this paper, we have been able to comparatively analyse the lexico-phonetic features of Lukumi and Olukumi. The analysis aided the display of lexico-phonetic features in a sample compilation of a multilingual dictionary on the varieties. Thus, lexical and phonetic information of dictionary entries were shown in the dictionary, while maintaining space economy. It was discovered that the varieties have many concepts that are represented with the same form units; hence their lexical similarities are much. In the same vein, a lot of their phonemes are similar though there are a few that are peculiar to either varieties and these peculiar ones tend to occur in the same environment with their counterparts in the other variety. Due to this peculiarity, they share many words that are in free variation. This is already shown in the sample. Also, there are synonymous and polysemous words in the varieties, particularly Lukumi.
Hence, in the sample compilation, all these were taken into account. Information about the entries in free variation was included. Furthermore, the entries that are synonymous and polysemous respectively, were indicated through cross-referencing. With this depth of information given in the dictionary, users will find it easy to understand the varieties; language learning will be a lot facilitated.
The study confirms that dictionary compilation should not be haphazard. A good analysis of the language to be compiled is important to arm the lexicographer with detailed information to display in the dictionary. Based on the analysis of the two varieties under study, the entries of the proposed dictionary are categorised as follows: words of the varieties that have the same form units and the same meaning; those that have different form units for the same concept; those that differ in one or two phonemes (free variants) across the varieties and those concepts that are represented by more than one word as well as some words that denote more than one concept. Hence this knowledge enabled adequate explanation of the entries. Therefore, we have shown how the lexical items can be compiled in the dictionary in such a way that the dictionary user can easily identify features that distinguish the entries, those that the varieties share as well as those they can interchange (free variation). This has been made possible by the analysis of lexical and phonetic features of the words.
References
Dictionaries and word lists
Anderson, G.D.S., B. Arokoyo and K.D. Harrison. 2012. Olükümi Talking Dictionary. Living Tongues Institute for Endangered Languages. Available at: http://www.talkingdictionary.org/olukumi and http://talkingdictionary.swarthmore.edu/olukumi/.
Arokoyo, B.E. and O. Mabodu. 2017. Olükümi Bilingual Dictionary. 2017. Oregon: Living Tongues Institute for Endangered Languages.
Lucumi Dictionaries. Available at: https://www.orishaimage.com/blog/dictionaries. Downloaded 30 January 2018.
Lucumi Vocabulary. Available at: http://www.orishanet.org/vocab.html. Downloaded 30 January 2018.
Map of Olukumi speaking areas
Available at: https://www.google.com.ng/search?q=map+of+olukumi+speaking+areas+in+delta+state&tbm=isch&source=iu&ictx=1&fir=hyLUQdP2J-. Downloaded 30 January 2018.
Oral interview
Lucumi Vocabulary. Available at: http://www.orishanet.org/vocab.html and https://www.orishaimage.com/blog/dictionaries. Downloaded 30 January 2018.
Ogwu, E. 2017. Word list collected from Ogwu, E. 2017. Headmaster of a primary school in Ukwunzu, (oral interview) researcher: 31st March 2017.
Other literature
Adda-Decker, M. and L. Lamel. 2006. Multilingual Dictionaries. Schultz, T. and K. Kirchhoff (Eds.). 2006. Multilingual Speech Processing: 123-168. Amsterdam et al.: MA: Academic Press.
Adeshokan, O. 2018. An In-depth Look into Lucumi and Yoruba in Comparison. The Guardian, 18 March 2018. Available at: https://guardian.ng/life/an-in-depth-look-into-lucumi-and-yoruba-in-comparison/.
Arokoyo, B.E. 2012. A Comparative Phonology of the Olukumi, Igala, Owe and Yoruba Languages. Paper presented at the Conference on Towards Proto-Niger Congo: Comparison and Reconstruction, Paris, 18-21 September 2012.
Ayoh'Omidire, F. 2003. Àkògbádún: ABC da língua, cultura e civilização iorubanas. (ABC of the Yoruba language, Culture and Civilization.) Salvador: EDUFBA. [ Links ]
Ayoh'Omidire, F. 2017. Yorúbá, Lukumí and Nagô: The Ilé-Ife Perspective. Available at: http://www.orishaimage.com/blog/felixayohomidire. Accessed 12/08/18.
Booij, G. 2003. The Codification of Phonological, Morphological, and Syntactic Information. Van Sterkenburg, P. 2003. A Practical Guide to Lexicography: 251-259. Amsterdam/Philadelphia: John Benjamins. DOI: 10.1075/tlrp.6.30boo. Available at: https://www.researchgate.net/publication/300848849 6.1. [ Links ]
Brandon, G. 1993. Santería from Africa to the New World: The Dead Sell Memories. Bloomington: Indiana University Press. [ Links ]
Cermák, F. 2010. Notes on Compiling a Corpus-Based Dictionary. Lexikos 20: 559-579. [ Links ]
Concordia, M.J. 2012. The Anagó Language of Cuba. Unpublished M.A. Thesis. Miami: Florida International University. [ Links ]
Coulmas, F. 1996. The Blackwell Encyclopedia of Writing Systems. Oxford, UK/Cambridge, Mass.: Blackwell.
Dellert, J., T. Daneyko, A. Münch, A. Ladygina, A. Buch, N. Clarius, I. Grigorjew, M. Balabel, H.I. Boga, Z. Baysarova, R. Mühlenbernd, J. Wahle and G. Jäger. 2020. NorthEuralex: A Wide-coverage Lexical Database of Northern Eurasia. Language Resources and Evaluation 54: 273-301. [ Links ]
Guy, G.R. 2007. Variation and Phonological Theory CUUK1061B-Bayley, R. and C. Lucas (Eds.). 2007. Sociolinguistic Variation: Theories, Methods, and Analysis: 5-23. Cambridge: Cambridge University Press. Available at: http://gregoryrguy.com/wp-content/uploads/GuyProofs-BayleyLucasvolpdf. [ Links ]
Haviland, J.B. 2006. Documenting Lexical Knowledge. Jost, G., P.H. Nikolaus and M. Ulrike (Eds.). 2006. Essentials of Language Documentation: 129-162. Berlin: Mouton de Gruyter. [ Links ]
Jain, M. 2003. Lexicography for Endangered Languages. Available at: http://www.tezu.ernet.in/wmcfel/pdf/Cog/lexico/03.pdf.
Jarrar, M. 2018. Introduction to Lexical Semantics. Lecture Notes on Introduction to Lexical Semantics. Birzeit University, Palestine. Available at: http://www.jarrar.info/courses/Jarrar.LectureNotes.LexicalSemantics.pdf.
Kroskrity, P.V. 2015. Designing a Dictionary for an Endangered Language Community: Lexicographical Deliberations, Language Ideological Clarifications. Language Documentation and Conservation 9: 140-157. [ Links ]
Lanwermeyer, Manuela, Karen Henrich, Marie J. Rocholl, Hanni T. Schnell, Alexander Werth, Joachim Herrgen and Jürgen E. Schmidt. 2016. Dialect Variation Influences the Phonological and Lexical-Semantic Word Processing in Sentences. Electrophysiological Evidence from a Cross-Dialectal Comprehension Study. Frontiers in Psychology 7:739. https://doi.org/10.3389/fpsyg.2016.00739. [ Links ]
Mason, J. 1997. Ogun: Builder of the Lukumi's House. Barnes, S.T. (Ed.). 1997. Africa's Ogun: Old World and New: 353-368. Second, expanded edition. Bloomington/Indianapolis: Indiana University Press. [ Links ]
Mbah, B.M., E.E. Mbah, E.S. Ikeokwu, C.O. Okeke, I.M. Nweze, C.N. Ugwuona, C.M. Akaeze, J.O. Onu, E.A. Eze, G.A. Prezi and B.C. Odii. 2013. Igbo Adi. Nsukka: University of Nigeria Press. [ Links ]
Mdee, J.S. 1997. Language Learners' Use of a Bilingual Dictionary: A Comparative Study of Dictionary Use and Needs. Lexikos 7: 94-106. [ Links ]
Meechan, Marjory and Janie Rees-Miller. 2001. Language in Social Contexts. O'Grady, William, John Archibald, Mark Aronoff and Janie Rees-Miller (Eds.). 2001. Contemporary Linguistics: 485-524. Fourth edition. Bedford: St. Martin's. [ Links ]
Okolo-Obi, B. 2014. Aspects of Olukumi Phonology. A Project Report of the Department of Linguistics, Igbo and other Nigerian Languages, University of Nigeria. Nsukka: University of Nigeria. [ Links ]
Olmsted, D.L. 1953. Comparative Notes on Yoruba and Lucumí. Journal of the Linguistic Society of America 29 (2): 157-163. [ Links ]
Onwueme, I.C. 2015. Questions Not Being Asked: Topical Philosophical Critiques in Prose, Proverbs, and Poems. Bloomington: AuthorHouse. [ Links ]
Ramos, M.W. 2012. Obí Agbón: Lukumí Divination with Coconut. Miami: Eleda.Org. Available at: https://books.google.com.ng/books?isbn=1877845116. Downloaded 27 January 2018.
Rundell, Michael. 2012. It Works in Practice but Will it Work in Theory? The Uneasy Relationship between Lexicography and Matters Theoretical. Fjeld, R.V. and J.M. Torjusen (Eds.). 2012. Proceedings of the 15th Euralex International Congress, 7-11 August 2012, Oslo: 47-92. Oslo: Department of Linguistics and Scandinavian Studies, University of Oslo.
Schepens, J., T. Dijkstra, F. Grootjen and W.J.B. van Heuven. 2013. Cross-language Distributions of High Frequency and Phonetically Similar Cognates. PLoS One 8(5): e63006. [ Links ]
Schierholz, Stefan J. 2015. Methods in Lexicography and Dictionary Research. Lexikos 25: 323-352. [ Links ]
Sobkowiak, W. 2000. Phonetic Keywords in Learner's Dictionaries. Heid, U. et al. (Eds.). 2000. Proceedings of EURALEX 2000: 237-246. Stuttgart: IMS, Universität Stuttgart. [ Links ]
Stark, M. 1999. Encyclopedic Learners' Dictionaries. Tübingen: Max Niemeyer. [ Links ]
Swanepoel, P. 1994. Problems, Theories and Methodologies in Current Lexicographic Semantic Research. Martin, W. et al. (Eds.). 1994. Euralex 1994. Proceedings, Papers Submitted to the 6th EURALEX International Congress on Lexicography in Amsterdam, The Netherlands: 11-26. Amsterdam: Vrije Universiteit. [ Links ]
Uguru, J.O. 2015. Ika Igbo. Journal of the International Phonetic Association 45(2): 213-219. [ Links ]
Uguru, J.O. and C.O. Okeke. 2020. Reflecting Pronunciation in a Multilingual Dictionary: The Case of Lukumi, Olukumi and Yoruba Dictionary. Lexikos 30: 519-539. [ Links ]
Wiegand Herbert Ernst. 1998. Wörterbuchforschung. Untersuchungen zur Wörterbuchbenutzung, zur Theorie, Geschichte, Kritik und Automatisierung der Lexikographie. Volume 1. Berlin/New York: Walter de Gruyter. [ Links ]
^rND^sBooij^nG.^rND^sCermák^nF^rND^sDellert^nJ.^rND^nT.^sDaneyko^rND^nA.^sMünch^rND^nA.^sLadygina^rND^nA.^sBuch^rND^nN.^sClarius^rND^nI.^sGrigorjew^rND^nM.^sBalabel^rND^nH.I.^sBoga^rND^nZ.^sBaysarova^rND^nR.^sMühlenbernd^rND^nJ.^sWahle^rND^nG.^sJäger^rND^sGuy^nG.R^rND^sHaviland^nJ.B^rND^sKroskrity^nP.V.^rND^sLanwermeyer^nManuela^rND^nKaren^sHenrich^rND^nMarie J^sRocholl^rND^nHanni T^sSchnell^rND^nAlexander^sWerth^rND^nJoachim^sHerrgen^rND^nJürgen^sE. Schmidt^rND^sMason^nJ^rND^sMdee^nJ.S^rND^sMeechan^nMarjory^rND^nJanie^sRees-Miller^rND^sOlmsted^nD.L.^rND^sSchepens^nJ.^rND^nT.^sDijkstra^rND^nF.^sGrootjen^rND^nW.J.B.^svan Heuven^rND^sSchierholz^nStefan J^rND^sSobkowiak^nW^rND^sSwanepoel^nP^rND^sUguru^nJ.O.^rND^sUguru^nJ.O.^rND^nC.O.^sOkeke^rND^1A01^nDragica^sZugic^rND^1A02^nMilica^sVukovic-Stamatovic^rND^1A01^nDragica^sZugic^rND^1A02^nMilica^sVukovic-Stamatovic^rND^1A01^nDragica^sZugic^rND^1A02^nMilica^sVukovic-StamatovicARTICLES
Problems in Defining Ethnicity Terms in Dictionaries
Probleme met die definiëring van etniese terme in woorde-boeke
Dragica ZugicI; Milica Vukovic-StamatovicII
IFaculty of Philology, University of Donja Gorica, Podgorica, Montenegro (dragica.zugic@udg.edu.me)
IIFaculty of Philology, University of Montenegro, Niksic, Montenegro (vmilica@ucg.ac.me)
ABSTRACT
Despite the fact that lexicographers have increasingly been taking more care when it comes to defining socially sensitive terms, we argue that ethnicity terms still remain rather poorly defined. In a number of online monolingual dictionaries we surveyed in this study, we find that ethnicity terms are generally simplistically defined, mostly in terms of geography and citizenship, and argue that such definitions are too reductionist and sometimes even erroneous. We also find that some disparaging ethnicity terms are not labelled as such in some of the dictionaries surveyed. We also present a case study from Montenegro, in which a dictionary of the national academy of sciences was immediately revoked over a few ethnicity and ethnicity-related terms, after a violent outcry from two of Montenegro's ethnic minorities, dissatisfied with how their ethnicities were defined and treated in the dictionary. Based on our survey and the earlier findings from the literature, we recommend that international dictionaries follow a standardised model of defining ethnicities, which would additionally refer to an ethnicity's culture and potentially language, and be as inclusive as possible. We also recommend that editors and lexicographers of national dictionaries pay special attention to how they define the ethnic terms relating to the minorities living in their country or region, following a combination of a standardised and a partly customised approach, which would take into account the specific features of the minorities.
Keywords: ethnicity terms, ethnicity-related terms, dictionaries, labels
OPSOMMING
Ondanks die feit dat leksikograwe in die definiëring van sosiaal-sensitiewe terme toene-mend versigtigheid aan die dag lê, word hier aangevoer dat etniese terme steeds redelik swak gedefinieer is. In 'n aantal aanlyn eentalige woordeboeke wat ons in hierdie studie ondersoek het, vind ons dat etniese terme oor die algemeen simplisties gedefinieer word, meestal in terme van geografie en burgerskap, en ons redeneer dat hierdie definisies té reduksionisties en soms selfs fou-tief is. Dit het ook geblyk dat sommige neerhalende etniese terme in sommige van die woorde-boeke wat ondersoek is nie as sodanig geëttiketteer is nie. Ons lê ook 'n gevallestudie uit Montenegro voor, waarin 'n woordeboek van die nasionale akademie van wetenskappe weens 'n paar etniese en etniesverwante terme onmiddellik onttrek is ná die geweldadige protes van twee etniese minderhede in Montenegro wat ontevrede was met die manier waarop hul etnisiteite in die woordeboek gedefinieer en hanteer is. Gegrond op ons ondersoek en die vroeëre bevindings uit die literatuur, stel ons voor dat internasionale woordeboeke 'n gestandaardiseerde model vir die definiëring van etniese terme volg wat ook sal verwys na die kultuur en moontlik taal van 'n etniese groep, en wat so inklusief moontlik sal wees. Ons beveel ook aan dat redakteurs en leksikograwe van nasionale woordeboeke besondere aandag skenk aan die manier waarop hulle die etniese terme rakende minderhede wat in hul land of streek woon, definieer deur 'n kombinasie van 'n gestandaardi-seerde en gedeeltelik pasgemaakte benadering te volg waarin die spesifieke eienskappe van die minderhede in ag geneem sal word.
Sleutelwoorde: etniese terme, etniesverwante terme, woordeboeke, Etikette
1. Introduction
A typical user expects a general dictionary to contain ethnicity terms and to define them (Rader 1989). However, even though lexicographers have been making great efforts to improve their treatment of various politically sensitive and socially charged terms over the last decades, ethnic terms in dictionaries are still described rather poorly, usually just in geographical terms and even in those cases, sometimes too restrictively. To some ethnic groups such definitions may be offensive and a dictionary can face a strong public backlash on account of this. In this paper we will describe one such recent case from Montenegro, as well as inspect the literature on the issue and comparatively analyse the definitions of ethnic terms in various online monolingual dictionaries (English, German, Italian, Croatian, Serbian, and Albanian).
We start the paper by surveying the relevant literature on how dictionaries treat politically sensitive terms, with a special focus on ethnic terms.
2. Treatment of politically sensitive terms in dictionaries
The present paper follows the tradition of studying how dictionaries treat politically sensitive terms. Some of the studies exploring these issues include the following: the treatment of ethnic names (Rader 1989), racial terms (Murphy 1991, 1998) and political terms (Dieckmann 1975; Veisbergs 2002); ideological aspects of dictionaries in general (Moon 1989; Ezquerra 1995; Wierzbicka 1995); use of offensive language (Schutz 2002); the issue of political correctness, with special emphasis on the treatment of gender (Barnickel 1999), etc. As can be seen, these studies overlap somewhat in their topics of interest and how they approach them; for our present purposes, we will say that the present paper deals with how ethnic names or ethnonyms, as politically and socially charged terms, are dealt with in dictionaries.
As Murphy (1998) argues, this type of research is conducted with two purposes in mind. The first refers to highlighting the inaccuracies and prejudice in dictionaries so that they can be corrected in later editions and prevented from occurring in new dictionaries. Insensitive treatment of some terms (particularly racial and ethnic, Murphy notes) may provoke a public outcry, as well as organised boycotts, protests and even the banning of a dictionary (see Subsection 2.2). One such recent case will be described later in the paper (Section 4). The second purpose of this type of research is to make a contribution to how we understand the relations between language, on the one hand, and social attitudes and categorisations, on the other.
All the studies mentioned reveal that dictionary definitions are indeed sometimes insensitive or ideologically charged. Reflecting the nature of human beings, the vocabulary of every language contains "unpleasant" language. Therefore, naturally, the lexicon itself will reflect unpleasant stereotypes (Schutz 2002: 640). All authors agree that ideologies, political and social aspects will always be present in the definitions and that ideologically neutral entries as a whole cannot exist (cf. Moon 1989; Ezquerra 1995; Schutz 2002). Veisbergs (2002) notes that even some seemingly innocuous choices, such as the choice of a spelling variant, for instance, may reflect ideology - e.g. by our subscribing to British spelling in this paper we take a position and reject the American one. Some of the other choices we make may be seen as offensive by some groups and the same definitions may be seen quite differently by different ideological groups.
Items in dictionaries may be offensive in two ways, Schutz (2002) finds - either directly, i.e. those used offensively with a deliberate intention, typically name-calling (e.g. nigger for a black person) or indirectly, which is far more often the case. For instance, in the examples accompanying the entry for the noun research in the online Cambridge English Dictionary1, we found an overuse of the pronoun he vs. she. Namely, in the 7 examples accompanying the definition of the term, three contained a third person singular personal pronoun and all with a male referent (e.g. his researches he dedicated his life to science; he emphasised ...). While modern dictionaries are making great efforts to avoid such infelicities, they unavoidably still do happen. This is due to the fact that many modern dictionaries are based on authentic corpora and authentic corpora reflect reality, which, in this case, includes the reality that some occupations are stereotypically seen as predominantly male jobs (typically those requiring physical strength, but also some highly intellectual ones, such as being a researcher). In addition, corpora themselves are composed of texts which are censored (every text, prior to its publication, undergoes some sort of censorship, at least self-censorship), which means that the word list based on such a corpus may not contain some words which are politically undesirable (Wierzbicka 1995: 194).
Another issue frequently cited as leading to bias in dictionaries is the fact that lexicographers are just humans and thus have human weaknesses, such as their debts to other people and their attachment to certain ideas (Ezquerra 1995: 151). They are also very likely to be imbued with their own culture, which shapes their understanding and perceptions (Veisbergs 2002). This all, of course, applies to the editor(s) of a dictionary as well. Landau (1984: 303)2 finds that dictionaries reflect prejudice and views of the upper classes, those established and well-educated ones, and so present what is valued by such groups. Dictionaries thus often reflect the leading social ideologies (Kalogjera 2001: 263).
Context is also very important in the study of potentially insulting words. Murphy (1991: 21) notes that "much of the usage labelling of racial, sexual and other epithets is based on the assumption that a member of the outgroup is using the term to describe the given ingroup". And while nigger may be used by the ingroup members to refer to themselves, it is certainly derogatory when used by the outgroup.
These issues especially become visible in the dictionaries produced under totalitarian regimes. Veisbergs (2002) observes that, inter alia, in such dictionaries some words are typically banned, while others, usually the politically charged ones, are purposefully misrepresented; in addition, some political terms are given plenty of dictionary space whereas some easily undergo a U-turn revision after certain ideas are rehabilitated in the society concerned.
These are, of course, extreme cases of visible bias in a dictionary; however, the dictionaries produced in modern democratic societies also feature some ideological distortions, in a much milder form, such as the gender bias discussed above. In the modern world, there is a growing need to correct such issues in language in general and, consequently, in dictionaries. Much of this has been driven by the movement advocating political correctness, which started in the '70s (Barnickel 1999). Some of the corrections made in the English dictionaries on account of greater sensitivities include a different treatment of the compound occupational names containing a "man"-element, e.g. the dictionaries now tend to add an admonitory note to terms for occupations ending in -man (e.g. salesman, policeman ...). The examples accompanying definitions in the dictionaries are now carefully chosen to avoid ones reflecting stereotypes; and, increasingly, care is taken to use neutral pronouns such as I or they or everyone, etc. instead of he and she; etc. (Barnickel 1999). The requests made in the name of political correctness have also been criticised as unduly exaggerated in some cases (which is why the term has itself deteriorated and now it might even have a negative ring to many), whereas the very concept is somewhat controversial and contended by those opposing any type of censorship (Busse 2000).
2.1 Treatment of ethnic terms in dictionaries
Before we delve into the research done on ethnic terms or ethnonyms, we will define what mean under the term "ethnicity". This complex term has received many different definitions in various social sciences, but most of them present it very broadly in scope and do not clearly distinguish between "ethnicity" and other close terms, such as "race" and "nationality". For Horowitz (1985) and many authors who follow his classification, ethnicity is, in fact, an umbrella term for these concepts (Chandra 2006). Similarly, some authors, including Francis (1947), Rothschild (1981), Connor (1984) and Brass (1991), do not systematically distinguish between an ethnic group and a nation, and find the two largely synonymous (Gabbert 2006). For them, an ethnicity may refer to a minority in a state, e.g. French Canadians in Canada, as well as to the French in France (Gabbert 2006). We will adhere to such an understanding of the term ethnicity, covering both these situations. In this paper, the term ethnicity was chosen rather than the term nationality for two reasons, cited in Xu (2002): first, while ethnicity is more of an academic concept, nationality is rather a legal and/or political one; second, ethnicity as a term can be more widely used than the term nationality, i.e. ethnicity can be a synonym for nationality, while the converse is not always the case. Thus, under such a broad definition, all the examples cited in this paper are considered as ethnicity labels.
The research on ethnicity terms can be divided into two strands - on the one hand, many studies have dealt with how the insulting nature of some ethnicity words is labelled in dictionaries and, on the other, little research has been conducted into the definitions of the ethnic terms which are generally not offensive.
Busse (2000), for instance, studies the insulting abbreviations for ethnicities (Frog, Jap, Kraut...) in some English learners' dictionaries and argues that, even though these terms are racist, students need to know their connotations when encountering them and advises on including them in the dictionaries. The dictionaries Busse studied varied on whether and how many of these terms they included, as well as what labels were used for indicating the genre range in which the terms are used - some were marked as taboo and some as informal (which suggests less insulting connotations than taboo). Busse commends the fact that the Oxford Advanced Learner's Dictionary puts a ! sign next such terms, as an indication to a foreign learner that these words should be avoided in use.
In the same vein of research, Norri (2000) and Nissinen (2015) find that learners' dictionaries typically have more warnings for potentially insulting words, whereas slang dictionaries (Nissinen 2015) tend to use them the least. On the other hand, some dictionaries simply decide to omit such entries (Norri 2000). In this strand of research we also find a study conducted by Çtefãnescu (2015) on labelling disparaging ethnicity words in Romanian dictionaries and Wachal's (2000) study of labelling of taboo words in British and American dictionaries.
When it comes to defining ethnicity terms that themselves have no such obvious insulting connotations, fewer studies are available. Rader (1989) argues that ethnic terms should be defined in dictionaries. Despite the typical derivational and etymological connection which exists between an ethnonym and a certain place-name, geographical criteria should not be the sole criteria in such definitions, he argues. He specifically mentions the problem of an "over- or under-lap between ethnic group and citizenship", typically ignored in the dictionaries. As an example, he gives the term Hungarian, usually defined as "a native/ inhabitant of Hungary", even though there are other ethnicities living in Hungary (Serbs and Slovaks, among others) as well as significant communities of ethnic Hungarians living in other countries (Romania, Serbia, The Czech Republie, Slovakia, etc.). Rader (1989: 133) states that "in some instances ethnicity should be separated from citizenship, and each accorded a separate definition, though I hesitate as to where the line should be drawn".
In one part of her paper, Murphy (1998) deals with the ethnicity terms in South African English dictionaries. She notes that complex issues were sometimes oversimplified in the dictionaries, which she thinks may well be acceptable for an international audience, who just needs to have a general idea of some terms, but not acceptable for the members of those ethnicities, who want a more technical or specific definition of an ethnic term that they already know (cf. Murphy 1998: 13). Therefore, the dictionary's target audience needs to be taken into account when defining these terms and certainly much more is expected of a general-purpose dictionary which is to be used locally than of a dictionary intended for an international audience, especially a learners' dictionary. Also, if certain ethnicity and ethnicity-related terms are particularly sensitive in some societies, these considerations need to be taken into account.
Rader (1989) and Murphy (1998) both find that most of the definitions of ethnic terms in dictionaries are rather simplistic, being typically geographically based, although "this common failing has been criticised for over a century" (Rader 1989: 21). In her corpus, Murphy found just one dictionary attempting to go beyond a geographical definition, but this resulted in some problematic cultural stereotypes appearing in the work. Both Rader (1989) and Murphy (1998) find that some level of standardisation of ethnicity definitions in dictionaries is certainly necessary.
Despite claims of descriptiveness, dictionaries can have a prescriptive effect (Busse 2000: 166). Bearing in mind the authoritative role they have in the modern society, both in terms of perception and education (Veisbergs 2002) and even the legal role they play in some countries given that their definitions are used in court cases (Moon 1989), every effort should be taken to address the issues raised by the studies referred to above. Research has shown that modern dictionaries have greatly improved in this respect but that there still remains room for improvement, which is why these type of studies are very important.
2.2 Public reaction to the treatment of ethnic terms in dictionaries
Hauptfleisch (1993: 84-85) states that there are two possible directions in which a public may react to how some ethnic terms are treated in a dictionary. On the one hand, he explains that critical comments coming from individual users and reviewers are quite common and should not be "unduly worrying" as they may help improve the dictionary in its ensuing editions. On the other hand, a more serious threat, one which may affect not only the dictionary itself but also the lexicographer, in terms of his/her self-confidence and status, comes from pressure groups in a community. This may take the form of an organised protest against the definitions and labelling of some derogatory terms, and also against the very inclusion of some lexical items that have offensive connotations.
Hauptfleisch (1993) further gives a brief history of such public outcries. An often-cited essay is that of Burchfield (1980), who had edited the Oxford English Dictionary for thirty years, about his experiences following the publication of the definitions of some senses of the ethnic terms such as Jew, Palestinian and Pakistani in the Concise Oxford Dictionary. The pressure included boycotts of the dictionary and confiscations of its copies, until the contested definitions were amended. Even legal action was taken but the plaintiff lost the case. From such experiences, editors may learn that they need to devote maximum attention to sensitive terms, Burchfield (1980: 292) concludes and argues that dictionaries may aim to be normative only by the use of cautionary labels and/or symbols.
A judge also ruled in the favour of the publisher of the Van Dale dictionary, which included some negative expressions regarding Jews, as reported by Hauptfleisch (1993). As Burchfield, he also concludes that such situations make editors more aware of the sensitivity of some terms and more cautious in how they handle them, which is a positive thing. Still, Hauptfleisch advises against succumbing under pressure and keeping a cool head in adhering to professional standards in a dispassionate way.
3. Ethnicity terms in various dictionaries
For the purposes of this paper, we inspected various online monolingual dictionaries and how they define ethnicities. We explore this issue using one specific ethnicity term only, but the findings are generalisable. We specifically sought entries for the ethnicity term Albanian as the definition for this entry proved to be contentious in the Montenegrin case study, which will be presented in section 4. We excluded the sense "Albanian language".
We used monolingual dictionaries which are freely accessible online, under the assumption that most users will first resort to these in an effort to look up an ethnicity term. As a result, different dictionaries are included in our study - most of them are general-purpose dictionaries, but there are also some learners' dictionaries. We covered dictionaries for several languages - English, as expected, had the largest number of free online monolingual dictionaries. We also inspected monolingual online dictionaries of German, Italian, Croatian, and Serbian, as these countries, amongst others, have considerable Albanian communities living in them. The number of the online monolingual dictionaries varied, depending on the language in question. We also included the Albanian free online monolingual dictionaries in the overview.
In the table below, we provide an overview of the dictionaries used and how they define the entry Albanian - both nouns and adjectives were inspected. Links to the relevant definitions of the entry Albanian, are given in the footnotes. The definitions from non-English dictionaries were literally translated into English.
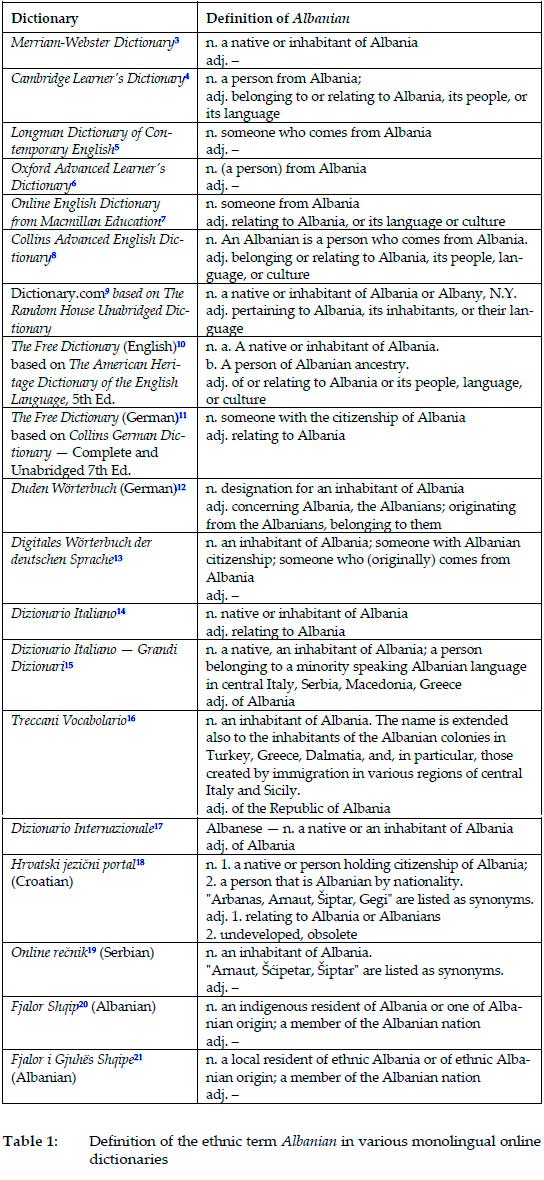
As can be seen, most of the dictionaries defined the noun using geographical criteria, defining the ethnicity term as "an inhabitant/a native of a COUNTRY", "someone from a COUNTRY". As pointed out by Rader (1989), such a designation may be problematic as there could be large communities living outside the borders of the country with whose name their ethnonym is related. We are purposefully not using the term their "homeland", as these could be autochthonous communities of people who do not hail from such a country but have always lived elsewhere. In this particular case, autochthonous communities of Albanians live in a number of countries outside Albania (Montenegro included). Also, there are large Albanian immigrant communities in many Western European and North American countries. In fact, more ethnic Albanians live outside Albania than inside it, which makes this kind of a definition even more problematic.
Some dictionaries reduced the definition of the noun to just citizenship ("someone with the citizenship of a COUNTRY"). We also find this very problematic as citizenship may be held by members of ethnic minorities living in that particular country who do not belong under the related ethnic term, e.g. in this particular case, there are Serbs, Montenegrins and Greeks living in Albania, many of them probably holding the Albanian citizenship but, generally, they would not call themselves Albanians. Equating citizenship with how one identifies himself/herself may be the prevailing norm in some countries, but in the Balkans, for instance, this has never been the case. On the other hand, the definition is also problematic as there are many ethnic Albanians living, for instance, in Montenegro and having a Montenegrin citizenship, but some of them would not identify themselves as Montenegrins.
As noted in the literature, complex issues are simplified in dictionaries and sometimes this is more justified if a dictionary is intended for an international audience, who just needs a general idea of what an ethnicity term that they are not familiar with stands for (Murphy 1998). Still, we must point out that even some international dictionaries did offer more apposite definitions when it came to the adjectival forms of the term, involving the issue of "culture" and including additionally the wording "relating to" in their definition, e.g. "belonging or relating to a COUNTRY, its people, language, or culture" (Collins Advanced English Dictionary) or "of or relating to a COUNTRY or its people, language, or culture" (The Free Dictionary based on The American Heritage Dictionary of the English Language). Namely, "belonging" and "pertaining" are too exclusive to accommodate for some of the cases discussed above (e.g. autochthonous communities of Albanians living outside Albania). "Relating to" is broader and more inclusive than these two forms, given that the ethnic communities living outside the country from whose name their ethnonym was derived, are always "related to" it in certain ways (culturally, language-wise, etc.). Going beyond geography to include culture (as well as the relation to the language), as typically one of the defining characteristics of an ethnicity, certainly is a step forward in defining ethnicity terms.
