










Servicios Personalizados
Articulo
 Africano (pdf)
Africano (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
Indicadores

Links relacionados
-
 Citado por Google
Citado por Google -
 Similares en Google
Similares en Google
Compartir

 Permalink
PermalinkTydskrif vir Geesteswetenskappe
versión On-line ISSN 2224-7912
versión impresa ISSN 0041-4751
Tydskr. geesteswet. vol.61 no.4-2 Pretoria dic. 2021
http://dx.doi.org/10.17159/2224-7912/2021/v61n4-2a10
RESEARCH AND REVIEW ARTICLES (2)
'n Oorsig oor die ontwikkeling en waarde van Interpreting Research in South Africa (IRSA)
An overview of the development and value of Interpreting Research in South Africa (IRSA)
Hercülene KotzeI; Rone WierengaII
INoordwes-Universiteit, Potchefstroom, Suid-Afrika. ORCID: 0000-0001-5816-8090. E-pos: herculene.kotze@nwu.ac.za
IIVirtuele Instituut vir Afrikaans en Noordwes-Universiteit, Potchefstroom, Suid-Afrika. ORCID: 0000-0002-7172-7165. E-pos: rone@viva-afrikaans.org
OPSOMMING
IRSA (Interpreting Research in South Africa) is 'n omvattende databasis wat bestaan uit 279 bronne oor tolknavorsing in Suid-Afrika of wat deur Suid-Afrikaanse tolknavorsers geproduseer is. IRSA sluit publikasies vanuit die tydperk 1968 tot 2020 in en poog om so inklusief en omvattend moontlik te wees. IRSA het ten doel om die vertrek- en sentraleverwysingspunt vir navorsing oor tolking in Suid-Afrika te wees deur die relevante wetenskaplike publikasies gratis en op een plek beskikbaar te stel. Hierdie artikel bied 'n oorsig oor a) die totstandkoming en ontwikkeling van só 'n databasis met klem op die werkwyse wat toegepas is om die akkuraatheid van die databasis te verseker, b) die publikasies wat by IRSA ingesluit is en die oorhoofse navorsingstendense wat sedert 1968 waargeneem word, en c) die toekoms, instandhouding en voordele wat IRSA vir tolknavorsers in Suid-Afrika kan inhou.
Trefwoorde: bibliometriese studies, tolknavorsing, bronne vir tolknavorsing, tolking databasis, tendense in tolknavorsing, Suid-Afrika
ABSTRACT
IRSA (Interpreting Research in South Africa) is a database consisting of 279 scientific sources regarding interpreting research in South Africa or by South African interpreting researchers. The database includes publications from 1968 to 2020 and aims to be as inclusive and encompassing as possible. The database is housed by the North-West University's Ferdinand Postma library and can be reached via the following link: https://collections.nwu.ac.za/dbtw-wpd/textbases/Tolking-Navorsing/irsa.html.
IRSA aims to be the central point of reference for interpreting research in South Africa. The database has the advantage of providing researchers with easy access to trustworthy publications. The publications included in IRSA are vetted. Only scientific sources, including articles from accredited and nonaccredited journals, books, honours research reports, master's dissertations and doctoral theses are included in IRSA.
This article outlines the challenges faced in the establishment of such a database. These challenges include the unavailability of electronic copies of older publications, which prohibits these publications from being vetted for inclusion in IRSA, and accounting for thoroughness. The article also provides an overview of the observable publication trends. These trends include a) the overarching themes of the publications, such as educational interpreting, legal interpreting and the professionalisation of interpreting in South Africa, b) the research approaches that are prevalent (for instance investigative or descriptive approaches), and c) the types of publications that are favoured (i.e. journal articles, book chapters or graduate research publications). Lastly, an overview of the future purpose of IRSA and the research possibilities that it presents is provided.
Keywords: bibliometrics, Interpreting Research in South Africa, IRSA, interpreting research, sources for interpreting research, interpreting database, interpreting research trends, South Africa
1. Agtergrond
IRSA (Interpreting Research in South Africa) is die naam van 'n aanlyn databasis oor tolknavorsing in Suid-Afrika. Die databasis word gehuisves deur die NWU se Ferdinand Postma-biblioteek en kan besoek word deur die volgende skakel te volg: https://collections.nwu.ac.za/dbtw-wpd/textbases/Tolking-Navorsing/irsa.html. Die databasis bevat 'n versameling tolkverwante publikasies wat in Suid-Afrika of deur Suid-Afrikaanse navorsers gepubliseer is vanaf 1968 tot 2020. IRSA beskik tans oor 297 inskrywings.
