










Serviços Personalizados
Artigo
 Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
Indicadores

Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkLexikos
versão On-line ISSN 2224-0039
versão impressa ISSN 1684-4904
Lexikos vol.28 Stellenbosch 2018
http://dx.doi.org/10.5788/28-1-1459
ARTICLES
Corpus-driven Bantu Lexicography Part 3: Mapping Meaning onto Use in Lusoga
Omutengeso gw'eitu ogukozesebwa mu namawanika w'ennimi dha Bantu. Ekitundu 3: Okukwanagania amakulu n'enkozesa mu Lusoga
Gilles-Maurice de SchryverI, II; Minah NabiryeIII, IV
IBantUGent, Department of Languages and Cultures, Ghent University, Ghent, Belgium
IIDepartment of African Languages, University of Pretoria, Pretoria, South Africa (gillesmaurice.deschryver@UGent.be)
IIIBantUGent, Department of Languages and Cultures, Ghent University, Ghent, Belgium;
IVDepartment of Teacher Education and Development Studies, Kyambogo University, Kampala, Uganda (minah.nabirye@UGent.be)
ABSTRACT
This article is the third instalment in a trilogy of studies that deal with corpus-driven Bantu lexicography as applied to Lusoga. Having dealt with corpus-building in Part 1, and macrostructural aspects in Part 2, we now focus on the microstructure of a dictionary and in particular on the concept of Mapping Meaning onto Use. The starting point is Patrick Hanks's book chapter by the same title, which we transpose to a study of the high-frequent motion verb -v- in Lusoga. Our detailed analysis is as much practical as it is methodological.
Keywords: bantu, lusoga, corpus lexicography, distributional corpus analysis, mapping meaning onto use, meaning potentials, motion verbs
OBUFUNZE
Olupapula luno n'olwokusatu mu nteeko y'okulaga omusomo gw'omutengeso gw'eitu ogukozesebwa mu namawanika w'ennimi dha Bantu ogulaga omulimu ogw'akolebwa ku Lusoga. Oluvainhuma lw'okwandhula engeli eitu ly'Olusoga mu Kitundu 1 n'omuteeko gw'omutindiigo ogusinziilwaku okuzimba olukala lwa namungi w'ebigambowazo mu Kitundu 2, buti eisila liize ku kulaga ngeli amakulu g'ebigambo ye gakwanaganizibwa n'enkozesa. Omusingi gw'eisomo elilagibwa mu kitundu kino gw'ateebwawo Patrick Hanks. Ensonga enkulu dhe yataaku eisila dhilondoolebwa okusinziila ku kigelo kya namungi w'ennhingizo entabaazi (o)ku.v.a. Olupapula luno lugelaagelania engeli ennhingizo eno bwe yaingizibwa mu Eiwanika ly'Olusoga elitaasinziililwa ku itu lya bigambo n'engeli gye yandibaile esengekebwa singa eitu n'ebigelo by'emiwendo egilagibwamu byali bikozeseibwa. Eby'asoboka n'ebitaasoboka bigelaagelanhizibwa n'ebigendelelwa by'omusingi gw'eisomo ly'eitu lya namawanika mu mpandiika y'amawanika.
Ebigambo ebikulu: bantu, lusoga, eitu lya namawaika, ennekeeneenia y'ebigelo by'emiwendo ebilagibwa mu ITU ly'olulimi, okukwanagania amakulu n'enkozesa, amakulu agasoboka, kinantabila omutabaazi
1. Goal of the present study
In this article we wish to investigate how meaning potentials may be drawn from usages as found in a Bantu-language corpus, through an approach known as 'mapping meaning onto use' (Hanks 2002), as applied in the ongoing compilation of a new Lusoga dictionary. With this topic we are squarely dealing with a dictionary's microstructure, although the method may of course be used (and is used) in the field of Bantu corpus linguistics more generally, as may be seen from the recent PhDs of Nabirye (2016) for Lusoga, Kawalya (2017) for Luganda, and Mberamihigo (2014), Nshemezimana (2016) and Misago (2018) for Kirundi.
The major reference for any corpus-based microstructural issues in Bantu lexicography is de Schryver and Prinsloo (2000). In the academic literature, the attention paid to the microstructural level is far more extensive than that paid to the macrostructural level, even in articles that aim to give a perspective on both (Prinsloo and de Schryver 2001, de Schryver 2008) or in articles that take the 'lemmatisation of ...'-formula as a point of departure (de Schryver et al. 2004: 37), which is at heart macrostructural in nature but typically develops into a discussion of microstructural aspects. This may briefly be illustrated with dictionary research undertaken for Northern Sotho.
The 'lemmatisation of ...'-formula may be found in the numerous corpus-based lexicographic studies for the various word classes and other word sets of Northern Sotho, including: reflexives (Prinsloo 1992), verbs (Prinsloo 1994, Prins-loo and Gouws 1996, de Schryver and Prinsloo 2001), adjectives (Gouws and Prinsloo 1997), nouns (Prinsloo and de Schryver 1999, Bosch and Prinsloo 2002), days (de Schryver and Lepota 2001), loan words (Nong et al. 2002), copulatives (Prinsloo 2002), terms (Prinsloo and de Schryver 2002, Taljard and de Schryver 2002), adverbs (Prinsloo 2003), demonstrative copulatives (de Schryver et al. 2004), concords and pronouns (Prinsloo and Gouws 2006), and kinship terms (Prins-loo 2012, Prinsloo and Bosch 2012, Prinsloo 2014b). The opposite also occurs, namely when a primarily microstructural aspect impacts the macrostructure, again with examples for Northern Sotho: left-expanded microstructures (Gouws and Prinsloo 2005), reversibility (de Schryver 2006), communicative equivalence (Prinsloo 2006), and paradigms (Prinsloo 2014a). It has furthermore been noted that the distinction between the macrostructural and microstructural levels tends to disappear in a digital dictionary environment, as has also been illustrated abundantly for Northern Sotho (Prinsloo 2005, Prinsloo et al. 2012, Prinsloo et al. 2014, Prinsloo et al. 2017). Lastly, dictionary reviews, of for instance the corpus-based Oxford Bilingual School Dictionary: Northern Sotho and English (de Schryver 2007), likewise tend to focus on microstructural aspects (Prinsloo 2009, Chabata and Nkomo 2010, Faaß 2010, Klein 2010a, b, Madiba and Nkomo 2010, Kosch 2013).
While the use of a corpus to create the microstructure of a Bantu-language dictionary is thus arguably not a novel undertaking in the field, we do add to the existing studies: (i) a theoretical framework for the current practice,1 and (ii) a detailed analysis of how one actually goes from concordance lines to dictionary lines. In the process we will also explore two further issues, namely: (i) the differences between the use of a corpus and a manual effort, and (ii) the potential enhancement of illustrative material through the exploitation of corpus metadata.
2. On methods and theoretical models
2.1 Corpus linguistics
The description of any language - whether in dictionaries, grammars or other reference works - should be based on real usage of that language. While one could claim that this ought to be the obvious approach, even a cursory look at much of the output by linguists shows otherwise. As adherents of the work of Patrick Hanks, we find the following quote most appropriate:
[...] the literature of twentieth-century linguistics is strewn with examples of self-fulfilling theoretical prophecies, in which bizarre examples are first invented, then judged to be acceptable (according to the researcher's intuitions), and then presented as evidence for conclusions about some aspect of the nature of language or linguistic rules. (Hanks 2013: 307)
In order to be able to describe 'real' language,2 large quantities of actual occurrences of that language are first collected, and then brought together in what is known as 'an electronic corpus'. Dedicated corpus-query software, such as WordSmith Tools (Scott 1996-2018), is used to search and help quantify the hard evidence found in a corpus. At that point, and only at that point, does the researcher explain that evidence:
There is a huge difference between consulting one's intuitions to explain data and consulting one's intuitions to invent data. Every scientist engages in introspection to explain data. No reputable scientist (outside linguistics) invents data in order to explain it. It used to be thought that linguistics is special - that an exception could be made in the case of linguistics - but comparing the examples invented by linguists with the actual usage found in corpora shows that this is not justifiable. (Hanks 2013: 20)
To an increasing number of researchers in the language sciences the power of natural language data is compelling indeed, and for major languages this has given rise to the vibrant field of corpus linguistics, for which Sinclair (1966) may be considered the pioneering study.3 Now half a century on, the field of corpus linguistics is booming; the International Journal of Corpus Linguistics, for instance, celebrated its 20th anniversary in 2015.
Crucial for corpus linguistics is to have access to a fair amount of textual data - at least a million running words, although for major languages corpora of several billion words are not uncommon (Kilgarriff 2003-18). For languages of limited diffusion - be those minor, minority, endangered or simply neglected languages - the lack of sufficient textual data is typically the bottleneck. Billion-word corpora are obtained by crawling the web (de Schryver 2002), a type of corpus-building effort for which most aspects are automated. Transcribing naturally-occurring speech, the default for documentary linguists, is known to be both time-consuming and costly. However, for more and more formerly under-resourced languages, written material is becoming available online (Scannell 2003-18), and for those languages the prospect of applying techniques from the field of corpus linguistics comes into view.
2.2 Bantu corpus linguistics (BCL)