Some dictionaries from countries with large communities of Albanians offered more detailed descriptions. One such country is Italy, in which there are substantial Albanian immigrant communities. Of the four Italian dictionaries included in this review (these are all the online monolingual dictionaries for this language which we were able to find via Google search), two are quite simply based on geography, in the ways discussed above, and the other two invest more efforts in defining this community and use particularised definitions for this ethnicity. In Dizionario Italiano - Grandi Dizionari, this ethnicity also includes Albanian minorities living in several countries, who are thus defined through their language ("a minority speaking the Albanian language"), as well as geographically ("in central Italy, Serbia, Macedonia, Greece"), though this list of countries could also be contested by some as being too narrow. The Treccani Vocabolario includes immigrant communities in certain countries and regions, as well as colonies in three territories, but fails to include some significant autochthonous communities outside Albania (for instance, in Montenegro and North Macedonia). What is evident is that the lexicographers had in mind that the members of all these communities might be using their dictionary and a particularised definition would be more suitable in this case. Even though the said definitions could both be said to be lacking in some respects, this customised approach in defining an ethnicity whose members are amongst the dictionary's target audience is commendable in our opinion.
Croatia is a Balkan country with a small Albanian minority. The Croatian dictionary (Hrvatski jezicni portal) defines this ethnic term in terms of geography and citizenship ("a native or person holding citizenship of Albania") and also as follows: "a person that is Albanian by nationality", which could be characterised as a circular definition. While a circular definition solves the problem of political correctness and inclusivity, it certainly is not precise enough from a lexicographic point of view. This dictionary entry also lists some other names for this ethnicity as synonyms, one of which Albanians now find politically incorrect or even offensive ("Siptar"), with no label which would mark it as such.
The same is the case with another regional dictionary, a Serbian one (Online recnik). Serbia has a substantial Albanian minority and one of its regions, Kosovo, inhabited mostly by Albanians, declared its independence (after a history of ethnic conflicts in the region), now recognised by a considerable part of the international community. This dictionary defines an Albanian in the simplest terms, as "an inhabitant of Albania", and lists the same term ("Siptar") as a synonym without a label which would warn that this is a politically incorrect or disparaging term. We find that not using labels to mark this ethnic term as offensive is not a good practice, especially bearing in mind that these are regional and local dictionaries, the target users of which include these minorities.
We also examined two Albanian online dictionaries. They both added the meaning of "a member of the Albanian nation", similarly to the second meaning in the Croatian entry, which, despite being inclusive, we commented on as being a circular definition.
in summary, most dictionaries used rudimentary definitions for ethnicities and in the literature we saw that this is recommended, at least to a certain level (Rader 1989; Murphy 1998). As suggested above, we cannot expect international dictionaries to have detailed definitions of all ethnicities, but we did see that some of them used more inclusive definitions, involving culture and the wording "relating to" (instead of exclusively "belonging to"), which we think could be an appropriate model for international dictionaries. Some dictionaries went beyond the standardised approach when treating a minority which is substantial in the region for which the dictionary is intended. This customised approach, although it was slightly flawed in some respects in the dictionaries we inspected, could be recommended for such cases, as it provides more inclusivity. in addition, if a certain ethnicity term could be seen as politically incorrect or offensive, then it is certainly advisable to label it as such. Failing to do this might lead to a backlash from some communities, which could be justified, at least to some degree. We will describe one such extreme case in the next section.
4. Problematisation of ethnicity and ethnicity-related terms in a dictionary: A case study from Montenegro
This section will focus on a case study from Montenegro. Namely, shortly after its publication, the first dictionary of the Montenegrin language provoked violent reactions and protests from some Albanian parties and the Bosniak Party, representing two ethnic minorities living in Montenegro, due to its treatment of certain ethnicity and ethnicity-related terms. The protests had an epilogue in the Parliament and eventually caused the publisher, the Montenegrin Association of Sciences and Arts (MASA), to revoke the dictionary.
The first volume of Rjecnik crnogorskog knjizevnog i narodnog jezika (English translation: Montenegrin Dictionary of Vernacular and Literary Language), which contained 12,018 words beginning with the letters A, B and V, was published in March 2016, as the most important project of Montenegrin lexicography, representing the first complete overview of the lexical complexity of the Montenegrin language and laying the foundations for the development of the dictionaries of this type in Montenegro. As stated in the Preface, p. XI, the dictionary itself, being general and descriptive, should reflect social, scientific and civilisational reality, and give the first complete presentation of the lexical structures of the Montenegrin language, of its functional and stylistic diversity; in addition to providing a linguistic contribution, it was also supposed to be of a great cultural and national identity significance.
Soon after its publication, the problem with the definitions of the term Albanac (Eng. translation: Albanian) and its derived forms albanizacija (Eng. trans.: Albanisation) and albanizovati (Eng. trans.: to albanisate), which were seen as offensive and wrong by the Albanian people living in Montenegro, grew into a big political issue and it was regarded as case of "culturocide". A group of intellectuals, linguists, political activists and representatives of different state and private institutions, including the Albanian and the Bosniak people living in Montenegro, harshly criticised the management of MASA and the authorial team of the dictionary. They argued that MASA did not have a very favourable opinion of co-life and multiculturalism in Montenegro, and that MASA had the agenda to define, shape, recommend, propagate and try to spread their own desires, frustrations, prejudices, stereotypes, fears, covert and overt hatred. An MP of Albanian ethnicity in protest even tore a few pages of the dictionary during a live session of the National Assembly. The specific problems raised are described below:
1. Firstly, a problem arose with the ethnic term Albanac (Eng. translation: Albanian), which is defined in this dictionary as "an inhabitant of Albania; someone who is originally from Albania" (p. 43)22. This definition was seen as too reductionist, given that a substantial autochthonous Albanian minority lives in Montenegro. It follows from the dictionary definition that every Albanian must be originally from Albania and that (s)he cannot be an autochthonous inhabitant of another country and be originally from it. The dictionary definition, the Albanian representatives argued, denied them their autochthonicity in Montenegro. The authorial team argued that this was a rudimentary definition, applied to every ethnic entry in the dictionary, but this did not appease the Albanian representatives, who accused MASA of having a hidden agenda of not representing them as autochthonous in Montenegro.
Therefore, applying the standardised approach (which was followed by many international dictionaries, as we saw in Section 3), in this particular case was problematic, given the ethnic sensitivities in the country, some of them surrounding the issue of ethnic autochthonicity.
2. Another problem arose with the ethnicity-related terms albanizacija (Eng. trans.: Albanisation) and albanizovati (Eng. trans.: to albanisate), which were defined as "imposed" assimilation processes, implying aggressive actions, the critics argued. They argued that some other assimilation terms in this dictionary, did not suggest imposition - for instance, the critics referred to how balkanizacija (Eng. transl.: Balkanisation) and amerikanizacija (Eng. transl.: Americani-sation) were defined in MASA's dictionary:
- Balkanisation: "adoption of the characteristics of the languages and cultures of the Balkan peoples, adoption of the Balkan tradition" (p. 130);
- Americanisation: "1. to give someone or to something the features of the American way of life and culture; 2. to receive American characteristics, way of life and thinking, to become similar to the Americans" (pp. 56-57).
in contrast, this is how albanizacija (Eng. trans.: Albanisation) was defined:
- Albanisation: "1. to convert to Albanians; to impose the Albanian language, culture and customs on other peoples; 2. to became an Albanian; to get the characteristics of an Albanian" (p. 43).
As can be seen, the definition of the noun balkanizacija (Eng. transl.: Balkanisation) does not mention or imply any coercion, any imposition or any kind of oppression by either neighbouring or distant peoples. Moreover, balkanisation as here described happens naturally like acquiring a language. Similarly, amerikanizacija (Eng. transl.: Americanisation) indicates the introduction, acceptance, or receiving some of American characteristics, which seems to be carried out voluntarily by both those who provide the characteristics and those who accept them. Contrary to that, this dictionary suggests that Albanians imposed their culture, language and customs, and converted other nations into Albanians through the albanisation process. This was also reinforced in the example accompanying the entry, which also confirms the "imposition" implied in the definition:
Asking himself, he also offered some answers - based on the experiences of Orthodox refugees from Albania who were exposed to systematic albanianisation, especially in the time after World War II war in 1945. (Zoran Lakic)
Semantically analysed, all these terms (Albanisation, Americanisation and Balkanisation) have the same semantic base resting on assimilation (linguistic, cultural or national), which MASA lexicographers defined without implying imposition (p. 93), as "the adjustment of the minority to the majority adopting the characteristics of the majority". However, they did not use this definition as their standard for all assimilation processes, but defined them in a customised way, depending on the ethnicities involved. in this particular case, the lexicographers did not opt for a standardised approach when treating assimilation as an ethnicity-related term, which created problems.
In defining albanizacija (Eng. trans.: Albanisation), the MASA lexicographers were guided by their corpus, in which they opted to include various texts from the last 200 years. However, this means that the whole of the 19th century and the early 20th century were included, which are periods marked by a series of ethnic wars and political ideologies imbued with inter-ethnic hatred and intolerance, which the present-day society has been trying to overcome for decades now (to varying success). So, the problem with these ethnicity-related terms might be found in the corpus itself - as Wierzbicka argues (1995: 194), obsolete corpora do not reflect the contemporary reality. The lexicographers did not use labels to mark potentially disparaging meanings of the term or its use in a historical context.
3. Another problematised ethnicity term in the dictionary was "Agarjanin" (Eng. trans.: "Hagarian"23), defined as: "muslim, Turk; unbeliever, infidel" (p. 10) and accompanied by a corpus example illustrating the second meaning. The Bosniaks were especially critical of this definition as it implied an equation sign between Muslims, Turks, and infidels, they argued. The senses of the word were delimited with a comma and a semi-colon; numbers were not used to imply different meanings. No disparaging labels were used or notes on the term's historic use and meanings.
This particular case points to the importance of delimiting different meanings and marking those that are disparaging. This remains the issue, however, of what qualifies as "disparaging", as we have seen, different tendencies in the literature regarding such markings. in this case, however, a label marking the offensive uses and probably some note on the historical context of the word would have been needed.
The pressure from the Albanian and the Bosniak communities was such that the whole dictionary was revoked over a few definitions. As we have seen, in one case the problem was following a standardised definition of all ethnicity terms equally, which did not account for the autochthonous communities living outside the country from whose name their ethnonym was derived. in the second case, the lexicographers did not use a standardised approach to define assimilation processes relating to certain ethnicities, governed by their corpus which did not reflect a modern reality. in the third case, no disparaging labels were used to mark the offensive uses of the term, nor were there any delimitations between the non-offensive and the offensive meanings.
Following the outcry and criticism, the Parliament adopted a Resolution on the dictionary with recommendations to MASA to stop its distribution, which MASA did. A new, revised edition was to be issued, but this has not happened in the five years since the event. Perhaps such definitions would not have caused an outcry in another country or, at least, the reaction would not have been equally harsh, but in a country like Montenegro, in which the issue of ethnicity is an extremely sensitive one, along with the issue of autochtonicity and religion (the lines along which many stark divisions are drawn in the society), these issues become a matter to which a lexicographer should devote maximum attention.
5. Conclusions
In this paper we described the problems of defining ethnicity terms in dictionaries. We reviewed a number on online monolingual dictionaries and critically analysed their ethnic definitions, and we also described the case of Rjecnik crnogorskog knjizevnog i narodnog jezika (Eng. trans.: Montenegrin Dictionary of Vernacular and Literary Language), which was revoked over a few ethnicity and ethnicity-related terms.
We found that most of the ethnic definitions in dictionaries are rather simple, being typically geographically or citizenship-based, but some of the definitions also proved more inclusive - such was the case with the definitions involving culture, as well as with the adjectival forms which included the wording "relating to". Such definitions offered good models for international and learner's dictionaries. We also commented on the pros and cons of the customised approach to some ethnicity terms used in a small number of the dictionaries we examined. Having analysed the case of a few ethnicity and ethnicity-related terms in a Montenegrin dictionary and the public reaction which followed its publication, we concluded the same thing as Hauptfleisch (1993) and Burchfield (1980): editors and lexicographers should be very cautious in how they define and label ethnicity and ethnicity-related terms. As we have seen, sometimes rudimentary definitions will not suffice, while at other times lack of standardisation will create problems.
As suggested in the literature (Rader 1989; Murphy 1998), we argue that some level of standardisation of ethnicity definitions in dictionaries should certainly be established, but we also commend a partly customised approach when defining ethnicities which are amongst the target audience of a dictionary, particularly if the issue of ethnicity is a sensitive one in a particular society. It is the responsibility of lexicographers to examine more carefully the characteristics of such ethnic groups, their autochtonicity, culture and religion, to accompany the definitions related to ethnicity with non-ideologically imbued examples, and to mandatorily use appropriate labelling to mark the disparaging ethnicity terms and uses.
Endnotes
1 https://dictionary.cambridge.org/dictionary/english/research
2 This section is not retained in Landau (2001).
3 https://www.merriam-webster.com/dictionary/Albanian
4 https://dictionary.cambridge.org/dictionary/english/albanian
5 https://www.ldoceonline.com/dictionary/albanian
6 https://www.oxfordlearnersdictionaries.com/definition/english/albanian?q=albanian
7 https://www.macmillandictionary.com/dictionary/british/albanian_1
8 https://www.collinsdictionary.com/dictionary/english/albanian
9 https://www.dictionary.com/browse/albanian?s=t
10 https://www.thefreedictionary.com/albanian
11 https://de.thefreedictionary.com/albaner
12 https://www.duden.de/rechtschreibung/Albaner
13 https://www.dwds.de/wb/Albaner
14 https://www.dizionario-italiano.it/dizionario-italiano.php?parola=albanese
15 https://www.grandidizionari.it/Dizionario_Italiano/parola/A/albanese.aspx?query=albanese
16 http://www.treccani.it/vocabolario/ricerca/albanese/
17 https://dizionario.internazionale.it/parola/albanese
18 http://hjp.znanje.hr/index.php?show=search
19 https://onlinerecnik.com/leksikon/srpski/albanac
20 http://www.fjalorshqip.com
21 https://fjalorthi.com/shqiptar
22 The definitions from the Dictionary given here were literally translated into English.
23 Descendants from Abraham's son Ishmael, whose mother was Hagar.
References
Online dictionaries
Cambridge Learner's Dictionary. 2020. https://dictionary.cambridge.org
Collins Advanced English Dictionary. 2020. https://www.collinsdictionary.com/
Dictionary.com. The Random House Unabridged Dictionary 2020. https://www.dictionary.com
Digitales Wörterbuch der deutschen Sprache. 2020. https://www.dwds.de
Dizionario Internazionale. 2020. https://dizionario.internazionale.it/
Dizionario Italiano - Grandi Dizionari. 2020. https://www.grandidizionari.it/Dizionario_Italiano
Dizionario Italiano. 2020. https://www.dizionario-italiano.it/
Duden Wörterbuch. 2020. https://www.duden.de
Fjalor i Gjuhës Shqipe. 2020. https://fjalorthi.com
Fjalor Shqip. 2020. http://www.fjalorshqip.com
Hrvatski jezicni portal. 2020. http://hjp.znanje.hr/
Longman Dictionary of Contemporary English. 2020. https://www.ldoceonline.com
Merriam-Webster.com. 2020. https://www.merriam-webster.com
Online English Dictionary from Macmillan Education. 2020. https://www.macmillandictionary.com
Online recnik. 2020. https://onlinerecnik.com/leksikon
Oxford Advanced Learner's Dictionary. 2020. https://www.oxfordlearnersdictionaries.com
The Free Dictionary - The American Heritage Dictionary of the English Language. Fifth Edition. 2020. https://www.thefreedictionary.com
The Free Dictionary - Collins German Dictionary. Complete and Unabridged Seventh Edition. 2020. https://de.thefreedictionary.com
Treccani Vocabolario. 2020. http://www.treccani.it/vocabolario/
Other literature
Barnickel, K.-D. 1999. Political Correctness in Learners' Dictionaries. Herbst, T. and K. Popp (Eds.). 1999. The Perfect Learners' Dictionary(?): 161-174. Tübingen: Niemeyer. [ Links ]
Brass, P.R. 1991. Ethnicity and Nationalism: Theory and Comparison. Newbury Park, CA: Sage.
Burchfield, R. 1980. Dictionaries and Ethnic Sensibilities. Michaels, L. and C. Ricks (Eds.). 1980. The State of the Language: 15-23. Berkeley: University of California Press. [ Links ]
Busse, U. 2000. Recent English Learners' Dictionaries and Their Treatment of Political Correctness. Mogensen, J.E., V.H. Pedersen and A. Zettersten (Eds.). 2000. Symposium on Lexicography IX. Proceedings of the Ninth International Symposium on Lexicography, April 23-25, 1998 at the University of Copenhagen: 165-201. Tübingen: Niemeyer. [ Links ]
Chandra, K. 2006. What is Ethnic Identity and Does It Matter? Annual Review of Political Science 9: 397-424. [ Links ]
Connor, W. 1984. Eco- or Ethno-nationalism? Ethnic and Racial Studies 7(3): 342-359. [ Links ]
Dieckmann, W. 1975. Sprache in der Politik. Einführung in die Pragmatik und Semantik der politischen Sprache. Mit einem Literaturbericht zur 2. Auflage. Heidelberg: Carl Winter. [ Links ]
Ezquerra, M.A. 1995. Political Considerations on Spanish Dictionaries. Kachru, B.B. and H. Kahane (Eds.). 1995. Cultures, Ideologies, and the Dictionary: Studies in Honor of Ladislav Zgusta: 143-152. Tübingen: Niemeyer. [ Links ]
Francis, E.K. 1947. The Nature of the Ethnic Group. American Journal of Sociology 52(3): 393-400. [ Links ]
Gabbert, W. 2006. Concepts of Ethnicity. Latin American and Caribbean Ethnic Studies 1(1): 85-103. [ Links ]
Hauptfleisch, D.C. 1993. Racist Language in Society and in Dictionaries: A Pragmatic Perspective. Lexikos 3: 83-139. [ Links ]
Horowitz, D.L. 1985. Ethnic Groups in Conflict. Berkeley: University of California Press. [ Links ]
Kalogjera, D. 2001. "Teske rijeci" za leksikografa. Filologija 36-37: 263-271. [ Links ]
Landau, S. 1984. Dictionaries. The Art and Craft of Lexicography. New York: The Scribner Press. [ Links ]
Landau, S. 2001. Dictionaries. The Art and Craft of Lexicography. Second edition. Cambridge: Cambridge University Press. [ Links ]
Montenegrin Association of Sciences and Arts. 2016. Rjecnik crnogorskog knjizeunog i narodnog jezika (Montenegrin Dictionary of Vernacular and Literary Language). Podgorica: Montenegrin Association of Sciences and Arts. (revoked) [ Links ]
Moon, R. 1989. Objective or Objectionable: Ideological Aspects of Dictionaries. Knowles, M. and K. Malmkjcer (Eds.). 1989. ELR Journal 3: 59-95.
Murphy, M.L. 1991. Defining Racial Labels: Problems and Promise in American Dictionaries. Dictionaries: Journal of the Dictionary Society of North America 13(1): 43-64. [ Links ]
Murphy, M.L. 1998. Defining People: Race and Ethnicity in South African English Dictionaries. International Journal of Lexicography 11(1): 1-33. [ Links ]
Nissinen, S. 2015. Insulting Nationality Words in Some British and American Dictionaries and in the BNC. MA thesis. Tampere: University of Tampere. [ Links ]
Norri, J. 2000. Labelling of Derogatory Words in Some British and American Dictionaries. International Journal of Lexicography 13(2): 71-106. [ Links ]
Rader, J. 1989. People and Language Names in Anglo-American Dictionaries. Dictionaries. Journal of the Dictionary Society of North America 11: 125-138. [ Links ]
Rothschild, J. 1981. Ethnopolitics: A Conceptual Framework. New York: Columbia University Press. [ Links ]
Schutz, R. 2002. Indirect Offensive Language in Dictionaries. Braasch, A. and C. Povlsen (Eds.). 2002. Proceedings of the Tenth EURALEX International Congress, EURALEX 2002, Copenhagen, Denmark, August 13-17, 2002: 637-641. Copenhagen: Center for Sprogteknologi, Copenhagen University.
Stefãnescu, M. 2015. Dysphemisms for Ethnicity: Cautionary Labelling of Disparaging Ethnic Words in Some Romanian Dictionaries. Studia Universitatis Babe§-Bolyai - Philologia 60(2): 51-63. [ Links ]
Veisbergs, A. 2002. Defining Political Terms in Lexicography: Recent Past and Present. Braasch, A. and C. Povlsen (Eds.). 2002. Proceedings of the Tenth EURALEX International Congress, EURALEX 2002, Copenhagen, Denmark, August 13-17, 2002: 657-667. Copenhagen: Center for Sprog-teknologi, Copenhagen University.
Wachal, R.S. 2002. Taboo or Not Taboo: That is the Question. American Speech 77(2): 195-206. [ Links ]
Wierzbicka, A. 1995. Dictionaries and Ideologies: Three Examples from Eastern Europe. Kachru, B.B. and H. Kahane (Eds.). 1995. Cultures, Ideologies, and the Dictionary: Studies in Honor of Ladislav Zgusta: 181-196. Tübingen: Niemeyer. [ Links ]
Xu, Jieshun. 2002. Ethnic Group and Nationality: The Concepts and Their Relationships. Ethno-national Studies 1: 12-18. [ Links ]
^rND^sBarnickel^nK.-D.^rND^sBurchfield^nR.^rND^sBusse^nU.^rND^sChandra^nK.^rND^sConnor^nW^rND^sEzquerra^nM.A.^rND^sFrancis^nE.K.^rND^sGabbert^nW.^rND^sHauptfleisch^nD.C.^rND^sKalogjera^nD.^rND^sMurphy^nM.L.^rND^sMurphy^nM.L.^rND^sNorri^nJ.^rND^sRader^nJ.^rND^sStefãnescu^nM.^rND^sWachal^nR.S.^rND^sWierzbicka^nA.^rND^sXu^nJieshun^rND^1A01^nDai^sLingzhen^rND^1A01^nDai^sLingzhen^rND^1A01^nDai^sLingzhenREVIEWS
Sarah Ogilvie and Gabriella Safran (Eds.). The Whole World in a Book: Dictionaries in the Nineteenth Century. 2020, 358 pp. ISBN: 978-0190913199 (Hardback). Oxford: Oxford University Press. Price: £22.99.
Dictionaries are works of individual lexicographers or a group of lexicographers and also constrained by social and cultural factors of the time. Thus, they bear unmistakable features of the makers and the period. Historical studies of dictionaries can reveal the facts about the dictionaries and their compilers, and it is necessary to carry out such studies to promote further progress in academic lexicography (Hartmann 2001: 39).
The nineteenth century witnessed the dramatic development of industrialization and globalization. The industrial revolution and technological development opened up increasing opportunities for the mobility of people and sped up communication, which brought about the burgeoning of dictionaries worldwide. Dictionaries in the nineteenth century bore features of the time: they promoted national identity; they reflected different views on language; they portrayed authorship differences and lexicographic innovations. Previous historical studies of dictionaries mainly focused on different versions of a dictionary or dictionaries in one country. A more recent exception is The Cambridge World History of Lexicography edited by John Considine (2019). The present book can be seen as an addition, exploring dictionaries in the nineteenth century worldwide and giving answers to the following four questions: Who were the nineteenth-century lexicographers? How did the world within which they lived foster their projects? What did language itself mean to them? What goals did they try to accomplish in their dictionaries? (p. xv). The book is divided into 16 chapters together with an introduction and an index. The articles are organized on the principle that the dictionary dealt with is from the general to the specific, and from the more familiar to the less familiar (p. xix). The dictionaries include famous ones such as Oxford English Dictionary (OED), Noah Webster's American Dictionary of the English Language, Vladimir Dahl's Explanatory Dictionary of the Living Great-Russian Language, etc., but also less known Chinese, French, Frisian, Japanese, Persian, Scottish and Yiddish dictionaries, and dictionaries of sign language.
In Chapter 1, John Considine provides a general background of nineteenth-century lexicography by pointing out the challenges needing to be addressed by the lexicographers. Despite the flourishing of lexicography in the eighteenth century, some problems remained unsettled. The expanding and speeding up of communication also brought up new questions concerning the structure and contents of the dictionary entry, the scope of the dictionary wordlist, and the type of information which dictionaries should offer. Considine points out that the questions must be considered 'in the context of the whole ecosystem of reference publishing' (p. 13).
In Chapter 2, Brian Kim traces the development of foreign language dictionaries and dictionaries of the native language in the nineteenth century in Russia and Japan with statistical evidence. The increasing tendency was the result of greater contact with Western Europe and the efforts to seek modernization while maintaining the national identity.
In Chapter 3, Michael Adams describes and evaluates Charles Richardson's New Dictionary of the English Language (1836-1837). As a mirror of the compiler's philosophy of language, NDEL is a valuable foil in the history of lexicography and is 'the pivot on which the scientific revolution of English lexicography turned' (p. 49).
In Chapter 4, Sarah Ogilvie explains why OED features prominently in modern lexicography. It was a collaborative work of both specialists and the general public. It applied historical principles systematically to the structure and content of the dictionary entry, adopted a descriptive rather than prescriptive approach, attempted a thorough coverage of the lexicon, and was received as a national project.
Chapter 5 deals with the Deutsches Wörterbuch (DWB), which is considered the starting point of scientific lexicography. The scientific feature was illustrated by the descriptive agenda, the description of word meaning, the collaborative network, data collection, etc. Volker Harm also shows that its scientific approach was still deeply rooted in Romanticism.
In Chapter 6, Anne Dykstra studies Joost Hiddes Halbertsma's unfinished dictionary of Frisian, the Lexicon Frisicum (1872). The dictionary reveals strong nationalistic tendencies of Romanticism. Dykstra analyzes it in terms of structure, source and material, metalanguage, meaning description, examples, etymology, and encyclopedic information, as well as the relationship between Frisian and English, and cultural nationalism. Although it lacks consistency and the use of Latin as the metalanguage restricted the target users to a limited group, it provides insights into nineteenth-century linguistics, lexicography and culture.
Chapter 7 focuses on John Jamieson's Etymological Dictionary of the Scottish Language (1808/1825), the first Scottish national dictionary. Having a reputation for its pioneering historical principles, the dictionary was of greater significance as a national and patriotic work, featuring widespread participation in the dictionary, coverage of cultural vocabulary, and presenting Scots as a distinct language. Though being criticized for excluding the lexis that Scots shared with English, it was regarded as a repository of national identity and cultural participation.
In Chapter 8, Wim Remysen and Nadine Vincent study Dunn's idea of a united and independent French Canada and the legitimacy of Canadian French. The topic is explored against the nineteenth-century sociopolitical context and the life experience of Dunn. They show that his vision was neatly reflected in the 1880 Glossaire franco-canadien, which figured prominently in the development of Quebec lexicography.
In Chapter 9, Edward Finegan studies the 1828 edition of Noah Webster's American Dictionary of the English Language. He shows that the dictionary is a manifestation of the lexicographer's nationalism and Christian commitments, through etymologies, definitions, and illustrative citations.
Chapter 10 explores Webster's unabridged dictionary of 1864. Peter Sokolow-ski focuses on the innovations of the revision work which set the course for the modernization of lexicography, featuring the organization of the editorial staff, the removal of Webster's etymologies, the historical ordering of the senses, the systematic pruning of the lexicon, the dual presentation of the engravings, the volunteer reading for citations, etc. The innovations, together with the keen business sense of the publisher, made the dictionary a great commercial success.
In Chapter 11, Ilya Vinitsky studies Vladimir Dahl's Explanatory Dictionary of the Living Great-Russian Language within the context of the Russian literature and culture and the religious and mystical doctrines of language. The dictionary reflected Dahl's view on language, that is, the word was a spiritual entity, a bridge between worlds, and a window onto the national soul. Viewing the Russian language as centered on the notion of family, he endeavored to reveal the communal spirit of Russia and create the national epic.
In Chapter 12, Marten Söderblom Saarela discusses Banihun and Pu-gong's Manchu-Chinese Literary Ocean (1821). The dictionary aimed at a greater integration of Manchu and Chinese and to serve the hybrid culture of lettered bannermen. He compares this dictionary with Callery's unfinished Chinese-French encyclopaedic dictionary, which was inspired by the same source dictionary, to show the importance of imperial Chinese lexicography. As the product of a specific historical period, the utility of the dictionary depended on the readers' proficiency in Manchu and their knowledge of the Confucian literary tradition.
In Chapter 13, Walter Hakala traces the century-long history of British lexicographic works on the Persian language, which concluded in 1892 with Francis Joseph Steingass's A Persian-English Dictionary. This chapter also documents the rise and fall of Persian as a transregional language. By the time Steingass produced his Comprehensive Persian-English Dictionary in 1892, the use of Persian in British India had been on the decline, which doomed the dictionary to failure.
Chapter 14 focuses on American missionary women lexicographers. Lindsay Rose Russell explores what made the missionary women lexicographers and what features their dictionaries contained. Compared with the large-scale dictionaries mentioned in the previous chapters, which aimed for national identities or featured refined lexicographic methods, the dictionaries made by the American missionary women are characterized as small-scale, pragmatic and appreciative of local languages and cultures.
In Chapter 15 Gabriella Safran discusses the historical confluence of Yiddish dictionaries and Jewish dialect comic books in the Russia Empire and the USA. Instead of assigning a social meaning to the dictionaries as seeking linguistic identity for a low-status and minority language, Safran focuses on the popularization of Yiddish dictionaries and Jewish comic books and proposes that their success may be attributed to their ability to meet people's needs to produce low-status and high-status languages and perform comedy to impress others. Both were products of specific social conditions.
Chapter 16 is devoted to sign language dictionaries, which contributed to the recognition of the identity of the deaf community and the dissemination of sign languages. Jorge Bidarra and Tania Aparecida Martins start with a brief overview of the development of Libras dictionaries in Brazil from the nineteenth century to the twentieth century, showing that the development of sign languages was affected by educational philosophy and government policies. The authors then introduce the ongoing monolingual dictionary, PORLIBRAS, a project they have been working on.
Having different dictionaries discussed in one volume makes it possible and easy for the readers to compare and contrast. As shown, the authors of Chapters 5-9 share an interest in exploring the lexicographic works from the perspectives of language, culture, and nationalism. It also reveals that dictionaries produced in similar circumstances could yield different results. Steingass's Comprehensive Persian-English Dictionary failed, because of the limitation of Persian as a written elite language. In contrast, the dictionaries made by the American missionary women in Asia were successful since they insisted on the importance of local language users. These two examples also prove that the success of a dictionary depends in part on whether it could meet the needs of the users in a specific period, which is reinforced by the examples in Chapters 12 and 15. In addition, the dictionaries are explored from different perspectives. Some are focused on lexicographic innovations, such as Chapters 4, 5 and 10. Some, for example Chapters 6, 7, 8 and 9, attach greater weight to the social or cultural value of the dictionaries. Furthermore, the articles are not isolated, but related and compared. The contributors focus on different dictionaries. When they are exploring the dictionaries, it is usual that they compare the dictionaries with others, which also draws the readers' attention to the differences and similarities.
However, the book is not without shortcomings. It is not made clear by which principle the dictionaries were selected for study. Nearly half of the volume is devoted to English or English-related dictionaries. It would have better shown the panorama if more dictionaries of other languages were incorporated.
By offering an overview of nineteenth-century dictionaries and exploring dictionaries from varied perspectives, anyone interested in the history of lexicography would find this book informative, readable, and well researched.
Dai Lingzhen
School of Foreign Studies
Minnan Normal University
Zhangzhou
P.R. China
References
Considine, J. 2019. The Cambridge World History of Lexicography. Cambridge: Cambridge University Press. [ Links ]
Hartmann, R.R.K. 2001. Teaching and Researching Lexicography. London: Longman. [ Links ]
^rND^1A01^nRufus H.^sGouws^rND^1A02^nD.J.^sPrinsloo^rND^1A01^nRufus H.^sGouws^rND^1A02^nD.J.^sPrinsloo^rND^1A01^nRufus H^sGouws^rND^1A02^nD. J^sPrinslooARTICLES
Lexicographic Data Boxes Part 3: Aspects of Data Boxes in Bilingual Dictionaries and a Perspective on Current and Future Data Boxes*
Leksikografiese datakassies. Deel 3. Aspekte van datakassies in tweetalige woordeboek en 'n perspektief op huidige en toekomstige data-kassies
Rufus H. GouwsI; D.J. PrinslooII
IDepartment of Afrikaans and Dutch, Stellenbosch University, Stellenbosch, South Africa (rhg@sun.ac.za)
IIDepartment of African Languages, University of Pretoria, Pretoria, South Africa (danie.prinsloo@up.ac.za)
ABSTRACT
This article, the third in a series of three on lexicographic data boxes, firstly focuses on a number of aspects of data boxes in bilingual dictionaries with the emphasis on different approaches in bilingual dictionaries with an African language as one of the members of the treated language pair. It is not possible to provide a comprehensive discussion within the limitations of an article. Then the discussion proceeds by looking at some new ways of using data boxes in online dictionaries. It is shown that the possibilities of the new medium allow lexicographers to employ data boxes in both traditional and non-traditional ways. It is argued that data boxes are expected to fulfil a variety of purposes ranging from navigational information and the provision of salient information to giving access to relevant data in dictionary-internal and dictionary-external sources. Lexicographers of online dictionaries have introduced new ways of using data boxes that have not yet been fully discussed in metalexicographic literature. This article gives an identification and a brief discussion of some of these innovative uses of data boxes. It stresses the potential that the online environment offers lexicography. Practical and theoretical lexicographers need to be aware of these possibilities and challenges. By embarking on a more comprehensive use of data boxes dictionaries can become even better containers of knowledge and can serve their users in an optimal way.