As vertrekpunt word die gebruik van sekere terme uitgeklaar. Daar word doelbewus na IRSA as 'n biblioteek-databasis verwys en nie 'n biblioteek-katalogus nie, omdat 'n databasis beskryf kan word as 'n hulpbron wat gebruikers in staat stel om vir gepubliseerde items (in die algemeen of oor 'n spesifieke onderwerp) te soek, terwyl 'n katalogus beskryf kan word as 'n hulpbron wat jou toelaat om items te soek wat deur 'n spesifieke instelling (soos 'n biblioteek) besit word (Illinois Library, 2020). Die voordele verbonde aan die gebruik van 'n databasis is as volg: Databasisse kan as betroubaar bestempel word, aangesien die meeste items wat daarin vervat word, aan 'n keurproses onderwerp is en is dus, in teenstelling met 'n opiniestuk, meer betroubaar (Chen et al., 2020:1056). In hierdie opsig stel 'n databasis 'n mens in staat om vas te stel of die bron geloofwaardig is deur bepaalde inligting weer te gee, soos die outeur se naam en die item se publikasiebesonderhede. Nog 'n voordeel van 'n databasis is dat, deur gebruik te maak van sleutelterme, 'n soektog pasgemaak kan word (Chen et al., 2020:1056). Sleutelwoorde sluit gewoonlik vakterminologie in (wat die soektog meer effektief kan maak), terwyl byvoorbeeld die outeursnaam, publikasietitel en die jaartal gebruik kan word om die soektog te verfyn. Laastens is dit ook soms die geval dat 'n databasis 'n volteksweergawe van die betrokke item bevat. Dit is egter nie in alle gevalle só nie, omdat kopieregwette dit soms nie toelaat nie. Tog, kan sommige biblioteke 'n volteksweergawe aan so 'n databasisitem koppel indien die biblioteek ingeteken is op die publikasie, wat dan beteken dat gebruikers van die biblioteek (soos dosente en studente in die geval van die NWU se Ferdinand Postma-biblioteek) ook toegang tot die volteksweergawe het.
IRSA het sy ontstaan te danke aan die behoefte om makliker toegang tot en inligting oor tolknavorsing in Suid-Afrika te kry. Tipiese soektogte na publikasies oor 'n spesifieke onderwerp verg meer tyd en dikwels herhaaldelike soektogte wanneer 'n soekenjin of katalogus eerder as 'n gespesialiseerde databasis gebruik word. Selfs meer as een soektog lewer ook nie altyd die gewenste resultate op nie. 'n Databasis wat alles oor dié een onderwerp insluit kan hierdie probleme die hoof bied. Dit is ook waar dat ander soortgelyke databasisse toenemend ontwikkel word en as bruikbaar vir navorsers beskou word. Voorbeelde hiervan sluit die BNTL (Bibliografie Nederlandse Taal- en Letterkunde), die DBAT (Digitale Bibliografie van die Afrikaanse Taalkunde), die DBAL (Digitale Bibliografie van die Afrikaanse Letterkunde) en die Translation Studies Bibliography (TSB) in.
Met die voorafgaande as agtergrond, poog ons in hierdie artikel om 'n oorsig te bied van die ontwikkeling en instandhouding van IRSA, insluitende die uitdagings om so 'n databasis te ontwikkel, asook die oorhoofse tendense wat in die databasis waargeneem word. Vorige publikasies oor hierdie onderwerp het slegs 'n gedeelte van die data wat ingesamel is bespreek, terwyl hierdie die eerste een is wat die volledige databasis betrek: dit voeg dus bykans 'n dekade se data en -besprekings by tot die gesprek oor tolknavorsing in Suid-Afrika. Verder sal die artikel 'n langtermynoorsig bied oor die rol wat IRSA in tolknavorsing in Suid-Afrika kan speel.
1.1 Die ontwikkeling van IRSA
Verskillende benaderings tot die ontwikkeling van 'n databasis word hedendaags gebruik - en die redes en/of doelwitte daarvan verskil ook. Die terrein ter sprake is dié van bibliometriese studies. Van Doorslaer (2016) is van mening dat hierdie tipe ondersoeke veel meer gebruiklik as navorsingsmetode geword het. Van Doorslaer (2016:170) ondersteun GrbiC (2013:20) se stelling dat bibliometriese studies beskou kan word as 'n empiriese vertakking van die sosiale wetenskappe. Van Doorslaer (2016:171) meen verder dat bibliometriese studies se onlangse sukses toegeskryf kan word aan die kwantifisering van navorsingsuitsette wat toenemend ook (soos in ander wetenskappe) in die sosiale wetenskappe teëgekom word. Een van die metodes wat deel vorm van bibliometriese studies is die sogenaamde publikasietellings, wat die navorser in staat stel om akademiese literatuur en die impak daarvan te meet en kwantitatief te bestudeer.
Grbic en Pöllabauer (2008) skryf dat publikasietellings waardevolle inligting oor weten-skaplike prosesse kan lewer, soos die ontwikkeling van 'n dissipline en die verwantskappe tussen navorsingsterreine. Afhangende van die fokus van die betrokke studie, kan publikasie-tellings insigte lewer oor individuele navorsers, navorsingspanne, projekte, instellings, dissiplines en geografiese streke of lande. Wanneer hierdie inligting gekategoriseer word, kan dit op mikrovlak (individuele navorsing), mesovlak (groepsnavorsing) en makrovlak (nasionale navorsing) uitsette oplewer. Borgman (1990, 2000) beskryf die veranderlikes wat met hierdie metodes bestudeer kan word en gebruik die term "artefacts" - hierna artefakte - om na publikasies te verwys en sluit artikels, boeke, gepubliseerde kongresvoordragte en vaktydskrifte by hierdie term in.