The prospect of applying techniques from the field of corpus linguistics has now become a reality for a good number of Bantu languages. For Lusoga in particular, corpus-building efforts have been described in Part 1 of the present series of three articles. There it was shown that, in addition to an oral component of over half a million words in the 1.7m Lusoga corpus, about a quarter of a million words were found on the Internet, the rest of the corpus being mainly the result of the digitalisation of printed materials.
The field of Bantu corpus linguistics is about two decades old, and is reckoned to have begun with de Schryver's (1999) corpus take on the phonetics of Cilubà. Subsequently, and together with colleagues from South Africa, de Schryver effectively established BCL as a feasible research methodology. While de Schryver was at the University of Pretoria, corpus-based linguistics was undertaken for Zulu (de Schryver and Gauton 2002, Gauton et al. 2004) and for Northern Sotho (Taljard and de Schryver 2002, de Schryver and Taljard 2006). Related work was also done at the universities of Helsinki and Dar es Salaam on Swahili (Sewangi 2000, 2001, Toscano and Sewangi 2005). This early work tended to be corpus-based (i.e. studies for which a corpus is used as one source of evidence in addition to others), in contrast to more recent studies which tend to be corpus-driven (i.e. studies in which a corpus itself is considered to be the sole source of hypotheses about language) - a distinction we owe to Tognini-Bonelli (2001).
The team at the University of Pretoria has since furthered the field of BCL, as may be seen in studies on Northern Sotho (Taljard 2006, de Schryver and Taljard 2007, Taljard 2012, Taljard and de Schryver 2016). Meanwhile at BantUGent (i.e., the UGent Centre for Bantu Studies), an increasing number of research articles includes aspects of BCL, as seen in studies on Lusoga (de Schryver and Nabirye 2010, Nabirye and de Schryver 2011, Nabirye 2016), on Cilubà (De Kind and Bostoen 2012, Dom et al. 2015), on Kirundi (Bostoen et al. 2012, Mberamihigo 2014, Lafkioui et al. 2016, Mberamihigo et al. 2016, Nshemezimana 2016, Nshemezimana and Bostoen 2016, Devos et al. 2017, Misago 2018), on Swahili (Devos and de Schryver 2013, 2016), on Kikongo (De Kind et al. 2013, Bostoen and de Schryver 2015, De Kind et al. 2015), and on Luganda (Kawalya et al. 2014, Kawalya 2017, Kawalya et al. 2018). Not all of these studies are truly corpus-based, let alone corpus-driven, as some of them are closer to being 'corpus-illustrated' (Tummers et al. 2005) or even tend to use their corpora as fish ponds:
Some famous and influential linguists have simply denied the relevance of corpus evidence to linguistic theory. Others have in recent years treated corpora as 'fish ponds' in which to angle for fish that will fit independently conceived hypotheses and theories. Fish that don't fit the theory are thrown back into the pond. [Note: I owe this metaphor to John Sinclair, in conversation some years ago.] (Hanks 2013: 7, 431)
On the relationship between corpus-driven and fish-pond linguistics, Hanks furthermore points out:
Corpus-driven research [...] attempts to approach corpus evidence with an open mind and to formulate hypotheses and indeed, if necessary, a whole theoretical position on the basis of the evidence found. If work is merely 'corpus-based', [Tognini-Bonelli] argues, it risks missing important insights. A truly empirical linguist (or lexicographer) is 'driven' by the data in the corpus. [... The fish pond] analogy is no doubt unfair, for even Tognini-Bonelli, Sinclair, Stubbs, Hanks, and other empirical linguists cannot avoid making some theoretical assumptions as a starting point and using examples selectively, not merely randomly. However, a corpus-driven linguist holds her or his theoretical assumptions lightly and is ready to reconsider them in the light of accumulated evidence. (Hanks 2012: 417)
Therefore, whenever possible, any future studies for Bantu languages should aim to be driven by corpus data. This, too, is valid for the field of lexicography, in our case for the compilation of Lusoga dictionaries.
2.3 Distributional corpus analysis (DCA)
For each aspect for which a corpus is used, a corpus analyst first takes stock of the evidence through an approach that has been termed 'distributional corpus analysis'. Geeraerts (2009: 422-423) proposes to view DCA of the Sinclair-type as a neostructuralist approach to lexical semantics, with, as its main characteristic, the 'radical usage-based rather than system-based approach: it considers the analysis of actual linguistic behaviour to be the ultimate methodological foundation of linguistics' (Geeraerts 2010: 168). Hanks, however, takes issue with Geeraerts's view of DCA as primarily a method, not a model, and comments:
This is odd, because examination of the work of corpus analysts such as Sinclair, Hoey, Wray, Stubbs, Moon, Partington, Semino, McEnery, Hanks, and others would show that corpus analysis lends support to a model of linguistic behaviour founded on prototypical usage - and Geeraerts himself is a proponent of the theory of conceptual prototypes. (Hanks 2015: 102-103)
Entering the fray on whether or not corpus linguistics is more than a methodology goes beyond the scope of the present study. It is certain, however, that in the field of Bantu lexicography, we do use DCA as a method to arrive at various distributions (of homonyms, of meaning potentials, etc.). We nonetheless also like to believe that corpus linguistics is a/our theoretical model.
2.4 Mapping meaning onto use
The various lexicographic uses of a corpus on the macrostructural level have been described, and were illustrated for Lusoga, in Part 2 of the present series of three articles. When querying a corpus in order to compile a dictionary's microstructure, there are at least five uses of that corpus: (i) to map meaning potentials, (ii) to verify and support mother-tongue intuitions, (iii) to study various distributions, (iv) as a source of examples, and (v) to provide overall counts. Working briefly through this list, from last to first, and with a focus on our Lusoga case study, we can note the following. As far as corpus counts are concerned, these are a natural by-product of the steps described in Part 2. There, it was shown that the output of the lemmatisation effort consists of 'skeleton dictionary articles', each with a lemma, part of speech, frequency, rank, frequency band and (optionally) a short meaning. The relative frequency of each candidate lemma sign is, in other words, known at the start of the compilation of each dictionary article.
Each meaning potential that will eventually be singled out is ideally also illustrated with one or more of the corpus lines that were studied to arrive at that meaning. It is a good idea to include information on the source (cf. the Filename in Part 1) in one way or another, with the aim to either show it overtly in 'the' or in 'one of several' final lexicographic products, or to only keep it on file for the dictionary-makers while hiding it from the target users, so that the evidence may always be traced.
As one works through the corpus lines, one is bound to begin sorting and grading the evidence, whereby one automatically ends up drawing up distributions, which may again either be used implicitly or explicitly in the actual dictionary/-ies.
Regarding intuition, it has already been pointed out that the corpus analyst needs her or his own intuition to explain data, but in order to wade through the mass of data beyond the word level, intuition is also an excellent trait to start exploring the corpus with. It is good to make ample use of it, but subsequently one should always stick to the principles of corpus-driven analysis in explaining the evidence. What exists is mentioned, what doesn't appear in the corpus (when expected on intuition) may or may not be pointed out. Of course the latter does not mean that something definitely cannot occur and/or would be ungrammatical, as 'no amount of corpus evidence will provide negative evidence - evidence for what cannot occur' (Hanks 2013: 415). This is not a problem, as 'being able to make predictions about probable usage is much more useful than speculating about the boundaries of possibility' (Hanks 2013: 415).4
As regards the meaning, it may come as a surprise to non-lexicographers but it is well-known to lexicographers: no single mother-tongue speaker knows 'all the words' of her or his language (a feature lexicographers make you believe they possess; after all, aren't they supposed to say something about every word of a language?). As a matter of fact, corpus data continuously challenges what one assumes one knows about words and their meanings. Meanings, in short, can only sensibly be derived from their uses as seen in a corpus, through a principle known as Mapping Meaning onto Use (Hanks 2002), which uses the technique of Corpus Pattern Analysis (Hanks 2004), itself based on the Theory of Norms and Exploitations (Hanks 2013). Reference is made to these seminal works for the full theoretical framework. The problem has been stated by Hanks as follows:
Existing dictionaries may be guilty of sins of omission (e.g. in accounting for pragmatics and function words), but they are equally guilty of sins of commission. They can make things seem even more complicated than they really are. In part, this is because the structure of a traditional dictionary entry is dictated by meanings not by use. Word meaning (if such a thing exists at all) is extremely vague and unstable. A word can have about as many senses as a lexicographer cares to perceive. (Hanks 2002: 159)