Keywords: Dictionaries, Data Boxes, Pop-up Boxes, Hyperlinking, African Languages, Sepedi, Isizulu, Search Domain, Search Universe, Data Distribution
OPSOMMING
Hierdie artikel, die derde in 'n reeks van drie oor leksikografiese datakassies, fokus eerstens op aspekte van datakassies in tweetalige woordeboeke met die klem op verskillende benaderings in tweetalige woordeboeke met 'n Afrikataal as een van die lede van die behandelde taalpaar. Daarna gaan die bespreking voort deur te kyk na 'n paar nuwe maniere om datakassies in aanlyn woordeboeke te gebruik. Daar word aangetoon dat die moontlikhede wat die nuwe medium bied, leksikograwe in staat stel om datakassies op sowel tradisionele as nie-tradisionele maniere te gebruik. Daar word aangevoer dat die datakassies gebruik kan word om 'n verskeidenheid doel-eindes te bereik, wat wissel van navigasie-inligting en die verskaffing van belangrike inligting tot toegang tot relevante data in woordeboek-interne en woordeboek-eksterne bronne. Leksikograwe van aanlyn woordeboeke het nuwe maniere bekendgestel om datakassies te gebruik wat nog nie volledig in die metaleksikografiese literatuur bespreek is nie. Hierdie artikel gee 'n identifisering en 'n kort bespreking van sommige van hierdie innoverende gebruike van datakassies. Dit beklem-toon die potensiaal wat die aanlynomgewing aan die leksikografie bied. Leksikograwe moet bewus wees van hierdie moontlikhede en uitdagings. Deur met 'n meer omvattende gebruik van datakas-sies te begin, kan woordeboeke selfs beter kennishouers word en hul gebruikers op 'n optimale manier dien.
Sleutelwoorde: Woordeboeke, Datakassies, Opspringkassies, Hiperskakels, Afrikatale, Sepedi, Isizulu, Soekdomein, Soekuniversum, Dataverspreiding
1. Introduction
The fact that data boxes are not used at all in many dictionaries and that they are often almost randomly used merely to bring together or highlight information could create the impression that data boxes have an insignificant role to play in dictionaries and should therefore only belong to the periphery of metalexicographic discussions. In this article we wish to argue to the contrary, i.e. that data boxes are important and even essential but underutilized lexicographic components which should be used to fulfil specific needs. The user should be guided with regard to salient information which cannot typically be catered for by standard dictionary conventions and items such as those giving a paraphrase of meaning, translation equivalents and examples of use. We wish to make it clear that treatment in data boxes is not in competition with the default treatment in the article of a specific lemma. They supplement each other, default treatment is the first objective then consideration of a data box if the compiler deems it necessary to give further guidance on salient information. In Part 1 Gouws and Prinsloo (2021) and Part 2 Prinsloo and Gouws (2021) (this volume), lexicographic data boxes as text constituents in dictionaries and types and contents of data boxes were discussed with the purpose of setting the scene for the discussion of the future of data boxes and data boxes of the future in this article.
Moreover, as seen in section 3, data boxes did not lose their relevance in the transition from paper to electronic dictionaries but electronic dictionaries often employ alternative strategies for the presentation of data boxes enabled by the digital era.
Dictionaries have a genuine purpose, cf. Wiegand (1998: 299). This also applies to the different components of dictionaries, including the data boxes. Data boxes of the future should focus on what we believe is the genuine purpose, cf. Wiegand (1998: 299), of data boxes, i.e. guidance on salient data not sufficiently emphasised in the default lexicographic presentation. These include for example the contrasting of different words, aspects of the range of application, antiquation, taboos etc. However, the possibilities offered by the online environment and the innovative and dynamic options regarding the structure of dictionary articles should lead lexicographers to use data boxes in ways that include but also go beyond the mere representation of salient data. Where the first part of this article focuses on various aspects of data boxes presenting salient data, the second section moves towards new uses of data boxes. In the first section the discussion will be directed at some issues in bilingual dictionaries in which an African language is a member of the treated language pair. The second section will primarily be directed at online dictionaries in general but will also be relevant to future African language dictionaries.
2. Data boxes in bilingual dictionaries - African languages as a case in point
2.1 Different approaches to data boxes
Dictionaries for the African languages could firstly cater for the inclusion of data boxes dealing with issues not restricted to the given language pair. Secondly, they could include data boxes specific to the language family they belong to and finally data boxes dealing with unique features of individual members of the language family. With regard to these three issues data boxes can play a significant role in making the user aware of salient data. What is presented in this paragraph is a selection of a number of lemmas which should be considered for the provision of data boxes in addition to the standard treatment given in the dictionary article. The selected issues pertain to different aspects of morphology, syntax and semantics such as (a) demonstratives, (b) multiple recurring phrases as translation equivalents, (c) reference to men and women versus addressing them, (d) different constructions used for English adjectives and (e) equivalent relations. It is, however, not possible to present a comprehensive or systematic account of the full scope of required data boxes within the limitations of an article.
The African language Sepedi (a Sotho language) will be taken as example language in the following discussion with occasional reference to isiZulu (a Nguni language) both belonging to the Bantu1 Language Family. To the knowledge of the authors the only Sepedi and isiZulu dictionaries using data boxes are the Oxford school dictionaries for Sepedi and isiZulu (henceforth ONSD and OZSD respectively).
As far as the first category is concerned it can simply be stated that data boxes for African languages should give guidance on issues applicable to all languages such as contrasting related words, range of application, cultural considerations, etc. Secondly, attention should be given to typical characteristics of the language family such as verbal moods, nominal classes, kinship terminology, etc. Finally, data boxes should be included guiding the user on issues characteristic of the specific African language such as guidance on pronunciation, syntax, semantics, word division, etc. These issues are discussed in detail in Part 1 Gouws and Prinsloo (2021) and Part 2 Prinsloo and Gouws (2021). Consider figure 1 as an example dealing with contrast and range of application.
The data box at Sepedi contrasts the names Sepedi versus Northern Sotho and informs the user that these terms refer to the same language. There is much controversy around the use of these names and what the relation or difference between these terms is, therefore guidance is required. The data box at umzala gives a precise indication of the range of application i.e. that it can be used to refer to cousins but not to the children of one's father's brother. A complicated system of kinship terminology exists for African languages, cf. Van Wyk and Haasbroek (1990) for Setswana and Prinsloo and Van Wyk (1992) for Sepedi. Data boxes can provide valuable guidance on kinship, e.g. on the range of application as in the case of umzala in figure 1 and contrasting kinship relations, e.g. relatives on father's versus mother's side, whether you address a specific relative versus speak about them. The shortage of space will always be a consideration in paper dictionaries and it is for the lexicographer to prioritise the type of information to be provided, e.g. treatment in the article by means of translation equivalents or providing a data box or both. So, for example, the compiler of OZSD and ONSD has valued the importance of text boxes at demonstratives as so important that he dedicated 40% of the page in figure 5 to text boxes.
As far as the second category is concerned, figure 2 illustrates a typical category which Sepedi and isiZulu (and probably all other members of the language family) have in common, i.e. guidance on grammatical data like nominal classes and their concords or that the English articles a, an and the are not translated/do not have equivalents.
As far as data boxes dealing with unique features of Sepedi and isiZulu are concerned, much guidance is required in respect of what Prinsloo (2017 and 2020) call complicated grammatical structures. Consider figures 3 and 4 as examples of unique features of prefixing and composition of specific words in Sepedi and isiZulu.


In the treatment of ngale in figure 3 a cross-reference to the locative adverb le2is given. The data box, however, refers to the demonstrative pronoun le1which is lemmatised and treated in its appropriate alphabetical position in OZSD.
For most African languages strong normative guidance is required since standardization is still in progress, cf. Gallardo (1980: 62). Such boxes could well be high on the list of typical data box content for these languages and OZSD and ONSD have done well in the provision of valuable information for the users in data boxes. Consider the following six examples of data boxes for Sepedi dictionaries which could substantially enhance their value in respect of user guidance suggested as model entries for future Sepedi dictionaries.
2.2 Demonstratives
Demonstratives basically express this or these in relation to three relative distances within sight of the speaker, e.g. monna yo 'this man', monna yoo 'that man' and monna yola 'that man over there, yonder'. Linguists such as Louwrens (1991), Van Wyk et al. (1992), Lombard (1985) and Poulos and Louwrens (1994) distinguish three basic positions but differ in respect of the sub-positions into which demonstratives can be classified. Louwrens (1991) distinguishes between the different positions as follows:
Position 1(A) Speaker and the addressee are close to one another, while the object referred to is relatively near them
Position 1(B) Speaker and the addressee are at a distance from each other, while the object referred to is directly next to the speaker
Position 2(A) Speaker and the addressee are relatively far apart, while the object referred to is nearer to the addressee
Position 2(B) Refer to objects which are very close or directly next to the addressee
Position 3 Speaker and the addressee are very close to one another, while the object referred to is far away from them
Louwrens (1991: 106-108)
Consider table 1 as an extract from the table given in ONSD.
Two issues pertaining to demonstratives are relevant to the user i.e. firstly a complete table indicating all the demonstratives of the different positions and classes and their basic meanings, i.e. indicating three distances, 'here', 'there' and 'there (yonder). Secondly indication of the exact semantic relations in respect of speaker and addressee is required. The lexicographer could, for example, give the full table, e.g. as in table 1 and the basic translations as the reference address e.g. in the back matter of a paper dictionary or as a clickable pop-up window in an electronic dictionary - see the next section. The purpose is a complete illustration of the different classes and positions of demonstratives and their meanings and translation equivalents. The meanings of the different positions as described by Louwrens (1991: 106-108) above could be presented as pop-up boxes for each demonstrative or as data boxes in the central text of a paper dictionary as has successfully been done in ONSD as in figure 5.
In figure 5 the compiler regarded the salient information given by data boxes for demonstratives as so important that they are provided for each demonstrative and not only as a separate section in e.g. the back matter of the dictionary. Such a decision remains the prerogative of the compiler in consideration of the skills level of the target user.
2.3 Multiple recurring phrases as translation equivalents
These are cases where an English word can be translated by means of a grammatical pattern determined by the different noun classes, - every as a typical case in figure 6.

The duplication of the adjective construction, as in figure 6, i.e. Class 5 le lengwe le le lengwe (le lengwe: a certain/other (day) + le: and + le lengwe: another one) reflects a single instance of the recurring pattern for all other classes. This example is fine but it is important to inform the user by means of a data box that this can be done for all classes keeping in mind that the concords used have to match the nominal class to which the noun belongs. A data box as in figure 7 which gives examples from more noun classes is recommended at the article for every. Such a box should preferably have a cross-reference to the back matter where a full table with a description of the strategy, i.e. that the concept 'every' is expressed by means of the duplication of 'another' (e.g. monna yo mongwe 'another/certain man' le 'and' yo mongwe 'another one') is given.
Prinsloo and Gouws (2006) describe this type of repetition of a phrase across the different classes as in figure 7 as grammatical divergence and all such occurences belonging to different classes, e.g. this man/finger/axe, etc. or he/she/ him/her, etc. could be treated in data boxes with great success.
2.4 Reference to men and women versus addressing them
Groot Noord-Sotho-woordeboek (GNSW) gives the following translation equivalent paradigm for mohumagadi: "queen, king's wife, chief's wife, chieftainess, lady, Mrs [a term of courtesy applied to any married woman]", mohumagatsana: "miss, queen (of cards)" and for mosadi: "woman, married woman, wife". Although all three words refer to a woman/adult female person, the user should be warned that it is inappropriate to address a woman as mosadi. The same holds true for a man/adult male person monna 'a man' versus morena 'Mr.' Consider the suggested data boxes for women and men in figure 8. This is pragmatic data, a function of data boxes. It is for the lexicographer to decide whether it should be emphasized by inclusion in a data box.
The data box in figure 8 or the applicable sections thereof could be given at the articles of man and woman.
2.5 Hair
Compilers of Sepedi dictionaries should give clear guidance on the correct meanings and use of Sepedi words dealing with different kinds of hair. ONSD lemmatised hair and gives a translation equivalent moriri. This is the singular form, i.e. a/one hair. It would be better to give meriri 'hair (plural)' as translation equivalent since in most cases reference to the plural is made. No data box is suggested here, only different treatment of the lemma.
No mention is made of, e.g. the hair of an animal or guidance that hair is normally used in the plural form in Sepedi, i.e., meriri. GNSW gives the following translation paradigm for boya: "hair of an animal, wool, hair of human body (but not of head)" and translates meriri as human hair and mariri as mane (of a lion). ONSD translates boya as wool, animal hair, fur and mariri as mane and adding "of a lion" in brackets. Meriri is lemmatised but not treated and cross-referred to the singular moriri which is simply translated as hair - it should have been translated as human hair. Stronger guidance is required in respect of hair, animal hair, mane, boya and mariri in order to prevent the user from, e.g. incorrectly using meriri to refer to wool or animal hair or boya to refer to hair on the head of a person A data box contrasting boya, meriri and mariri as in figure 9 is recommended at the article of hair.

2.6 Different constructions used for English adjectives
A number of English adjectives such as last, own, naughty, etc. are not expressed as adjectives in Sepedi but through different constructions. So, for example, is there no single-word adjective for naughty in Sepedi - it is expressed by either a full sentence in the relative mood or by means of a possessive construction as in example (1).
(1)
a. Verbal relative
Mošemane yo a selekago (mošemane noun class 1 'a boy' + yo demonstrative class 1 + a subject concord class 1 + seleka verb stem 'be naughty' + go relative suffix) 'A naughty boy'
b. Possessive construction
Mošemane wa go seleka (mošemane noun class 1 'a boy'+ wa possessive concord class 1 + go infinitive class prefix class 15 + seleka verb stem 'be naughty' 'A naughty boy'
A data box, e.g. as in figure 10 presented at the article of naughty will provide the required guidance to the user provided that the target users should have basic grammatical knowledge of Sepedi. If not, grammatical terms such as verbal relative and possessive construction should be briefly described in terms of their meaning, i.e. "who is doing something, something of something else respectively". Both options can even be given with the semantic one in brackets, i.e. Verbal relative (who is doing something) and Possessive construction (something of something else).

2.7 Equivalent relations
As a final example consider instances of semantic divergence where a polyse-mous source language word has more than one translation equivalent (Gouws and Prinsloo 2005). A single Sepedi word bala has different translation equivalents, namely read, count and study. Sepedi has two homonyms -tala. The one member of the homonym pair has old as its translation equivalent whereas the second homonym has both green and blue as equivalents. ONSD translates the homonyms -tala correctly as respectively old and green, blue. The user will be well-guided if alerted by means of a data box such as figure 11 because being able to distinguish between green and blue could be vital in text production situations. A typical situation could be where it is crucial to distinguish between different specific functions performed by e.g. green versus blue buttons on a control panel.

The Sesotho sa Leboa / English Pukuntsu Dictionary (SEPD) could mislead the user because only blue is given as translation equivalent for -tala. The proposed data box in figure 11 could be placed at the article of -tala in the Sepedi to English side as well as at the articles for blue and green in the English to Sepedi side of the dictionary to warn the user that additional clarification might be required in text production situations. It is for the compiler to decide whether sufficient guidance in respect of -tala translated as green or blue was given in the default treatment of the lemma or whether a data box is desired to focus the attention of the user on the different senses. So, for example, the compiler of SEPD will be well-advised to firstly give green also as translation equivalent for -tala, illustrated by typical examples for each equivalent and further supported by a data box.
The same holds true for a data box such as figure 12 for -bala where the lemma -bala has read, count and study as translation equivalents. Although examples will help the user, real success in the treatment of -tala and -bala would at best be achieved by means of a data box that displays these salient semantic issues.

In contrast to one Sepedi word having more than one English equivalent as in figures 11 and 12, a single English word can also have more than one Sepedi equivalent. Sepedi has two words for ask, i.e. botsisa 'ask, e.g. a question' and kgopela 'ask for something'. Consider figure 13 as a data box giving the required guidance on the range of application for botsisa and kgopela. Such a data box is especially required in the English to Sepedi side of dictionaries such as SEPD where ask is simply translated as botsisa, kgopela without any indication of the range of application.

Data boxes are also required at the articles of wear, e.g. apara /apere 'wear clothes' versus rwala 'wear a hat' and the many Sepedi equivalents for close, e.g. tswalela 'close a gate/door' versus khurumetsa 'close a container, e.g. the lid of a bottle' versus khupetsa 'conceal' versus moma 'close(d) mouth', etc.
All these data boxes convey salient information which should be presented to users in a way that draws their attention. The use of data boxes is an ideal presentation method to enable such a transfer of information.
3. Salient data and more than salient data
Data boxes can be regarded as important and even essential but often under utilized dictionary components which should be used to fulfil a specific need, i.e. typically guiding the user towards carriers of salient data. From the preceding sections it should be clear that data boxes can contribute in a systematic way to assist in the presentation of data that cannot be sufficiently accommodated in the default search positions of dictionary articles or article stretches. The system prevailing in the decision to use data boxes is based on the salience of the specific data. The lexicographic method of using data boxes should not be performed in a haphazard way or as a form of lexicographic face-lifting, cf. Wiegand and Gouws (2011: 238). Lexicographers should have a clear understanding of the reasons why these boxes are used. The presentation of salient lexicographic data can be regarded as one of the major motivations for the use of data boxes in printed dictionaries. Irrespective of what happens in the development of online dictionaries printed dictionaries should preferably continue to use data boxes and even to increase their use. Innovative strategies could complement the traditional way of using these dictionary components. Printed dictionaries of the future could employ data boxes in various ways to respond to new lexicographic challenges.
Data boxes also have an important role to play in online dictionaries. The examples and discussion of data boxes in the following sections of this article should not be regarded as of a language-specific nature but rather relevant to all languages, including the African languages.
Online dictionaries, especially those that were originally planned and published as printed dictionaries, often use data boxes in the same way as found in printed dictionaries. Figure 14 shows the use of a data box as found in the article of the lemma sign underground in the OALD to present a usage note: (a comparable usage note is also presented in the articles of the lemmata metro, subway and tube):
In addition, online dictionaries also display new ways of utilising data boxes. This was already alluded to in Prinsloo and Gouws (2021). This can be seen in figure 15 where the Merriam-Webster uses data boxes for navigation in the article of the lemma sign dull:
A click on these navigation boxes guides the user to the relevant addresses as seen in figure 16, the address of the link to Synonyms & Antonyms:
The boxes shown in figure 15 do not only have a navigational purpose. They give users the opportunity to unlock textual venues that accommodate additional lexicographic data, as seen in figure 16.
4. Innovative uses of data boxes in online dictionaries
The transition from printed to online dictionaries can rightly be regarded as extremely important with radical and far-reaching consequences. This can be seen in many aspects of online dictionaries, for example, as indicated by Heu-berger (2020: 404), with regard to accessibility of data, multimedia functions, customization, hybridization, user input and storage space. The transition to online lexicography has also had a huge impact on research in the field of metalexicography. Theories of lexicography were primarily developed for the printed environment. The online environment demands a re-assessment of all aspects of these theories, including the various dictionary structures. Some structures of printed dictionaries, for example the article structure, will also prevail in online dictionaries although certain adaptations are needed; some structures, for example the frame structure, are not maintained in online dictionaries. In addition, online dictionaries can also display structures that do not occur in printed dictionaries. An example of such a structure is the screenshot structure, cf. Gouws (2014: 165). When using an online dictionary the user is confronted by various screenshots that are populated by dictionary articles and partial articles. These screenshots display innovative uses of data boxes. With regard to the use of data boxes online dictionaries show that the lexicographic practice has embarked on procedures not yet adequately described or discussed in metalexicographic publications. In the subsequent sections of this article a few occurrences of data boxes in online dictionaries will be identified and briefly discussed in order to show the need for a comprehensive look at data boxes of the future.
4.1 Highlighting data types
Online dictionaries often have dynamic article structures and even multi-layered dynamic article structures (Gouws 2014: 165). The internal access structures provide the user with access routes to the required data in its specific search zone and article layer. This is seen in elexiko where the opening screenshot of an article contains data indicators that help the user to move to a next layer of the article and then perhaps to a further layer. When reaching a specific search zone the data indicator as well as the search zone is boxed by means of a thin frame. This frame helps the user to identify the boxed items as a destination of the search route. The following screenshots show this process. Figure 17 is the opening screenshot of the article of the lemma Arm (arm) in elexiko:
A user looking for grammatical data regarding the sense of this word referring to a body part finds the data indicator Körperteil (Body part) and clicks on the entry weiter (=further) next to it. This click moves the user to the partial article presented in figure 18:
This screenshot shows the paraphrase of meaning of the specific sense of Arm with a thin line putting the paraphrase of meaning, its appropriate data indicator (Bedeutungserklärung) (=explanation of meaning) as well as links to example sentences (Belege) and illustrations (Illustrationen) in a data box. To the right of the data indicator bar the user can find the indicator Grammatik (=Grammar) and a click on that indicator opens the next layer, as seen in figure 19:
This screenshot shows the grammatical data along with the relevant data indicator appearing in a thinly framed data box.
Both figure 18 and figure 19 display data that are part of the default treatment of nouns in this dictionary. The data box is not used to distinguish salient from less salient data with regard to the presentation in the article as a whole but it does highlight the data salient for the specific consultation - the destination unlocked by the preceding click of a data indicator. This use of data boxes is done in a consistent and systematic way in elexiko. It highlights the identification of specific items and enhances the retrieval of the required information. In addition, the type of data box in figure 18 and figure 19 also contributes to improve the layout of the screenshot. This approach is made possible by the dynamic nature of articles in online dictionaries and is in sharp contrast to the limitations due to the static nature of articles in printed dictionaries.
This use of data boxes can also be seen in the following partial article of the lemma sign koekje (figure 20) in the Dutch dictionary ANW (Algemeen Neder-lands Woordenboek). Having navigated from the opening screenshot of the article to the screenshot presenting the partial article in which the sense of koekje "small cake" is treated, the user finds a typical partial article layout with three sections presented in columnlike way.
The right-hand section contains a data box, unfortunately not as clearly visible in the figure, that accommodates items giving part of speech, spelling and inflection, word relations and pronunciation. In all articles of this dictionary items giving these data types are presented in a data box, situated in the same position in the screenshot. A similar data box is also seen in figures 21 and 22, giving screenshots with partial articles for two senses of the lemma sign representing the word muis (mouse):
In figures 20-22 data boxes continue their assignment as containers of lexicographic data but they play an additional role, namely to improve the article layout and make data easier accessible to the users due to a conspicuous way of presentation. This is a function of data boxes that still needs further exploration. It demands dedicated future work which falls beyond the scope of this article.
4.2 Adding data
4.2.1 Lexicographic data
In online dictionaries data boxes are also used to highlight the access to additional dictionary-internal data that the lexicographer regards as relevant to the word treated in the specific article. Some articles in Merriam-Webster have a section "From the editors of Merriam-Webster." Below this heading a data box is given in which different types of data can be found. The data are usually of a lexicographic nature and help to fulfil a cognitive function. The data could be a reference to other articles in the dictionary that contain words in the same semantic field as the lemma or it can focus on a discussion of certain related aspect. In figure 23, a screenshot of a partial article of the lemma bicycle, shows this data box with its data indicator "10 words every true cyclist will know." A click on this data indicator in the box guides the user to a list of ten articles. This list includes articles with lemmata like penny-farthing, peloton, velocipede and tandem bicycle.
In this list the article of the lemma velocipede has an extensive treatment - with the paraphrase of meaning comparable to that given in the article of the lemma velocipede, as seen in figure 24:

The treatment of velocipede in the article list is as seen in figure 25:

This use of data boxes like that in the article of the lemma bicycle shows a significant change in the way in which lexicographers employ this article component - data boxes present a departure slot from where the user can depart to article-external but dictionary-internal data venues. By including these isolated thematically-bound article stretches the lexicographer increases the extent of the dictionary as a search region and the relevant data boxes ensure access to these new venues in the search region.
4.2.2 Non-lexicographic data
Online dictionaries contain typical lexicographic data. Data boxes participate in accommodating the lexicographic data. However, the online environment opens possibilities for dictionaries to become containers of more than just traditional lexicographic data. As components of dictionary articles data boxes in online dictionaries can contain data that even go beyond a display of lexicographic data relevant to the treatment of the word represented by the lemma sign of the specific article. The data distribution structure of these dictionaries can also make provision for the satisfaction of more general cognitive needs. Irrespective of the lemma functioning as guiding element of an article the articles in lexico.com contain a data box in which the "word of the day" is given and another box displaying the most recent "word of the year". This is seen in figure 26 with the word of the day in an orange coloured box and the word of the year in a green coloured box:
Because these boxes are presented in every article, knowledgeable users of this dictionary will know that they can retrieve this information from the dictionary and know where to find it. For a user consulting the dictionary for the first time or consulting it to find other data in a dictionary article these data boxes offer a data bonus and additional consultation success.
Lexicographers of online dictionaries also use the lesser space restrictions to include data boxes with non-lexicographic data that could be seen as a type of lexicotainment, where lexicotainment could refer to the presentation of data that do not contribute to achieving the genuine purpose of the dictionary, but enable the retrieval of information that might not be lexicographically relevant but may enrich the consultation procedure. Schierholz (2015: 340) also refers to "reading dictionaries for entertainment or to kill time (which is called 'lexico-tainment'". The following screenshot of a partial article of the lemma bench in lexico.com shows a data box that contains a brief quiz of which the topic is not related to the lemma of the article accommodating this data box. On any given day this quiz will not be the same in all articles. However, the subsequent data box with "trending words" is the same in all articles. The data in this latter data box are not actually a form of lexicotainment because this box given in figure 27 rather adds to the fulfilment of a cognitive function of the dictionary and therefore this data fall within the scope of the genuine purpose of the dictionary.
Lexicographers can also employ data boxes to respond to questions from their dictionary users. Articles in the Merriam-Webster dictionary contain a data box "Ask the editors". This data box given in figure 28 contains separate boxes with the response of the lexicographer to questions put by the users:
This data box is used to introduce an innovative communication opportunity between dictionary maker and dictionary user. This use of data boxes and the further possibilities that could arise demand more comprehensive attention from the field of metalexicography.
4.3 Information and reference tools
As utility tools dictionaries, whether in printed or online format, are carriers of data from which users can retrieve information. Online dictionaries are no longer only regarded as isolated tools but they are part of a larger family of reference tools. Besides presenting lexicographic data to their users online dictionaries often also guide the users to dictionary-external sources - either in the same search domain, a dictionary portal, or in the search universe where other lexicographic and non-lexicographic sources can be targeted. Although the mediostructure of printed dictionaries also makes provision for cross-reference positions accommodated by cross-reference items with a dictionary-external address these cross-references typically are embedded within the dictionary article - either within a search zone complementing another item or in a search zone dedicated to dictionary-external cross-references, as seen in figure 29, the article of the lemma Benutzungsgrund in the Wörterbuch zur Lexikographie und Wörterbuchforschung / Dictionary of Lexicography and Dictionary Research (WLWF: Wiegand et al. 2010)

In this article the typographical structural indicator  identifies the search zone populated by items giving dictionary-external cross-reference addresses, as seen in figure 30:
identifies the search zone populated by items giving dictionary-external cross-reference addresses, as seen in figure 30:
Online dictionaries can cross-refer users in a much better way to a specific reference address, for example by including a link with an unambiguous data marker, as seen in figure 15. It can also be done by directing users to sources in either the same search domain or in the search universe (Gouws 2021: 15; 2021a). Unlike presenting these sources as items in a search zone populating the obligatory microstructure of the dictionary, as seen in figure 29, the lexicographer can use a data box that contains, among others, a reference to different sources from which the user can retrieve additional information. This is seen in figure 31, the article of the lemma sign Zug in dict.cc where a click on the information icon in the left and the right margins of the article activates a pop-up data box, seen in figure 31 in the bottom right-hand corner of the article.
The lower section of this data box is used to convey another type of salient data, namely the titles of dictionary-external sources. A click on any of these sources guides the user to the treatment of the item of which the information icon was clicked in the source given in the data box. Here the data box assists the user in a way not typically found in printed dictionaries.
This is another innovative use of data boxes. The dictionary introduces an occurrence of this type of text constituent that gives access to data relevant to the lemma and it also gives access to other sources where additional relevant information could be retrieved.
5. The future
Data boxes have made a significant contribution in ensuring a more comprehensive and diverse transfer of lexicographic data. Lexicographers of both printed and online dictionaries have been innovative in introducing different ways of best employing data boxes. Certain procedures, for example the procedure of boxing salient data, became established in printed dictionaries. This tradition has been continued in some online dictionaries. The reality of lesser space restrictions but also dynamic article structures, new layout possibilities and easier linking of items in a dictionary article to either dictionary-internal or dictionary-external addresses have resulted in new ways of using data boxes in online dictionaries. Many of these ways have not been sufficiently discussed in metalexicographic literature and this paper emphasises the need for such a discussion. Not only lexicographic data but also relevant non-lexicographic data can be accommodated in data boxes. This offers numerous opportunities to lexicographers when devising the data distribution structures of their dictionaries. Much more attention can now be given to the possibility of a stronger focus on the cognitive function of dictionaries.
Electronic dictionaries of the future are expected to continue the tradition of the paper and current electronic dictionary to present data as part of the treatment of the lemma. So, for example in figure 14 the data box is presented directly following the treatment of the second sense in the article of underground. In this way the users have no option whether they want to see the data box or not. Presentation of databoxes in this way can add to information overload and increase text density. Hyperlinking could be a better or alternative approach to the presentation of data boxes in future electronic dictionaries. Electronic dictionaries employ hyperlinking and pop-up boxes to such an extent that almost every item in a dictionary article is hyperlinked to a pop-up box. Such pop-up boxes provide the user with information on various issues ranging from convention explanation, phonetic and grammatical information and translation equivalents or individual words used in paraphrase of meaning; thus, a complicated cross-referencing system. This system is designed on the basis of two approaches namely hovering and clicking. In the case of hovering no deliberate action from the user is required but an opportunity is offered to them to obtain more information through a deliberate clicking action. Consider an inventory of pop-up boxes obtained through hovering and clicking for mosadi compiled by Prinsloo and Van Graan (2021: 54) in figure 32.
The first 20 pop-up boxes deal with a variety of issues such as frequency indication, pronunciation, grammatical guidance, additional examples, complete articles of words used in the translation equivalent paradigm, etc. The final two pop-up boxes are data boxes offering salient information pertaining to the range of application of mosadi. A hierarchy exists between these two data boxes. Through hovering over the warning/attention note as is the case in the top left box on frequency, the user is informed about a box that can be obtained through clicking. Two considerations are at stake here. Firstly, the issue of information overload and secondly, a hierarchical drill-down strategy. Prinsloo and Bothma (2020: 87) say in this regard:
A user does not need such an information overload to solve a very specific information need in a given situation - the user typically prefers to be provided with exactly the required amount of information to solve his/her information need in the given situation. In an e-environment, this information overload can easily be circumvented by initially providing only basic information that builds upon existing knowledge, but then providing, through drill-down options on demand, either more basic or more in-depth information about the problem at hand.
Drill-down actions through clicking in figure 32 lead to another (deeper) level of information. In the case of frequency indication the drill-down action renders a pop-up box with detailed information on the star rated convention used for frequency indication in the dictionary. In the Macmillan Dictionary (MED) such drill-down actions result in the provision of a wealth of information for the user. Hovering over the frequency star convention in any dictionary article guides the way to several levels of drill-down options. The first level is detailed information "RED WORDS AND STARS". Second levels obtained through further clicking are clicking on a video entitled "Smart learning with Red Words and Stars" and a clicking option to download a "Red Words & Stars pack". The same holds true for the data box "Range of application of mosadi" in figure 32 where the drilling-down action results in data boxes such as the one designed for mosadi in figure 8 above.
One of the exciting possibilities in online lexicography is the use of data pulling procedures (Gouws 2018; 2021). The successful employment of data pulling procedures can be enhanced by a clear indication of the information retrieval structure of the specific dictionary. In this regard it is important that users need be made aware of the dictionary-external sources functioning in the relevant search domain as well as the search universe. Data boxes can make a huge contribution in presenting a position in a dictionary article where the menu of dictionary-external sources can be given - as seen in figure 31.
In further metalexicographic research into data distribution options in dictionaries as well as into the enhanced use of data pulling procedures an increased use of data boxes should be negotiated. This is a dictionary component that could continue to play a significant role in future dictionaries.
6. Conclusion
This article as well as the preceding two articles in this trio have focused on a variety of aspects related to data boxes in printed and online dictionaries. The first article (Gouws and Prinsloo 2021) gave a metalexicographic perspective with a focus primarily on the occurrence of lexicographic data boxes as text constituents in dictionaries. In the second article (Prinsloo and Gouws 2021) the types and contents of data boxes were discussed. This third contribution put the emphasis on data boxes in bilingual dictionaries with an African language as one of the treated languages. It also looked at new ways in which existing online dictionaries have used data boxes.
The current use of data boxes in both printed and online dictionaries can form an important point of departure for the future use of this type of text constituents. Accommodating salient data should remain a significant assignment to data boxes. In addition, the use of data boxes to ensure an improved article layout and data distribution gives future lexicographers numerous options to enhance the quality of their dictionaries. As dynamic utility tools dictionaries can also use data boxes as text constituents that form a bridge between dictionary-internal and dictionary-external consultation procedures.
Data boxes have played a significant role in the lexicographic practice. This role should be maintained and increased in future dictionaries. Better collaboration between metalexicographers and practical lexicographers can ensure an exciting use of data boxes when fully exploiting the potential of the online environment.