In die lig hiervan bestudeer ons in hierdie projek artefakte op 'n makrovlak: die publikasietendense oor tolking in Suid-Afrika.
1.2 Metode: Die bou van 'n databasis oor tolknavorsing
Die projek en die proses om die databasis te skep, het in verskillende fases plaasgevind. Die eerste fase was die insameling van data, of te wel artefakte. Ten einde 'n databasis te ontwikkel wat so volledig en geldig moontlik is, is 'n sistematiese literatuuroorsig as data-insamelings-metode gekies.
1.2.1 'n Sistematiese literatuuroorsig as data-insamelingsmetode
Die doel van 'n sistematiese literatuuroorsig (hierna SL) is om die literatuur in 'n spesifieke navorsingsgebied te ondersoek ten einde 'n basis of vertrekpunt vir alle lede van die akademiese gemeenskap te bied. 'n SL is 'n diepgaande literatuurondersoek wat nie nuwe data insamel nie, maar bestaande publikasies as primêre data beskou. Okoli en Schabram (2010:6-7) spesifiseer verskeie stappe waaruit 'n SL moet bestaan om as sodanig beskou te kan word en sodoende te voldoen aan 'n sistematiese en deeglike standaard wat uiteindelik 'n SL van 'n gewone literatuurondersoek onderskei. Hierdie stappe sluit in:1 a) die doel van die ondersoek, b) protokol en opleiding, c) literatuursoektog(te), d) praktiese sifting, e) gehaltebepaling, f) data-onttrekking, g) sintese van die studie, en h) verslagdoening.
Kortliks kan die stappe soos volg beskryf word: Die studie moet eerstens 'n duidelike doel hê wat aan die hele navorsingspan gekommunikeer word. IRSA se doel was om 'n oorsig te bied oor die tolknavorsing wat tot op hede in Suid-Afrika of deur Suid-Afrikaners opgelewer is. 'n Bekende internasionale databasis, die Translation Studies Bibliography (TSB), is in 2002 gevestig. Anders as IRSA, is die primêre fokus van hiérdie bibliografie eerder vertaling as tolking, alhoewel publikasies oor tolking wel ingesluit is. Die TSB is deur KU Leuven, die Europese Gemeenskap vir Vertaalstudies en John Benjamins Uitgewery ontwikkel. Die TSB is dus 'n internasionale databasis wat beoog om al die publikasies oor die oordrag van mediasie, alle aspekte van intra- en interlinguistiese vertaling, interkulturele kommunikasie, adaptasie, tolking, lokalisering, multimedia vertaling, talige mediasie, terminologie en dokumentasie wêreldwyd in te sluit (Gambier & Van Doorslaer, 2021). In kontras met die TSB, fokus IRSA uitsluitlik op publikasies in en oor tolking in Suid-Afrika. IRSA het 'n nouer fokus as die TSB en is dus geskep met die doel om 'n deurslaggewende bron te wees vir tolkstudie in Suid-Afrika.
Volgende moet die protokol en opleiding vasgestel word. Die projek is deur een persoon behartig, dus het die nodige protokolle en opleiding net op die eerste outeur van die publikasies oor IRSA betrekking gehad. Daar is reeds oor die nodige opleiding beskik (die gebruik van die MS Office-pakket asook die sagtewareprogram Zotero). Die protokol wat gevolg is, word in die onderstaande stappe deeglik uiteengesit.
Hierná moet volledige detail oor die literatuursoektog(te) gelewer word om sodoende die omvattendheid van die soektog(te) te bevestig. In hierdie opsig is data tydens twee geleenthede ingesamel deur gebruik te maak van geredelik beskikbare akademiese soekenjins: NEXUS (die Nasionale Navorsingstigting se databasis oor voltooide verhandelinge en proefskrifte), SAePublications (South African electronic publication database), National ETD (die databasis van digitale verhandelinge en proefskrifte), ISAP (Index of South African periodicals) en OneSearch ('n omvattende soekenjin wat al die bostaande kategorieë bevat en die vermoë het om items op te spoor wat nie in die bostaande databasisse is nie).
Om te verseker dat die databasis so volledig moontlik bly, word kollegas en kundiges in die veld ook gekontak en gevra om hul publikasies op die databasis na te gaan - asook dié van hulle nagraadse studente. Literatuursoektogte word sesmaandeliks gedoen om die jongste publikasies in die databasis op te neem. Deel van die proses is om baie eksplisiet te wees oor watter artefakte ingesluit word en watter nie ingesluit word nie. Die volgende ontwikkelingsfase van IRSA is om die publikasies van Suid-Afrikaanse tolknavorsers in die TSB na te gaan om sodoende te verseker dat IRSA volledig is.