To which Hanks proposes the following solution:
[...] the lexicographer must first group the corpus evidence for each word according to the contexts in which it occurs, and then decide to what extent it is possible to group different contexts together (on the grounds that they express what is essentially the same meaning), and to what extent it is necessary to make distinctions. 1 With the advent of large corpora, it is possible to be much more precise about the typical contexts in which a word is used, and to associate different meanings with different contexts. The crucial point here is to choose, as an organizing principle for the dictionary entry, context (which is objectively observable and measurable) rather than meaning (which is opaque and depends on the perceptions of the definer). Lexicographers should think first in terms of syntax and context (or, more strictly, syntagmatics), rather than directly in terms of semantics. They can thus approach meaning indirectly, through syntag-matic analysis, according to a motivated grouping of the evidence. (Hanks 2002: 159-160)
In short, then, and with reference to our new dictionary project for Lusoga, in addition to the brief meanings as may already be logged following lemma-tisation in the dictionary writing system (i.e., the TLex file (Joffe and de Schryver 2002-18)), the main use of a corpus on the microstructural level is to say more about word meanings in context.
3. A case study for Lusoga
3.1 Choosing the Lusoga case study
We now wish to illustrate the mapping of meaning onto use for Lusoga lexicography. Compared to working on English and writing about the process in English, which is already quite hard enough, we have the additional problem that we need to translate everything out of Lusoga and into English for the reader to be able to follow. Hanks's (2002) article on the topic, which also bears the title 'Mapping Meaning onto Use', has been summarised as follows:
Hanks presents his own corpus analyses of lean and tank for lexicographical purposes. Rare are such detailed accounts in which the reader is led by the hand and allowed to see how the master cuts his way through the corpus vines. The latter, including their analyses, are displayed in full as addenda, hereby allowing the reader to appreciate the hesitations - about which Hanks is quite open - even more. Once the path has been cut, once Hanks unspun the hanks, the reader is offered the view that syntagmatics in tandem with 'perceived meaning' ought to be the organising principle of dictionary entries for verbs and adjectives. The organisation for nouns is similar, but slightly more complicated. (de Schryver 2005: 423)
In other words, just two words are used to illustrate the process, one verb (lean) and one noun (tank). For reasons of space, and given that we also need to translate our material, we will limit our current analysis for Lusoga to just one verb. For an idea of the issues involved in undertaking a study of the Lusoga noun using a corpus, see de Schryver and Nabirye (2010), which contains a section on the semantic import of the noun in Lusoga.
The Lusoga verb chosen for the present case study is the motion verb -v-. The root of this verb consists of just one letter, the letter 'v', which immediately indicates the additional difficulty of merely finding this verb in a raw corpus, thus one without any morphological analysis, which the 1.7m Lusoga corpus was before lemmatisation. We, however, took up the challenge.
3.2 The verb -v- in the monolingual Lusoga dictionary
To begin the discussion in a practical way, we will be employing a shortcut, by translating the relevant information gleaned from the Eiwanika ly'Olusoga (Nabirye 2009b), which is a monolingual dictionary of Lusoga, compiled without access to a corpus. This dictionary has also been digitised (Nabirye and de Schryver 2013), and is available on disc as well as freely online from http://menhapublishers.com/dictionary/. In that dictionary, the verb -v- is to be found on page 379, as two homonymous forms, and as two lemma signs with the locative enclitics -ku and -mu respectively. This page is shown in Addendum 1, while the slightly edited and reformatted online data is shown in Table 1, on the left.
Intuition combined with the fieldwork that led to the dictionary data seen in Table 1 clearly indicate that the verb(s) -v-, without and with locative enclitics, is/are indeed quite polysemous.
3.3 The verb -v- in the Lusoga lemmatised frequency list
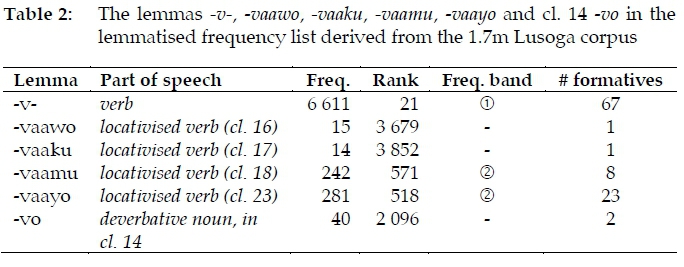
From the 1.7m Lusoga corpus (cf. Part 1), a lemmatised frequency list was created (cf. Part 2). Perusing it, we notice that the data for the verbal lemma -v-was not split into two. Deciding whether or not to create two homonyms for -v-was not feasible during lemmatisation, where the focus was literally on lemma-tisation and part-of-speech assignment, not on any detailed studies of usage leading to meaning. When it comes to the verbal forms with locative enclitics, however, we find not just -vaaku (with an enclitic from cl. 17) and -vaamu (cl. 18) in the lemmatised frequency list, but also -vaawo (cl. 16) and -vaayo (cl. 23). From a frequency point of view, then, one can say that the latter two locativised verbs were 'overlooked' during the manual (i.e., non-corpus) effort to compile the monolingual Lusoga dictionary. Also overlooked in the Eiwanika ly'Olusoga is the deverbative noun -vo in cl. 14, which does have a respectable frequency in the lemmatised frequency list. These six lemmas are listed in Table 2, together with their lemma frequencies, lemma ranks, lemma frequency bands, as well as number of formatives.
The formative (or underlying) data that led to the six lemmas listed in Table 2 is presented in Addendum 2. For the verb -v-, for instance, 67 types were frequent enough - meaning that their frequency was at least 12 in the 1.7m Lusoga corpus (cf. Part 2, §3) - and the frequencies of these 67 all contribute to the total frequency of the lemma -v-, being 6 611, which turns out to be one of the most frequent lemmas in the language, with rank 21. From Table 2 one may further conclude that given that -vaaku was entered in the Eiwanika ly'Olusoga, -vaawo with a similar frequency and cl. 14 -vo should indeed have been entered as well, and especially the top-frequent -vaayo, the 518th-most-frequent lemma overall in Lusoga.5
3.4 The verb -v- in the 1.7m Lusoga corpus
3.4.1 Mapping steps and sampling procedure
We are now in a position to study the Lusoga corpus evidence for -v-. The steps of the procedure to map meaning onto use have been enumerated as follows by Hanks, with reference to his case study of English lean:
Working with a 500-line sample, we sort all the occurrences into different categories, first on broad syntactic grounds (separating adjectives from the verbs), then into more delicate semantic and syntactic frames (e.g. separating 'lean meat' from 'lean businesses') and finally making more subtle distinctions on semantic grounds (e.g. separating different meanings of 'lean on someone', according to the perceived purpose of the person doing the leaning, i.e. reliance or choice). [... ] It should be emphasized that the level of detail used in categorization of corpus lines is a matter of choice and judgement: even more delicate subcategorization is possible, or different patterns may be lumped together in a single category. (Hanks 2002: 165-166, our underlining)
Without any further information, sampling the raw Lusoga corpus in search of -v- is obviously hard. However, once one realises that one has the underlying forms which led to each lemma at hand, the process is actually perfectly doable. According to the data presented in Addendum 2, the most frequent formatives for the lemma -v- are okuva (freq. 2 668), ava (freq. 389), ova (freq. 325), kuva (freq. 267), yava (freq. 188), nva (freq. 162), etc. In other words, one may simply instruct WordSmith Tools to search for any or all of such frequent types at the same time (by simply placing slashes between the various forms), with or without a randomiser (for instance, to limit the output to a sample of 100 lines), to then study the concordance lines. As an alternative, adding a verbal extension, such as an applicative, or the perfect, and searching for -viil- rather, is also an option.
3.4.2 The verbs -v-1, -v-2, the connective kye-SM-va, and the adverb kuva
After a careful study of several hundreds of concordance lines for -v-, we concluded that the various uses are indeed best presented in two separate, homonymous, dictionary entries. Given that we are describing the evidence in English, there may be a tendency to let the English categories influence the Lusoga evidence. We have avoided that, just as it is good practice in bilingual lexicography not to allow the target language to 'pull' or 'distort' the source language analysis (Atkins 1996: 8).
The various verbal uses as seen in the corpus lead to the meaning potentials listed below, ordered from more to lesser frequent, and grouped around usages that have to do with movement, vs. usages that have to do with projection and direction. Adding an addendum with the many concordance lines will not be beneficial to the reader; instead, we add a glossed example for each use. (For the abbreviations in the glosses, see the explanations at the end.)
okuva1[move senses]
1. to leave, to depart, to go away
2. to hail (from)
3. to abandon
4. to make way, to move away
5. to result, to come out
6. to spend (time)