Acknowledgement
This research is supported in part by the South African Centre for Digital Language Resources (SADiLaR). Findings and conclusions are those of the authors.
Endnote
1 . The term 'Bantu' got stigmatized during the Apartheid Era in South Africa. Therefore, the term 'African' is preferred in South Africa even in reference to what is internationally referred to as 'Bantu languages'. The discussion in this article is, however, focused on the Bantu language family and most of the issues described cannot necessarily be generalized to be applicable to other languages on the continent of Africa. To respect the view of those opposed to the term 'Bantu', it will only be used in cases where a distinction between African languages (languages spoken in Africa) versus a member of the Bantu language family is essential.
References Dictionaries
ANW. Algemeen Nederlands Woordenboek. Available at http://anw.inl.nl/. (Date of access: June 2021.)
dict.cc. Online-Wörterbuch Englisch-Deutsch/Deutsch-Englisch. Available at https://www.dict.cc/. (Date of access: June 2021.)
elexiko. Online-Wörterbuch zur deutschen Gegenwartssprache. Available at https://www.owid.de/docs/elex/start.jsp. (Date of access: June 2021.)
GNSW = Ziervogel, D. and P.C. Mokgokong. 1975. Groot Noord-Sotho-woordeboek / Comprehensive Northern Sotho Dictionary /Pukuntsu ya Sesotho sa Leboa. Pretoria: J.L. van Schaik. [ Links ]
lexico.com. Oxford English and Spanish Dictionary, Thesaurus, and Spanish to English Translator. https://www.lexico.com/.
MED = Macmillan Dictionary. Available at https://www.macmillandictionary.com/. (Date of access: August 2021.)
Merriam-Webster. Available at https://www.merriam-webster.com/dictionary/. (Date of access: June 2021.)
OALD = Oxford Advanced Learner's Dictionary. Available at http://oald8.oxfordlearnersdictionaries.com/dictionary/underground_3. (Date of access: June 2021.)
ONSD = De Schryver, G.-M. (Ed.). 2007 Oxford Bilingual School Dictionary: Northern Sotho and English / Pukuntsu ya Polelopedi ya Sekolo: Sesotho sa Leboa le Seisimane. E gatisitswe ke Oxford. Cape Town: Oxford University Press Southern Africa. [ Links ]
OZSD = De Schryver, G.-M. (Ed.). 2010. Oxford Bilingual School Dictionary: Zulu and English /Isichazamazwi Sesikole Esinezilimi Ezimbili: IsiZulu NesiNgisi, Esishicilelwe abakwa-Oxford. Cape Town: Oxford University Press Southern Africa. [ Links ]
SEPD = Mojela, M.V., M.C. Mphahlele, M.P. Mogodi and M.R. Selokela. 2006. Sesotho sa Leboa / English Pukuntšu Dictionary. Cape Town: Phumelela. [ Links ]
Wiegand, H.E., M. Beißwenger, R.H. Gouws, M. Kammerer, A. Storrer, and W. Wolski (Eds.). 2010. Wörterbuch zur Lexikographie und Wörterbuchforschung / Dictionary of Lexicography and Dictionary Research. Volume 1. Berlin: De Gruyter. [ Links ]
Other references
Gallardo, A. 1980. Dictionaries and the Standardization Process. Zgusta, L. (Ed.). 1980. Theory and Method in Lexicography: 59-69. Columbias: Hornbeam Press. [ Links ]
Gouws, R.H. 2014. Article Structures: Moving from Printed to e-Dictionaries. Lexikos 24: 155-177. [ Links ]
Gouws, R.H. 2018. 'n Leksikografiese datatrekkingstruktuur vir aanlyn woordeboeke Lexikos 28: 177-195. [ Links ]
Gouws, R.H. 2021. Expanding the Use of Corpora in the Lexicographic Process of Online Dictionaries. Piosik, M., J. Taborek und M. Woznicka (Eds.). 10. Kolloquium zur Lexikographie und Wörterbuchforschung. Korpora in der Lexikographie - Stand und Perspektiven: 1-19. Berlin/Boston: De Gruyter. [ Links ]
Gouws, R.H. 2021a. Lexicography and Documentation in a Multilingual Environment. Unpublished paper delivered at the 14th International Conference of the Asian Association for Lexicography, ASIALEX 2021,12-14 June 2021.
Gouws, R.H. and D.J. Prinsloo. 2005. Principles and Practice of South African Lexicography. Stellenbosch: SUN PReSS. [ Links ]
Gouws, R.H. and D.J. Prinsloo. 2021. Lexicographic Data Boxes. Part 1: Lexicographic Data Boxes as Text Constituents in Dictionaries. Lexikos 31: 330-373. [ Links ]
Heuberger, R. 2020. Monolingual Online Dictionaries for Learners of English and the Opportunities of the Electronic Medium: A Critical Survey. International Journal of Lexicography 33(4): 404-416. [ Links ]
Lombard, D.P. 1985. Introduction to the Grammar of Northern Sotho. Pretoria: J.L. van Schaik [ Links ]
Louwrens, L.J. 1991. Aspects of Northern Sotho Grammar. Pretoria: Via Afrika. [ Links ]
Poulos, G. and L.J. Louwrens. 1994. A Linguistic Analysis of Northern Sotho. Pretoria: Via Afrika. [ Links ]
Prinsloo, D.J. 2017. Africa's Response to the Corpus Revolution. Xu, Hai (Ed.). 2017. Proceedings of the 11th International Conference of the Asian Association for Lexicography, ASIALEX 2017, 10-12 June 2017, Guangzhou, China: Lexicography in Asia: Challenges, Innovations and Prospects: 20-31. Guangzhou, China: ASIALEX. Available at http://asialex.org/pdf/Asialex-Proceedings-2017.pdf. [Consulted January 2021. [ Links ]]
Prinsloo, D.J. 2020. Detection and Lexicographic Treatment of Salient Features in e-Dictionaries for African Languages. International Journal of Lexicography 33(3): 269-287. [ Links ]
Prinsloo, D.J. and T.J.D. Bothma. 2020. A Copulative Decision Tree as a Writing Tool for Sepedi. South African Journal of African Languages 40(1): 85-97. [ Links ]
Prinsloo, D.J. and R.H. Gouws. 2006. Lexicographic Presentation of Grammatical Divergence in Sesotho sa Leboa. South African Journal of African Languages. 26(4) 184-197. [ Links ]
Prinsloo, D.J. and R.H. Gouws. 2021. Lexicographic Data Boxes. Part 2: Types and Contents of Data Boxes with Particular Focus on Dictionaries for English and African Languages. Lexikos 31: 374-401. [ Links ]
Prinsloo, D.J. and N.D. van Graan. 2021. Principles and Practice of Cross-referencing in Paper and Electronic Dictionaries with Specific Reference to African Languages. Lexicography, Journal of Asialex 8(1): 32-58. [ Links ]
Prinsloo, D.J. and J.J. van Wyk. 1992. Verwantskapsterminologie van die Noord-Sotho. South African Journal of Ethnology 15(2): 43-58. [ Links ]
Schierholz, Stefan J. 2015. Methods in Lexicography and Dictionary Research. Lexikos 25: 323-352. [ Links ]
Van Wyk, E.B., P.S. Groenewald, D.J. Prinsloo, J.H.M. Kock and E. Taljard. 1992. Northern Sotho for First-Years. Pretoria: J.L. van Schaik. [ Links ]
Van Wyk, J.J. and F.T. Haasbroek. 1990. Verwantskapsterminologie van die Batswana. South African Journal of Ethnology 13(4): 159-179. [ Links ]
Wiegand, H.E. 1998. Wörterbuchforschung. Untersuchungen zur Wörterbuchbenutzung, zur Theorie, Geschichte, Kritik und Automatisierung der Lexikographie. Volume 1. Berlin/New York: Walter de Gruyter. [ Links ]
Wiegand, H.E. and R.H. Gouws. 2011. Theoriebedingte Wörterbuchformprobleme und wörter- buchformbedingte Benutzerprobleme I. Ein Beitrag zur Wörterbuchkritik und zur Erweiterung der Theorie der Wörterbuchform. Lexikos 21: 232-297. [ Links ]
* This is the third in a series of three articles dealing with various aspects of lexicographic data boxes.
^rND^sGallardo^nA.^rND^sGouws^nR.H.^rND^sGouws^nR.H.^rND^sGouws^nR.H.^rND^sGouws^nR.H.^rND^nD.J.^sPrinsloo^rND^sHeuberger^nR.^rND^sPrinsloo^nD.J.^rND^sPrinsloo^nD.J.^rND^sPrinsloo^nD.J.^rND^nT.J.D.^sBothma^rND^sPrinsloo^nD.J.^rND^nR.H.^sGouws^rND^sPrinsloo^nD.J.^rND^nR.H.^sGouws^rND^sPrinsloo^nD.J.^rND^nN.D.^svan Graan^rND^sPrinsloo^nD.J.^rND^nJ.J.^svan Wyk^rND^sSchierholz^nStefan J.^rND^sVan Wyk^nJ.J.^rND^nF.T.^sHaasbroek^rND^sWiegand^nH.E.^rND^nR.H.^sGouws^rND^1A01^nJanja^sPolajnar^rND^1A01^nJanja^sPolajnar^rND^1A01^nJanja^sPolajnarARTICLES
Das Modul Werbeslogans. Eine korpusinformierte lexikografische Ressource zum aktuellen Gebrauch von Werbeslogans außerhalb der Domäne Werbung
E-Module Werbeslogans. A Corpus Informed Lexicographic Ressource of Advertising Slogan Use Outside the Domain of Advertising
Janja Polajnar
Department of German, Faculty of Arts, University of Ljubljana, Ljubljana, Slovenia (janja.polajnar@ff.uni-lj.si)
ZUSAMMENFASSUNG
Der vorliegende Artikel setzt sich zum Ziel, das Modul Werbeslogans, das in das OWWID-Sprichwörterbuch am Leibniz-Institut für Deutsche Sprache nachhaltig integriert ist, in seiner Entstehung darzustellen. Es handelt sich um eine korpusinformierte und nach Kriterien der wissenschaftlichen Lexikografie erarbeitete Onlinedokumentation von Werbeslogans bzw. von aktuell gebräuchlichen verfestigten Sätzen aus der Werbung, die bereits Einzug in die Gemeinsprache gefunden haben. Da diese Slogans ähnlich wie Sprichwörter gebraucht werden, wurden sie auch ähnlich beschrieben. Das Modul basiert auf den innovativen lexikografischen Konzepten im Sprichwortbereich, die im EU-Projekt SprichWort. Eine Internetplattform für das Sprachenlernen für die Sprichwort-Plattform entwickelt wurden, und auf dem OWID-Sprichwörterbuch; es ist innovativ und stellt keine Fortschreibung tradierter Wörterbücher im Bereich der Phraseologie dar. Im Artikel wird einerseits die korpusinformierte Methodik zur Analyse des Slogangebrauchs außerhalb der Domäne Werbung expliziert und andererseits der lexikografische Prozess, die Konzeption der Mikrostruktur der Slogan-Artikel sowie die verschiedenen Zugriffsmöglichkeiten in OWID (OnlineWortschatz-Informationssystem Deutsch) dargestellt. Die dargestellte lexikographische Behandlung von Werbeslogans im Rahmen von OWID ist (in der germanistischen Lexikographie) ein Novum und trägt zur lexikographischen Behandlung von polylexikalen Lexikon-Einheiten bedeutend bei; vor allem aus der Sicht der neueren Betrachtungen des Lexikons aus der Perspektive der Konstruktionsgrammatik.
Schlüsselwörter: modul Werbeslogans, Online-slogan-artikel, Slogangebrauch, Slogan-varianten, Slogan-muster, Lexikografische Ressourcen, Korpusinformierte Internetlexikografie, Lexikografische Online-sloganartikel
ABSTRACT
The article aims to describe the development of E-Module Werbeslogans, integrated into OW/ID-Sprichwörterbuch at the Leibniz Institute for German Language in Mannheim. It represents a corpus informed online description and presentation of advertising slogans, i.e. set sentences from advertising, currently used outside the domain of advertising in everyday language. As these advertising slogans are used in the same way as proverbs, they can be similarly lexicographically described. The module is based on the lexicographic concepts developed in the EU project SprichWort. Eine Internetplattform für das Sprachenlernen für die Sprichwort-Plattform as well as the proverb articles in the OWID-Sprichwörterbuch; it is innovative and does not represent a continuation of traditional dictionaries in the field of phraseology. The article describes the corpus informed method for the analysis of advertising slogans used outside of the domain advertising, continues with the description of the lexicographic process as well as the microstructure of online slogan articles and concludes with the links that connect different information at the macrostructural level of OWID (Online-Wortschatz-Informationssystem Deutsch).
Keywords: module Werbeslogans, Online Slogan Articles, Advertising Slogan Use, Slogan Variants, Slogan Patterns, Lexicographic Ressources, Corpus Informed Internetlexicography, Lexicographic Online-slogan-articles
1. Einleitung
Heute steht einem eine Vielfalt an unterschiedlichen, online frei verfügbaren lexikografischen Ressourcen in vielen Sprachen zur Verfügung, denn die lexi-kografische Forschung und Praxis haben sich seit Mitte der 90er Jahre durch das Internet, den Computereinsatz und die Untersuchungen umfangreicher elektronischer Korpora1 funktional und strukturell stark verändert und modifiziert (Stichwort: Internetlexikografie) (vgl. Klosa und Müller-Spitzer 2016: XI).
Wörterbuchportale, semi-automatisch generierte Angaben, komplexe Suchfunktionen und ein moderater Umfang an Multimodalität sind heute Usus. Auch die lexikographische Arbeitsumgebung spiegelt diese Entwicklung wider mit der Verbindung zwischen Korpora und intelligenten Tools zur Extraktion von Daten und verschiedenen Möglichkeiten der Verbindung zu texttechnologischen Anwendungen (Engelberg, Klosa-Kückelhaus und Müller-Spitzer 2019: 30).
Lexikografische Online-Ressourcen zur deutschen Sprache werden beispielsweise vom Dudenverlag (Duden Onlinewörterbuch), von der Union deutscher Akademien (z. B. DWDS, Wörterbuchnetz u. a.) und auch am Leibniz-Institut für Deutsche Sprache in Mannheim (OWID) (vgl. Klosa-Kückelhaus und MüllerSpitzer 2019: 418f.) erstellt. Im Wörterbuchportal OWID (Online-Wortschatz-Informationssystem Deutsch), das sich auf „Ressourcen zu spezialisierten Wortschatzbereichen konzentriert" (ebd.), stehen den User/-innen zehn lexikogra-fische Ressourcen zur Verfügung (Stand März 2021)2, darunter auch das OWID-Sprichwörterbuch, eine korpusbasierte und „nach Kriterien der wissenschaftlichen Lexikografie erarbeitete Dokumentation aktuell gebräuchlicher fester Sätze der deutschen Sprache - im Kern Sprichwörter" (OWID-Sprich-wörterbuch)3(Abb. 1). Ins Sprichwörterbuch wurde zuletzt das Modul Werbeslogans (Steyer und Polajnar 2015) integriert. Hierbei handelt es sich um die lexikografische Beschreibung des aktuellen Korpusgebrauchs von Werbeslogans, die in der Gemeinsprache eine gewisse Geläufigkeit aufweisen. Da diese Slogans ähnlich wie Sprichwörter funktionieren, wurden sie nach demselben Modell (Steyer 2012; Steyer und Durco 2013; Durco, Steyer und Hein 2017) mit einigen Änderungen in der Wörterbuchartikel-Struktur beschrieben und in das Sprichwörterbuch integriert. Die Slogan-Artikel zeigen nicht nur, wie lebendig und variabel Werbeslogans in außerwerblichen Kontexten sind und wozu Sprecher/-innen sie benutzen, sondern auch, dass die Werbesprache eine moderne Quelle für die Entstehung neuer Sprichwörter darstellt.
Dem Modul Werbeslogans liegt eine umfangreiche korpusinformierte Untersuchung zugrunde. Darin wurde der Slogangebrauch in Zeitungskorpora des Deutschen Referenzkorpus (vgl. DeReKo) im Zeitraum 1990-2008 diachron untersucht und die Mikrodiachronie ihres Vorkommens sowie die Tendenzen ihres Bedeutungswandels, ihrer Varianz und Musterbildung und ihrer kontex-tuellen Einbettung in außerwerblichen Kontexten nachgezeichnet (Polajnar 2012, 2016, 2019).
Das neue Modul ist ähnlich wie das Sprichwörterbuch selbst eine korpusinformierte und „nach Kriterien der wissenschaftlichen Lexikografie erarbeitete Onlinedokumentation aktuell gebräuchlicher verfestigter Sätze" (OWID-Sprich-wörterbuch) aus der Werbung. Die Dokumentation von Werbeslogans wird mithilfe systematischer, empirischer Erhebungen mit COSMAS II (DeReKo) und anschließend mit lexpan (2017), dem Analysewerkzeug zur Systematisierung von KWIC-Zeilen, erarbeitet. Folglich wird nicht an die Fortschreibung tradierter Wörterbücher angeknüpft. Das Modul basiert einerseits auf den lexiko-grafischen Konzepten, die im EU-Projekt SprichWort. Eine Internetplattform für das Sprachenlernen für die Sprichwort-Plattform entwickelt wurden (vgl. SWP; Steyer 2012; Steyer und Durco 2013; Durco, Steyer und Hein 2017; Jesensek 2011, 2013), und andererseits auf der im Folgenden vorgestellten korpusinformierten Untersuchung.
Der vorliegende Artikel bemüht sich um eine transparente Darstellung der korpusinformierten Methodik für die Untersuchung des Slogangebrauchs (Abschn. 3 und 4), des lexikografischen Prozesses, der Konzeption der Mikrostruktur der Slogan-Artikel (Abschn. 5) sowie die verschiedenen Zugriffsmöglichkeiten in OWID (Abschn. 6). Darüber hinaus wird ein Einblick in die bisherigen lexikografischen Versuche der Sloganbeschreibung gegeben (Abschn. 2).
2. Werbeslogans in Nachschlagewerken
Lexikografisch wurden Slogans bis dato zwar einerseits in klassischen oder online-zugänglichen Zitatensammlungen (Büchmann 1864, 422001; Duden 12 (32008); Jeromin 1969; Redensarten-Index; Liste geflügelter Worte) und andererseits in Sloganlexika (Hars 2002) erfasst, allerdings wurden in diesen Nachschlagewerken Slogans fast nie eigenständig und oft nicht systematisch sowie korpusbasiert beschrieben. Interessanterweise waren in der Ausgabe des Dudenbands 12 Zitate und Aussprüche aus dem Jahr 2002 15 Werbeslogans, in der kommenden Ausgabe aus dem Jahr 2008 bereits 31 Werbeslogans verzeichnet, was auf das Interesse bzw. Offenheit der Sprachgemeinschaft für moderne Sprüche sowie „auf die Präsenz und Tendenz zur Usualisierung von Slogans im aktuellen Sprachgebrauch hinweist" (Polajnar 2019: 45); in den Wörterbuchartikeln des Dudenbands 12 sind Werbeslogans nicht systematisch beschrieben und deren Gebrauch ist nur relativ selten mit Belegen aus elektronischen Korpora veran-schlaulicht. Auch in den lexikografischen Online-Ressourcen sind nur vereinzelte Werbeslogans verzeichnet. Zudem wird in den Wörterbuchartikeln dieser Ressourcen eher auf die Entstehungsgeschichte als auf den Gebrauch im Alltag bzw. auf den Korpusgebrauch eingegangen. Auch das umfangreichste Nachschlagewerk zu Werbeslogans von Wolfgang Hars (2002), Das Lexikon der Werbesprüche. 500 bekannte deutsche Werbeslogans und ihre Geschichte, fokussiert die werbegeschichtlichen Informationen und es wird nur punktuell auf ihren Gebrauch eingegangen. Es kann also festgehalten werden, „dass bis dato korpusinformierte Untersuchungen zu Slogans im aktuellen Sprachgebrauch fehl[t]en" (Polajnar 2019: 14) und eine nach Kriterien der wissenschaftlichen Lexikografie systematisch erarbeitete Onlinedokumentation von Slogans wie die vorliegende als Desideratum galt. Dies hängt damit zusammen, dass Werbeslogans bis dato nicht korpuslinguistisch systematisch untersucht wurden, was die Grundlage für eine systematische, korpusinformierte, lexiko-grafische Beschreibung und Dokumentation darstellt.4
Werbeslogans wurden bis dato als Gegenstand unterschiedlicher Forschungsdisziplinen behandelt, vorwiegend in der Werbesprachenforschung und zwar als Bausteine der Werbung im Hinblick auf ihre Form, Inhalt und Funktion. Darüber hinaus wurden Werbeslogans als eigenständige Bausteine bzw. Texte im Hinblick auf ihre Einbindung in außerwerbliche Kontexte aus Sicht der Textlinguistik (vgl. Fix 1997, 2007; Janich 1997, 2019), Jugendsprachenforschung (vgl. Androutsopoulos 1997; Schlobinski 1989), Medienlinguistik (vgl. Betz 2006) sowie Phraseologie (vgl. Burger, Buhofer und Sialm 1982; Lüger 1999) untersucht (vgl. Polajnar 2019: 19-51). Hierbei entstanden einige textlinguistische und phraseologische Definitions- und Klassifikationsversuche, die den Slogan entweder als Werbespruch (Hemmi 1994: 62), Spruchtextsorte (Fix 2007: 464), geflügeltes Wort (Janich 1997) oder satzwertigen Phraseologis-mus (Lüger 1999; Burger 2015) auffassten; das Prinzip ihrer Wiederverwendung bzw. Verselbstständigung wurde im Hinblick auf Intertextualität (vgl. Fix 1997; Janich 1997) oder Phraseologisierung mit den Stufen Zitat, geflügeltes Wort, satzwertiger Phraseologismus (vgl. Burger, Buhofer und Sialm 1982: 56) perspektiviert. Die einzige korpusinformierte Untersuchung zum aktuellen Slogangebrauch außerhalb Werbung ist die Untersuchung von Polajnar (2019), die dem Modul Werbeslogans zugrunde liegt.
3. Korpusinformierter Zugang zum Slogangebrauch außerhalb der Domäne Werbung
Im Mittelpunkt der Untersuchung, die dem Modul Werbeslogans zugrunde liegt, standen „ausgewählte deutschsprachige Werbeslogans mit hohem Wie-dererkennungswert und einer Tendenz zur Usualisierung im aktuellen Sprachgebrauch" (Polajnar 2019: 11). Ihre lexikalische Verfestigung konnte korpusinformiert5 anhand umfangreicher elektronischer Korpora (DeReKo) validiert und rekonstruiert werden. In die Untersuchung wurden 44 kodifizierte Werbeslogans miteinbezogen, die zwei Slogansammlungen mit Referenzcharakter entstammen (Duden 12 2008 und eine Liste der bekanntesten (Firmen-)Slogans vom Internetportal slogans.de). „Für die Beschreibung ihrer Verwendungsspezifik als eigenständige satzwertige Wortschatzeinheiten außerhalb der Domäne Werbung wird das Modell der usuellen Wortverbindungen sowie die korpuslinguistische Methodologie von Steyer (u. a. 2013, 2018) auf die Spruchtextsorte ,Slogan' angewandt" (Polajnar 2019: 11)6 und in einem nächsten Schritt mit weiteren qualitativen und quantitativen Methoden (vgl. Keibel 2008; Polajnar 2012) verknüpft. Die Slogan-Muster und Slogan-Varianten wurden mit dem Analysewerkzeug zur Systematisierung von KWIC-Zeilen lexpan (2017) erarbeitet.
3.1 Iterative Phrasensuche mit engen und weiten Suchanfragen
Die Korpusvalidierung ausgewählter Slogans und deren Varianten sowie die Identifizierung von Slogan-Mustern erfolgt mit einer unterschiedlich elabo-rierten iterativen Phrasensuche im Deutschen Referenzkorpus (DeReKo). Slogans wurden zunächst mithilfe einer komplexen Suchprozedur7 via COSMAS II eigens analysiert und dann anhand der Korpusevidenzen qualitativ bewertet.
Als Beispiel seien die enge und die weite Suchanfrage8 zum Slogan Da weiß man, was man hat. dargestellt und diskutiert. Die enge Suchanfrage dient der genauen Ermittlung von Korpusbelegen für die Kernform, z. B. $da /+w1:1 weiß /+w1:1 man /+w1:1 was /+w1:1 man /+w1:1 hat. In der Regel umfassen enge Suchanfragen die im Stichwort angeführten Wortformen des Slogans und einen geringen Wortabstand; sie orientieren sich an der Form des Stichworts. Man bekommt bei dieser Suche dann alle Belege mit genau dieser Kernform. Hierbei können die ermittelten Kernformen noch sehr eng an dem werblichen Ursprungskontext gebraucht werden, oder aber haben bereits eine allgemeinere Bedeutung entwickelt, wie die folgenden Belege aus dem Korpus zeigen.
(1) HAZ09 die Vertrautheit des guten, alten „Tatorts". Da weiß man, was man hat, HMP12 Eiche, da weiß man was man hat. Ein echter Wert und "unkaputtbar". T12 2013 wird wieder Merkel gewählt (da weiß man, was man hat) und wir rutschen RHP13 Ich koche jedes Jahr Marmelade ein. Da weiß man, was man hat, und sie schmeckt NGACB Dann mache die Updates doch alle manuell. Da weiß man, was man hat.
Bei einer weiten Suchanfrage hingegen erweitert man den Wortabstand zwischen den Formen des Stichworts und/oder bezieht das ganze Flexionsparadigma ein. Mittels einer weiten Suchanfrage können lexikalische, aber auch syntaktische Varianten sowie Musterrealisierungen und dadurch SloganMuster erarbeitet werden; letztere geben des Weiteren die Auskunft über den invarianten Kern, lexikalische Füller sowie die Einschübstellen: $da /+w1:1 (&wissen oder weiß) /+s0 was /+s0 &haben (siehe 5i. Formvarianten und 5j. Ersetzung von Komponenten). Um eine passende weite Suchanfrage bei einem jeden Slogan zu fixieren, muss diese durch ein iteratives Verfahren feingetunt werden. So gibt die Auswahl der Konkordanzen der genannten weiten Suchanfrage Auskunft darüber, dass im Slogan Da weiß man, was man hat. ausschließlich die beiden Indefinitpronomen man durch verschiedene Personalpronomen ersetzt werden können, was bereits Indizien für den invarianten Kern Da [wissen] X, was X [haben]. liefert.
(2) U02 „Kinder, kauft Staatspapiere, da wisst ihr, was ihr habt
BRZ06 pflanze ich lieber selber Bohnen, Erbsen und Möhren an. Da weiß man doch, was man hat".
NGLD Da weißt Du, was Du hast - und musst nichts wegwerfen.
T91 auf den Kleinstadtgeschmack abgestimmt. Da weiß der Alte, was er hat.
Aus methodischer Sicht können also bereits KWIC- und Volltext-Analysen wichtige Hinweise über den invarianten Kern bzw. die Binnenstruktur eines lexikalisch geprägten Slogan-Musters, die typischen Slogan-Varianten sowie Gebrauchsrestriktionen liefern. Besonders ertragreich scheint in solchen Fällen die iterative Suchheuristik (z. B. Ausschließen von Teilkomponenten u. a.) sowie KWIC-Ana-lysen und KWIC-Systematisierung mit Analyseprogramm lexpan (2017).
3.2 Exploration syntagmatischer Slogan-Muster mit lexpan
Mit dem Analysewerkzeug zur Systematisierung von KWIC-Zeilen lexpan9(2017) erfolgte die systematische Analyse von Slogan-Varianten und syntagmatischen Slogan-Mustern und zwar mithilfe von exportierten KWIC- und Kookkurrenz-listen aus DeReKo.10 Das einzelsprachenunabhängige Analyseprogramm dient „der explorativen Untersuchung von Festigkeit, Varianz, Slotbesetzungen und kontextuellen Einbettungsmustern syntagmatischer Strukturen" (ebd.).
Mithilfe von lexpan konnten die zunächst manuell erarbeiteten Ergebnisse in folgenden Bereichen automatisch verifiziert werden. Zum einen lassen sich mit dem Analysewerkzeug Slogan-Muster explorieren, indem Leerstellen entdeckt und systematisch untersuchen werden. Zum anderen kann man auf diese Weise den Kontext von Slogans bzw. ihre kontextuelle Einbettung analysieren, indem man typische kontextuelle metakommunikative Marker und minimale lexikalische Einschübe systematisch untersucht. „Der Mehrwert von lexpan gegenüber manuellen Analysen erweist sich nicht nur in einer viel einfacheren, systematischen Identifikation von einbettenden Elementen, sondern auch von kontextuellen Einbettungsmustern." (Polajnar 2019: 65)
Um mit lexpan den Ikea-Werbeslogans Wohnst du noch, oder lebst du schon? auf Musterhaftigkeit bottom up anhand lexikalischer Musterrealisierungen zu rekonstruieren, muss man mit einer weiten Suchanfrage im virtuellen Zeitungskorpus noch /+w1:1 „oder" /+w3:3 schon eine KWIC-Liste ermittelt. Nach dem Exportieren in lexpan wird die KWIC-Liste mit dem Suchmuster # # noch oder # # schon durchsucht. Die automatische Auswertung der Y-Leerstellen ergibt, dass diese auf Personalpronomen restringiert sind, darunter überproportional häufig auf das Personalpronomen du-du bzw. Du-Du (78,40 %). Daraus ergibt sich, dass der lexikalisch geprägte Slogan-Muster X du noch, oder Y du schon? eine prototypische Teilrealisierung des abstrakteren Musters darstellt. Allerdings weisen auch weitere Personalpronomina gewisse Vorkommenshäufigkeit auf: Sie-Sie (6,64 %), ihr-ihr (2,66 %), sie-sie (1,66 %), wir-wir (1 %), er-er (0,66 %) und es-es (0,66 %) (Abb. 2).
Analysiert man zugleich alle vier Slots des abstrakten Musters, ergibt die Füllerliste aus lexpan, dass der Slogan Wohnst du/Du noch, oder lebst du/Du schon? mit 15,28 % als der prototypische Vertreter gilt, da diese Verb-PronomenKombination im Vergleich zu den anderen Kombinationen eine relativ hohe Vorkommenshäufigkeit aufweist (Abb. 3). Unter den häufigeren lässt sich auch die umgekehrte Kombination beider Verben wohnen und leben konstatieren, die als eine syntaktische Slogan-Variante aufzufassen ist: Lebst du/Du noch, oder wohnst du/Du schon? (2,66 %).
4. OWID-Sloganliste
Vor der lexikografischen Beschreibung muss man sich zunächst den Selektionsmethoden bzw. der Sloganauswahl widmen. Die hiesige Stichwort-Liste der Werbeslogans stellt eine Auswahl der häufigsten Werbeslogans dar, die den Gegenstand der oben erwähnten korpusinformierten Untersuchung zum Slogangebrauch in Zeitungskorpora des DeReKo bildeten. Die ersten 30 Slogans mit höchster Vorkommenshäufigkeit wurden im nächsten Analyseschritt auf ihre „Satzwertigkeit" („satzwertige Phraseologismen" Lüger 1998, 1999) hin genauer untersucht, weil sich Satzwertigkeit bereits bei der Sprichwortidentifizierung als empirisch gut operationalisierbares Kriterium erwiesen hat (vgl. Steyer und Durco 2013). Der nichtsatzwertige Gebrauch bzw. die Einbettung des Werbeslogans in die Satzstruktur hat nämlich oft seine Dekomposition zur Folge. Werden Werbeslogans, wenn auch im Korpus häufig vorkommend, also vorwiegend in die Satzstruktur eingebunden gebraucht, so wurden sie in das Modul nicht aufgenommen. Als Beispiel seien Belege zweier ausgesonderten Slogans Das einzig Wahre. (Warsteiner, 1972) und Der Duft der großen weiten Welt! (Peter Stuyvesant, 1959) genannt, die den nichtsatzwertigen Korpusgebrauch veranschaulichen.
(3) NUN90 das ich liebe, das habe ich bis zur Langweile wiederholt, das einzig wahre Rimini ist das, was ich im Studio gebaut habe."
NUN90 Appell auch all jene erreicht, die glauben, unser System sei das einzig wahre_auf dieser Welt. T90 idealistischen Logik erscheint das fortschreitende Ganze als das einzig Wahre, welches von den "Achtundsechzigern" zwanzig Jahre lang
(4) NUN90 "Vielleicht fehlt ein bißchen der Duft der großen weiten Welt im Vergleich zu anderen Berufen?"
T90 Die kannten den Duft der großen weiten Welt schon und rauchten den ganzen Abend Joints T90 Die waren ja noch nie in Italien und Spanien und wollen den Duft der großen weiten Welt auch mal schnuppern.
Im Modul Werbeslogans sind nur solche satzwertigen Werbeslogans vorzufinden, die sich bereits von ihrem Ursprungskontext (Produktwerbung) entfernt haben und eine Tendenz zum „Weisheitssatz" aufweisen. Hierbei wurden in der OWD-Sloganliste (Abb. 4) Werbeslogans aus unterschiedlichen Jahrzehnten des 20. und 21. Jahrhunderts lexikografisch erfasst:
- aus den 20ern: Nie war er so wertvoll wie heute. (Klosterfrau Melissengeist, 1925),
- aus den 50ern: Mach mal Pause-Serie (Coca-Cola, 1955), Mit fünf Mark sind Sie dabei. (ARD-Fernsehlotterie, 1956), Er läuft und läuft und läuft... (Volkswagen, 1959) und Der Duft der großen weiten Welt! (Peter Stuyvesant, 1959),
- aus den 60ern: Wer wird denn gleich an die Luft gehen? (HB, 1960), Alle reden vom Wetter, wir nicht. (Deutsche Bahn, 1966), Da weiß man, was man hat.