Na afloop hiervan moet praktiese sifting en gehaltebepaling plaasvind. Omdat die doel is om 'n databasis beskikbaar te stel wat so volledig moontlik is, is geen artefakte uitgesluit nie en die databasis sluit tans verslae (hoofsaaklik regeringsverslae), joernaalartikels (beide geakkrediteer en niegeakkrediteer), boeke,2 doktorale proefskrifte, meestersgraadstudies en honneursverslae in. Die databasis is wel 'n wetenskaplike databasis, dus word niewetenskaplike tekste (soos nuusberigte of populêre tydskrifartikels) nie hierby ingesluit nie en is daar ook nie in hierdie verband ondersoek ingestel nie. 'n Uitsondering word gemaak vir regeringsverslae, omdat hierdie verslae dikwels akademiesgefundeerd is en toonaangewend is vir tolknavorsing in Suid-Afrika. Dit is verder 'n vereiste dat die studie moet aandui of die gehalte van die publikasies nagegaan is en enigiets op grond daarvan uitgesluit is. In hierdie opsig is geen publikasies uit IRSA uitgelaat op grond van die gehalte van die navorsingsmetode of -uitsette wat daarin vervat word nie.
Die voorlaaste stap is data-onttrekking. Data-onttrekking beteken iets anders vir elke SL. Tydens hierdie studie is verskillende metodes gebruik om spesifieke data te onttrek ten einde geskikte analises te maak. Sodra die bostaande stappe voltooi is, word die data oplaas ontleed en die resultate daarvan opgeskryf. Hierdie proses is tweeledig.
Eerstens is die data met gebruik van ATLAS.ti onttrek en bepaalde resultate is opgelewer. Daar is breedvoerig oor hierdie proses verslag gedoen in Kotzé en Wallmach (2020). Tweedens is die data volgens verskillende kodes en kodegroepe ook in Excel ingelees ten einde beskrywende statistiese toetse daarop te kan doen.
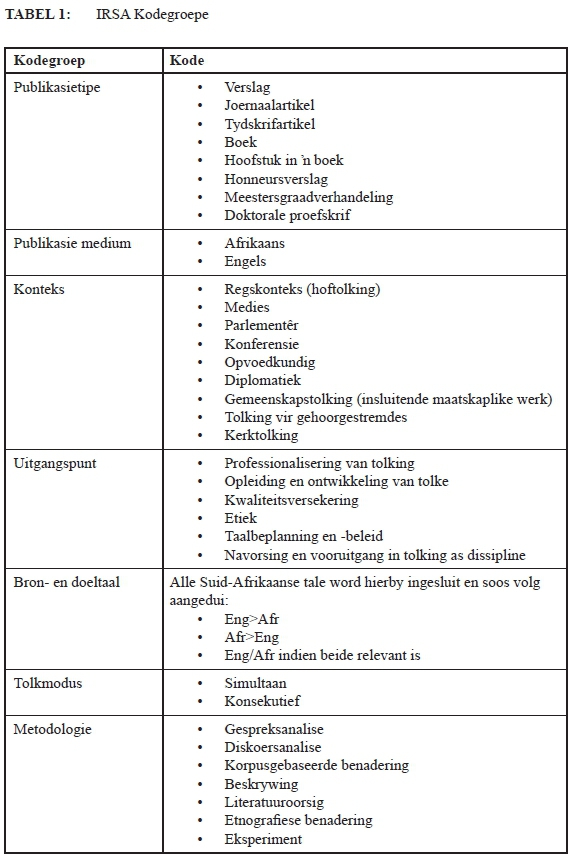
Sewe kodegroepe is deurgaans gebruik: a) die publikasietipe, b) die taalmedium van die publikasie, c) die oorhoofse konteks waarin die teks gepubliseer is, d) die uitgangspunt van die publikasie, e) die doel- en brontaal waaroor die publikasie handel (in gevalle waar die doel- of brontaal ongespesifiseerd is, is dit ook so aangeteken in die databasis), f) die tolkmodus (dit wil sê simultaan of konsekutief), en g) die metodologie wat in die publikasie gebruik is. Vir elkeen van hierdie kodegroepe is vasgestelde kodes bepaal. Hierdie kodes word in die onderstaande tabel aangebied.
Daar word breedvoerig verslag gedoen oor die kodegroepe en die nut van die kodes in beskrywende statistiese analises in Kotzé en Wallmach (2020) asook Kotzé (2020). In Kotzé (2020) word onder andere verslag gedoen oor die verhouding tussen die tale wat as medium dien vir tolknavorsingspublikasies in Suid-Afrika, die toenemende gewildheid en behoefte aan tolknavorsing in mediese kontekste, en die verhouding tussen die gebruik van tolkmodusse in die Suid-Afrikaanse konteks.
Laastens kan die datastel egter nooit as "volledig" bestempel word nie, aangesien nuwe publikasies deurlopend die lig sien. Soos reeds genoem, word daar gepoog om sesmaandeliks 'n aanvullende rondte data-insameling te doen. Die bywerkingsproses geskied op dieselfde wyse as hier bo uiteengesit. Nuwe inskrywings word onmiddellik by die databasis bygevoeg en geen tekste word teruggehou tydens hierdie proses nie. Sodoende word verseker dat die databasis deurgaans so volledig moontlik is. In sommige gevalle neem dit egter 'n wyle vir outeurs om hul publikasies op die databasis na te gaan. Indien 'n outeur aandui dat 'n publikasie nie op die databasis verskyn nie, word die betrokke publikasie so gou moontlik by die databasis ingesluit.