Combinations
Three combinations appear frequently in the concordance lines, the first derived from -v-1, sense 1.

The next two frequent combinations are derived from -v-2, sense 1, and have to do with measuring, either space or time.

Other word classes
Addendum 2 indicates that, among the formatives of the verb -v-, one also finds the forms kyava, kyebaava, kyenva, kyetuva and kyeyava. These words actually belong to a different word class, as these are connectives which are built according to a fixed formula, combining the object relative of class 7, followed by a subject marker, and then -v-1, sense 5.


3.4.3 The locativised verb -vaawo
When the class 16 locative enclitic -wo is suffixed to the base verb -v-1, a new use that was not seen for the base verb is found (1. below), together with the main use as also seen for the base verb (2. below).7

3.4.4 The locativised verb -vaaku
When the class 17 locative enclitic -ku is suffixed to the base verb -v-1, numerous new uses that were not seen for the base verb are found (all but one below), together with one main use as also seen for the base verb (2. below).



Combinations
Together with the noun omusolo 'tax', sense 4 acquires a specific use, as shown below.

3.4.5 The locativised verb -vaamu
When the class 18 locative enclitic -mu is suffixed to the base verb -v-1, numerous new uses that were not seen for the base verb are found (3. to 5. below), together with variations of the two main uses as also seen for the base verb (1. and 2. below).
okuvaamu < okuva1
1. to abandon though it is expected
2. to come out, to flow out, to exit
3. to grow well, to turn out well
4. to yield, to generate
5. to not gain



Combinations
Together with the noun enda 'stomach', sense 2 acquires a specific use, as shown below.

Other word classes
One particular frequent construction has lexicalised and is used as a connective - namely the subject relative of cl. 7, with the past tense marker, and sense 2 of -vaamu - as shown below.
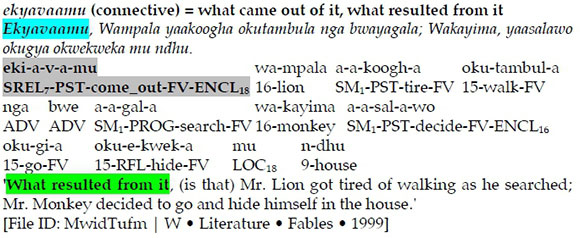
3.4.6 The locativised verb -vaayo
When the class 23 locative enclitic -yo is suffixed to the base verb -v-1, either a variation of sense 5 of the base verb is seen, or a new one.
okuvaayo <okuva1
1. to come out
2. to give way

3.4.7 The cl. 14 deverbative noun -vo
While all previous derivations (§§3.4.3-3.4.6) were derived from -v-1, one fre-quent derivation, the cl. 14 deverbative noun -vo, is derived from -v-2, sense 1, as shown below.
obuvo = the beginning < okuva2