(Volkswagen, 1969),
- aus den 70ern: Quadratisch, praktisch, gut. (Ritter Sport, 1970), Die zarteste Versuchung, seit es Schokolade gibt. (Milka, 1971), Das einzig Wahre. (Warsteiner, 1972), Es gibt viel zu tun. Packen wir's an. (Esso, 1974), Nicht immer, aber immer öfter. (Clausthaler, 1979),
- aus den 80ern: Man gönnt sich ja sonst nichts. (Malteserkreuz Aquavit, 1985), Wir machen den Weg frei. (Volks- und Reiffeisenbanken, 1988),
- aus den 90ern: Nichts ist unmöglich. (Toyota, 1992), Ich bin doch nicht blöd. (Media Markt, 1996) oder Ja is' denn heut' scho' Weihnachten. (E-Plus, 1998) und
- aus dem 21. Jh.: Geiz ist geil! (Saturn, 2001), Wohnst du noch oder lebst du schon? (Ikea, 2002).
Die empirischen Untersuchungen haben gezeigt, dass Werbeslogans oft, aber nicht immer eine auffällige sprachliche Struktur aufweisen wie Wohnst du noch oder lebst du schon? (Ikea, 2002). In einigen Fällen basieren sie allerdings auf völlig regulären, strukturell unauffälligen Sätzen (z. B. Ich liebe es (McDonald's, 2003), Mit fünf Mark sind Sie dabei. (ARD-Fernsehlotterie, 1956)), die zum Teil umgangssprachlichen oder dialektalen Charakter aufweisen (z. B. Ich bin doch nicht blöd. (Media Markt, 1996), Es gibt viel zu tun. Packen wir's an. (Esso, 1974) sowie Ja is' denn heut' scho' Weihnachten (E-Plus, 1998)). Erst durch die Verknüpfung mit einer Marke bzw. einem Produkt und durch vielfaches Wiederholen treten sie aus dem Fluss der Werbekommunikation heraus. Die Sprachgemeinschaft entscheidet dann schließlich darüber, ob der Slogan genug „Spruch-Potenzial" hat, d. h. Alltagssituationen, Verhaltensweisen und Normen plastisch kommentiert und auf den Punkt bringt und damit die Chance besitzt, in den Sprachbestand auf Dauer überzugehen.
5. Aufbau der Slogan-Artikel
Die korpusbasierte Beschreibung umfasst folgende Bausteine: „Kernform", „Basiskomponenten", „Äquivalente in anderen Sprachen" (falls vorhanden), „Suchanfragen für Recherche im Korpus", „Geschichte", „Bedeutung", „Gebrauchsbesonderheiten", „Formvarianten", „Ersetzung von Komponenten", „Typische Verwendung im Text" und „Vorkommen in Nachschlagewerken". Die Slogan-Artikel unterscheiden sich von den anderen SprichwörterbuchArtikeln durch folgende Strukturmerkmale: In den Bausteinen „Kernform", „Äquivalente" und „Geschichte" (siehe dazu 5a, 5c und 5e) wird auf die Entstehungsgeschichte als (internationaler) Firmen-, Marken- oder Produktslogan verwiesen; zudem wird am Ende der Slogan-Artikel im Baustein „Vorkommen in Nachschlagewerken" (5k) ihre bisherige lexikografische Erfassung eviden-tiert. Im Folgenden sollen die einzelnen Bausteine der Slogan-Artikel anhand von Beispielen dargestellt und kommentiert werden.
a. Kernform
Obwohl man bei Werbeslogans intuitiv in die Versuchung geraten könnte, den Originalslogan als Kernform anzusetzen, zeigt die empirisch fundierte und hiermit methodisch sichere Korpusanalyse (Abschn. 3) ein anderes Bild. Die Kernform stellt folglich die im Korpus häufigste satzwertige Form des Werbeslogans dar; diese ist im Vergleich zum Originalslogan oft ohne Angabe des Markennamens. Die Korpusanalyse, mit welcher die auffällig rekurrente Vorkommensform identifiziert wird, hat gezeigt, dass Markennamen oft eine Hürde bei der Verselbstständigung von Slogans darstellen. Dies ist auf ihre Identifikationsfunktion des Unternehmens bzw. der Marke und hiermit mit dem Verweis auf die Ursprungsdomäne zurückzuführen. So können Werbeslogans, bei denen der Markenname Teil der Satzstruktur ist, erst auf der Musterebene eine usuelle, situationsunabhängig-abstrakte (nicht-werbliche) Bedeutung erlangen, wie dies beim Haribo-Slogan X macht Kinder froh. deutlich wird.
Bei den meisten Werbeslogans entspricht die Kernform dem Slogan ohne den Markennamen. Zudem liegen Slogan-Artikel mit Kernformen vor, die eine verkürzte Form des Originalslogans darstellen: Z. B. wurde die Kernform vom Werbeslogan für die Deutsche Bahn aus dem Jahr 1966 Alle reden vom Wetter. Wir nicht. Fahr lieber mit der Bundesbahn. anhand von Korpusvorkommen auf Alle reden vom Wetter. Wir nicht. angesetzt. Unter der Kernform wird im Werbeslogan-Artikel deshalb immer auch der Originalslogan mit dem Markennamen aufgeführt (Abb. 5).
Wie die Sprichwörter weisen auch die meisten Werbeslogans eine eindeutige Kernform auf. Bei einigen Werbeslogans liegen jedoch mehrere Varianten vor, bei denen sich eine als prototypisch erweist (Kernform) und die anderen unter Formvarianten aufgeführt werden (siehe dazu auch h) (vgl. Steyer und Durco 2013).
Kernform: Es gibt viel zu tun. Packen wir's an.
Formvarianten: Es gibt viel zu tun. Packen wir es an.; Es gibt viel zu tun. Packt es an.; Packen wir es an.; Packen wir's an.; Packen Sie es an.
Bei Werbeslogans, die beispielsweise verselbstständigte Sätze aus Werbespots darstellen (gebundene Slogans) und nur gesprochen realisiert werden, konkurrieren mehrere (orthografische) Varianten miteinander, von denen keine als prototypisch gelten kann. In einem solchen Fall muss eine kompetenzbasierte Entscheidung getroffen werden. Als Beispiel sei der Werbeslogan für E-Plus genannt:
Kernform: Ja is' denn heut' scho' Weihnachten?
Formvarianten: Ja is' denn heut' schon Weihnachten?; Ja ist denn heut' scho' Weihnachten?; Ja ist denn heute schon Weihnachten?
b. Basiskomponenten
Alle lexikalischen Komponenten des Slogans (außer bestimmtem und unbestimmtem Artikel) werden zwecks Verlinkung mit dem elexiko-Wörterbuch in OWID und der Ermöglichung unterschiedlicher Zugriffsmöglichkeiten gesondert ausgezeichnet.
c. Äquivalente in anderen Sprachen
Diese Rubrik wird in all jenen Fällen bearbeitet, in denen Webseiten unterschiedlichen Charakters mit Äquivalenten in anderen Sprachen gefunden wurden (Wikipedia, Firmenseiten usw.): In der Regel handelt es sich um Werbeslogans international agierender Unternehmen, wie z. B. Milka: Die zarteste Versuchung, seit es Schokolade gibt., McDonald's: Ich liebe es. oder Media Markt: Ich bin doch nicht blöd., die wegen europaweiten oder weltweiten Präsenz Marketing bedingte Äquivalente in unterschiedlichen Sprachen aufweisen. Bei den Äquivalenten internationaler Slogans handelt es sich meist um Teiläquivalente, vereinzelt wurden auch semantische Äquivalente und Nulläquivalente konstatiert (Polajnar 2016). Ob diese in den jeweiligen Sprachen genauso wie der Originalslogan in außerwerblichen Kontexten Verwendung finden, müsste einzeln für jede Äquivalente wie im Deutschen korpusbasiert überprüft werden. Eine exemplarische Untersuchung von Sloganäquivalenten (Polajnar 2016) hat jedoch zeigen können, dass viele populäre internationale Slogans nicht nur in der Ausgangssprache bzw. im Deutschen, sondern auch in den anderen Sprachen erneut in außerwerblichen Kontexten Verwendung finden und sogar Variationsmuster bilden (z. B. für Snickers im Slowenischen: X si ful drugacen. ('X bist du ganz anders') sowie für Red Bull im Englischen: .X gives you wings. usw.).
d. Suchanfrage für Recherche im Korpus
Diese bereits im großen OWID-Sprichwörterbuch integrierte Angabe soll der schnellen Auffindbarkeit von authentischen Sprachbelegen im Deutschen Referenzkorpus (DEREKO) dienen. Die Suche nach komplexen Sätzen stellt gerade für einen unerfahrenen Nutzer oft eine erhebliche Hürde dar, muss er sich doch einer manchmal recht komplizierten Syntax bedienen. Die hinterlegten Suchanfragen können nun ganz problemlos in das COSMAS II-Suchfenster kopiert werden. Ein neues OWID-Feature wird demnächst diese Suche noch weiter erleichtern. Der Nutzer muss dann nur noch auf die Suchanfrage klicken, und die Korpusanalyse startet automatisch im Hintergrund. Der Nutzer kann so alle Originaltextstellen, in denen der Slogan vorkommt, immer auf dem jeweils aktuellen Stand von DEREKO erhalten. Es werden eine enge und eine weite Suchanfrage für weitere eigenständige Recherchen im Korpus aufgeführt (vgl. Abschn. 3.1).
e. Geschichte
Anders als bei den Sprichwörtern war es bei den Slogans wichtig, auf ihren ursprünglichen Gebrauch in der Werbung bzw. ihre Entstehungsgeschichte sowie auf ihre domänenspezifische Bedeutung zu verweisen. Weil der Ursprung bzw. die Quelle von Werbeslogans nachgewiesen werden kann, werden Slogans häufig als zeitspezifische geflügelte Worte der jüngsten Vergangenheit bezeichnet (vgl. Janich 2010: 61). Doch die Slogan-Artikel zeigen, dass Slogans nicht nur zitiert werden, sondern Varianten und vor allem Muster mit Leerstellen aufweisen, die einem ermöglichen, sie durch das Aufgreifen von Schlüsselwörtern an beliebige Kontexte anzupassen. Dies verweist eher auf ihren ausgeprägten musterhaften Gebrauch (vgl. Bubenhofer 2009).
In diesem Teil des Slogan-Artikels werden also Informationen zur Entstehung des Werbeslogans aus Sekundärquellen gegeben (Nachschlagewerke, Webportale und einschlägige Webseiten usw.). Angereichert werden diese Texte durch DEREKO-Belege, in denen die Entstehung oder der Ursprungskontext des jeweiligen Slogans explizit thematisiert wird und Werbeslogans in Zitatform gebraucht werden. Dadurch unterscheidet sich auch der Korpusgebrauch von Slogans in diesen Belegen vom Korpusgebrauch in allen weiteren Belegen, da hier der Werbeslogan noch keine usuelle, situationsunabhängig-abstrakte (nicht-werbliche) Kernbedeutung aufweist, wie sie in weiteren Teilen der Slogan-Artikel genau beschrieben wird (siehe f). Zudem liegen hier Links auf Youtube-Videos mit den Originalwerbespots (wenn vorhanden) vor. Beim Werbeslogan der Firma Ritter Sport Quadratisch, praktisch, gut. werden in dieser Rubrik eine Vorgeschichte samt Werbespot und ein Beleg, der auf die Werbung rekurriert (Abb. 6), dargestellt:
Geschichte
Die Firma Ritter Sport wirbt noch heute mit diesem Werbeslogan für die Schokolade der Marke Ritter Sport, die für ihre quadratische Form bekannt ist. "Es gibt die Schokolade in dieser Form [...] bereits seit 1932, der populäre Werbespruch wurde aber erst im Jahr 1970 entwickelt. Heute zitiert man ihn im Zusammenhang mit den verschiedensten Produkten oder Ideen meist dann, wenn man deren praktische Seite lobend hervorheben möchte" (Duden 12 2008: 434).
Werbespot 1994 auf Youtube
f. Bedeutung
Die Bedeutungserklärungen basieren durchweg auf den authentischen Korpusvorkommen. Hier geht es um die usuelle, situationsunabhängig-abstrakte (nicht-werbliche) Kernbedeutung, die in allen Korpusverwendungen nachweisbar sein muss. Unter „Bedeutung" wird der verallgemeinerte semantische Kern erfasst, der für alle üblichen Vorkommen dieses Slogans gleichermaßen zutrifft (vgl. SWB). Hierbei verwenden wir eine weitgehend standardisierte Beschreibungssprache, die bereits im EU-Projekt Sprichwort (vgl. Steyer 2012 und SprichWort-Projekt) aus fremdsprachendidaktischen Gründen eingeführt wurde, beispielsweise einleitende Formulierungen wie „Sagt man dafür, dass „Sagt man, wenn Die Bedeutungsbeschreibung soll anhand zweier Beispiele illustriert werden. Für den Slogan Da weiß man, was man hat. lautet die Bedeutung wie folgt: „Sagt man, wenn man lieber auf Bewährtes setzt, als neue, aber möglicherweise riskantere Dinge anzustreben." (SWB-SL) Dazu werden Belege aus dem Korpus aufgeführt.
(5) Wie Gertrud und Reiner Baum machen es viele der inzwischen mehr als 20 000 deutschen Hausbesitzer an Floridas Golfküste: Außerhalb des eigenen Urlaubs vermieten sie ihre Ferien-Immobilie wochenweise - am liebsten an Landsleute: "Da weiß man, was man hat!" (Rhein-Zeitung, 28.02.1997; florida)
Der Slogan Quadratisch, praktisch, gut wird folglich paraphrasiert: „Sagt man, wenn etwas ohne großen Aufwand seine Funktion erfüllt und Qualität hat." (SWB-SL)
(6) Auf- und Umbau funktionieren nach dem Baukastenprinzip: Die dünnen Holzplatten werden mithilfe einer neuartigen Kunststofffolie zum Würfel verspannt - fertig ist der Beistell- oder Nachttisch. Merkmal: quadratisch, praktisch, gut, ganz ohne Schrauben, Bohren oder Hämmern. (Hannoversche Allgemeine, 29.05.2010; Mobil mit Modulen)
Bedeutungsbeschreibung fällt dann anspruchsvoller aus, wenn ein Slogan überwiegend in den Kontexten vorkommt, die noch stark mit der Domäne Werbung verknüpft sind. In einigen Fällen konstituiert sich die abstrakte Bedeutung erst auf der Musterebene. So ist die Verwendung des DeutscheBahn-Slogans Alle reden vom Wetter. Wir nicht. stark an den Wetter-Kontext gebunden. Erst durch die Ersetzung des Lexems Wetter durch andere Nomina wie Rezession oder Benzinpreise lässt sich eine generelle Bedeutung festschreiben: „Sagt man dafür, dass man anders handelt als die Mehrheit und damit vom Gängigen abweicht." (SWB-SL)
(7) Heulen und Zähneklappern wie in vielen anderen Wirtschaftsbereichen ist in der Spielwarenbranche derzeit nicht angesagt: "Alle reden von Rezession - wir nicht", betont DSVI-Geschäftsfiihrerin Printzen mit Verweis auf insgesamt leichte Umsatzzuwächse. "Allen Unkenrufen zum Trotz konnte sich der Spielwarenmarkt in der ersten Jahreshälfte gut behaupten", unterstreicht auch Marktforscherin Gabriele Eberl. (Nürnberger Nachrichten, 26.10.2001, S. 11; Spielwarenbranche hofft auf Umsatzplus im Gesamtjahr - Warten auf Weihnachten)
Ein vergleichbares Phänomen lässt sich beim Ikea-Slogan Wohnst du noch oder lebst du schon? feststellen. Der Slogan wird noch recht häufig in Verbindung mit dem Wohnen und der Philosophie des Möbelkonzerns Ikea gebraucht. Auch hier ist die abstraktere Bedeutung erst durch andere Verbfüller gegeben: Frierst du noch oder heizt du schon? Isst du noch oder genießt du schon? Die Bedeutung kann dan wie folgt festgeschrieben werden: „Sagt man dafür, dass zu fragen ist, ob ein Zustand noch erstrebenswert oder ein anderer zu bevorzugen ist." (SWB-SL)
(8) Nein, noch geht es nicht um die Weihnachtsgeschenke - auch wenn im Handel längst wieder Lebkuchen und Spekulatius Einzug gehalten haben und familienintern mitunter schon diskutiert wird, um wessen Weihnachtsbaum man sich an Heiligabend versammeln wird. Vorerst wird allenthalben die Frage diskutiert: „Frierst du noch oder heizt du schon?!" Angesichts der Wetterkapriolen, die sich vom Frühling über den Sommer nahtlos in den Herbst gerettet haben, hat man in den letzten Wochen kleidungstechnisch dem Zwiebellook gefrönt: morgens Wollpullover, mittags T-Shirt, abends Daunenjacke. Aber jetzt schon heizen? (Mannheimer Morgen, 01.10.2010, S. 17)
g. Gebrauchsbesonderheiten
Unabhängig von der Grundbedeutung liegen bei Slogans zudem Gebrauchsbesonderheiten vor; diese repräsentieren das Typische in den Korpusbelegen und können nur in bestimmten konkreten Gebrauchssituationen auftreten. Unter „Gebrauchsbesonderheiten" werden konnotative, pragmatische und domänenspezifische Aspekte des Slogangebrauchs berücksichtigt, die in den Belegen oft zu beobachten sind, aber nicht für alle Vorkommen verallgemeinerbar sind: Die Beschreibungen der Gebrauchsbesonderheiten werden durch folgende Formulierungen eingeleitet: „(In den Korpusbelegen wird) häufig „typischerweise" oder „in bestimmten Korpusbelegen" (SWB). Für den Slogan Da weiß man, was man hat. lautet eine der Gebrauchsbesonderheiten wie folgt: „In den Korpusbelegen wird mit dem Slogan häufig thematisiert, dass man landwirtschaftliche Produkte aus der eigenen Heimat oder aus vertrauter Herkunft bevorzugt." (SWB-SL)
(9) Es war 1989. Die Öffentlichkeit erfuhr erstmals vom Thema BSE, dem Rinderwahnsinn. Da konnte die schwangere Dorothe Lengert, obwohl keine Vegetarierin, "kein Fleisch mehr sehen ", zumal auch eine Krankheit bei Schweinen grassierte. Die in Hochscheid geborene Försterstochter und ihr Mann Thomas, ein aus Hinzerath stammender Betriebsschlosser, suchten nach Alternativen. Denn Fleisch sollte auch weiterhin auf den Tisch. Da blieb nur die Haltung eigenen Viehs: "Da weiß man, was man hat!" (Rhein-Zeitung, 15.02.1997; Altes Glanvieh kommt - durch BSE neu in Mode)
Der Slogan Quadratisch, praktisch, gut. weist ein ganzes Spektrum von Gebrauchsbesonderheiten auf (Abb. 7):
h. Typische Formvarianten
Formvarianten (h) gehören zusammen mit Ersetzungen von Komponenten (i) zur Varianz, die auf Usualität basiert. Unter Formvarianten sind Informationen zu allen usuellen Typen von formalen Systemvarianten einzelner SloganKomponenten oder des ganzen Slogans subsumiert (z. B. morphologische oder grammatische Varianten, orthographische Varianten). Es sind nur rekurrete Varianten verzeichnet, die bei relativ wenigen Slogans vorzufinden sind (vgl. SWB). Als Beispiel sind die morphologischen Formvarianten zum Coca-ColaSlogan Mach mal Pause. sowie die lexikalischen Formvarianten zum Slogan Mit fünf Mark sind Sie dabei. zu nennen:
Slogan-Kernform: Mach mal Pause.
Morphologische Formvarianten: Macht mal Pause. und Machen Sie mal Pause.
Slogan-Kernform: Mit fünf Mark sind Sie dabei. Lexikalische Formvarianten: Mit fünf Euro sind Sie dabei.
(10) Machen Sie aus dem Möbeleinkauf ein kleines Erlebnis. Gehen Sie entspannt durch die einzelnen Abteilungen oder flanieren Sie von einem Einrichtungsgeschäft zum nächsten. Setzen Sie sich nicht selbst unter Druck. Machen Sie mal Pause und gehen zwischendurch etwas essen. (Mannheimer Morgen, 22.10.1995; Wer nicht handelt, ist selber schuld)
Der Entstehung nach können Slogan-Varianten bei Werbeslogans unabhängig vom Variantentyp in zwei Gruppen unterteilt werden:
(a) domänenspezifische Slogan-Varianten, die im Rahmen der Werbekam-pagne(n) entstehen:
- Zu Mit 5 Mark sind Sie dabei. enstand wegen Währungsänderung eine lexikalische Variante Mit 5 Euro sind Sie dabei. (Fernsehlotterie)
- Zu Haribo macht Kinder froh. entstand wegen Zielgruppenerweiterung eine syntaktische Variante Haribo macht Kinder froh und Erwachsene ebenso. (Haribo)
(b) Slogan-Varianten, die im DEREKO identifiziert werden:
- Zum gesprochensprachlich markierten Slogan von E-Plus Ja, is' denn heut' scho' Weihnachten? eine orthografische Variante Ja, ist denn heute schon Weihnachten?
- Zu Nicht immer, aber immer öfter. eine lexikalische Variante Nicht immer, aber immer öfters.
- Zu Wer wird denn gleich in die Luft gehen? syntaktisch-lexikalische Varianten Aber halt - Wer wird denn gleich ... sowie Warum denn nicht gleich in die Luft gehen?
i. Typische Ersetzung von Komponenten
Hier sind Variationsmuster verzeichnet, bei denen eine Leerstelle unterschiedlich besetzt wird. Die Ersetzung von Komponenten wird durch die Korpusanalyse ermittelt; hierbei muss das Kriterium der Verallgemeinerbarkeit erfüllt werden (vgl. Steyer 2013). Die Muster-Angaben enthalten feste lexikalische Komponenten (fester lexikalischer Kern) und so genannte Füllerangaben. Im Folgenden sind Beispiele dafür aufgeführt, wie die varianten Stellen im Korpus gefüllt werden (Abb. 8).
Die lexikalischen Ersetzungen können auf unterschiedlichen Ebenen und mit unterschiedlichen Effekten erfolgen, z. B.:
(a) Ersetzungen unter Beibehaltung der Sloganbedeutung
- durch formale Ersetzungen, z. B. Da weiß man, was man hat. -> Da weiß ich/sie/Frau, was ich/sie/Frau habe/hat.
- durch andere Lexeme, z. B. Er läuft und läuft und läuft -> (VW-Käfer/ Auto/AC Milano) läuft und läuft und läuft.
(b) Ersetzungen, die unter Beibehaltung der Sloganbedeutung auf andere Sachverhalte referieren, z. B.
- Die zarteste Versuchung, seit es Schokolade gibt -> Die zarteste Versuchung seit es Schinken/Männer/Parteien gibt;
(c) Ersetzungen, die die Sloganbedeutung verändern, z. B.:
- Alle reden vom Wetter, wir nicht -> Alle reden von/vom Zukunft/Globalisierung/Superwahljahr, wir auch; Alle reden von (der) Krise/Fußball, wir nicht.
- Es gibt viel zu tun. Packen wir es an -> Es gibt viel zu tun, lassen wir es sein/warten wir es ab/fangt schon mal an.
- Ja, is' denn heut schon Weihnachten -> Ja, is' denn heute schon Rosen-momtag/1. April/Wahlkampf (Funktionswandel: Ausdruck von unverhoffter Freude -> Ausdruck von Verwunderung)
j. Typische Einbettungen in den Text
Die Markierung von Slogans im neuen Kontext erfolgt durch Marker, Anführungszeichen, oft aber ohne jegliche Kennzeichnung. Diese Angabe erfasst jedoch ausschließlich auffällige sprachliche Phänomene in der unmittelbaren sprachlichen Umgebung eines Slogans. Solche Einbettungen steuern häufig die Interpretation auf maßgebliche Weise. Beispiele für typische Einbettungen sind „fiktive Antworten" wie die folgende Negation:
(11) Neuschnee in der Lüneburger Heide! Ja, is denn heut scho Weihnachten? N& aber die erste Skihalle Norddeutschlands eröffnete gestern in Bispingen. (Hamburger Morgenpost, 21.10.2006, S. 17; Ein Auftakt zum Ausschütten)
Zahlreiche Slogans werden im neuen Kotext nicht nur durch domänen- bzw. werbespezifische Termini (Werbeslogan, Werbekampagne, Werbespruch etc.) eingebettet, sondern ähnlich wie Sprichwörter durch Marker wie unter dem Motto, Devise usw. Steyer kommt anhand der korpusbasierten Untersuchung von 2000 Sprichwörtern zum Schluss, dass es in der Sprachgemeinschaft „durchaus ein ausgeprägtes Sprecherbewusstsein von ,Sätzen' gibt (nicht im grammatischen Sinne, sondern im Sinne einer funktional vollständigen Einheit)" (Steyer 2013: 348). Allerdings scheint die Klassifizierung dieser als Sprichwort, Motto, Devise usw. für die Sprecher/-innen unwichtig. In den Sloganartikeln werden die werbespezifischen oder allgemeinen Marker nur dann vermerkt, wenn diese selbst ein Muster bilden, wie beispielsweise die Vergleiche mit einem Substantiv X à la oder X wie bei Slogan Geiz ist geil.
(12) Und auch die anderen Fraktionen im Rathaus haben sich bei der Wahl des neuen Bürgermeisters am 1. Oktober unter dem Motto "Da weiß man, was man hat" mit großer Mehrheit für den, wie damals zu hören war, "sachkundigen, fairen und zu Kompromissen bereiten Kommunalpolitiker" entschieden. (Frankfurter Allgemeine, 04.11.1997; Der neue Bürgermeister ist jetzt "an Bord")
(13) Die »MarktHallen« am Hauptgüterbahnhof stemmen sich gegen Schnell-und-Billig-Trends à la »Geiz ist geil«: Die Geschäftsleute wollen mit hochwertiger Qualität, die natürlich ihren Preis hat, und ihrem Hintergrundwissen die Kundschaft überzeugen. »Wir drücken niemandem etwas auf, sondern wir geben Erklärungen zu unseren ausschließlich biologischen Produkten«, sagt »Markt-Hallen«-Betreiber und Käseverkäufer Jürgen Würth. (Nürnberger Nachrichten, 15.12.2003; Einkauf mit Genuss - "MarktHallen" wollen Dornröschenschlaf beenden)
Als sprachlich auffällig werden unter typischen Einbettungen bei Slogans zudem markenspezifische Marker wie Ikea-Parole, Lotterie-Weisheit, ToyotaPrinzip genannt, also Bildungen mit Bindestrich-Komposita.
(14) Mit fünf Mark ist man bei der Verbandsgemeinde dabei
Man muss nicht immer mit der Zeit gehen - das meint offensichtlich die VerbandsgemeindeVerwaltung Kirn-Land und hält es mit der alten Lotterie-Weisheit "Mit fünf Mark sind Sie dabei". Das sagt jedenfalls die Aufschrift an der Schrankenanlage vor dem Verwaltungsgebäude an der Bahnhofstraße aus. Doch keine Angst: Der Schlagbaum öffnet sich in diesen Euro-Zeiten auch für Nicht- Mark-Besitzer. Und wenn es keinen stört, muss man in Zeiten leerer kommunaler Kassen schließlich auch eine müde Mark für ein neues Schild ausgeben. (Rhein-Zeitung, 17.11.2004; Mit fünf Mark ist man bei der...)
k. Vorkommen in Nachschlagewerken
Diese Angabe dient dokumentarischen Zwecken, indem vermerkt wird, ob ein Slogan bereits in irgendeiner Form kodifiziert ist.

6. Suche und Vernetzung innerhalb des OWID-Systems
Die Sloganartikel sind auf unterschiedliche Weise mit anderen Inhalten in OWID verbunden:
Bestimmte Slogans werden direkt mit jenen Sprichwortartikeln (SWB) verlinkt, mit denen sie in einem wie auch immer gearteten Verwendungszusammenhang stehen (vgl. Abb. 10):
Andere Beispiele für Verbindungen zu Sprichwörtern aus dem OWID-Sprich-wörterbuch (SWB) sind folgende:
Nichts ist unmöglich:fv
Wer wagt, gewinnt; Der Glaube versetzt Berge; Den Mutigen gehört die Welt; Sag niemals nie, Beharrlichkeit führt zum Ziel, Frisch gewagt ist halb gewonnen
Im Bedeutungsaspekt des „Erst-Mal-Abwartens"
Man sollte sich nicht zu freuen; Noch ist nicht aller Tage Abend; Man soll das Fell des Bären nicht erlegen, bevor er erlegt ist; Eine Schwalbe macht noch keinen Sommer
Nicht immer, aber immer öfter
Unverhofft kommt oft; Was lange währt, wird endlich gut; Steter Tropfen höhlt den Stein; Geduld bringt Rosen
Wer wird denn gleich in die Luft gehen ...
In der Ruhe liegt die Kraft; Eile mit Weile
Durch die Auszeichnung der Basiskomponenten wird zum einen eine Ver-linkung zu dem entsprechenden Einwort-Artikel in elexiko hergestellt, zum anderen kann die OWID-Suche auf die Basiskomponenten zurückgreifen. So erhält man beispielsweise bei der Komponente gut folgende Suchergebnisse (Abb. 11).
Des Weiteren ist es möglich, alle Slogans und Sprichwörter nach einer Basiskomponente zusammenstellen zu lassen (Abb. 12):
OWID sieht schließlich die Möglichkeit vor, unterschiedliche Stichwortlisten anzeigen zu lassen. So kann man den Slogan Da weiß man, was man hat als Teil des Sprichwörterbuchs sehen. Es ist aber auch möglich, die gesamte OWID-Stichwortliste abzrufen.
6. Schlussbemerkungen und Ausblick
Die dargestellte lexikographische Behandlung von Werbeslogans im Rahmen von OWID ist (in der germanistischen Lexikographie) ein Novum und trägt zur lexikographischen Behandlung von polylexikalen Lexikon-Einheiten bedeutend bei; vor allem aus der Sicht der neueren Betrachtungen des Lexikons aus der Perspektive der Konstruktionsgrammatik. Mit dem hier vorgestellten lexikografischen Prozess, der zum Modul Werbeslogans führte, verfolgten wir das Ziel, den Korpusgebrauch von aktuell gebräuchlichen deutschen Werbeslogans nach Kriterien der wissenschaftlichen Lexikografie aufzubereiten und als Onlinedokumentation nachhaltig zur Verfügung zu stellen. Da systematische korpusbasierte (Online-)Dokumentationen von Werbeslogans bis dato fehlen, dürfte das beschriebene Modul ein innovatives Konzept zur lexikografischen Erfassung und linguistischen Beschreibung der Werbeslogans darstellen. Anhand zahlreicher Korpusbelege konnte veranschaulicht werden, wie vielfältig und variabel der Gebrauch von Werbeslogans als verfestigten Sätzen in außerwerblichen Kontexten ist sowie wie und wozu Sprecher/-innen sie verwenden. Dadurch versuchten wir nicht nur zu verdeutlichen, dass Werbeslogans in der Gemeinsprache ähnlich wie Sprichwörter funktionieren und verwendet werden, sondern dass die Werbesprache eine moderne Quelle für die Entstehung neuer Sprichwörter darstellt. Es kann beobachtet werden, dass es in der Sprachgemeinschaft ein ausgeprägtes Bewusstsein von Sätzen als funktional vollständigen Einheiten gibt. Ob diese satzwertigen Gefüge als Sprichwort, Slogan, Motto, Devise u. a. bezeichnet werden, scheint für die Alltags-sprecher/-innen unwichtig, was metakommunikative Elemente im Kotext von Slogans sowie Sprichwörtern veranschaulichen. Damit ließ sich auch die lexi-kografische Beschreibung von Werbeslogans nach demselben Modell wie dem für Sprichwörter sowie ihre Integration in das OWID-Sprichwörterbuch begründen. Stellenweise wurden die Slogan-Artikel jedoch im Hinblick auf die Spezifik der Werbeslogans erweitert („Kernform", „Äquivalente in anderen Sprachen", „Geschichte", „Vorkommen in Nachschlagewerken"), um auf die für Slogans wichtige Entstehungsgeschichte und ihre bisherige sporadische Dokumentation zu verweisen. Der künftige Schwerpunkt bei der lexikografischen Beschreibung des Korpusgebrauchs von Werbeslogans wird neben der Erarbeitung neuer Artikel auf der Weiterentwicklung der Methode der Erfassung lexikalischer Variationsmuster und von neuen Darstellungsformaten (z. B. in Form von Lückenfüllertabellen vgl. Steyer 2013) mit lexpan liegen.
Das OWID-Sprichwörterbuchmodul Werbeslogans richtet sich zum einen an In- und Auslandsgermanist/-innen und Deutschlehrende, die das Modul in ihre Lehrtätigkeit integrieren könnten, sowie an alle Deutschlernenden und Interessierten, die anhand zahlreicher Links das Thema Korpusgebrauch von Werbeslogans für sich entdecken wollen. Die korpusinformierte Untersuchung und Beschreibung von Werbeslogans soll aber auch für die Forschung anregend sein, insbesondere im Bereich der Sprichwortforschung und der Konstruktionsgrammatik, aber auch im Bereich der Werbesprachenforschung.
7 . Endnoten
1 . Es war die korpuslinguistische Wende, die das Erforschen und lexikografische Erfassen von sprachlichen Phänomenen im Allgemeinen und von Phraseologismen bzw. „usuellen Wortverbindungen" (Steyer 2013) im Speziellen tiefgreifend veränderte. Die korpuslinguistische Wende führte im Bereich der Phraseologie zu zwei Paradigmenwechsen: Liberalisierung und Erweiterung der phraseologischen Einheiten in Richtung „funktionale Verfestigung" und musterbasierte Phraseologie (vgl. Steyer 2013).