Verder, om die databasis so nuttig moontlik te maak, is dit belangrik dat die breër navorsingsgemeenskap daartoe toegang het, en dus is daar besluit om die data in 'n aanlyn databasis te omskep. Hiervoor is die DBText-databasisprogrammatuur gebruik.
1.2.2 Is IRSA 'n nuttige hulpbron?
Die waarde van 'n databasis soos IRSA kan op verskillende maniere gemeet word. Vanuit 'n wetenskaplike oogpunt is dit moontlik om, soos reeds genoem, byvoorbeeld publikasietendense oor tolking te identifiseer. Hierdie tendense kan 'n reeks kategorieë insluit onder meer die onderwerpe wat nagevors word of die metodologieë wat die prominentste gebruik word. Verder kan beskrywende statistiek insigte lewer oor die korrelasies tussen sekere temas soos die tolkmodus (simultaan en/of konsekutief) en die tipe tolking (byvoorbeeld opvoedkundige of mediese tolking). Kotzé (2020) en Kotzé en Wallmach (2020) rapporteer reeds noukeurig oor beide die tipiese publikasietendense wat hier bo genoem word asook die resultate van die beskrywende statistiese toetse wat tydens die studie gedoen is. Die langtermynoorsig oor die navorsing wat oor tolking in Suid-Afrika opgelewer is, is egter nie in hierdie publikasies aangebied nie. Die sagtewareprogram Zotero word gebruik om hierdie langtermynoorsig uiteen te sit en 'n kort oorsig hieroor word in die onderstaande afdeling aangebied.
2. Tolknavorsing in Suid-Afrika: 'n Tydlyn
Zotero - 'n verwysingshulpbron - is 'n oopbronnavorsingsprogram waarmee navorsingsitems gestoor en georganiseer kan word. Die tipe items sluit teks, video en klank in. Alhoewel Zotero nie diepgaande data-analises kan doen nie, is dit moontlik om 'n bibliografie daarmee te genereer asook 'n nuttige tydlyn en gepaardgaande verslae. Die program is uiters gebruikers-vriendelik en elke datapunt (of te wel publikasie) bevat velde wat van toepassing is op die betrokke item, byvoorbeeld wanneer 'n joernaalartikel gekies word as die tipe inskrywing, is die gepaardgaande velde wat ingevul moet word slegs van toepassing op joernaalartikels en nie, byvoorbeeld, 'n proefskrif nie.
Hier onder verskyn 'n skermgreep van die data soos voorgestel in Zotero vir die beraamde tydperk 1994 tot 2004. Die volledige tydlyn kan slegs op 'n rekenaarskerm gesien word, aangesien daar te veel inligting is. Hierdie skermskoot is 'n goeie aanduiding van hoe die tydlyn lyk. Soos reeds genoem, word elke publikasie ingesleutel volgens die inligting wat betrekking daarop het, hierdie werkswyse kan in die skermskoot waargeneem word: Nagraadse studies word voorgestel deur 'n graduandihoed, hoofstukke in boeke word voorgestel deur 'n oopgeslaande boek en joernaalartikels lyk soos bladsye.
Figuur 1 dui aan hoe vinnig tolknavorsing na 1994 gegroei het. Vóór 1994 het enkele publikasies oor tolking die lig gesien en dit wat wel gepubliseer is, was in nie-geakkrediteerde tydskrifte of joernale, regeringsverslae en enkele nagraadse studies gepubliseer - die somtotaal van publikasies binne hierdie tydperk is 16.

Die eerste publikasie wat opgespoor is, Die opleiding van vertalers en tolke, is 'n verslag wat in 1968 deur die Taaldiensburo uitgegee is en handel oor die opleiding van vertalers en tolke in Suid-Afrika. Hierdie verwysing het 'n groot uitdaging vir die projek ingehou: Ongelukkig, soos met die meeste ou publikasies, was dit tot op hede nie moontlik om 'n kopie van hierdie teks op te spoor nie en bestaan daar nie elektroniese kopieë daarvan nie. Die enigste bewys dat hierdie publikasie wel bestaan, is verwysings daarna in ander publikasies. Dit bring mee dat die publikasie nie werklik tematies of statisties ontleed kon word nie. Sekere afleidings kan wel uit die verwysings- en publikasie-inligting gemaak word en, soos reeds verduidelik, is hierdie tipe publikasies nie uit die databasis uitgelaat nie, aangesien dit belangrike insigte gee oor die pad wat tolknavorsing tot op hede gestap het. Alhoewel hierdie ouer tekste moeilik is om op te spoor, word daar deurgaans pogings aangewend om dit wel te doen en moontlikhede om toestemming vir digitisering te kry, word ook ondersoek.