3.4.8 Summary of the corpus evidence for the Lusoga verb -v-
The corpus evidence as analysed and illustrated in §3.4.2 through §3.4.7 can now be synthesised as presented in Table 3. The three steps of Hanks's procedure may be recognised, but for a Bantu language the approach is not as linear as suggested in §3.4.1 for English. Part of Step 1, the division 'on broad syntactic grounds', is the outcome of the lemmatisation, which resulted in the distinction between verbal, locativised verbal and nominal uses (column 1 in Table 3). The other half, with connectives and an adverbial use, was only revealed during analysis (column 4 in Table 3). When it comes to Step 2, the division 'into more delicate semantic and syntactic frames' is what we termed combinations (column 3 in Table 3). In our case study, these may be combinations of verb + noun, verb + verb, verb + preposition, and verb + locative + noun. Those that include a preposition also turn into prepositional uses. Due to the structure of Bantu languages, some of these lemmas and combinations include codes for entire paradigms (here LOC = any locative, SM = any subject marker). Lastly, Step 3, 'making more subtle distinctions on semantic grounds', goes to the heart of the splitting vs. lumping decisions that every lexicographer must contend with (column 2 in Table 3).
3.5 Comparison of the manual effort vs. the corpus evidence for the Lusoga verb -v-
Any comparison between a manual effort and a corpus-driven one is always unfair, as the corpus tends to 'win'. in doing so, one often forgets about the heroic efforts that went into the manual effort in the first place (Nabirye 2008, 2009a, Nabirye and de Schryver 2010, 2011, 2013). The following, therefore, is only for illustrative purposes.
While the lemmatisation had already revealed that two of the four loca-tivised verbs had accidentally been overlooked, including a very frequent one, as well as a deverbative noun (probably because it was assumed to belong to the grammar rather than the lexicon), all of the trickier derived word classes as well as the truly frequent combinations were also absent from the manual effort. (The one combination offered in the monolingual dictionary, viz. okuva ku luguudo, was not found in the 1.7m Lusoga corpus.) With regard to the various meaning potentials: while one notices a few overlaps, one especially notices a good number of additions and more fine-grained descriptions as a result of the corpus analysis. The order of the meaning potentials that do overlap is not always the same either (cf. [ ] in Table 3).
What the manual effort does include, and what the corpus does not reveal in the same way, is the long list of 19 proverbs seen in Table 2. This is only partly the result of the fact that proverbs are known to be far less canonical in their use than dictionary-makers try to make you believe (Moon 1998). The proverb Akaviile mu igi tikatya ikoli 'The one that has just come from an egg does not fear an eagle' from the monolingual dictionary is for instance found in the corpus as Akazaalibwa tikatya ikoli 'The one which has just been born does not fear an eagle', hence without what one would assume to be a core term, 'egg'. Or, more Bantuish in nature, the monolingual-dictionary proverb Omusaadha kikele kiva kyonka mu bwina A man is a frog, which comes out of the hole by itself' is found in the corpus as Omusaadha ikere: liva lyonka mu bwina A man is a frog, which comes out of the hole by itself', which appears to be the same in translation, but in Lusoga the canonical form uses the noun in gender 7/8, while it is found in gender 5/6 in the corpus. Given this variation, proverbs have to be spotted mostly manually in a corpus. As to the reverse, a dedicated search does reveal proverbs not included into the otherwise pretty exhaustive manual list, such as Awava omugulu waila mwigo 'The stick takes the place of the leg that has left', Awava omwosi wava omulilo 'Fire comes from where smoke comes from', etc. Even so, their frequency of use is simply too low to merit inclusion when reasonable corpus frequencies and a nice spread across sources are used as an inclusion criterion.
3.6 Constructing corpus-driven microstructures for the Lusoga verb -v-
The data synthesised in Table 3 is the starting point for constructing the various dictionary articles that revolve around the verb -v- in Lusoga. In a desk or school dictionary, one may select from that data by taking, say, only the top n (frequent) lemmata and for these the top n (frequent) meaning potentials. At the other extreme, in a comprehensive dictionary, one will also want to exemplify all possible senses. To do so, reusing the examples that were studied during the analysis is an option, so the sentences and phrases from §§3.4.2-3.4.7 are prime candidates.10 In doing so, however, it is good to recall that 'giving equal prominence to all senses, when they are not equally common, is a distortion' (Hanks 2002: 157). So, the most frequent meaning potentials could be illustrated with multiple examples, while the lesser-frequent ones could do with just one or even no examples. Likewise with the combinations: whether or not to include some or all of them will depend on the target. For an unabridged paper dictionary, however, or for a digital dictionary in which the information is layered and where it may be 'peeled off' (Geeraerts 2000: 78-79), one can as well prepare and optionally present as much as possible. Adding the sources of the various examples also becomes a worthwhile addition at that point, as is the tradition in dictionaries based on historical principles. While such information on each source could be synthesised in the dictionary itself, a link to the full information, as seen in Addendum 1 of Part 1, could furthermore easily be added. In a digital dictionary actual hyperlinks to the corpus material itself could even be envisaged, thereby handing dictionary users the 'raw data' on which the lexicographers based their decisions, and/or allowing such users to explore the (corpus) data further (cf. de Schryver 2003: 167, 169, i.e. 'Dream # 31'). In short, a maximally populated dictionary writing system is best viewed as a single database from which any number of dictionaries may be generated, a concept that has been termed 'one database, many dictionaries' (de Schryver and Joffe 2005).
4. Discussion
In this article we have made a strong case for the analysis of corpora to discover word meanings. After two decades of querying corpora for Bantu lexicography in general, and about one decade of corpus-building for Lusoga in particular, we are pretty much convinced that a careful study of the natural production of language that was produced by a multitude of speakers and writers indeed offers the best perspective on how language is truly used, from which meanings may be mapped (as explained and illustrated in the present article), and with which detailed studies of language may be undertaken. Some colleagues remain sceptical however, as voiced by Michael Marlo two years ago:
A criticism that can be levelled at corpus-based approaches is that because they lump together data by individual speakers, it is extremely difficult if not impossible in a corpus-based approach to make sense of variation across individuals which is the result of the speakers having different internal grammars. The present approach seems to reject the idea that grammar is in the heads of individual speakers. It focuses on 'e-language' vs. 'i-language'. That is fine, but the approach has some limitations - such as the ability to state with precision what is a 'language'. (Marlo 2016, personal communication)
By using a corpus in the way we do, one ends up compromising, and indeed focusing on many e-languages (with e for 'external/externalised'), rather than on a single or a limited number of i-languages (with i for 'internal/internalised'). That said, even though the corpus analyst likes lots and lots of data and ditto examples, it is also true that: '"Overwhelming evidence", be it noted, may consist of no more than a handful of textually well-formed and convincing modern uses' (Hanks 2002: 174). Michael Marlo goes on to suggest:
Moreover, most linguists consider negative evidence to be essential for understanding the rules of language - not just what is common vs. uncommon but determining what is possible vs. impossible. There is considerable discussion of this within the generativist community under the notion of 'poverty of the stimulus' - the idea that speakers of a language know much about the language, even if they have never heard the expressions in question before. (Marlo 2016, personal communication)
in our strand of corpus linguistics, the focus is on the norms, not the exploitations, and the focus is consequently also not on what does not occur or on what occurs infrequently. Of course, this is a choice, but for a language like Lusoga which needs 'first descriptions', focusing on the speech community and their general needs first, and attempting to bring back their own words to them, in this case in the form of corpus-driven dictionary-making, seems like a worth while venture.
With this, we have come to the end of our three-part study of corpus-driven Bantu lexicography as applied to Lusoga. To conclude, it is now fitting to point out that our effort is not the first trilogy of articles on the application of corpora in modern dictionary-making. As a matter of fact, Michael Rundell and Penny Stock initiated this trend a quarter of a century ago, with a three-part report on what was then called 'The corpus revolution' (as applied to English lexicography). Compared to our effort, the sequence of their articles is organised differently, however. In their first part, Rundell and Stock (1992a) looked at the relative merits of large-scale text corpora compared to traditional citation banks. in the light of Hanks's theoretical framework of mapping meaning onto use, their most important observation in favour of the use of computerised corpora over manual reading and marking is that:
it is astonishingly difficult for even the most experienced person to collect material for ordinary everyday usages since human beings tend to notice the unusual. [... ] When using corpus evidence, therefore, the lexicographer works with whatever comes up in the corpus rather than with individually or specially selected examples. (Rundell and Stock 1992a: 13, 10)
The other advantages they list in favour of a corpus remain valid to this day, and have also all been illustrated for Lusoga lexicography: (i) 'it can provide evidence for the comparative frequency of word occurrence and behaviour', (ii) 'It can be of immense help in enabling the lexicographer to give examples to show the word in its most typically or frequently used contexts', (iii) 'it allows the lexicographer to structure an entry in such a way as to reflect how a word is normally used', and (iv) 'it can enable the dictionary maker to give an accurate account of grammatical behaviour at the level of individual senses' (Rundell and Stock 1992a: 14).
In their second part, Rundell and Stock (1992b) looked at the ways in which corpus evidence informs the actual writing of dictionary articles. With de Schryver and Joffe's practical concept of one database, many dictionaries in mind, the following observations on what to put in a certain dictionary ring true:
In fact the task of omitting or not including known meanings which are nonetheless inappropriate to a particular dictionary is a very hard one. It is so much easier to play safe and let such meanings in [... ] Again the evidence of many millions of examples of usage can be of enormous assistance in strengthening the lexicographer's nerve in such cases [... ] (Rundell and Stock 1992b: 25)
On a more generic level, their closing statement has proven to be as valid for Bantu as it is for English:
It is perhaps fairly rare to find all one's preconceptions about a word being overturned on consulting a corpus, but it is equally rare to come away from analysing a given word or use without having learned a great deal that is new, illuminating, and sometimes unnerving. (Rundell and Stock 1992b: 28-29)
In their third part, Rundell and Stock (1992c) mainly deal with corpus building, and try to predict some of the automated tools and procedures that will be developed. These are, using the terms that have come to be adopted since Rundell and Stock's predictions from the early 1990s: (i) lemmatisers, (ii) sampling techniques, (iii) POS-taggers, (iv) parsers, and (v) word-sense disambiguators. Over the past 25 years these have indeed all been created for the world's major languages. More in particular, in Part 2 of our series we have indicated how the lemmatisation and POS-tagging for lexicographic purposes may be achieved for the Bantu languages. Unlike for English, these macrostructural aspects are hugely complex for the Bantu languages, which led Prinsloo and de Schryver to develop instruments known as part-of-speech rulers and alphabetical (or multidimensional lexicographic) rulers in order to measure, evaluate, predict and manage Bantu-language dictionary projects. We therefore trust that thanks to corpora, and just as is the case for English, we are now indeed 'emancipated from the role of harmless drudge and empowered to make new insights into every area of language' (Rundell and Stock 1992c: 51).
Abbreviations