2 . Das Wörterbuchportal OWID enthält neben dem Sprichwörterbuch folgende lexikografische Ressourcen: elexiko - Online-Wörterbuch zur deutschen Gegenwartssprache (online seit 2013), Paronymwörterbuch (online seit 2018), Kommunikationsverben (online seit 2013), Kleines Wörterbuch der Verlaufsformen im Deutschen (online seit 2013), Deutsches Fremdwörterbuch - Neubearbeitung (Buchstaben A-H online seit 2016), Neologismenwörterbuch (online seit 2014), Schulddiskurs 1945-55 (online seit 2008), Protestdiskurs 1967/68 (online seit 2012), Schlüsselwörter der Wendezeit 1989/90 (online seit 2015).
3 . Die deutschen Wörterbuchartikel wurden im Rahmen des multilingualen EU-Projekts SprichWort. Eine Internetplaform für das Sprachenlernen (2008-2010) erarbeitet und anschließend von Dr. Kathrin Steyer für die Online-Publikation zubereitet.
4 . Bekannte Werbeslogans wurden beispielsweise im Slowenischen noch seltener lexikografisch erfasst: Einige Slogan-Artikel finden sich in einer kolaborativ geschriebenen Online-Ressource des gesprochenen Slowenisch „Razvezani jezik" (http://razvezanijezik.org/?page=Naslovnica), die punktuell die Entstehungsgeschichte und die Bedeutung skizzieren, ohne konkrete Sprachbelege anzuführen. Weitere lexikografische Ressourcen in anderen Sprachen sind mir nicht bekannt.
5 . Wie in jüngsten korpusempirischen Arbeiten im Bereich der Phraseologie üblich, wird auch in der vorliegenden Untersuchung eine vordefinierte Liste von Slogans mit vermuteter Tendenz zur Usualisierung anhand eines virtuellen Korpus aus DeReKo validiert. Allerdings wird auch bei einem korpusbasierten („corpus-based") Vorgehen wie diesem immer wieder beobachtet, dass Erkenntnisse anhand Korpusevidenzen in den Forschungsprozess einfließen und ihn beeinflussen. Folglich wird die Festlegung auf ein Korpusparadigma in jüngster Zeit von Forschern relativiert: Der corpus-based- und corpus-driven-Ansatz schließen sich gegenseitig nicht aus und nur ihre Verknüpfung kann wirklich ertragreich sein (vgl. Steyer 2013: 71-72). Um dieser Relativierung terminologisch gerecht zu werden, wird in der vorliegenden Untersuchung in Anlehnung an Gredel (2014) von einem korpusinformierten Ansatz gesprochen.
6 . Die Adaption der musterbasierten Korpusmethodlogie für Slogans und ihre lexikografische Beschreibung im Modul Werbeslogans im OWID-Sprichwörterbuch wurden in Kooperation mit dem Projekt Usuelle Wortverbindungen (Leitung: Dr. Kathrin Steyer) während mehrerer Forschungsaufenthalte seit 2009 am Leibniz-Institut für Deutsche Sprache erarbeitet.
7 . Die Suchprozedur basiert auf einer bestimmten Suchsyntax, dessen Komplexität von der Komplexität der Oberflächenform des Slogans abhängt. Diese wurde im Rahmen des EU-Projekts SprichWort. Eine Internetplattform für das Sprachenlernen sowie des UWV-Projekts entwickelt.
8 . Ergebnisse der Suchanfragen werden zunächst in Form von KWIC-Ansicht (Kontextzeilen des Suchwortes/des Suchsyntagmas) analysiert. Die KWIC-Ansicht liefert einen ersten Überblick dazu, ob die Suchanfrage bereits eine hohe Anzahl an relevanten Treffern erbringt oder ob sie durch bestimmte Parameter anzupassen ist, d. h. ob die Suchanfrage zu eng oder zu weit ist. Zu jeder KWIC-Zeile kann man einen Volltext abrufen, der je nach Wahl einige (Ab-)Sätze vor und nach dem zentralen Suchsyntagma angibt.
9 . Das Analysewerkzeug wurde vom Projekt Usuelle Wortverbindungen (UWV) am Leibniz-Institut für Deutsche Sprache in Mannheim entwickelt.
10 . Bevor mit dem Analyseprogramm lexpan eine KWIC-Systematisierung erfolgen kann, müssen zunächst anhand einer adäquaten Suchanfrage aus dem DEREKO entsprechende KWIC-Listen ermittelt werden. Diese werden in lexpan exportiert und darin abgespeichert sowie in einem nächsten Schritt mithilfe von einfachen Suchanfragen ohne komplexe Suchsyntax systematisch und schnell untersucht.
8. Literaturverzeichnis
Androutsopoulos, Jannis. 1997. Intertextualität in jugendkulturellen Textsorten. Klein, Josef und Ulla Fix (Eds.). 1997. Textbeziehungen. Linguistische und literaturwissenschaftliche Beiträge zur Intertextualität: 339-372. Tübingen: Stauffenburg. [ Links ]
Betz, Ruth. 2006. Gesprochensprachliche Elemente in deutschen Zeitungen. Radolfzell: Verlag für Gesprächsforschung. [ Links ]
Bubenhofer, Noah. 2009. Sprachgebrauchsmuster. Korpuslinguistik als Methode der Diskurs- und Kulturanalyse. Sprache und Wissen 4. Berlin/New York: Walter de Gruyter. [ Links ]
Büchmann, Georg. 1864, 422001. Geflügelte Worte: der klassische Zitatenschatz. 42. neu bearb. u. aktual. Aufl. München: Ullstein Verlag. [ Links ]
Burger, Harald. 2015. Phraseologie. Eine Einführung am Beispiel des Deutschen. 5. Aufl. Berlin: Erich Schmidt Verlag. [ Links ]
Burger, Harald, Annelies Buhofer und Ambros Sialm. 1982. Handbuch der Phraseologie. Berlin/ New York: Walter de Gruyter. [ Links ]
Cosmas-II (Projekt „Cosmas II" (2015). Korpusrecherche- und -analysesystem. Institut für Deutsche Sprache. Mannheim). http://www.ids-mannheim.de/cosmas2/ [12.1.2021].
DEREKO (Institut für Deutsche Sprache (2016): Deutsches Referenzkorpus / Archiv der Korpora geschriebener Gegenwartssprache 2016-I (Release vom 31.03.2016)). Mannheim: Leibniz-Institut für Deutsche Sprache. www.ids-mannheim.de/DeReKo [12.1.2021]. [ Links ]
Duden 12: Zitate und Aussprüche. 2002, 32008. Mannheim/Leipzig/Wien/Zürich: Dudenverlag.
Durco, Peter, Kathrin Steyer und Katrin Hein. 2017. Sprichwörter im Gebrauch. Unveränderter Wiederabdruck der 2015 in Trnava erschienenen Erstausgabe. Mannheim: Institut für Deutsche Sprache. [ Links ]
elexiko (Online-Wörterbuch zur deutschen Gegenwartssprache). http://www.owid.de/wb/elexiko/start.html [12.1.2021].
Engelberg, Stefan, Annette Klosa-Kückelhaus und Carolin Müller-Spitzer. 2019. Lexikographie zwischen Grimm und Google? Sprachreport 35(2): 30-34. [ Links ]
Fix, Ulla. 1997. Kanon und Auflösung des Kanons. Typologische Intertextualität - ein ,post-modernes' Stilmittel? Eine thesenhafte Darstellung. Antos, Gerd und Heike Tietz (Eds.). 1997. Die Zukunft der Textlinguistik. Traditionen, Transformationen, Trends: 97-108. Reihe Germanistische Linguistik 188. Tübingen: Niemeyer. [ Links ]
Fix, Ulla. 2007. Der Spruch - Slogans und andere Spruchtextsorten. Burger, Harald et al. (Eds.). 2007. Phraseologie. Ein internationales Handbuch der zeitgenössischen Forschung: 1. Halbband: 459-468. Handbücher für Sprach- und Kommunikationswissenschaft 28(1). Berlin/New York: Walter de Gruyter. [ Links ]
Gredel, Eva. 2014. Diskursdynamiken. Metaphorische Muster zum Diskursobjekt Virus. Berlin: Mouton de Gruyter. [ Links ]
Hars, Wolfgang. 2002. Das Lexikon der Werbesprüche. 500 bekannte deutsche Werbeslogans und ihre Geschichte. Frankfurt a. Main: Piper Verlag. [ Links ]
Hemmi, Andrea. 1994. „Es muß wirksam werben, wer will nicht verderben": Kontrastive Analyse von Phraseologismen in Anzeigen-, Radio- und Fernsehwerbung. Zürcher Germanistische Studien. Frankfurt a. M.: Peter Lang. [ Links ]
Janich, Nina. 1997. Wenn Werbung mit Werbung Werbung macht ... Ein Beitrag zur Intertextua-lität. Muttersprache 107: 297-309. [ Links ]
Janich, Nina. 2010. Werbesprache. Ein Arbeitsbuch. 5. erw. Aufl. Tübingen: Narr Studienbücher. [ Links ]
Janich, Nina. 2019. Intertextualität und Text(sorten)vernetzung. Janich, Nina (Ed.). 2019. Textlinguistik. 15 Einführungen und eine Diskussion. 2. Aufl. 177-198. Tübingen: Narr. [ Links ]
Jeromin, Rolf. 1969 (o. J.). Zitatenschatz der Werbung. Slogans erobern Märkte. Gütersloh: Präsentverlag Heinz Peter. [ Links ]
Jesensek, Vida. 2011. Sprichwörter im Wörterbuch. Linguistik online 47(3): 67-78. http://www.linguistik-online.de/47_11/. [ Links ]
Jesensek, Vida. 2013. Das lexikographische Beispiel in der Parömiographie. Formen und Funktionen. Lexikos 23: 150-171. http://lexikos.journals.ac.za/pub/article/view/1209/720. [ Links ]
Keibel, Holger. 2008. Mathematische Häufigkeitsmaße in der Korpuslinguistik: Eigenschaften und Verwendung. Mannheim: Institut für Deutsche Sprache. URL: http://www.ids-mannheim.de/kl/dokumente/freqMeasures.html [13.07.2020]. [ Links ]
Klosa, Annette und Carolin Müller-Spitzer unter Mitarbeit von Martin Loder. 2016. Internetlexi-kografie. Ein Kompendium. Berlin/Boston: Walter de Gruyter. [ Links ]
Klosa-Kückelhaus, Annette und Carolin Müller-Spitzer. 2019. OWID und OWIDplus: lexikographische und lexikalische Ressourcen am IDS Mannheim. Zeitschrift für germanistische Linguistik 47(2): 418-431. Berlin/Boston: Walter de Gruyter. [ Links ]
lexpan - Lexical Pattern Analyzer (Version 2019-06-21). Ein Analysewerkzeug zur Untersuchung syntagmatischer Strukturen auf der Basis von Korpusdaten. Entwickelt vom Projekt "Usuelle Wortverbindungen", Institut für Deutsche Sprache, Mannheim. http://uwv.ids-mannheim.de/lexpan/ [13.1.2020].
Liste geflügelter Worte. https://de.wikipedia.org/wiki/Liste_gefl%C3%BCgelter_Worte [12.1.2020].
Lüger, Heinz-Helmut. 1998. Vom Zitat zur Adaption. Zu einigen Verwendungsweisen satz-wertiger Phraseologismen. Beiträge zur Fremdsprachenvermittlung 34: 118-135. [ Links ]
Lüger, Heinz-Helmut. 1999. Satzwertige Phraseologismen. Eine pragmalinguistische Untersuchung. Wien: Ed. Praesens. [ Links ]
OWWID (Online-Wortschatz-Informationssystem Deutsch des IDS). https://www.owid.de/ [12.1.2021].
Polajnar, Janja. 2012. Textuelle Aspekte von rekontextualisierten Werbeslogans in deutschsprachigen Zeitungen. Eine korpusbasierte Untersuchung bekannter Werbeslogans im Zeitungskorpus des Deutschen Referenzkorpus (DeReKo). Muttersprache 122(1): 48-64. [ Links ]
Polajnar, Janja. 2016. Recontextualisation of International Advertising Slogans and their Equivalents in Different European Languages. Poznan Studies in Contemporary Linguistics [Online ed.] 52(1): 85-117. [ Links ]
Polajnar, Janja. 2019. Werbeslogans im aktuellen Sprachgebrauch. Eine korpusinformierte, diachrone Untersuchung zur Dynamik des Slogan-Gebrauchs mit lexikografischen Fallstudien. Amades 55. Mannheim: IdS Leibniz-Institut für Deutsche Sprache. [ Links ]
Razvezani jezik. Prosti slovar zive slovensäne. http://razvezanijezik.org/?page=Naslovnica [12.3.2021]
Redensarten-Index (Wörterbuch für Redensarten, Redewendungen, idiomatische Ausdrücke und feste Wortverbindungen). http://www.redensarten-index.de/suche.php [12.1.2021].
Schlobinski, Peter. 1989. Frau Meier hat Aids, Herr Tropfmann hat Herpes, was wollen Sie einsetzen? Exemplarische Analyse eines Sprechstils. Schlobinski, Peter et al. (Eds.). 1989. OBST 16. Sprache und Erfahrung: 1-34. Osnabrücker Beiträge zur Sprachtheorie 41. Osnabrück: Univ. Osnabrück. [ Links ]
Slogans.de. http://www.slogans.de/slogans.php?Op=SRanking1 [12.1.2021].
Steyer, Kathrin (Ed.). 2012. Sprichwörter multilingual. Theoretische, empirische und angewandte Aspekte der modernen Parömiologie. Studien zur Deutschen Sprache 60. Tübingen: Gunter Narr Verlag. [ Links ]
Steyer, Kathrin. 2013. Usuelle Wortverbindungen. Zentrale Muster des Sprachgebrauchs aus korpusanalytischer Sicht. Studien zur Deutschen Sprache 65. Tübingen: Narr. [ Links ]
Steyer, Kathrin (Hg.). 2018. Sprachliche Verfestigung. Wortverbindungen, Muster, Phrasem-Konstruk-tionen. Studien zur Deutschen Sprache 79. Tübingen: Narr. [ Links ]
Steyer, Kathrin und Peter Durco. 2013. Ein korpusbasiertes Beschreibungsmodell für die elektronische Sprichwortlexikografie. Benayoun, Jean-Michel, Natalie Kübler und Jean-Philippe Zouogbo (Eds.). 2013. Parémiologie. Proverbes et formes voisines. Band 3: 219-250. Sainte Gemme: PUSG. [ Links ]
Steyer, Kathrin und Janja Polajnar. 2015. Werbeslogans. Sprichwörterbuch in OWID. http://www.owid.de/wb/sprw/start.html.
SWB: Sprichwörterbuch in OWID. http://www.owid.de/wb/sprw/start.html [12.1.2020].
SWB-SL: Steyer, Kathrin und Janja Polajnar. 2015. Modul Werbeslogans im OWID-Sprichwörter- buch. https://www.owid.de/service/stichwortlisten/slgn [12.1.2020].
SWP (EU-Sprichwortplattform). http://www.sprichwort-plattform.org/ [12.1.2020].
^rND^sAndroutsopoulos^nJannis^rND^sEngelberg^nStefan^rND^nAnnette^sKlosa-Kückelhaus^rND^nCarolin^sMüller-Spitzer^rND^sFix^nUlla^rND^sFix^nUlla^rND^sJanich^nNina^rND^sJanich^nNina^rND^sJesensek^nVida^rND^sJesensek^nVida^rND^sKlosa-Kückelhaus^nAnnette^rND^nCarolin^sMüller-Spitzer^rND^sLüger^nHeinz-Helmut^rND^sPolajnar^nJanja^rND^sPolajnar^nJanja^rND^sSchlobinski^nPeter^rND^sSteyer^nKathrin^rND^nPeter^sDurco^rND^1A01^nAnna^sTenieshvili^rND^1A01^nAnna^sTenieshvili^rND^1A01^nAnna^sTenieshviliPROJECTS
The New Online English-Georgian Maritime Dictionary (NEGMD): Current State of the Project
Die Nuwe Aanlyn Engels-Georgiese Maritieme Woordeboek (NEGMD): Stand van die projek
Anna Tenieshvili
Foreign Languages Department, Batumi State Maritime Academy, Batumi, Georgia (a.tenieshvili@bsma.edu.ge) (anna_tenieshvili@yahoo.com)
ABSTRACT
My practical training at the Maritime Transport Administration of Georgia in 2018 inspired the project of compiling the NEGMD. The project was boosted by an international grant of the European Lexicographic Infrastructure (ELEXIS), which led to an invitation to visit the Instituut voor Nederlandse Lexicologie in Leyden, the Netherlands.
The aim of this report on the compilation of the NEGMD is to show the state of this project from a practical point of view using concrete examples of terminological entries.
The project includes two main issues: the compilation of the dictionary itself and the coinage of new maritime terms in Georgian to fill the existing lexical/terminological gaps. It is of great importance for the field of maritime education and training in Georgia, for the whole maritime economy of the country and for the development of the Georgian language and, consequently, for the fields of Georgian linguistics and lexicography.
All issues related to this project including the criteria according to which it is being compiled and the information each terminological entry of the dictionary comprises, will be thoroughly covered. Perspectives on future dictionary development will be presented, illustrating it by concrete examples from the NEGMD.
Keywords: Dictionary compilation, Guiding principles, Terminological Entries, Coinage of georgian maritime terminology
OPSOMMING
My praktiese opleiding by die Maritieme Vervoer-administrasie van Georgia in 2018 het die projek om die NEGMD saam te stel, ge'inspireer. Die projek is bevorder deur 'n internasionale toekenning van die Europese Leksikografiese Infrastruk-tuur (ELEXIS), wat gelei het tot 'n uitnodiging om die Instituut voor Nederlandse Lexicologie in Leiden, Nederland, te besoek
Die doel van hierdie verslag oor die samestelling van die NEGMD is om die stand van die projek uit 'n praktiese oogpunt te toon met konkrete voorbeelde van terminologiese inskrywings.
Die projek omvat twee hoofkwessies: die samestelling van die woordeboek self en die skepping van nuwe seevaartterme in Georgies om die bestaande leksikale/terminologiese gapings te vul. Dit is van groot belang vir die vakgebiede van maritieme opvoeding en opleiding in Georgia, vir die algehele maritieme ekonomie van die land en vir die ontwikkeling van die Georgiese taal, en dus vir die vakgebiede Georgiese linguistiek en leksikografie.
Alle kwessies rakende hierdie projek, insluitende die kriteria waarvolgens dit saamgestel word en die inligting wat elke terminologiese inskrywing van die woordeboek bevat, sal deeglik gedek word. Perspektiewe op toekomstige woordeboekontwikkeling sal aangebied word deur dit met konkrete voorbeelde uit die NEGMD te illustreer.
Sleutelwoorde: Woordeboeksamestelling, Riglyne, Terminologiese inskry-Wings, Nuutskeppings in georgiese maritieme terminologie
Introduction
The aim of the present report is to familiarize readers with the progress of work on the compilation of the NEGMD. The dictionary represents a pioneering project both for the fields of Georgian lexicography and Georgian maritime terminology. The reason for this is that previously, all maritime dictionaries that had been compiled in Georgia were translational dictionaries, giving one or several meanings of a particular term. The dictionary subject of this report has an explanatory character that is conditioned by the fact that term definitions are given both in English and Georgian, and also for the purpose of illustrating the terminology usage, the terms are provided with corpora examples. The information given in each terminological entry is organized in such a way that the student and general user are given an idea and understanding of the particular concept expressed by means of terms in the language. The compilation of this dictionary is guided by a terminological rather than a lexicographic approach. since this is a specialized dictionary, the approach is therefore onomasiological, rather than semasiological, i.e. starting from the concept and moving to naming the concept by means of a term.
The project also addresses the coinage of missing Georgian maritime terminology with the purpose of filling existing lexical gaps, an issue that is especially relevant for terms of maritime navigation. During this process, i identify terms that do not have Georgian equivalents and through cooperation with the Georgian Linguistics institute and the state Language Chamber of Georgia terms will be coined and added to the dictionary.
The NEGMD project
several contributing factors led to the start of the NEGMD project. They can be formulated and explained in the following way:
one of the priorities of the Georgian economy and sustainable development is to develop the maritime field. The development of the maritime field is especially important for the economics of the country and this field should be developed in several directions. They are: ports, logistics, maritime education and training that comprises navigation, maritime transportation, maritime management and marine engineering. The importance of the maritime field is confirmed by the fact that this field makes a large contribution to the country's economy and budget and therefore its development is of strategic importance.
Nowadays, the maritime field is an international field in which various countries of the world fulfil various functions. Georgia mainly fulfils a transit function and owing to its geostrategic location throughout history, the country has formed a link between Europe and Asia. Georgia, being an important centre of maritime education, can increase its role in the preparation of highly qualified seafarers since maritime education plays a significant role in establishing Georgia in the international domain and in the development of the country's economy.
The idea of the project of compiling the NEGMD occurred to me after I had my practical training at the Maritime Transport Administration of Georgia in 2018. This practical training was obligatory since, in addition to my PhD in English Philology, I received an MSc in Maritime Affairs majoring in Maritime Education and Training from the World Maritime University (WMU).
As part of the above-mentioned project I received an international grant from the European Lexicographic Infrastructure (ELEXIS) in 2019 and being the receiver of the grant program, I was invited to the Instituut voor Nederlandse Lexicologie in Leyden, the Netherlands. In order to compile a dictionary that will contain various types of information including definitions, corpus examples, some encyclopedic information, related words, etc., it was necessary to conduct some research work, to pay attention to advice of specialists experienced in similar work. As my dictionary is intended to have both terminological and lexicographic features, the opinions of terminologists and lexicographers are to be taken into consideration when composing entries and compiling the dictionary as a whole. In addition to the dictionary compilation, the purpose of my work is to conduct research in order to fill in the lexical gaps existing in maritime terminology in Georgian.
During work on the NEGMD project, I am guided by the following recommendations for the compilation of specialized dictionaries that were given by L'Homme (2006: 182) in the article "The Processing of Terms in Dictionaries":
- Dictionaries should consider user needs and include highly specialized but also less specialized items;
- Terminologists or specialized lexicographers should make more use of evidence found in corpora as a basis for taking decisions about terms;
- Dictionaries should include more data on terms (e.g., collocations, valence patterns, images);
- Bilingual and multilingual dictionaries should account for interlinguistic differences;
- Dictionaries should describe relationships between terms;
- Specialized dictionaries should contain encyclopedic or pragmatic information;
- Definitions should be structured in order to display key conceptual components.
The project includes consideration of and work on maritime terminology. As maritime terminology is divided into two parts, general maritime terminology and specific maritime terminology, I started the compilation of the dictionary from work on general maritime terminology. At the present stage, the project comprises more than 1000 terminological entries, the majority of which are general maritime terms.
The following criteria and principles guide the compilation of the dictionary:
1. The terminology comprises the following maritime subfields: maritime navigation, marine mechanical engineering, marine electrical engineering, logistics, economics of maritime transport, mechanization of port operations, cargo work and maritime law;
2. At the current stage I consider and work on simple terms, as for terminological lemmas, they will form the following stage of the dictionary compilation work;
3. Each terminological entry includes definitions and corpus examples;
4. Each term is considered from the viewpoint of its monosemantic nature.
During dictionary compilation, I am guided by the international standard of terminology processing and enter all information related to terminological entries into a specially developed online platform.
As mentioned in Tenieshvili (2020: 485-491) the NEGMD project is very important to Georgia as a sovereign country, for Georgian linguistics and lexicography and for the Georgian maritime semantic field. Georgia is a sovereign country now, and terminology is one of the means of establishing the country as an independent state. Although maritime terminology is the most globalized semantic field in the world, each country, especially maritime nations like Georgia, must have its own maritime terminology. It is especially important for reaching the following aims:
1. Stimulation for developing Georgian maritime terminology;
2. Application of the developed maritime terminology in textbooks, maritime documentation and materials;
3. Economy of space and facilitation of understanding among specialists and students of the maritime field;
4. Improvement of the system of maritime education and consequently of the national maritime industry;
5. Contribution to the lexicography of Georgian;
6. Development of the lexicography of the maritime semantic field;
7. Establishing a basis for a Georgian maritime corpus with further integration of the Georgian maritime corpus into the general corpus of the Georgian language;
8. General contribution to Georgian linguistics.
It would be expedient to give an idea of the NEGMD project by demonstrating terminological entries that have already been developed in the present report:
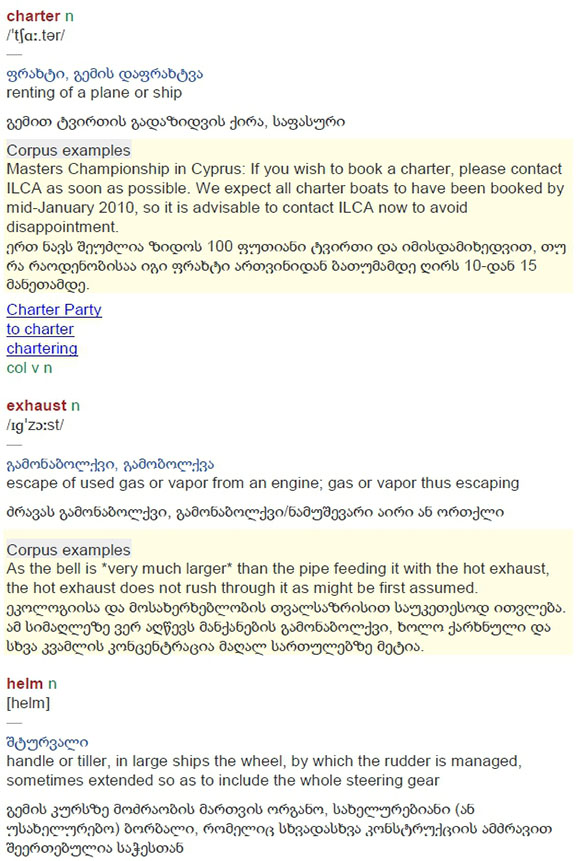

(extracted from: The NEGMD)
Along with the compilation of the dictionary itself, there is a second issue: the coinage of Georgian maritime terminology. There are different methods of terminology creation. Sometimes even calques can be used. In my opinion, as English is the official language of the maritime field established by the International Maritime Organization (IMO) based in London, it would be expedient if calquing takes place from the English language. That would contribute to the internationalization of terminology and this, in its turn, would facilitate communication between specialists of the maritime field. It is also important to ensure the coexistence of national terms and terms that have recently entered the language.
I think that when creating Georgian maritime terminology, specialists should be guided by the rules of Georgian and it would be better to avoid calquing taking into consideration international linguistic rules at the same time. Such a combined approach would help in reaching a certain balance in this issue. As an example, I would like to mention that owing to linguistic specifics of the English language there exist terms based on the noun + noun model in it, yet it does not mean that grammatical calques should be borrowed in line with lexical calques too.
In my opinion, the issue of coinage of the Georgian maritime terminology implies several organizational issues, such as:
1. Revision of existing maritime dictionaries and glossaries;
2. Selection of a policy for the coinage of maritime terms;
3. Selection of methods for the coinage of maritime terms;
4. Organization of a team.
Perfection and adoption of maritime terminology will contribute to the development of the entire maritime field and also its different subfields. It is very important to ensure the improvement of the academic level of maritime specialists.
Conclusion
Compilation of the New Online English-Georgian Maritime Dictionary is of utmost importance for the field of maritime education and training and for the whole maritime field of Georgia. It will stimulate the educational process in Georgian maritime educational institutions, provide much new information and increase comprehension of maritime issues, contributing to a better comprehension of maritime phenomena by Georgian maritime students in their native language. In addition, the project and all issues discussed in this report will contribute to the fields of lexicography and linguistics in Georgia, as it will enable native Georgians to study and comprehend maritime phenomena in their native language via correspondent terms and not only on the basis of English-English explanations, the practice that exists today.
The issues of compilation of the maritime dictionary and refining of Georgian maritime terminology are very important for the development of maritime education and for the establishment of Georgia in the international maritime arena.
References
L'Homme, Marie-Claude. 2006. The Processing of Terms in Dictionaries: New Models and Techniques. A State of the Art. Terminology 12(2): 181-188 [ Links ]
New Online English-Georgian Maritime Dictionary. Available at: https://www.lexonomy.eu/zy44hrpwh/.
Tenieshvili, A. 2020. The New Online English-Georgian Maritime Dictionary Project. Challenges and Perspectives. Gavriilidou, Z., M. Mitsiaki and A. Fliatouras (Eds.). 2020. Proceedings of the XIX Euralex International Congress, Alexandroupolis, Greece, 7-11 September 2021. Volume 1: 485-491. Komotini, Greece: Democritus University of Thrace. Available at: https://euralex2020.gr/wp-content/uploads/2020/11/EURALEX2020_ProceedingsBook-p485-491.pdf. [ Links ]
^rND^sL'Homme^nMarie-Claude^rND^sTenieshvili^nA^rND^1A01^nErnst^sKotzé^rND^1A01^nErnst^sKotzé^rND^1A01^nErnst^sKotzéREVIEWS
W.F. Botha (Hoofredakteur). Woordeboek van die Afrikaanse Taal, Sestiende Deel: SRP-SZONDITOETS. 2021, xx + 759 pp. ISBN-13 978-1-990998-46-1 (leerband), ISBN-13 978-1-990998-45-4 (plastiekband). Stellenbosch: Büro van die WAT. Prys: R900 (leerband) / R550 (plastiekband).
Inleidend
By die terhandneming van WAT XVI (2021), is 'n mens bewus van die historíese waarde van hierdie laaste gedrukte oplaag, 'n indrukwekkende foliant wat 'n voortsetting is van die formaat wat mettertyd gevestig geraak het as kenmerkend van hierdie vlagskippublikasie. Hierdie derde en laaste deel van die letter S strek van die lemma SRP, die afkorting vir sekuriteitsregulerings-paneel, tot die lemma Szonditoets. Aangesien die oorblywende dele ná S slegs aanlyn beskikbaar sal wees, word die papier-era hiermee afgesluit en die elek-troniese medium ten volle ingespan. Deur voortgesette hersiening en bywerking, wat hierdeur moontlik gemaak word, bly die WAT 'n aktuele bron van kennis oor die Afrikaanse woordeskat. Hierdie uitgawe beslaan 779 (759 + xx) bladsye, met 7 606 verklaarde lemmas in die sentrale teks. Hierby kom ook 'n addendum wat ongeveer 1 560 bygewerkte lemmas van AAHS tot Sri Lankaans bevat, en dus prakties deel vorm van die sentrale teks.
Vorderingstempo
Die eerste 15 dele (met 11 bykomende oplae) van die WAT het teen 'n frekwensie van gemiddeld 4 jaar en 10 maande per deel sedert 1950 van die pers gekom.

Deel sewentien (T) word vroeg in 2023 in die vooruitsig gestel, en die mikpunt vir die voltooiing van die woordeboek tot Z (ten minste voor 'n beoogde volledige herbewerking) is nou 2028. Dit is moontlik gemaak deur bykomende befondsing en personeeluitbreiding, waardeur die beplande voltooiingsdatum met 10 jaar vervroeg is. Vanaf 2020 het die effek van die heersende pandemie terselfdertyd maatreëls genoodsaak om die voorgenome voortgang van die werk te verseker, ten spyte van afsonderlike werkstasies.
Beoordelingsperspektief: Die WAT as omvattende woordeboek
'n Belangrike faktor by die beoordeling van enige woordeboek is die aard en doel van die betrokke publikasie, wat soos volg lui:.
Die missie van die WAT is om 'n omvattend verklarende woordeboek en ander leksikografiese produkte in Afrikaans saam te stel, en sodoende die Afrikaanse taal, sy gebruikers en die leksikografie te dien.
As teikengebruikers word uit die breë spektrum dan veral "hoërskoolleerders tot Afrikaans-akademici" uitgesonder, vir wie die aanbiedingswyse toeganklik behoort te wees. 'n Verdere eienskap wat beklemtoon word, is dat dit 'n sin-chroniese woordeboek is, en dus nie aanwysings van die herkomstyd of geskie-denis bevat nie, en voorbeeldmateriaal ook nie chronologies gerangskik is nie. Dit beteken egter nie dat ouer (en verouderende) vorme nie opgeneem word nie - wel dat sulke vorme deur etikette gemerk word.
In die onderstaande bespreking word daar eers 'n kort oorsig gegee van die hoofkomponente, waarna bepaalde kenmerke van die hoofteks bespreek en ook met mekaar in verband gebring word.
Die voorwerk
In die voorwerk word omvattende inligting verstrek, in aansluiting by die reeds bekende formaat van WAT XV en die voorafgaande dele. Daarby word 'n beskrywing van die mediostruktuur, of die wyse waarop kruisverwysings en bronverwysings aangebied word, aangevul deur 'n wye verskeidenheid aktuele inligting, wat die produksieproses, ander leksikografiese produkte, die personeel, skakeling met deskundiges en die publiek, en die missiestelling van die WAT (hierbo vermeld) insluit. 'n Enkele punt van kritiek wat betref die indrukwekkende lys vakkundige medewerkers is dat postume bydraers nie as soda-nig aangedui word nie - o.a. vdr. B. Hinwood en mnr. C. de Ruyter, wat beide al 'n geruime tyd oorlede is. Of dit wel ter sake is, is wel 'n ander vraag, maar dit sou waarskynlik nodig wees om nuwe deskundiges te betrek vir die toekomstige dele.
'n Eienskap van die toeligting (in die voorwerk) by die gebruik van die woordeboek is die uitvoerige beskrywing van die leksikografiese bewerking - iets wat vir die gebruiker grafies voorgestel word aan die hand van die (nou reeds bekende) skematiese voorstelling van inskrywings (hier op bl. vi).
Die makrostruktuur
Die feit dat die WAT 'n omvattende woordeboek is, beteken dat die makro-struktuur (d.w.s. die geheel van leksikale items wat as lemmas ingesluit word) 'n aansienlike mate van vryheid kan weerspieël wat betref die keuse van lemmas, en by alle waters kan skep.