Wanneer die tydlyn bestudeer word, vind 'n skielike toename in tolknavorsing om 1994 met die demokratisering van Suid-Afrika plaas. Balfour (2007:36) beskryf die sosiale impak van demokrasie en transformasie, en beaam die noodsaaklikheid van die basiese mensereg: om te kan deelneem aan demokrasie in sy/haar moedertaal (Suid-Afrika, 1996). In dieselfde trant argumenteer Beukes (2009:36) dat die beleide wat post-1994 ontwikkel is om meertaligheid te bewerkstellig en te ondersteun, 'n kritieke rol speel in die afdoening van afsonderingspraktyke, die implementering van transformasie en die bevordering van maat-skaplike geregtigheid. Sy verwys ook na verskeie wetgewende stappe wat geneem is om die verskeie beleide en beleidsprosesse te operasionaliseer. Dit sluit onder andere in: a) die totstandkoming van die Pan South African Language Board Act (1995), b) die Minister van Kuns, Kultuur, Wetenskap en Tegnologie se Taalplan-taakspan (1996) en c) die Nasionale Taalbeleidsraamwerk (NLPF - 2003). Verskeie ander strukture is ook tot stand gebring met die oog op beleidsimplementering, en Beukes (2009:36) noem spesifiek die Nasionale Taaldiens (1994) en die Pan Suid-Afrikaanse Taalraad (PanSALB) (1996). Die bostaande verwikkelinge het ruimte geskep om taalkwessies na te vors - 'n tendens wat volgehou is in die publikasies wat sedertdien verskyn het.
Die data wat in Tabel 2 en 3 aangebied word, is ingedeel volgens die jaartal, navor-singsbenadering, onderwerp en die aantal publikasies wat daaroor gehandel het. Ten opsigte van die navorsingsbenaderinge wat in die publikasies toegepas is, is die publikasies in twee kategorieë verdeel, naamlik beskrywend (sonder enige data-analises) en ondersoekend (met data-analises). Die rede hiervoor is gewoon om die tipe navorsing wat gedoen is uit te beeld en patrone te soek. Die onderwerp is rofweg verdeel om soortgelyke publikasies saam te groepeer, maar nie te veel te veralgemeen nie, sodat die verskille in onderwerpe ook duideliker na vore kan kom.
Twee publikasies word hier aangebied ter demonstrasie van beskrywende en onder-soekende navorsingsbenaderinge.
Lesch publiseer in 2014 'n artikel, getiteld "Die waarde en uitdagings van diensleer vir tolkopleiding: die ervaring van die tolkopleidingsprogram aan die Universiteit Stellenbosch", waarin hy die aard, voordele en nadele van diensleer vir tolke uiteensit. Lesch (2014) bied sy bevindinge oor die ervarings van leerlingtolke as 'n teoretiese verkenning aan. Geen statistiek of kwalitatiewe gegewens word in hierdie artikel aangebied nie. Hierdie publikasie is dus beskrywend van aard.
Op haar beurt publiseer Makhubu in 2015 'n artikel met die titel "A systemic modelling approach to interpreting service delivery". Alhoewel Makhubu nie empiriese statistiese resultate aanbied nie, is hierdie artikel ondersoekend van aard, omdat sy steeds data ingesamel het, besin het oor die data-insamelingsproses en 'n hipotese gestel en getoets het. Makhubu (2015) maak gebruik van 'n sistemiese model om 'n teoretiese model vir tolking in universiteitskon-tekste te ontwikkel. Makhubu (2015) het twee uitgangspunte wat as hipoteties van aard beskou kan word: a) teoretiese modelle vir tolking kan vanuit sistemiese modelle ontwikkel word, b) die teoretiese model wat ontwikkel word, is geldig en bruikbaar in die praktyk. Hierdie uitgangspunte word beproef in die artikel en is dus 'n voorbeeld van 'n ondersoekende navorsingsbenadering.
Tabel 1 bevat die navorsingsbenadering, onderwerp en aantal publikasies wat oor tolking opgespoor kon word vir die tydperk tussen 1994 en 1999, en word gevolg deur 'n bespreking van die data:
Die meerderheid publikasies wat tussen 1994 en 1999 verskyn het, kan as beskrywend bestempel word en handel oor verskeie onderwerpe. Dit is egter duidelik dat die onderwerp wat die meeste aandag geniet het, die opleiding van tolke was. Dit maak ook sin in die lig daarvan dat Suid-Afrika tydens post-demokratisering 'n groter fokus op meertaligheid geplaas het en die skielike behoefte aan opgeleide tolke baie groot was (verwys onder meer na die Suid-Afrika Departement van Onderwys 1997, 2002 en 2009). Die publikasies beskryf meestal die realiteite, uitdagings en benaderings soos dit verband hou met tolkopleiding en verskyn in die meeste gevalle in niegeakkrediteerde tydskrifte.