Acknowledgements
The research for this article was funded by the Special Research Fund of Ghent University. Thanks are due to the two anonymous referees.
References
Atkins, B.T.S. 1996. Bilingual Dictionaries: Past, Present and Future. Gellerstam, M., J. Järborg, S.-G. Malmgren, K. Norén, L. Rogström and C.R. Papmehl (Eds). 1996. Euralex '96 Proceedings I-II, Papers Submitted to the Seventh EURALEX International Congress on Lexicography in Göteborg, Sweden: 515-546. Gothenburg: Department of Swedish, Göteborg University. [ Links ]
Bosch, S.E. and D.J. Prinsloo. 2002. 'Abbreviated Nouns' in African Languages: A Morphological, Semantic and Lexicographic Perspective. South African Journal of African Languages 22(1): 92-104. [ Links ]
Bostoen, K. and G.-M. de Schryver. 2015. Linguistic Innovation, Political Centralization and Economic Integration in the Kongo Kingdom: Reconstructing the Spread of Prefix Reduction. Diachronica 32(2): 139-185 + 13 pages of supplementary material online. [ Links ]
Bostoen, K., F. Mberamihigo and G.-M. de Schryver. 2012. Grammaticalization and Subjectifica-tion in the Semantic Domain of Possibility in Kirundi (Bantu, JD62). Africana Linguistica 18: 5-40. [ Links ]
Chabata, E. and D. Nkomo. 2010. The Utilisation of Outer Texts in the Practical Lexicography of African Languages. Lexikos 20: 73-91. [ Links ]
De Kind, J. and K. Bostoen. 2012. The Applicative in ciLubà Grammar and Discourse: A Semantic Goal Analysis. Southern African Linguistics and Applied Language Studies 30(1): 101-124. [ Links ]
De Kind, J., M. Devos, G.-M. de Schryver and K. Bostoen. 2013. Negation Markers, Focus Markers and Jespersen Cycles in Kikongo (Bantu, H16): A Comparative and Diachronic Corpus-based Approach. Available online at: https://www2.hu-berlin.de/predicate_focus_africa/data/2013-12-10_deKind_Negation.in.Kikongo.pdf.
De Kind, J., S. Dom, G.-M. de Schryver and K. Bostoen. 2015. Event-centrality and the Pragmatics-Semantics Interface in Kikongo: From Predication Focus to Progressive Aspect and Vice Versa. Folia Linguistica Historica 36: 113-163. [ Links ]
de Schryver, G.-M. 1999. Cilubà Phonetics, Proposals for a 'Corpus-based Phonetics from Below'-Approach (Recall Linguistics Series 14). Ghent: Recall. [ Links ]
de Schryver, G.-M. 2002. Web for/as Corpus: A Perspective for the African Languages. Nordic Journal of African Studies 11(2): 266-282. [ Links ]
de Schryver, G.-M. 2003. Lexicographers' Dreams in the Electronic-Dictionary Age. International Journal of Lexicography 16(2): 143-199. [ Links ]
de Schryver, G.-M. 2005. Book Review: M.-H. Corréard, ed. 2002. Lexicography and Natural Language Processing. A Festschrift in Honour of B.T.S. Atkins. Lexicographica: International Annual for Lexicography 21: 420-425. [ Links ]
de Schryver, G.-M. 2006. Compiling Modern Bilingual Dictionaries for Bantu Languages: Case Studies for Northern Sotho and Zulu. Corino, E., C. Marello and C. Onesti (Eds). 2006. Atti del XII Congresso Internazionale di Lessicografia, Torino, 6-9 settembre 2006 / Proceedings XII Euralex International Congress, Torino, Italia, September 6th-9th, 2006: 515-525. Alessandria: Edizioni dell'Orso. [ Links ]
de Schryver, G.-M. 2007. Oxford Bilingual School Dictionary: Northern Sotho and English / Pukuntsu ya Polelopedi ya Sekolo: Sesotho sa Leboa le Seisimane. E gatisitswe ke Oxford. Cape Town: Oxford University Press Southern Africa. [ Links ]
de Schryver, G.-M. 2008. Why does Africa need Sinclair? International Journal of Lexicography 21(3): 267-291. [ Links ]
de Schryver, G.-M. and R. Gauton. 2002. The Zulu Locative Prefix ku- Revisited: A Corpus-based Approach. Southern African Linguistics and Applied Language Studies 20(4): 201-220. [ Links ]
de Schryver, G.-M. and D. Joffe. 2005. One Database, Many Dictionaries - Varying Co(n)text with the Dictionary Application TshwaneLex. Ooi, V.B.Y., A. Pakir, I. Talib, L. Tan, P.K.W. Tan and Y.Y. Tan (Eds). 2005. Words in Asian Cultural Contexts, Proceedings of the 4th Asialex Conference, 1-3 June 2005, M Hotel, Singapore: 54-59. Singapore: Department of English Language and Literature & Asia Research Institute, National University of Singapore. [ Links ]
de Schryver, G.-M. and B. Lepota. 2001. The Lexicographic Treatment of Days in Sepedi, or When Mother-Tongue Intuition Fails. Lexikos 11: 1-37. [ Links ]
de Schryver, G.-M. and M. Nabirye. 2010. A Quantitative Analysis of the Morphology, Morpho-phonology and Semantic Import of the Lusoga Noun. Africana Linguistica 16: 97-153. [ Links ]
de Schryver, G.-M. and D.J. Prinsloo. 2000. Electronic Corpora as a Basis for the Compilation of African-language Dictionaries, Part 2: The Microstructure. South African Journal of African Languages 20(4): 310-330. [ Links ]
de Schryver, G.-M. and D.J. Prinsloo. 2001. Towards a Sound Lemmatisation Strategy for the Bantu Verb through the Use of Frequency-based Tail Slots - with Special Reference to Cilubà, Sepedi and Kiswahili. Mdee, J.S. and H.J.M. Mwansoko (Eds). 2001. Makala ya kongamano la kimataifa Kiswahili 2000. Proceedings: 216-242, 372. Dar es Salaam: TUKI, Chuo Kikuu cha Dar es Salaam. [ Links ]
de Schryver, G.-M. and E. Taljard. 2006. Locative Trigrams in Northern Sotho, Preceded by Analyses of Formative Bigrams. Linguistics, An Interdisciplinary Journal of the Language Sciences 44(1): 135-193. [ Links ]
de Schryver, G.-M. and E. Taljard. 2007. Compiling a Corpus-based Dictionary Grammar: An Example for Northern Sotho. Lexikos 17: 37-55. [ Links ]
de Schryver, G.-M., E. Taljard, M.P. Mogodi and S. Maepa. 2004. The Lexicographic Treatment of the Demonstrative Copulative in Sesotho sa Leboa - An Exercise in Multiple Cross-referencing. Lexikos 14: 35-66. [ Links ]
Devos, M. and G.-M. de Schryver. 2013. From 'habitually going' to 'maybe': Grammaticalization and Lexicalization of an Epistemic Sentence Adverb in Swahili. Abstracts of The 21st International Conference on Historical Linguistics: 29. Oslo: University of Oslo. [ Links ]
Devos, M. and G.-M. de Schryver. 2016. From Usually Going to Epistemic Possibility. Origin and Development of an Epistemic Sentence Adverb in Swahili. 6th International Conference on Bantu Languages, Workshop on the Expression of Mood and Modality in Bantu Languages: 11. Helsinki: University of Helsinki. [ Links ]
Devos, M., M.-J. Misago and K. Bostoen. 2017. A Corpus-based Description of Locative and Non-locative Reference in Kirundi Locative Enclitics. Africana Linguistica 23: 47-83. [ Links ]
Dom, S., G. Segerer and K. Bostoen. 2015. Antipassive/Associative Polysemy in Cilubà (Bantu, L31a): A Plurality of Relations Analysis. Studies in Language 39(2): 354-385. [ Links ]
Faaß, G. 2010. A Morphosyntacic Description of Northern Sotho as a Basis for an Automated Translation from Northern Sotho into English. Unpublished Ph.D. dissertation. Pretoria: University of Pretoria. [ Links ]
Fox, G. 1987. The Case for Examples. Sinclair, J.M. (Ed.). 1987. Looking Up: An Account of the COBUILD Project in Lexical Computing and the Development of the Collins COBUILD English Language Dictionary: 137-149. London: Collins ELT. [ Links ]
Gauton, R., G.-M. de Schryver and L. Mohlala. 2004. A Corpus-based Investigation of the Zulu Nominal Suffix -kazi: A Preliminary Study. Akinlabi, A. and O. Adesola (Eds). 2004. Proceedings of the 4th World Congress of African Linguistics, New Brunswick 2003: 373-380. Cologne: Rüdiger Köppe Verlag. [ Links ]