In 'n onderhoud op RSG op 6 Junie 2021 wys Alet Cloete daarop dat die omvattende aard van die makrostruktuur weerspieël word deur die opname van historíese of verouderde woorde, nuutskeppings, vaktaal, formele, informele en plat vorme, en alle variëteite, wat streektaal- en geselstaalvorme insluit. Die insluiting van al hierdie kategorieë, asook betekenisonderskeidings wat met verloop van tyd verandering ondergaan, veroorsaak dat daar tydens die samestelling van die betrokke deel ordeningsbesluite geneem moet word op grond van die huidige gebruiklikheid. (Hierop word daar verder in die bespreking uitgebrei.)
Die mikrostruktuur
Wat die mikrostruktuur van artikelinskrywings betref - dus die wyse waarop die inligting oor elke lemma gestruktureer is - word aspekte soos gramma-tiese inligting, lettergreepverdeling, spelling, uitspraakleiding, woordsoortelik-heid, morfologie, etimologie en sintaksis gedek. Hierdie struktuur maak voor-siening vir 'n breë spektrum van moontlikhede, vanaf 'n enkele item (bv. 'n afkortingsvorm soos "Swaz. afk. Swaziland" tot 'n omvang van 5 200 woorde (in die geval van steek), of selfs langer. Oor die rangskikking van die elemente wat deel kan vorm van die mikrostruktuur word in die toeligting altesaam 12 kategorieë bespreek, wat kumulatief bydra tot die mees volledige struktuur van 'n artikel, maar wat uiteraard selde almal aan die beurt kom. Ook aspekte soos die aanduiding van samestellings en afleidings, verwysings en wissel-vorme kom ter sprake.
Bylaes
Benewens die lys van 55 bladsye met bronne waaruit in die artikelinskrywings aangehaal is, voorafgegaan deur 'n toeligtingsbladsy, is daar 'n enkele bylae (Addendum A, wat ongeveer 1 560 nuwe byvoegings vanaf Deel I tot XV insluit).
Die deskriptiewe en preskriptiewe aard van die woordeboek
As naslaanbron het die WAT nie 'n eksplisiet preskriptiewe funksie nie, maar weerspieël dit die breeds moontlike spektrum van geskrewe Afrikaans. Hoewel dus oorwegend deskriptief, sou die aanbieding van alle leksikografiese teks (bv. lemmas, definisies en mikrostrukturele inligting) wel ortografiese AWS-norme volg wat op Afrikaans van toepassing is. Vergelyk egter, by wyse van uitsondering, die lemmas sulu en Sulu, waarvan die meervoudsvorme as sulus en Sulus (sonder meervoudsapostroof) aangedui word.
Ten spyte van die feit dat die WAT teoreties die grense oorskry van wat as ortografíes genormeerde Afrikaans beskou kan word (wat betref die weergawe van sitate), word daar in die omgang deur die deursnee-taalgebruiker dikwels na hierdie bron verwys om 'n bepaalde gebruiksvorm as gemagtig of gesank-sioneer te staaf. Definisies van lemmas in die WAT as verklarende woordeboek word uiteraard wel as gesaghebbend aanvaar en stawend gebruik, 'n funksie wat daartoe lei dat die WAT deur die gewone gebruiker ook oor 'n breër spektrum van normering gebruik word.
Lemmatisering van fonetiese spelwyses (wat uitspraakverskynsels weerspieël)
Deur die opname van sitate uit variëteite wat (nog) nie ortografies genormeer is nie, bv. uit Kaaps, kom daar variante spellings voor wat dikwels op die fone-tiese interpretasie van individuele skrywers berus. Dit is in sulke gevalle waar die sitaat, en in sommige gevalle die lemma wat daardeur geïllustreer word, 'n tentatiewe normerende funksie het. 'n Voorbeeld van 'n geselstaalvariant, wat ook in verskillende variëteite voorkom, is spieg (p. 701), wat eerder 'n ontronde geselstaalvariant is van spuug, waarna daar nie verwys word nie, as van die meer neutrale spoeg. 'n Vergelykbare voorbeeld van die lemmatisering van fonetiese spelwyses is die opname van spien (met 'n kruisverwysing na 2speen), 'n enkele voorbeeld uit 'n veel groter aanbod in die sitate, soos ernstagge, 'ie, vloe, gie, suste, dieselle wot, vrint, vanaan, nuh, ds, ens., wat almal fonologiese kenmerke van Kaaps weerspieël). Dit onderstreep die behoefte aan ortografíese normering ten opsigte van veral informele variëteite. Daar sou aan die hand gedoen kon word dat so 'n tentatiewe normering kan berus op 'n frekwensie-gebaseerde aanduiding in die etikette, waardeur daar met groter stelligheid 'n keuse uitgeoefen kan word van hoe relatiewe frekwensie beskryf word. Dit het bv. betrekking op die onderskeid tussen etikette soos "meer dikw." (by stêre en ook stêrre), "ongewoon" (by sterde), en "selde ook" (by sterde en stêre), waarna hieronder verwys word.
Etikette - motivering en toepassing
Deur die gebruik van etikette word sommige geselekteerde lemmas gemerk wat benewens 'n basiese (denotatiewe) betekenis, ook spesifieke konnotasies dra waarvan die gebruiker kennis behoort te dra. Sulke etikette kan moontlik in algemene kategorieë verdeel word:
(a) Register, wat deur die stylvlak bepaal word, of die mate van formaliteit - redaksioneel word hierna as sosiostilistiese etikette verwys (Voorbeelde: geselstaal, skertsend, formeel, verhewe, ens.);
(b) Streeks- of groepsaanduidend (Voorbeelde: streektaal, visserstaal, studente-taal, sleng);
(c) Tegniese of vakterminologie (Voorbeelde: anatomie, oudheidkunde, skeep-vaart, stylleer, kookkuns, chemie);
(d) Stigmatisering (Voorbeelde: vloek, plat, vulgêr, neerhalend, rassisties, seksis-ties, skeltaal - as teenhanger van sulke terme word die etiket eufemisties ook gebruik);
(e) Gebruiklikheid en tydsgebondenheid (Voorbeelde: minder gebruiklik, ongewoon, selde ook, meer dikwels, verouderd, verouderend, histories);
(f) Inligting wat nie kontekstueel uit die sitaat of poëem afgelei kan word nie, soos by suursmaak, hoewel die sitaat hier deur die gebruik van "(sauerkraut)" reeds voldoende inligting bevat.
Die gebruik van etikette om registers, variëteite e.d.m. aan te dui, is 'n nood-saaklike komponent van die mikrostruktuur, gegewe die seleksie uit alle soorte variëteite waaruit sitate onttrek word, en kan van groot waarde wees om die variasiemoontlikhede van die taal leksikografies te struktureer. Aan die ander kant het sulke etikette ook die funksie om die beperkings ten opsigte van register en konteks onder die aandag te bring. By die bewerking van die betrokke lemma word die kontekstuele beperkings ook, al is dit implisiet, deur die sitate geïllustreer.
Een kategorie uit die lys etikettipes hierbo word met meer as gewone aan-dag onder die loep geneem, naamlik stigmatiseringsetikette. Omdat taal soveel aspekte van die gemeenskaplike bestaan van 'n taalgemeenskap (en verskillende taalgemeenskappe in 'n land soos Suid-Afrika) benoem, sluit dit ook die problematiek van sodanige saambestaan in. In taalkommunikasie dien die woord dikwels ook as wapen, en kom veral as uitdrukking van rassistiese en seksistiese houdings in die taalgebruik van sommige gebruikers na vore. Ter-wyl die bestudering van sulke items wetenskaplik onproblematies kan wees, kan die opname van emosioneel gelaaide items vir die deursnee-gebruiker dui op 'n erkenning van die gebruik daarvan, en dus as genormeerd (soos hierbo vermeld). 'n Duidelike uiteensetting van die opname van sulke items (bene-wens die gebruik van etikette) word in par. 6 van die voorwerk verstrek, iets waarvan die gebruiker met vrug kan kennis neem.
Opmerkings oor ortografíese aanbiedingswyse van lemmas
Wat betref die skryfwyse van samevoegings wat los of vas geskryf kan word, veral dan as bywoord plus voltooide deelwoord, sou die een en ander oor die aanbiedingswyse opgemerk kan word. Ook hier geld die waarneming dat vorme wat in die WAT gelemmatiseer word, deur heelwat sprekers as norm aanvaar word. In die geval van voorbeelde soos
sterkontwikkel, sterkruikend, sterkgewortel, sterkgroeiend
word die vas geskrewe (in die teks vasgeskrewe) vorme wel gelys op grond van die voorkoms daarvan in sitate, maar die etiket lui "(meer dikw. los)", wat by korpusondersoek dikwels blyk slegs los te wees. In die definisie van sterkontwikkel lui dit ook (los) "Wat sterk ... ontwikkel is". Die indruk kan hierdeur geskep word dat slegs die attributiewe vorme vas geskryf word, bv. ook sterk-skemer, en die predikatief los. Die antonimiese vorme met swak (bv. swakont-wikkelde, maar ook swak ontwikkelde, wat beide wel in korpora voorkom) volg dieselfde patroon, waar swak- as koppeltekenlemma aan die begin van 'n lys onverklaarde lemmas geplaas word, met 'n etiket wat aandui dat dit meer dikwels los geskryf word. Daardeur kan die afleiding (tereg of ten onregte) ook gemaak word dat daar in 'n mate selektief omgegaan is met die keuse van lemmas wat deur konvensie of semantiese verbleking (naas die los geskrewe by-woord plus naamwoord, wat uiteraard nie gelemmatiseer hoef te word nie) as vaste vorme kan voorkom.
In teenstelling hiermee word die mees gebruikte vorm, meestal los geskrewe, by idiomatiese en gespesialiseerde uitdrukkings (wat ook vas geskrewe teenhangers met 'n laer frekwensie het) as basis gebruik (vgl. die tweede alinea van par. 5.3 op p. xvii).
Slot
WAT XVI voeg in verskeie opsigte waarde toe aan sy voorgangers, o.a. deur die uitgebreide terminologieverklaring, die insluiting van klassieke (bv. Romaanse of Grieksgebaseerde) ekwivalente van Germaanse vakwoordeskat, en duidelike uitspraakleiding. Met inagneming van bepaalde kritiese opmerkings, kan hier-die sestiende deel beskou word as 'n uitstekende bron vir taalpraktisyns, navorsers en studente. Die redelik gekompliseerde mikrostruktuur maak dit ook van nut vir meer gevorderde gebruikers, en voldoen aan leksikografiese vereistes op 'n hoë vlak. Dit kan beskou word as 'n model vir kennis oor omvattende, verklarende woordeboeke.
Die grootste uitdaging wat betref die afhandeling van die woordeboek as geheel is waarskynlik om 'n konsekwente formaat van aanbieding van A tot Z in die uiteindelike aanlyn weergawe tot stand te bring.
Ernst Kotzé
Emeritus Nelson Mandela-Universiteit Port Elizabeth (ernst.somerstrand@gmail.com)
^rND^1A01^nRufus H.^sGouws^rND^1A02^nD.J.^sPrinsloo^rND^1A01^nRufus H.^sGouws^rND^1A02^nD.J.^sPrinsloo^rND^1A01^nRufus H^sGouws^rND^1A02^nD. J^sPrinslooARTICLES
Lexicographic Data Boxes Part 1. Lexicographic Data Boxes as Text Constituents in Dictionaries*
Leksikografiese datakassies. Deel 1. Leksikografiese datakassies as tekskonstituente in woordeboeke
Rufus H. GouwsI; D.J. PrinslooII
IDepartment of Afrikaans and Dutch, Stellenbosch University, Stellenbosch, South Africa (rhg@sun.ac.za)
IIDepartment of African Languages, University of Pretoria, Pretoria, South Africa (danie.prinsloo@up.ac.za)
ABSTRACT
This article, the first in a series of three on lexicographic data boxes, focuses primarily on the occurrence of lexicographic data boxes as text constituents in dictionaries. Following a brief look at what data boxes are, the focus shifts to the different venues where these boxes can be accommodated within the central list of a dictionary. Boxes containing items and/or item texts can be positioned within articles, or article-externally as phased-in inner texts within a partial article stretch of a dictionary. Data boxes are used to convey data that need to be highlighted and are therefore often formally marked (a coloured background or within a frame) and are put in an article slot that has a position of salience. As dictionary entries they can participate in procedures of both lemmatic and non-lemmatic addressing. It is shown that a box should preferably be inserted close to its address. In articles of polysemous words, the user should unambiguously know for which sense(s) the box is relevant. As phased-in inner texts data boxes can be addressed at a lemma within the same partial article stretch but also, in the case of synopsis boxes, at lemmata in other article stretches. This demands procedures of remote addressing.
Keywords: addressing, article stretch, article windows, article-external DATA BOXES, ARTICLE-INTERNAL DATA BOXES, DATA BOXES, DATA DISTRIBUTION, EXPANDED WORD LIST, INSERTS, LEXICOGRAPHIC DATA BOX, PARALLEL MACROSTRUCTURE, PARTIAL ARTICLE STRETCH, PHASED-IN INNER TEXTS
OPSOMMING
Hierdie artikel, die eerste in 'n reeks van drie oor leksikografiese datakassies, fokus veral op die voorkoms van leksikografiese datakassies as tekskonstituente in woordeboeke. Na 'n kort bespreking van wat datakassies is, verskuif die fokus na die verskillende plekke waar hierdie kassies in die sentrale woordelys van 'n woordeboek geakkom-modeer kan word. Datakassies wat aanduiders en/of aanduidertekste bevat, kan binne-in artikels, of artikel-ekstern as ingefaseerde binnetekste in die deeltrajekte van 'n woordeboek geplaas word. Datakassies word gebruik om data oor te dra wat beklemtoon moet word en word daarom dikwels gemerk (met 'n gekleurde agtergrond of in 'n raam) en word in 'n artikelgleuf geplaas wat in 'n posisie is wat die aandag trek. As woordeboekinskrywings word datakassies betrek by prosedures van lemmatiese en nielemmatiese adressering. Dit word aangetoon dat 'n kassie liefs so na as moontlik aan sy adres geplaas moet word. In artikels van polisemiese woorde moet die gebruiker ondubbelsinnig kan weet vir watter betekenisonderskeiding(e) die kassie relevant is. As ingefaseerde binnetekste kan datakassies aan 'n lemma in dieselfde deeltrajek geadresseer wees, maar ook, in die geval van sinoptiese kassies, aan lemmata in ander artikeltrajekte. Dit vereis prosedures van verwyderde adressering.
Sleutelwoorde: adressering, artikeldeeltrajek, artikel-eksterne data-KASSIES, ARTIKEL-INTERNE DATAKASSIES, ARTIKELTRAJEK, ARTIKELVENSTERS, DATA-KASSIES, DATAVERSPREIDING, INGEFASEERDE BINNETEKSTE, INVOEGING, LEKSIKO-GRAFIESE DATAKASSIE, PARALLELLE MAKROSTRUKTUUR, UITGEBREIDE WOORDELYS
And they all get put in boxes, little boxes all the same
(Malvina Reynolds)
1. Introduction
The emergence1 and establishment of dictionary structures as a focal area of research in the field of metalexicography and dictionary research has had a significant influence on the theory and practice of lexicography. The scope of this influence included a critical analysis and discussion of the occurrence and positioning of a variety of text compound constituents, texts and textual segments in dictionaries and dictionary articles. Research into dictionary structures had both a contemplative and a transformative approach, cf. Tarp (2004: 224). Existing structures were studied and described but a whole range of new structures were identified, proposed and employed in the planning and compilation of dictionaries. Research into dictionary structures resulted in lexicographers realising all articles in a given dictionary do not necessarily have to display exactly the same structure. A sequence of articles in a single article stretch does not merely have to be a presentation of more of the same. Instead of a single and consistently applied homogeneous article structure the lexicographer has the liberty to opt for less rigid heterogeneous article structures in which the obligatory microstructure, the default microstructure of the specific dictionary, can be supplemented by items enabling an extended obligatory microstructure. Different types of word list, micro- and article structures give lexicographers the opportunity to present partial article stretches, microstructural items and item texts in a way that would best fit the needs and reference skills of their intended target users. Yet again, the user-perspective plays a dominant role in the planning and compilation of dictionaries. This perspective also co-determines the data distribution and data presentation in any given dictionary as a search region, the word list as a search field, an article as a search area and the article slots as search zones, but also the structure allocated to any article as well as the potential inclusion of phased-in inner texts in a given article stretch. For the study of dictionary structures the occurrence and positioning of each partial article stretch, item text, item and indicator is of significance. This also applies to data boxes as lexicographic text constituents.
Lexicographic data boxes are lexicographic text constituents frequently employed in the presentation of data in various search venues of dictionaries. Although data boxes have become a common phenomenon in dictionaries, relatively little attention has been paid to their presentation, the motivation for their use and the type of data a dictionary displays in this specific way, cf. Gouws and Prinsloo (2010) and Taljard, Prinsloo and Gouws (2014). This article firstly motivates the need for a theoretical discussion of data boxes, focusing on the types of data boxes and the textual positions allocated to them before following a contemplative approach by taking a look at some aspects of the current use of data boxes. A transformative approach is also followed and some ideas deemed necessary for an improved use of this lexicographic text segment will be presented in the final article of this three-part series.
The focus in this article is on the occurrence of data boxes as text constituents in dictionaries. In the follow-up articles, part 2 and 3 in this series, the focus will be on the contents of data in boxes and a look at future improvements respectively.
2. What are lexicographic data boxes?
Before proceeding with a discussion of lexicographic data boxes it is important to have a clear understanding of what is meant in this article by the term lexicographic data box and its shortened form data box.
A lexicographic data box, or just data box, is a data-carrying constituent of the word list of a dictionary. It contains data presented
- as part of the treatment of a specific lemma that is the guiding element of the article in which the data box appears or that is in close proximity to the data box;
- as part of the treatment of various lemmata where the data box is an entry in an article or in a partial article stretch that accommodates one of the lemmata for which the treatment in the data box is relevant;
- in a phased-in inner text in an article stretch that contains a lemma for which the contents of the data box is relevant.
Data boxes contribute to the lexicographic treatment of a lemma in the same article stretch where they appear, specifically a lemma that is the guiding element of the article in which the data box is presented as entry or a lemma in close proximity of that data box. In addition, synoptic data boxes can also contain data relevant to the lexicographic treatment of lemmata in other article stretches of the dictionary. Data boxes are usually distinguished from other data-carrying constituents in terms of the form in which they are presented. They often occur within a framed box, as a text constituent with a coloured background, as an article window (cf. Wiegand and Gouws 2011: 281), or in clearly identified phased-in inner texts that split a partial article stretch. Although data boxes often contain data presented within a frame or against a coloured background, this is not always the case. Some data boxes are not presented in boxed or coloured format.
The term data box is preferred to the frequently used term text box because texts are not the only type of data to be accommodated in these boxes.
Examples of different types of data boxes will be presented in later sections of this article.
3. Why data boxes
Lexicographers should refrain from procedures that could result in a situation of data overload in their dictionaries, cf. Gouws and Tarp (2017). In its default microstructural presentation a dictionary article should contain the data the lexicographer regards as sufficient to satisfy the lexicographic needs of the envisaged target user. In addition to the data presented in the word list of a dictionary the lexicographer may also use a data distribution structure that allocates certain data to texts in the front and/or back matter sections of the dictionary. Where a lexicographer is convinced that specific data entries are needed to improve the lexicographic presentation and treatment in the word list of a given dictionary but the default microstructure, article structure and word list do not offer an appropriate position for such data entries, the lexicographer may embark on using data boxes - either article-internally or as phased-in inner texts. The use of data boxes needs to ensure an added value to the default treatment on offer in a given dictionary and the contents of data boxes should not be more of the same with regard to the default data presentation in dictionaries.
Data boxes are salient dictionary entries and as such they should be employed when there is a need to bring a non-default type of data to the attention of the user or to place more than the usual focus on a specific data item. As a result of lexicographic procedures used in an extended obligatory micro-structure, care should be taken that data boxes do not become part of the obligatory microstructure and in so doing lose their significance and decrease the emphasis on the data included in these boxes. Lexicographers should make a clear distinction between using data boxes and using other lexicographic procedures, e.g. a system of labelling, to focus the attention of the user on a specific item.
4. The need for a discussion of data boxes
The broad field of lexicography is characterised by an interactive relation between theory and practice. Because the theory of lexicography emerged much later than the practice there had to be a lot of catching up to ensure a comprehensive theoretical coverage of the endeavours of the lexicographic practice and to present future compilers of dictionaries with the necessary theoretical basis for their dictionaries. In lexicography theory and practice do not develop in a parallel way. In lexicographic theory new suggestions come to the fore and they are often only applied in practice at a much later stage, e.g. the proposal for semi-integrated microstructures (Wiegand 1996). Some suggestions resulting from research in the field of theoretical lexicography never even find an application in the lexicographic practice. Practical lexicographers often introduce innovative approaches in their dictionaries and the theory may eventually include a discussion of these approaches when they have already been firmly established in dictionary compilation processes. Yet, it remains important that there should be a relation of reciprocity between theory and practice in lexicography: theory should learn from and influence the practice and the practice should learn from and influence the theory.
The occurrence of data boxes in printed dictionaries, especially learner's dictionaries, as well as in electronic dictionaries, especially those which are based on paper dictionaries, has increased significantly in the last decades. Although (learner's) dictionaries continuously witness an enhancement in quality, also as a result of extensive research in the field of theoretical lexicography with regard to this dictionary type, the competitive market and the competition between publishing houses have also had an influence on changes in the structures and contents of dictionaries. Many of these changes have added value to the dictionaries but in some instances they were, according to Wiegand and Gouws (2011: 238), not much more than trends in lexicographic face-lifting. The lexicographic practice did, however, introduce innovative uses of data boxes coming to the fore in many dictionaries. In this regard practice took the lead and theory unfortunately failed to respond quickly enough. Consequently many of these approaches have not yet been sufficiently appreciated and discussed by metalexicographers.
In order for lexicographic theory to keep up with developments in the practice and in order to ensure that future dictionary compilers can use the theory for both a contemplative and a transformative commitment to the planning and compilation of their dictionaries, the use of data boxes needs to be included in theory-based discussions.
5. Data boxes as dictionary entries
5.1 Data boxes and addressing relations
The addressing structure and various addressing relations in dictionaries are important to identify the scope of each item in a dictionary article and the target of its treatment. According to Hausmann and Wiegand (1989: 328) a treatment unit results "when a form mentioned and information relating to that form are brought together. The relation of form and information is that of topic and comment." The "way in which a form and information relating to that form are brought together is the addressing procedure." Each information item is addressed to a form that is known as its address.
Data boxes are functional constituents of dictionaries and should not be employed as mere procedures of lexicographic face-lifting. They are included in dictionaries as part of the lexicographic treatment procedures. When allocating a data box to a specific search zone cognizance needs to be taken of the specific treatment contributed by the data box. Dictionary users should know exactly what constitutes both the address and the addressing relation of each data box.
To ensure an optimal comprehension of the relevant addressing relation, it is important that the notion of addressing has to be employed in an unambiguous way. In this article the procedures of addressing as discussed in Gouws (2014) will be employed. Wiegand and Gouws (2013) restrict addressing to relations within condensed articles where items display the addressing relations. Wiegand and Gouws (2013: 273) say that there are no addressing relations in non-condensed dictionary articles or in other non-condensed accessible entries. This implies that an item like a lemma sign cannot be addressed by an item text, even if the item text contributes to the treatment of the lemma. In contrast to this approach, Gouws (2014: 183) expands the application of the notion of addressing. The term addressing is used to incorporate both primary addressing which is the traditional procedure prevailing in condensed articles, and secondary addressing to go beyond textual condensation and item status as prerequisites for addressed entries. In accordance with this approach both items and item texts can participate in procedures of addressing. The addressing element and its address do not have to be in the same dictionary article and addressing can occur between different types of constituents of a word list, e.g. also between a phased-in inner text and an item in a dictionary article.
5.2 The position for data boxes and the different types of data box entries
In accordance with the data distribution structure of a specific dictionary the lexicographer has to allocate data-carrying segments to the different search positions in the dictionary. Where a dictionary displays a frame structure the positioning of data in the articles of the word list will be complemented by text constituents or other entries presented in the front and/or back matter sections of that dictionary. As a carrier of text types a dictionary could also include outer texts in its middle matter section.
Dictionaries have different search positions, traditionally ranging from a search zone within a dictionary article to the article as search area and the word list, the largest search position, as search field, cf. Wiegand, Beer and Gouws (2013: 63). Gouws (2018: 228) argued in favour of a further and more comprehensive search position, i.e. the search region. This search position is constituted by all the textual components of a dictionary as a text compound. For a single volume dictionary this is the most comprehensive search position. Although the outer texts of the front and back matter sections of a dictionary fall outside the domain of the search field they are part of the search region of a dictionary. Data boxes typically occur within a word list, that is a search field, of a dictionary. This could be within the central and only word list which is the most frequent occurrence of data boxes, or within any other word list that is part of a word list series of a given dictionary. Looking at data boxes in this article, the focus will only be on those data boxes occurring in a word list, i.e. within the search field of dictionaries. Data boxes in outer texts will not be discussed.
As entries in a search field the status of all data boxes is not the same. Data boxes could be phased-in inner texts, article-internal item texts or mere items occupying a search zone in a dictionary article. These different types of data boxes will be discussed in the subsequent sections.
5.3 Expanded word lists
The data distribution structure of any dictionary determines the way in which the lemmata presenting the macrostructural coverage of the dictionary have to be ordered within the word list of that dictionary. Whether it is a straight alphabetical ordering or an ordering with sinuous lemma files that enables the use of niched and nested lemmata, a word list will consist of a number of article stretches that accommodate articles with the lemmata as their guiding elements.
When planning the data distribution structure of a dictionary lexicographers need to make a decision regarding the type of word list the dictionary will display. This is determined by specific features of the nature of data allocated to the word list. In this regard a distinction is made between a single word list and an expanded word list, cf. Bergenholtz, Tarp and Wiegand (1999: 1766). A single word list contains article stretches but no inserts or phased-in inner texts, whereas an expanded word list also contains article stretches as well as inserts and/or phased-in inner texts. These inserts and phased-in inner texts split sequences of articles within partial article stretches. Therefore an expanded word list is also known as a split word list.
The distinction between inserts and phased-in inner texts is significant for the identification of data boxes.
5.3.1 Distinguishing between inserts and phased-in inner texts
5.3.1.1 Inserts
According to the Wörterbuch zur Lexikographie und Wörterbuchforschung/Dictionary of Lexicography and Dictionary Research (Wiegand et al. 2017), (henceforth abbreviated as WLWF) an insert is a text or text part that is inserted into the word list of a dictionary. It is an immediate constituent of the dictionary as a text compound. Inserts often are sections of photos, inserted between two article stretches or between two pages of an article stretch. In the Merriam-Webster's Advanced Learner's English Dictionary (Perrault 2008), (henceforth abbreviated as MWALD), the article stretch of the letter M is split between the lemmata mascot and masculine by an insert titled Color Art. This insert, with its own table of contents, contains pictures of themes like colours, vegetables, landscapes, gems and jewellery and clothing. These pictures do not adhere to the alphabetical ordering within the article stretch and although it splits the word list this insert is not an immediate constituent of either the specific article stretch or the word list. It is an immediate constituent of the dictionary as text compound and carrier of text types. Consequently inserts cannot be regarded as a type of data box or the type of data box discussed in this article.
The form of inserts sometimes resemble that of data boxes, e.g. the section on birds in an insert from the MWALD contains pictures of a variety of birds and the data box occurring in the article of the lemma deer, cf. figure 18 in paragraph 5.5.2.1, contains a number of pictures of different types of deer. Although both these text constituents are carriers of pictures, the insert is a different type of lexicographic text and will not be discussed any further in this article.
5.3.1.2 Phased-in inner texts
Phased-in inner texts occur in expanded word lists where they split the article stretches, resulting in internally expanded article stretches (Bergenholtz, Tarp and Wiegand 1999: 1766). The phased-in inner texts typically contain data relevant to a lemma in close proximity within the same article stretch and often also to other lemmata occurring in remote articles. The data in the phased-in inner texts can also have a more general relevance to the specific lemma or might link thematically with it. Phased-in inner texts often have an inner text title that can concur, but not necessarily, with the lemma of an article in its proximity. This title could also identify the more general nature of the data in the specific text. These texts are usually typographically distinguishable from default articles as constituents of a word list by being framed or presented with a coloured background. Examples will be provided in a subsequent section of this article.
Article-internal data boxes and phased-in inner texts sometimes show strong resemblances but the nature of a specific box as a text constituent of the word list determines whether it has to be regarded as an article-internal box or a box presented as phased-in inner text.
5.4 Article-internal data boxes
5.4.1 Items and item texts
One of the most frequent occurrences of data boxes is within dictionary articles. As constituents of articles data boxes do not form part of the obligatory micro-structure but rather enrich the obligatory microstructure, resulting in an extended obligatory microstructure. Data boxes in dictionary articles mostly contain text data but they can also display non-textual data. Data boxes are not default entries in any article but their use can be regarded as an extended treatment procedure. They can either contain items or item texts. Wiegand and Smit (2013: 153) distinguish as follows between items and item texts:
An item is a functional text segment without the status of a sentence but with the status of a text segment which is given as a discernible item form assigned with at least one genuine function, the latter being precisely such that a user can obtain knowledge about the item's subject as lexicographical information.
An item text is a functional text segment with item function and text constituent status exhibiting a complete and distinct natural-language syntactical structure and consisting of at least one sentence.
As constituents of dictionary articles data boxes may contain data presented in either condensed or non-condensed format. The articles in figure 1, a partial article stretch from the monolingual Afrikaans learner's dictionary Basiswoordeboek van Afrikaans (Gouws et al. 1994), (henceforth abbreviated as BW) contain two data boxes with items giving the pronunciation of the word represented by the lemma of the specific article. This dictionary only gives pronunciation guidance for a limited number of selected lemmata. It is not part of the obligatory microstructure and when pronunciation guidance is regarded as necessary, it is presented in a data box accommodated in the final slot of the article. The entries "Uitspraak 'gemie'" (= Pronunciation 'gemie') and "Uitspraak 'sjirurg'" (= Pronunciation 'sjirurg') are condensed forms and thus items.
The data box in figure 2 from the Junior Tweetalige Skoolwoordeboek/Junior Bilingual School Dictionary, (Stoman et al. 2018), (henceforth abbreviated as JBS) contains a sentence which is an entry given in non-condensed form. This entry therefore is an item text.
Whether entries are items or item texts may have implications for the addressing relations in an article. This will be discussed in a further section of this article.
5.4.2 Positioning data boxes within dictionary articles
Data boxes are functional dictionary entries because they contribute to achieving the genuine purpose of the dictionary in which they occur. That implies that from the data on offer in a data box users must be able to retrieve information that can assist them in finding a solution to the problem that initiated the specific dictionary consultation procedure. Because data boxes result from extended treatment procedures and are usually not entries belonging to the obligatory microstructure of a dictionary, users will not know beforehand whether an article contains a data box. That is why it is important that these boxes need to be clearly marked as framed or coloured text constituents. Dictionary articles have no fixed slot reserved for data boxes. When planning the data distribution structure of a dictionary lexicographer's need to decide on the slots in dictionary articles that could accommodate search zones populated by data boxes. Data boxes could be placed in different text positions in dictionaries, cf. Taljard et al. (2014: 698). They could be included within the comment on form or comment on semantics or in an alternative position, e.g. as precomment or postcomment.
5.4.2.1 Data boxes at the end of an article
One of the most typical positions allocated to data boxes, cf. Gouws and Prinsloo (2010), is a slot at the end of the article. In such a position the data box often falls beyond the scope of either the comment on form or the comment on semantics. As postcomment the data box is in a position of salience - further accentuated by its frame or colouring. Figure 3 shows the article of the lemma sign especially in the Oxford Advanced Learner's Dictionary of Current English (Turnbull 2010), (henceforth abbreviated as OALD):
The obligatory microstructure ends with the items in the third subcomment on semantics. The lexicographers have felt the need to present the users with additional guidance regarding the use of the words especially and specially. The data box containing this data has the title "Which Word?" and is presented after the comment on semantics as a postcomment to the article. Another example of a box presented as postcomment in the same dictionary can be found in the article of the lemma sign restaurant, figure 4. A type of data box frequently given in this dictionary contains collocations, but not necessarily collocations in which the word represented by the lemma functions as either base or collocator, but rather collocations applicable in the semantic domain of the word represented by the lemma sign. The user gets assistance regarding typical collocations used when dining in a restaurant:
The OALD presents the entries in data boxes against a blue background. These data boxes can easily be identified by the users of this dictionary.
There is no restriction on the number of data boxes per article, but lexicographers need to be careful not to have a data box overload that could diminish the emphasis on these boxes. An inflation of data boxes should therefore be avoided, but even more than one clearly marked data box per article should still be in order, as seen in figure 5, the article of the lemma sign school in the OALD. The two boxes "British/American" and "Grammar Point" are clearly identifiable and can enhance the nature and extent of the lexicographic treatment in this article.
Where a data box is presented as postcomment in the article of a lemma representing a polysemous lexical item it is not always clear whether the treatment presented in the box is directed at only one or more senses or at all the senses of the word. This problem will be elaborated on in section 5.4.2.4.
5.4.2.2 Data boxes at the beginning of the article
The lemma sign of an article is part of the main outer access structure of the dictionary and a guiding element of the specific article. Irrespective of the type of information a user wants to retrieve from a dictionary article as search area the access to that item, especially in a printed dictionary, proceeds via the lemma sign onto the search paths of the inner access structure. Items positioned in search zones in close proximity of the lemma are in salient positions. The framed or coloured appearance of data boxes adds focus to their occurrence as text constituents of an article and if such a box is awarded a position close to the lemma sign it further elevates the salience of the data in the box.