Die tolkopleiding-onderwerp skakel ook met 'n aantal publikasies oor taalbeleidskwessies (byvoorbeeld Wise & Van Zyl, 1994; Pluddemann, 1999) en die professionalisering van die bedryf (sien onder meer Du Plessis, 1997a, 1997b en 1999). Enkele publikasies handel egter oor tolking soos dit in die buiteland daar uitsien, en is ingesluit in hierdie databasis aangesien al hierdie items in 'n plaaslike boek getiteld Liason interpreting in the community (Erasmus et al., 1999) verskyn het en dus steeds binne die bestek van hierdie studie val.
Om dieselfde redes word 'n aantal gepubliseerde internasionale kongresverhandelinge ("conference proceedings") ook ingesluit by die databasis, omdat hierdie kongresbydraes deur Suid-Afrikaanse navorsers gelewer is en verslag doen oor Suid-Afrikaanse tolkkwessies (verwys onder meer na Lesch, 2008 en 2009d vir voorbeelde hiervan). Die betrokke publikasies tref ook vergelykings tussen Suid-Afrika en die buiteland, wat dit tersaaklik vir die IRSA-databasis maak.
Dit is opmerklik dat die eerste ondersoekende studies onderskeidelik oor tolking in die mediese veld en die regsomgewing gedoen is, 'n tendens wat ook in die volgende periodes gesien kan word:
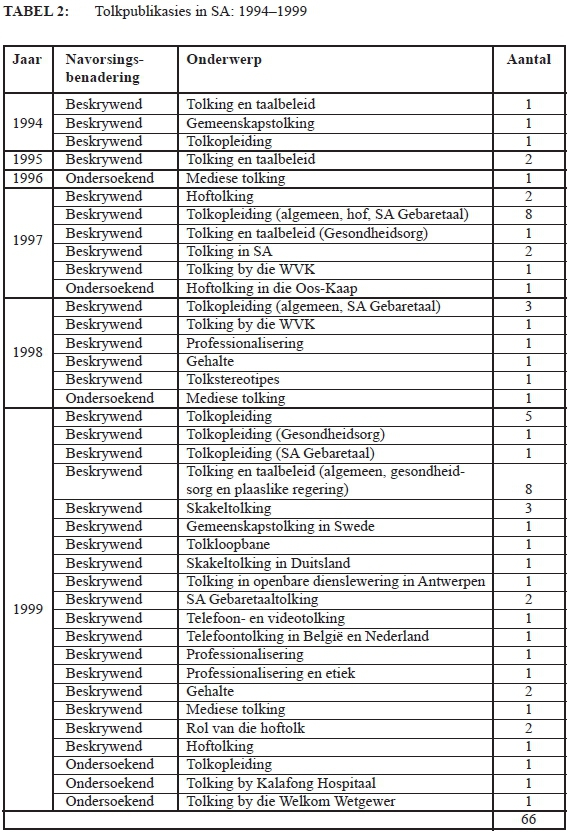
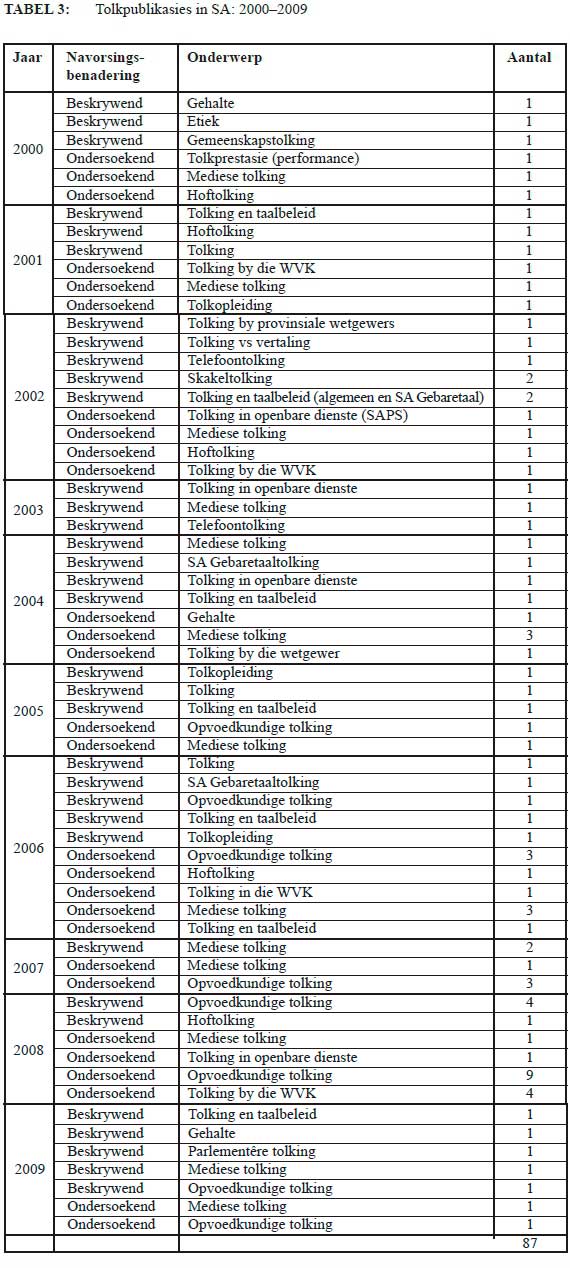
Tabel 3 gee inligting oor tolkpublikasies wat gepubliseer is in die tydperk 2000 tot 2009. 'n Opvallende verwikkeling is die groei in die aantal ondersoekende studies wat gedoen is teenoor die beskrywende studies, wat daarop dui dat tolking as 'n navorsingsonderwerp aansienlik meer belangstelling gedurende hierdie tydperk ontvang het. Kotzé (2020:56) rapporteer ook dat 'n aantal publikasies gedurende hierdie tydperk gespruit het uit nagraadse studies wat die voorafgaande stelling bevestig. 'n Toename in die aantal publikasies oor die algemeen kan ook gesien word en die onderwerpe waaroor outeurs geskryf het, spreek van die belangstelling in 'n verskeidenheid tolkverwante onderwerpe.