Geeraerts, D. 2000. Adding Electronic Value. The Electronic Version of the Grote Van Dale. Heid, U., S. Evert, E. Lehmann and C. Rohrer (Eds). 2000. Proceedings of the Ninth EURALEX International Congress, EURALEX 2000, Stuttgart, Germany, August 8th-12th, 2000: 75-84. Stuttgart: Institut für Maschinelle Sprachverarbeitung, Universität Stuttgart. [ Links ]
Geeraerts, D. 2009. Currents and Undercurrents in Lexical Semantics, Twenty Years After. Beijk, E., L. Colman, M. Göbel, F. Heyvaert, T. Schoonheim, R. Tempelaars and V. Waszink (Eds). 2009. Fons Verborum. Feestbundel voor prof. dr. A.M.F.J. (Fons) Moerdijk, aangeboden door vrienden en collega's bij zijn afscheid van het Instituut voor Nederlandse Lexicologie: 421-430. Amsterdam: Gopher BV. [ Links ]
Geeraerts, D. 2010. Theories of Lexical Semantics. New York: Oxford University Press. [ Links ]
Gouws, R.H. and D.J. Prinsloo. 1997. Lemmatisation of Adjectives in Sepedi. Lexikos 7: 45-57. [ Links ]
Gouws, R.H. and D.J. Prinsloo. 2005. Left-expanded Article Structures in Bantu with Special Reference to isiZulu and Sepedi. International Journal of Lexicography 18(1): 25-46. [ Links ]
Hanks, P. 2002. Mapping Meaning onto Use. Corréard, M.-H. (Ed.). 2002. Lexicography and Natural Language Processing. A Festschrift in Honour of B.T.S. Atkins: 156-198. s.l.: Euralex.
Hanks, P. 2004. Corpus Pattern Analysis. Williams, G. and S. Vessier (Eds). 2004. Proceedings of the Eleventh EURALEX International Congress, EURALEX 2004, Lorient, France, July 6-10, 2004: 87-97. Lorient: Faculté des Lettres et des Sciences Humaines, Université de Bretagne Sud. [ Links ]
Hanks, P. 2012. The Corpus Revolution in Lexicography. International Journal of Lexicography 25(4): 398-436. [ Links ]
Hanks, P. 2013. Lexical Analysis: Norms and Exploitations. Cambridge, MA: The MIT Press. [ Links ]
Hanks, P. 2015. Cognitive Semantics and the Lexicon. International Journal of Lexicography 28(1): 86106. [ Links ]
Joffe, D. and G.-M. de Schryver. 2002-18. TLex Suite - Dictionary Compilation Software. Available online at: http://tshwanedje.com/tshwanelex/.
Kawalya, D. 2017. A Corpus-driven Study of the Expression of Modality in Luganda (Bantu, JE15). Unpublished Ph.D. dissertation. Ghent: Ghent University. [ Links ]
Kawalya, D., K. Bostoen and G.-M. de Schryver. 2014. Diachronic Semantics of the Modal Verb -sóból- in Luganda: A Corpus-driven Approach. International Journal of Corpus Linguistics 19(1): 60-93. [ Links ]
Kawalya, D., G.-M. de Schryver and K. Bostoen. 2018. From Conditionality to Modality in Luganda (Bantu, JE15): A Synchronic and Diachronic Corpus Analysis of the Verbal Prefix -andi-. Journal of Pragmatics 127: 84-106. [ Links ]
Kilgarriff, A. 2003-18. Sketch Engine. Available online at: https://www.sketchengine.co.uk.
Klein, J. 2010a. Can the New African Language Dictionaries Empower the African Language Speakers of South Africa or Are They Just a Half-hearted Implementation of Language Policies? Dykstra, A. and T. Schoonheim (Eds). 2010. Proceedings of the XIV Euralex International Congress (Leeuwarden, 6-10 July 2010): 1485-1496. Leeuwarden/Ljouwert: Fryske Akademy. [ Links ]
Klein, J. 2010b. Nord Sotho Wörterbücher als Implementierungsstrategien der South African Languages Bill und der National Lexicographic Units Bill. Buchmann, L., L. Fuhrmann, N. Nassenstein, C. Vogel, M. Weinle and A. Wolvers (Eds). 2010. Beiträge zur 3. Kölner Afrikawissenschaftlichen Nachwuchstagung (KANTIII): 1-11. Cologne: University of Cologne. [ Links ]
Kosch, I. 2013. An Analysis of the Oxford Bilingual School Dictionary: Northern Sotho and English (De Schryver 2007). Lexikos 23: 611-627. [ Links ]
Lafkioui, M., E. Nshemezimana and K. Bostoen. 2016. Cleft Constructions and Focus in Kirundi. Africana Linguistica 22: 71-106. [ Links ]
Madiba, M. and D. Nkomo. 2010. The Tshivenda-English Tahalusamaipfi/Dictionary as a Product of South African Lexicographic Processes. Lexikos 20: 307-325. [ Links ]
Mberamihigo, F. 2014. L'expression de la modalité en kirundi : Exploitation d'un corpus électronique. Unpublished Ph.D. dissertation. Brussels; Ghent: Université libre de Bruxelles; Ghent University. [ Links ]
Mberamihigo, F., G.-M. de Schryver and K. Bostoen. 2016. Entre verbe et adverbe : Grammaticalisation et dégrammaticalisation du marqueur épistémique umeengo/umeenga en kirundi (bantou, JD62). Journal of African Languages and Linguistics 37(2): 247-286. [ Links ]
Misago, M.-J. 2018. Les verbes de mouvement et l'expression du lieu en kirundi (bantou, JD62) : Une étude linguistique basée sur un corpus. Unpublished Ph.D. dissertation. Ghent: Ghent University. [ Links ]
Moon, R. 1998. Fixed Expressions and Idioms in English. A Corpus-based Approach. Oxford: Oxford University Press. [ Links ]
Nabirye, M. 2008. Compilation of the Monolingual Lusoga Dictionary. Unpublished M.A. dissertation. Kampala: Makerere University. [ Links ]
Nabirye, M. 2009a. Compiling the First Monolingual Lusoga Dictionary. Lexikos 19: 177-196. [ Links ]
Nabirye, M. 2009b. Eiwanika ly'Olusoga. Eiwanika ly'aboogezi b'Olusoga n'abo abenda okwega Olusoga [A Dictionary of Lusoga. For speakers of Lusoga, and for those who would like to learn Lusoga]. Kampala: Menha Publishers. [ Links ]
Nabirye, M. 2016. A Corpus-based Grammar of Lusoga. Unpublished Ph.D. dissertation. Ghent: Ghent University. [ Links ]
Nabirye, M. and G.-M. de Schryver. 2010. The Monolingual Lusoga Dictionary Faced with Demands from a New User Category. Lexikos 20: 326-350. [ Links ]
Nabirye, M. and G.-M. de Schryver. 2011. From Corpus to Dictionary: A Hybrid Prescriptive, Descriptive and Proscriptive Undertaking. Lexikos 21: 120-143. [ Links ]
Nabirye, M. and G.-M. de Schryver. 2013. Digitizing the Monolingual Lusoga Dictionary: Challenges and Prospects. Lexikos 23: 297-322. [ Links ]
Nong, S., G.-M. de Schryver and D.J. Prinsloo. 2002. Loan Words versus Indigenous Words in Northern Sotho - A Lexicographic Perspective. Lexikos 12: 1-20. [ Links ]
Nshemezimana, E. 2016. Morphosyntaxe et structure informationnelle en kirundi : Focus et stratégies de focalisation. Unpublished Ph.D. dissertation. Ghent: Ghent University. [ Links ]
Nshemezimana, E. and K. Bostoen. 2016. The Conjoint/Disjoint Alternation in Kirundi (JD62): A Case for its Abolition. van der Wal, J. and L.M. Hyman (Eds). 2016. The Conjoint/Disjoint Alternation in Bantu (Trends in Linguistics. Studies and Monographs 301): 390-425. Berlin: Mouton de Gruyter. [ Links ]
Prinsloo, D.J. 1992. Lemmatization of Reflexives in Northern Sotho. Lexikos 2: 178-191. [ Links ]
Prinsloo, D.J. 1994. Lemmatization of Verbs in Northern Sotho. South African Journal of African Languages 14(2): 93-102. [ Links ]
Prinsloo, D.J. 2002. The Lemmatization of Copulatives in Northern Sotho. Lexikos 12: 21-43. [ Links ]
Prinsloo, D.J. 2003. The Lemmatisation of Adverbs in Northern Sotho. Lexikos 13: 21-37. [ Links ]
Prinsloo, D.J. 2005. Electronic Dictionaries Viewed from South Africa. Hermes, Journal of Linguistics 34: 11-35. [ Links ]
Prinsloo, D.J. 2006. Compiling a Bidirectional Dictionary Bridging English and the Sotho Languages: A Viability Study. Lexikos 16: 193-204. [ Links ]
Prinsloo, D.J. 2009. Current Lexicography Practice in Bantu with Specific Reference to the Oxford Northern Sotho School Dictionary. International Journal of Lexicography 22(2): 151-178. [ Links ]