The Macmillan Phrasal Verbs Plus (Rundell 2005), (henceforth abbreviated as MPVP) uses data boxes in a slot close to the beginning of an article, to provide an overview of the senses where the phrasal verb represented by the lemma sign has five or more than five senses. This box differs from other boxes because it does not contain the kind of data typically allocated to data boxes. It displays items conveying the menu of the comment on semantics and they function as navigational entries in this article. Alternative strategies for the provision of such navigational guidance could for instance be shortcuts, signposts and guidewords and will be discussed in detail in Part 2 of this series. The box as seen in figure 6 functions in such an article as a precomment.
Data boxes are also included as precomments of articles in the Macmillan English Dictionary (Rundell 2007), (henceforth abbreviated as MED). In figure 7, the article of the lemma sign above, the data box contains data regarding the use of the word above in its occurrence in different parts of speech. It makes the user aware of the differences between these uses.
To ensure that the target user of this learner's dictionary will focus on the differences between the uses of the word, this data can at best be presented in a precomment instead of being subsumed under the cotextual items in different comments or subcomments on semantics of one of the three partial articles of this twofold complex dictionary article, cf. Wiegand and Gouws (2011: 242).
Because the beginning of an article is a significant position of salience in a dictionary article lexicographers should carefully consider the type of data boxes to include in that search zone.
5.4.2.3 Data boxes as article windows
Lexicographers often have innovative ideas regarding the way of presenting data in their dictionaries. In the OALD several types of data boxes are used, with some types reserved for specific types of data. An article window is a type of data box reserved for a single type of data, i.e. word families, as seen in figure 8:
In the front matter text "Key to dictionary entries" it is said that: "Word families show words related to the headword." Although articles could in principle have windows in different article positions, e.g. top right, top centre, top left, middle right, middle centre, middle left, bottom right, bottom centre and bottom left, the OALD primarily uses the top right corner for its window data boxes. However, the layout of a dictionary article on the page could also have an influence on the position of the window. The editors of the OALD are consistent in always placing data boxes presented in article windows in the top right corner of a text block, albeit not necessarily of the article. Where an article commences at the bottom of a column there could be a lack of space for a window in the top right corner of the article, as seen in figure 9.
However, the window is then positioned in the top right corner of the text block, containing the remainder of the article, that starts in a new column, as seen in figure 10.
Technically such a window occupies the right centre of the article. From a layout perspective it could be argued that the OALD always presents its windowed data boxes in the top right corner of a text block, preferably but not always the top right corner of the article.
A brief identification of word families as found in the article windows can be valuable assistance to the target users of this dictionary. Users should be aware of this assistance but unfortunately the OALD does not provide an outer text in the front matter section with a list of articles that contain these windows. In spite of the focus that a data box puts on this data, there is no defined search path besides the main alphabetical outer access structure to guide users to these articles that contain article windows. This lack of predictable access impedes the added value of these article windows.
5.4.2.4 Data boxes within a comment of an article
Whether an article-internal data box contains an item or an item text, the contents of that data box is presented as part of a treatment procedure. This procedure is directed at one or more specific treatment units that constitute the address within this procedure of addressing. The positioning of article-internal data boxes directly reflects the relevant addressing relations in which data boxes can become involved.
Although lemmatic addressing, i.e. with the lemma as address, is the most frequently used addressing procedure in dictionaries, other types of addressing also prevail, especially non-lemmatic addressing. Various aspects of addressing are dealt with in Hausmann and Wiegand (1989), Louw and Gouws (1996), Gouws and Prinsloo (2005), Wiegand (2006; 2011) and Gouws (2014). Lexicographers utilise data boxes to emphasise certain entries not accounted for by items in search zones of the obligatory microstructure of a dictionary. These items or item texts do not always have the lemma as address, but often occur within one of the comments of an article, especially the comment on semantics or a subcomment on semantics, where they participate in relations of non-lemmatic addressing. A less optimal article-internal positioning of a box of which the entry or entries are not addressed at all the senses of the word represented by the lemma sign of the article may diminish the added value the data box is supposed to have. In figure 11 from the Handwoordeboek van die Afrikaanse Taal (HAT) (Odendal and Gouws 2005) the data box is included as postcomment at the end of the article. The contents of the box only applies to the use of the word instansie in its second and third senses. From this presentation it is not clear that the box is not addressed at the first sense.
Figure 12 is a partial article of the lemma open2from the Longman Exams Dictionary (Summers 2006), (henceforth abbreviated as LED). This article contains two data boxes, so-called study notes. Both these data boxes are presented within single subcomments on semantics for the first and the second sense of the polysemous word open. By positioning them there the lexicographer ensures that the user can know what the exact address of the data box is:
In the Longman South African School Dictionary (Bullon et al. 2007, (henceforth abbreviated as LSASD)) the article of the lemma sign name1has three subcomments on semantics. The thesaurus data box is positioned at the end of the first subcomment on semantics. The thesaurus guidance in the data box is only applicable to the first sense of the word name.
Figure 14 from BW shows a data box that only has the first sense of the word opmerking as its address. Such a procedure of immediate addressing is to the benefit of the target user of the dictionary and demands less dictionary using skills compared to correctly interpreting the address of a data box that is not positioned in close vicinity to its address, even if the user was able to identify the appropriate sense:
Where the treatment in a data box is directed at only one of the senses of a polysemous word or at only one of the items in the article and the data box is not positioned in such a way that an immediate addressing relation is possible, the lexicographer should clearly indicate what the address of the contents of the data box is. Such an approach is seen in figure 15, the article of the lemma mad in the Oxford Afrikaans-Engels/English-Afrikaans Skoolwoordeboek/School Dictionary (Pheiffer 2007), (henceforth abbreviated as OSD):
In this article with its four subcomments on semantics, the data box has been included as postcomment but it is clearly stated that it is addressed at the first sense.
Where a word can be used in more than one part of speech, the lexicographic treatment typically results in a complex article with a partial article for the occurrence of each of these parts of speech (Wiegand and Gouws 2011: 243). Data boxes could then be positioned in a search zone of one of the partial articles so that the other part of speech occurrence of the word falls beyond the scope of the data box. This can be seen in figure 16 from BW where the data box is positioned at the end of the first partial article of the article with the lemma smaak as guiding element.
5.5 Phased-in inner texts as data boxes
5.5.1 Article-external text boxes
Data boxes can also be accommodated in the word list of dictionaries as phased-in inner texts. These data boxes are immediate constituents of the article stretches of the word list and function as article-external data carriers. Data boxes presented as phased-in inner texts typically have a connection with a lemma that is the guiding element of an article occurring in the specific article stretch into which the data box is phased in. These data boxes can be items or item texts and participate in either primary or secondary addressing relations. In addition to having the lemma that is in close proximity as address, these data boxes can also participate in relations of remote addressing, cf. Louw and Gouws (1996), where one or more lemmata in the same or often in other article stretches can be the address. As is the case with article-internal text boxes, different types of data can be presented in these data boxes, cf. Wiegand et al. (2017: 140-144 (WLWF)).
Phased-in inner texts could be constituents of the word list of a dictionary with a single alphabetical macrostructure or constituents of different word lists of dictionaries with poly-alphabetical macrostructures with vertical or horizontal parallel alphabetical access structures, cf. Wiegand (1989: 402) and Wiegand and Gouws (2013: 88). In the remainder of this section the focus will primarily be on phased-in inner texts in single macrostructures but reference will briefly be made to their occurrence in dictionaries with poly-alphabetical macrostructures with vertical parallel alphabetical access structures.
5.5.2 Phased-in inner texts in the primary macrostructure
In an expanded word list different types of phased-in inner texts can be included to split the article stretches.
5.5.2.1 Data boxes phased out of the article
In paragraph 5.4.2.3 it was mentioned that the layout of a dictionary page could influence the positioning of text boxes presented as article windows. In a comparable way the structure and layout of a dictionary article and the physical size of a specific item could lead to such an item not being included as micro-structural constituent but rather in an article-external data box. This is where a phased-in inner text is the result of an item phased out of an article and phased into the article stretch as a data box.
Due to the position of an article in a column and on a page and due to their size pictorial illustrations do not always fit into the boundaries of an article as search area. The application of a well-defined data distribution structure may then lead to a situation where such a pictorial illustration is phased out of the article and presented within a data box included as phased-in inner text.
The MWALD often contains pictorial illustrations as items in its articles, as can be seen in figure 17, the article of the lemma glove:
No pictorial illustration is presented within the borders of the article of the lemma sign deer in the MWALD. However, an illustration does occur on the same page, in an article-external position, as can be seen in figure 18 where the illustration is entered across two columns and splits the partial article stretch between the articles of the lemmas defamatory and defame:
It could have been problematic for the lexicographers to fit this illustration into the article of the lemma deer. Consequently it has been phased out of the article and positioned as a phased-in inner text in the article stretch, where its title has the same form as the article of the lemma deer. Because the pictorial illustration is in close proximity of the article of the lemma deer, this article has no reference to the pictorial illustration.1
In dictionaries a distinction can be made between single and synopsis articles, cf. Bergenholtz, Tarp and Wiegand (1999: 1780). The treatment in a single article is directed only at the lemma of that article, whereas the treatment in a synopsis article also contains data relevant for the treatment of the lemmata of other articles. Data boxes also have a single or a synopsis character. This applies to article-internal as well as article-external data boxes. Figure 19, the article for the lemma lend in the Tweetalige aanleerderswoordeboek/Bilingual Learner's Dictionary (Du Plessis 1993), (henceforth abbreviated as TAW), has an article-internal data box presented as postcomment. The contents of this data box apply to the lemma lend but it is also remotely addressed at the lemma borrow. Figure 20 shows the article of the lemma borrow with an item giving a cross-reference to lend.
The data box in the article of the lemma lend is a synopsis data box. In a similar way the data box titled deer is a synopsis data box. The pictures are also relevant for the treatment of lemmata like moose, elk and caribou. Consequently the articles of these lemmata have an item giving a cross-reference "see picture at DEER".
Positioning the contents of the data box deer not within the article but as an article-external phased-in inner text, can probably best be motivated on article and page layout grounds. A similar use of data boxes where the data have been phased out of an article and into a data box functioning as phased-in inner text, is found in the Cambridge International Dictionary of English (Procter 1995), (henceforth abbreviated as CIDE). Figure 21 shows the framed data box Molluscs presented as a phased-in inner text. The contents of this box could have been included in the nearby article of the lemma mollusc. The layout of the column might have been disturbed by this illustration and consequently it was phased-out into a data box in the partial article stretch but still in close vicinity of the lemma sign. This is also a synopsis data box that functions as the cross-reference address for cross-reference items in the articles of lemmata like cuttle fish, octopus and snail:
Phasing-out procedures do not only target non-boxed data that could have been included in a search zone of an article and allocate them to an article-external data box. These procedures can also target data boxes that could have had an article-internal position and phase them out to function as article-external data boxes and phased-in inner texts. The OALD frequently includes a text box containing synonyms in a postcomment position of an article, as can be seen in figure 22, the article of the lemma painful:
This can be regarded as the default positioning of a data box that contains synonyms. The data box for synonyms is often phased out of the article and positioned as a data box and phased-in inner text in the textual position immediately preceding the article. This is probably due to article and page layout considerations, a column break and the approach not to allow column or page breaks to divide a data box into two sections but always to present such a data box as an uninterrupted text block. This can be seen in figure 23, the article of the lemma surprise:
The biggest section of the article of the lemma surprise appears in the left column with a brief section of this article continuing in the right column. Had this section also been included in the left column there would probably not have been room for an uninterrupted data box as postcomment in that column. Consequently the data box was phased out to an article-external position, preceding the article. This data box is not positioned as precomment because it lies outside the article borders.
Because the planned data distribution structure of a dictionary needs to be executed in a meticulous and consistent way, it is not plausible to deviate from such a structure for column or page break or article or page layout reasons. Such a deviation impedes the access of users to the required data. The structural inconsistency resulting from the phasing out of items to article-external data boxes can be seen in the treatment of the lemma save in the OALD. In the OALD synonyms are frequently provided in data boxes, as seen in the treatment of painful. Irrespective of the degree of complexity of an article (whether it is a single or an n-fold complex article) or the number of senses treated in one or more subcomments on semantics, article-internal data boxes containing synonyms are presented as postcomments. Although such a positioning of the data box may cause addressing uncertainty in complex articles or articles with polysemous lexical items as lemmata, knowledgeable users will become familiar with this positioning of data boxes if this execution of the data distribution structure is done in a consistent way.
Column and page breaks result in deviations of this execution of the default data distribution structure. The treatment of the lemma save is presented in a threefold complex article with partial articles for the use of the word save as different parts of speech, namely as verb, noun, preposition and conjunction. The partial article treating the occurrence of save as a verb accounts for eight polysemous senses of this word, presented in different subcomments on semantics. The treatment is interrupted by a column and page break within the eighth subcomment on semantics. For the senses presented in the first two subcomments on semantics synonyms are provided in data boxes. The data box containing the synonyms for the first sense is included article-internally, according to the default data distribution of this type of text constituent, as a postcomment. However, the data box containing synonyms for the second sense has been phased out to a position immediately preceding the article of the lemma save as an article external phased-in inner text. This can be seen in figure 24 that shows the article as it is spread over the right column of the first and the left column of the second page:
Successfully accessing this data will be challenging for even a knowledgeable user of this dictionary. This is a typical situation where procedures in the lexicographic practice, i.e. allowing column and page breaks to impede the execution of the default data distribution structure, has resulted in theory-determined dictionary structure problems. A more user-friendly way of dealing with these two data boxes would have been to either add them both as postcomments (reflecting the order of the senses at which they are addressed) or, even better, include each data box in a slot in the relevant subcomment on semantics. This would have enabled procedures of immediate addressing that would have assisted users in a quicker and better retrieval of information.
In some articles the inconsistency in the positioning of synonym data boxes in the OALD on column and page break grounds, results in such an article-internal data box not being included as the default postcomment but rather within the comment on semantics. The lemma reason has a single complex article with partial articles for its occurrence as noun and as verb. The article is interrupted by a column and page break, as seen in figure 25:
The comment on semantics of the partial article in which the occurrence as noun is treated, makes provision for four polysemous senses of this word. A data box is provided that contains synonyms for the first sense of this word. In order to present an uninterrupted text block the data box containing synonyms is positioned within the comment on semantics of the partial article in which the occurrence of reason as a noun is treated. It is positioned at the end of the first column on the first page on which the article is given. The data box occurs within the subcomment on semantics in which the second sense is treated, even though the synonyms are addressed at the first sense of the word. This positioning defies logical and consistent addressing relations.
5.5.2.2 Article-external data boxes resembling articles or article-internal items
Data boxes included in the word list as phased-in inner texts are often inserted between two other articles in a partial article stretch where it adheres to the alphabetical ordering. These data boxes typically have a guiding element that looks like a lemma and the box contains a rudimentary treatment of that word. In the TAW the word fridge had not been selected as a lemma candidate. However, the lexicographer must have felt the need to make the users of this learner's dictionary aware of that informal English word. Consequently, a data box was included as a phased-in inner text and inserted in its alphabetical position in the article stretch between the articles of the lemmata Friday and friend, as seen in figure 26, with the frame clearly identifying it as a data box and not a default article:
Figure 27, a partial article stretch from Groot Woordeboek/Major Dictionary (Eksteen et al. 1997); (henceforth abbreviated as GW), contains the data box with percentage point as its guiding element. This box follows the article niche attached to the article of the lemma percentage. This niche also contains the sublemma percentage point in a condensed format. In the niche the treatment of the lemma is restricted to an item giving a translation equivalent. The lexicographer wants to increase the assistance to users regarding this lemma and consequently employs the phased-in data box to supply the expression percentage point with a paraphrase of meaning.
Data boxes do not always look like articles but can occur in the alphabetical position of a word that has not been included as lemma, in order to make the user aware of some relevant feature of that word. In Afrikaans the word huidiglik (=presently) is often used. However, from a linguistic perspective the use of this word is not approved. The word does not qualify for inclusion as a lemma, but the lexicographers of the monolingual Afrikaans school dictionary the Oxford Afrikaanse Skoolwoordeboek (Louw 2012), (henceforth abbreviated as OSW) would like to make their users aware of the fact that the word should not be used. The word tans should rather be used. In the alphabetical slot where huidiglik would have been entered had it been a lemma in this dictionary, the lexicographers include an article-external data box, cf. figure 28, to sensitise users that they should not use the word huidiglik.
The data box in figure 28 is not a postcomment in the article of the lemma huidige but rather a phased-in inner text.
Article-external data boxes often include data that do not represent a data type that belongs to the default microstructural items but it does add to the treatment of a given lemma or lemma cluster. Figure 29 presents a partial article stretch from HAT:
In the comment on form of the article of the lemma horlosie (watch) it is indicated that oorlosie is a variant form of horlosie. Attached to the article of this lemma is a lemma cluster, presented as a first level nest that includes a condensed presentation of compounds with horlosie- as first stem. Between this nest and the following main lemma a data box has been inserted with guidance regarding the formation of compounds with horlosie- as first stem. Although this data is relevant to the main lemma horlosie- and to the sublemmata presented in the nest, the data box is positioned outside the article of the main lemma as well as the nest of sublemmata and therefore it is a phased-in inner text.
5.5.2.3 Other article boxes included as phased-in inner texts
A variety of other types of data boxes also function as phased-in inner texts in dictionaries. A typical feature of many of these data boxes is their synopsis character whilst the data presentation in others complements and expands the default data coverage of a specific lemma. These data boxes convey data regarded by the lexicographer as important enough to include them in salient search venues like data boxes. The added value of these data boxes is unfortunately too often impeded by insufficient access guidance.
In close proximity of the article of the lemma plural in CIDE one finds the data box titled "Plural of nouns", presented in figure 30:
The treatment in this data box is not addressed at any single lemma but it adds value to the treatment of all nouns that take plural. The problem is that it is very difficult for users in need of this guidance to know where to find the help. CIDE has a back matter text that provides an alphabetical index with relevant page numbers of all pictures, language portraits and lists of false friends included in the word list. The list includes an entry "Plurals" but no entry "Plural of nouns", the title of the data box in figure 30. It will remain a challenge for the target users of this dictionary to optimally benefit from this data box. They will probably only have access to this data box if they accidentally consult that page, seeing that the lemma plural is on the previous page and its article has no cross-reference to the data box.
Having consulted the lemmata meet and meeting in the CIDE a user has to turn the page to find the data box "Meeting someone", given in figure 31:
This data box contains pragmatic and cultural guidance that could assist the envisaged target users of this dictionary in their daily communication. Skilled users will be able to access this data box via the back matter list. However, for the user not aware of that list it would have been better if this data box could have been positioned on the same page where the lemmata meet and meeting appear.
On the same page in CIDE where the lemma dash is treated a data box has been presented that offers valuable complementary assistance regarding the use of a dash, cf. figure 32:
The contents of a data box like this one can hardly be included in the article of the corresponding lemma. Data boxes like these elevate the quality of the lexicographic treatment.
Even if an article in a learner's dictionary displays an extended obligatory microstructure lexicographers have to restrict the extent of the data presented in the different search zones and should refrain from procedures of data overload. If lexicographers want to respond to the needs of the users of a learner's dictionary, like CIDE, for some linguistic guidance typically contained in text books, they can use data boxes included as phased-in inner texts to convey this kind of data. Figure 33, a partial article stretch from CIDE, contains articles of the lemmata homograph and homophone. In each one of these articles there is an item giving a cross-reference to the language portrait (LP) Homophones and homographs.
This language portrait is presented as the data box seen in figure 34. This data box can also be accessed via the index in the back matter text. It has a synopsis character that could assist users in clearly distinguishing between homophones and homographs.
5.5.3 Phased-in inner texts in the secondary constituent of a parallel macro-structure
Dictionaries can have more than one word list and therefore more than one macro-structure. More than one macrostructure could prevail within the same alphabetical constituent of a dictionary. One such type identified by Wiegand (1989: 402) and Wiegand and Gouws (2013: 88) is the poly-alphabetical macrostructures with vertical parallel alphabetical access structures. The Reader's Digest AfrikaansEngelse Woordeboek/English-Afrikaans Dictionary (Grobbelaar 1987), (henceforth abbreviated as RWD), displays these macrostructures. The primary macrostructure of this dictionary is presented in two central columns on each page. An additional column on the left and an additional column on the right of the two central columns constitute a secondary macrostructure. The partial article stretch of the secondary macrostructure on each page falls within the alphabetical domain of the partial article stretch of the primary macrostructure on the same page. The RWD is an expanded version of a previously published bilingual dictionary. The primary macrostructure is an unchanged version of that of the previous dictionary. The secondary macrostructure is constituted by new text constituents. In the secondary word list there are articles that have a selection of lemmata from the primary macrostructure as guiding elements. A different and innovative treatment (not to be discussed here) has been executed in these articles. The secondary macrostructure displays an expanded word list with partial article stretches split by phased-in inner texts, as seen in figure 35:
The text boxes presented as phased-in inner texts are titled Words in action. They are addressed at some of the source and target language items in the articles of the primary macrostructure and they contain different types of data, e.g. pragmatic, usage, linguistic and lexical guidance.
The data boxes help to introduce new comments to enhance the quality of the original dictionary.
Conclusion
Data boxes occur frequently and in diverse ways in dictionaries. This is especially the case in printed dictionaries, although some electronic dictionaries, especially those that are based on printed dictionaries, also employ this type of lexicographic entry. Although various aspects of the use of data boxes have been discussed in metalexicographic literature, much still needs to be done in this regard. This paper focused on what data boxes are, identified them as a type of lexicographic entry and indicated where they are positioned in dictionaries and that they should be used in such a way that they add value to dictionaries. This can serve as an aid for future lexicographers who wish to employ data boxes in their dictionaries.
Endnote
1 The value of a picture presenting different types of deer (but not all types) is not discussed here. The decision to give a pictorial illustration rests with the lexicographer. Therefore it cannot be expected that a specific word will be illustrated or illustrated in the same way in all dictionaries. For example, the online version of the MED does not contain such an illustration.
Acknowledgement
This work is based on the research supported in part by the National Research Foundation of South Africa (Grant specific unique reference numbers (UID) 85434 and (UID) 8576). The Grantholders acknowledge that opinions, findings and conclusions or recommendations expressed in any publication generated by the NRF supported research are that of the authors, and that the NRF accepts no liability whatsoever in this regard.
References
Dictionaries
BW = Gouws, R., I. Feinauer and F. Ponelis. 1994. Basiswoordeboek van Afrikaans. Pretoria: J.L. van Schaik.
CIDE = Procter, P. (Ed.). 1995. Cambridge International Dictionary of English. Cambridge: Cambridge University Press.
GW = Eksteen, L.C. et al. (Eds.). 199714. Groot Woordeboek/Major Dictionary. Cape Town: Pharos.
HAT = Odendal, F.F. and R.H. Gouws. 20055. Verklarende Handwoordeboek van die Afrikaanse Taal. Cape Town: Pearson Education South Africa.
JBS = Stoman, A. et al. (Eds.). 2018. Junior Tweetalige Skoolwoordeboek/Junior Bilingual School Dictionary. Cape Town: Pharos.
LED = Summers, D. (Ed.). 2006. Longman Exams Dictionary. Harlow: Pearson Education.
LSASD = Bullon, S. et al. (Eds.). 2007. Longman South African School Dictionary. Harlow: Pearson Education.
MED = Rundell, M. (Ed.). 20072. Macmillan English Dictionary for Advanced Learners. Oxford: Macmillan.
MPVP = Rundell, M. (Ed.). 2005. Macmillan Phrasal Verbs Plus. Oxford: Macmillan Education. MWALD = Perrault, S.J. (Ed.). 2008. Merriam-Webster's Advanced Learner's English Dictionary. Springfield, Massachusetts: Merriam-Webster.
OALD = Turnbull, J. (Ed.). 20108. Oxford Advanced Learner's Dictionary of Current English. Oxford: Oxford University Press.
OSD = Pheiffer, F. et al. (Eds.). 2007. Oxford Afrikaans-Engels/English-Afrikaans Skoolwoordeboek/School Dictionary. Cape Town: Oxford University Press Southern Africa.
OSW = Louw, P. (Senior Editor). 2012. Oxford Afrikaanse Skoolwoordeboek. Cape Town: Oxford University Press Southern Africa.
RWD = Grobbelaar, P. 1987. Reader's Digest Afrikaans-Engelse Woordeboek/English-Afrikaans Dictionary. Cape Town. The Reader's Digest Association, South Africa (Pty) Ltd.
TAW = Du Plessis, M. 1993. Tweetalige aanleerderswoordeboek/Bilingual Learner's Dictionary. Cape Town: Tafelberg.
WLWF = Wiegand, H.E., M. Beißwenger, R.H. Gouws, M. Kammerer, A. Storrer and W. Wolski (Eds.). 2017. Wörterbuch zur Lexikographie und Wörterbuchforschung/Dictionary of Lexicography and Dictionary Research. Vol. 2. Berlin/New York: Walter de Gruyter.
Other references
Bergenholtz, H., S. Tarp and H.E. Wiegand. 1999. Datendistributionsstrukturen, Makro- und Mikrostrukturen in neueren Fachwörterbüchern. Hoffmann, L. et al. (Eds.). 1999. Fachsprachen. Ein internationales Handbuch zur Fachsprachenforschung und Terminologiewissenschaft/ Languages for Special Purposes. An International Handbook of Special-Language and Terminology Research, Bd./Vol. 2: 1762-1832. Berlin: De Gruyter. [ Links ]
Gouws, R.H. 2014. Expanding the Notion of Addressing Relations. Lexicography: Journal of ASIALEX 1(2): 159-184. [ Links ]
Gouws, R.H. 2018. Expanding the Data Distribution Structure. Lexicographica 34: 225-237. [ Links ]
Gouws, R.H. and D.J. Prinsloo. 2005. Principles and Practice of South African Lexicography. Stellenbosch: SUN PReSS, AFRICAN SUN MeDIA. [ Links ]
Gouws, R.H. and D.J. Prinsloo. 2010. Thinking out of the Box - Perspectives on the Use of Lexicographic Text Boxes. Dykstra, A. and T. Schoonheim (Eds.). 2010. Proceedings of the XIV Euralex International Congress, Leeuwarden, 6-10 July 2010: 501-511. Leeuwarden: Fryske Akademy. [ Links ]
Gouws, R.H. and S. Tarp. 2017. Information Overload and Data Overload in Lexicography. International Journal of Lexicography 30(4): 389-415. [ Links ]
Gouws, R.H. et al. (Eds.). 2013. Dictionaries. An International Encyclopedia of Lexicography. Supplementary Volume: Recent Developments with Focus on Electronic and Computational Lexicography. Berlin/New York: De Gruyter. [ Links ]
Hausmann, F.J. and H.E. Wiegand. 1989. Component Parts and Structures of Monolingual Dictionaries: A Survey. Hausmann, F.J. et al. 1989-1991: 328-360.
Hausmann, F.J. et al. (Eds.). 1989-1991. Worterbücher. Dictionaries. Dictionnaires. An International Encyclopedia of Lexicography. Berlin: Walter de Gruyter. [ Links ]
Louw, P.A. and R.H. Gouws. 1996. Lemmatiese en nielemmatiese adressering in Afrikaanse verta-lende woordeboeke. Suid-Afrikaanse Tydskrif vir Taalkunde 14(3): 92-100. [ Links ]
Taljard, E., D.J. Prinsloo and R.H. Gouws. 2014. Text Boxes as Lexicographic Device in LSP Dictionaries. Abel, A., C. Vettori and N. Ralli (Eds.). 2014. Proceedings of the 16th EURALEX International Congress: The User in Focus, Bolzano/Bozen, Italy, 15-19 July 2014: 697-705. Bolzano/ Bozen: EURAC. [ Links ]
Tarp, S. 2004. Basic Problems of Learner's Lexicography. Lexikos 14: 222-252. [ Links ]
Wiegand, H.E. 1989. Aspekte der Makrostruktur im allgemeinen einsprachigen Wörterbuch: alphabetische Anordnungsformen und ihre Probleme. Hausmann, F.J. et al. 1989-1991: 371-409.
Wiegand, H.E. 1996. Das Konzept der semiintegrierten Mikrostrukturen. Ein Beitrag zur Theorie zweisprachiger Printwörterbücher. Wiegand, H.E. (Ed.). 1996. Wörterbücher in der Diskussion II: 1-82. Tübingen: Max Niemeyer. [ Links ]
Wiegand, H.E. 2006. Adressierung in Printwörterbüchern. Präzisierungen und weiterführende Überlegungen. Lexicographica 22: 187-261. [ Links ]
Wiegand, H.E. 2011. Adressierung in der ein- und zweisprachigen Lexikographie. Eine zusammenfassende Darstellung. Kürschner, W. and M. Ringmacher (Eds.). 2011. Aus Ost und West: 109-234. Frankfurt: Peter Lang. [ Links ]
Wiegand, H.E., S. Beer and R.H. Gouws. 2013. Textual Structures in Printed Dictionaries. An Overview. Gouws, R.H. et al. (Eds.). 2013: 31-73.
Wiegand, H.E. and R.H. Gouws. 2011. Theoriebedingte Wörterbuchformprobleme und wörter-buchformbedingte Benutzerprobleme I: Ein Beitrag zur Wörterbuchkritik und zur Erweiterung der Theorie der Wörterbuchform. Lexikos 21: 232-297. [ Links ]
Wiegand, H.E. and R.H. Gouws. 2013. Addressing and Addressing Structures in Printed Dictionaries. Gouws, R.H. et al. (Eds.). 2013: 273-314.
Wiegand, H.E and M. Smit. 2013. Microstructures in Printed Dictionaries. Gouws, R.H. et al. (Eds.). 2013: 149-214.
* This is the first in a series of three articles dealing with various aspects of lexicographic data boxes.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
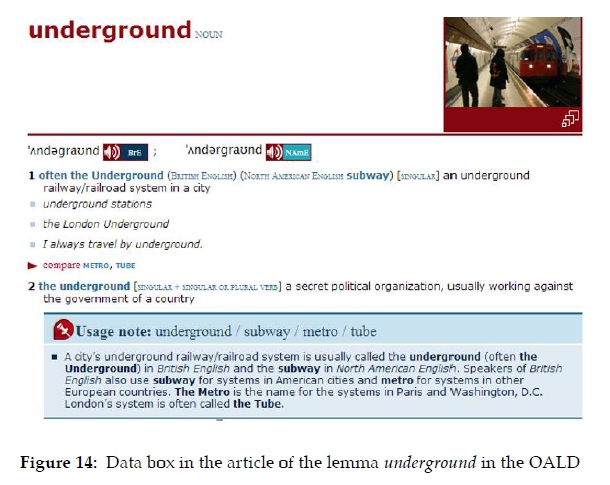{kind=link}
{kind=link}
{kind=link}
{kind=link}
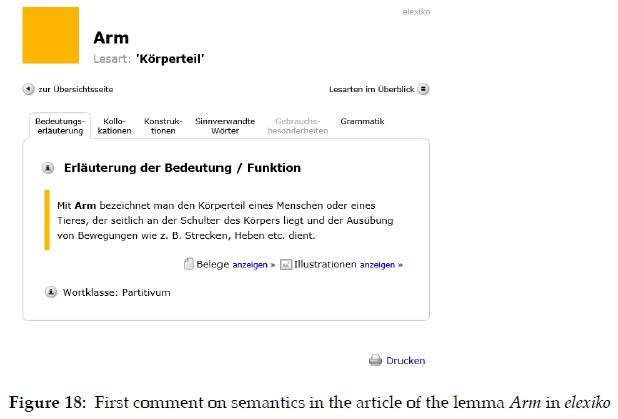{kind=link}
{kind=link}
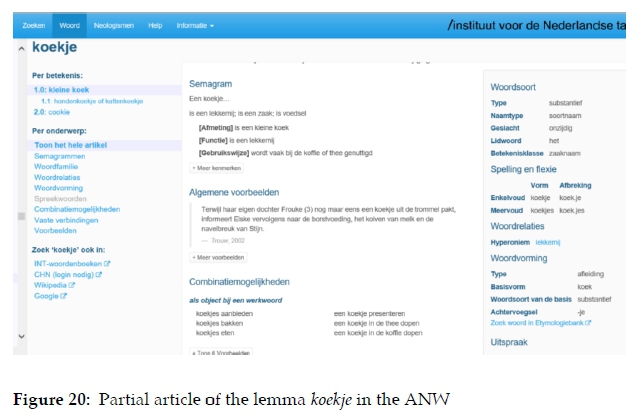{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
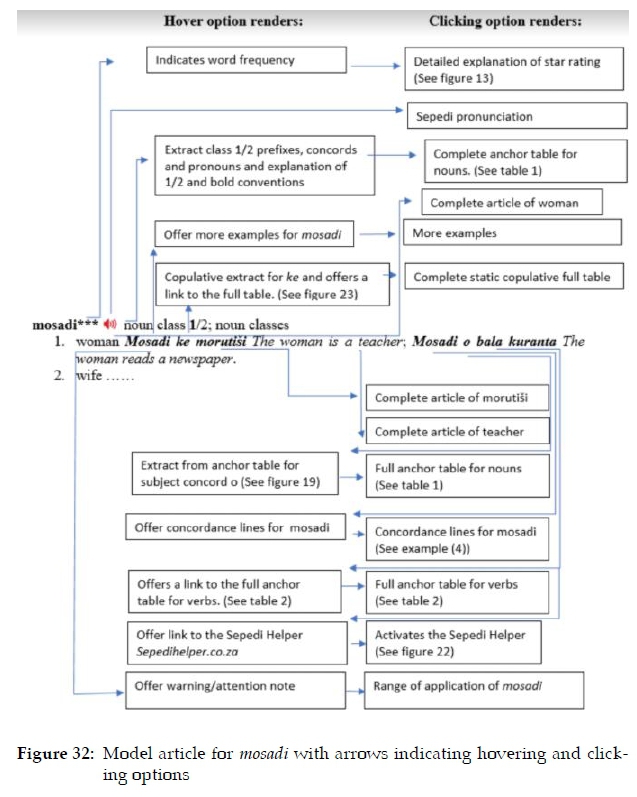{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}