Prinsloo, D.J. 2012. Die leksikografiese bewerking van verwantskapsterme in Sepedi. Lexikos 22: 272-289. [ Links ]
Prinsloo, D.J. 2014a. A Critical Evaluation of the Paradigm Approach in Sepedi Lemmatisation - The Groot Noord-Sotho Woordeboek as a Case in Point. Lexikos 24: 251-271. [ Links ]
Prinsloo, D.J. 2014b. Lexicographic Treatment of Kinship Terms in an English / Sepedi-Setswana-Sesotho Dictionary with an Amalgamated Lemmalist. Lexikos 24: 272-290. [ Links ]
Prinsloo, D.J. and S.E. Bosch. 2012. Kinship Terminology in English-Zulu / Northern Sotho Dictionaries - A Challenge for the Bantu Lexicographer. Fjeld, R.V. and J.M. Torjusen (Eds). 2012. Proceedings of the 15th EURALEX International Congress, 7-11 August, 2012, Oslo: 296-303. Oslo: Department of Linguistics and Scandinavian Studies, University of Oslo. [ Links ]
Prinsloo, D.J., T.J.D. Bothma and U. Heid. 2014. User Support in e-Dictionaries for Complex Grammatical Structures in the Bantu Languages. Abel, A., C. Vettori and N. Ralli (Eds). 2014. Proceedings of the XVI EURALEX International Congress: The User in Focus, 15-19 July 2014, Bolzano/Bozen: 819-827. Bolzano/Bozen: EURAC Research. [ Links ]
Prinsloo, D.J., T.J.D. Bothma, U. Heid and D.J. Prinsloo. 2017. Direct User Guidance in e-Diction-aries for Text Production and Text Reception - The Verbal Relative in Sepedi as a Case Study. Lexikos 27: 403-426. [ Links ]
Prinsloo, D.J. and G.-M. de Schryver. 1999. The Lemmatization of Nouns in African Languages with Special Reference to Sepedi and Cilubà. South African Journal of African Languages 19(4): 258-275. [ Links ]
Prinsloo, D.J. and G.-M. de Schryver. 2001. Taking Dictionaries for Bantu Languages into the New Millennium - with Special Reference to Kiswahili, Sepedi and isiZulu. Mdee, J.S. and H.J.M. Mwansoko (Eds). 2001. Makala ya kongamano la kimataifa Kiswahili 2000. Proceedings: 188-215. Dar es Salaam: TUKI, Chuo Kikuu cha Dar es Salaam. [ Links ]
Prinsloo, D.J. and G.-M. de Schryver. 2002. Reversing an African-language Lexicon: The Northern Sotho Terminology and Orthography No. 4 as a Case in Point. South African Journal of African Languages 22(2): 161-185. [ Links ]
Prinsloo, D.J. and R.H. Gouws. 1996. Formulating a New Dictionary Convention for the Lemmatization of Verbs in Northern Sotho. South African Journal of African Languages 16(3): 100-107. [ Links ]
Prinsloo, D.J. and R.H. Gouws. 2006. Lexicographic Presentation of Grammatical Divergence in Sesotho sa Leboa. South African Journal of African Languages 26(4): 184-197. [ Links ]
Prinsloo, D.J., U. Heid, T.J.D. Bothma and G. Faaß. 2012. Devices for Information Presentation in Electronic Dictionaries. Lexikos 22: 290-320. [ Links ]
Rundell, M. and P. Stock. 1992a. The Corpus Revolution 1. The first in a series of three reports on the development and use of electronic language corpora and their impact on dictionaries. English Today, The International Review of the English Language 8(2): 9-14. [ Links ]
Rundell, M. and P. Stock. 1992b. The Corpus Revolution 2. A consideration of the practical benefits to English-language lexicographers of the evidence derived from computer corpora (second article of three). English Today, The International Review of the English Language 8(3): 21-29. [ Links ]
Rundell, M. and P. Stock. 1992c. The Corpus Revolution 3. A consideration of the prospects and potential of corpus-and-concordance lexicography (third article of three). English Today, The International Review of the English Language 8(4): 45-51. [ Links ]
Scannell, K.P. 2003-18. An Crúbadán - Corpus Building for Minority Languages. Available online at: http://crubadan.org/.
Scott, M. 1996-2018. WordSmith Tools. Available online at: http://www.lexically.net/wordsmith/.
Sewangi, S.S. 2000. Tapping the Neglected Resource in Kiswahili Terminology: Automatic Compilation of the Domain-specific Terms from Corpus. Nordic Journal of African Studies 9(2): 60-84. [ Links ]
Sewangi, S.S. 2001. Computer-assisted Extraction of Terms in Specific Domains: The Case of Swahili. Unpublished PhD dissertation. Helsinki: University of Helsinki. [ Links ]
Sinclair, J.M. 1966. Beginning the Study of Lexis. Bazell, C.E., J.C. Catford, M.A.K. Halliday and R.H. Robins (Eds). 1966. In Memory of J.R. Firth: 410-430. London: Longmans. [ Links ]
Sinclair, J.M. 1987a. Collins COBUILD English Language Dictionary. London: William Collins Sons & Co. [ Links ]
Sinclair, J.M. (Ed.). 1987b. Looking Up: An Account of the COBUILD Project in Lexical Computing and the Development of the Collins COBUILD English Language Dictionary. London: Collins ELT. [ Links ]
Taljard, E. 2006. Corpus-based Linguistic Investigation for the South African Bantu Languages: A Northern Sotho Case Study. South African Journal of African Languages 26(4): 165-183. [ Links ]
Taljard, E. 2012. Corpus-based Language Teaching: An African Language Perspective. Southern African Linguistics and Applied Language Studies 30(3): 377-393. [ Links ]
Taljard, E. and G.-M. de Schryver. 2002. Semi-automatic Term Extraction for the African Languages, with Special Reference to Northern Sotho. Lexikos 12: 44-74. [ Links ]
Taljard, E. and G.-M. de Schryver. 2016. A Corpus-driven Account of the Noun Classes and Genders in Northern Sotho. Southern African Linguistics and Applied Language Studies 34(2): 169-185. [ Links ]
Tognini-Bonelli, E. 2001. Corpus Linguistics at Work (Studies in Corpus Linguistics 6). Amsterdam: John Benjamins. [ Links ]
Toscano, M. and S.S. Sewangi. 2005. Discovering Usage Patterns for the Swahili amba- Relative Forms cl. 16, 17, 18: Using Corpus Data to Support Autonomous Learning of Kiswahili by Italian Speakers. Nordic Journal of African Studies 14(3): 274-317. [ Links ]
Tummers, J., K. Heylen and D. Geeraerts. 2005. Usage-based Approaches in Cognitive Linguistics: A Technical State of the Art. Corpus Linguistics and Linguistic Theory 1(2): 225-261. [ Links ]
1. Parts of this theoretical discussion are based on sections from Nabirye (2016).
2. The reference to 'real' language is taken from the first-ever corpus-based dictionary, the Collins COBUILD English Language Dictionary (Sinclair 1987a), which was advertised as such.
3. In corpus-linguistic circles, Sinclair may be best known as the founder of the COBUILD (i.e., the Collins Birmingham University International Language Database) project in lexical computing (Sinclair 1987b), and the chief editor of the Collins COBUILD English Language Dictionary (Sinclair 1987a). The managing editor of the latter dictionary was Patrick Hanks.
4. Conversely, typologists may be interested in simply knowing what a language is capable of, and want answers to questions like: 'What is the longest possible verb form in this or that Bantu language?'
5. Also present in the TLex database, but not frequent enough to have been lemmatised, are -vw-, a spoken variant of -v-, and -evaamu 'dare; be brave', the reflexive form of -vaamu.
6. 2 Timothy 2:21
7. The locativised verb -vaawo also has a variant, namely -vaagho, but its frequency is too low to have made it into the lemmatised frequency list.
8. ARVs = antiretrovirals (i.e., drugs to treat HIV)
9. Kodh'eyo was a short-lived newspaper (1997-1998) written in Lusoga.
10. For the value of corpus examples over 'invented' (but more didactic) ones see Fox (1987).


{kind=link}
{kind=link}
{kind=link}