Een van hierdie onderwerpe is opvoedkundige tolking. In 2008 publiseer Verhoef en Du Plessis 'n boek, saamgestel deur hoofstukke geskryf deur verskeie Suid-Afrikaanse outeurs, getiteld Multilingualism and Educational Interpreting, wat volledig toegewy is aan die verklaring, bestudering en toepassing van opvoedkundige tolking in Suid-Afrika. Studies oor hoftolking en mediese tolking het ook heelwat toegeneem, veral as dit gaan om ondersoekende navorsing en verskeie hiervan is in geakkrediteerde tydskrifte, onder meer Papers in Education, Journal for Language Teaching, Southern African Linguistics and Applied Language Studies en Stellenbosch Papers in Linguistics Plus, gepubliseer.
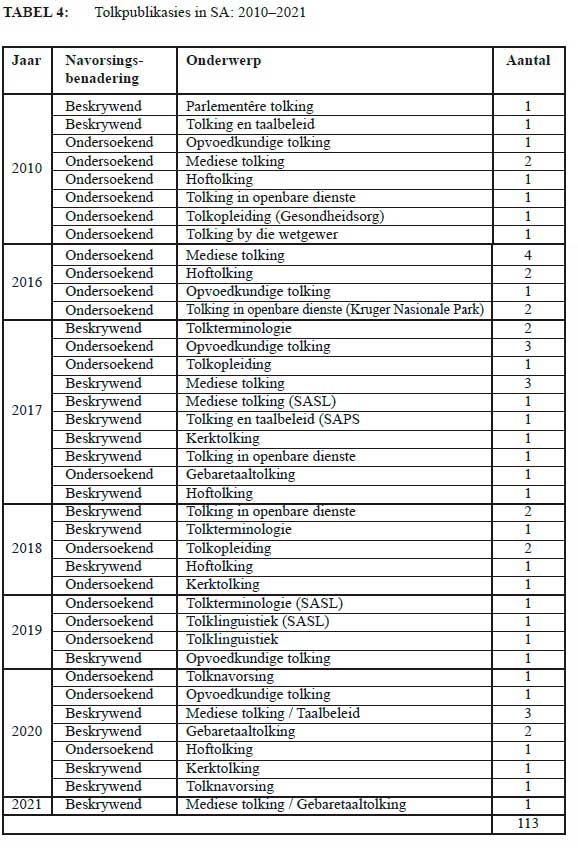
Daar word 'n toename in die aantal tolkpublikasies waargeneem vir die tydperk 2010 tot 2020. In hiérdie dekade is daar 112 publikasies teenoor die 87 wat in die dekade daarvoor verskyn het. In kontras met die styging in die aantal ondersoekende publikasies wat sedert 2001 waargeneem is en in 2014 'n hoogtepunt bereik, word 'n skerp styging in die aantal beskrywende publikasies vir 2017 en 2018 waargeneem. Die onderstaande lyngrafiek beeld die oorhoofse neigings in die navorsingsbenaderinge oor die laaste twee dekades visueel uit.
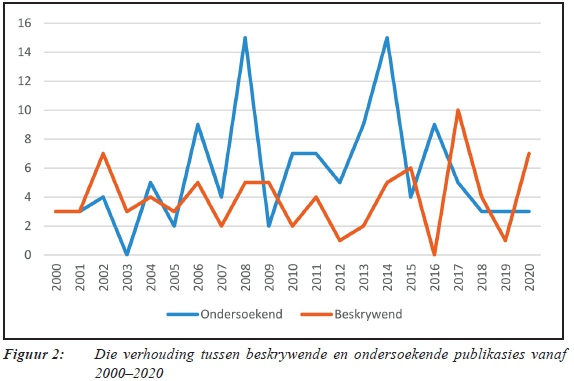
Hierdie styging in die beskrywende publikasies gaan gepaard met 'n ontluikende belangstelling in tolknavorsing en tolkterminologie as navorsingsonderwerpe. Die neiging na opvoedkundige en regstolking as oorhoofse navorsingsonderwerpe wat reeds sedert 1994 waargeneem is, word in die tolknavorsing van die laaste dekade voortgesit, terwyl kerktolking en mediese tolking ook populêre onderwerpe in hierdie tydperk is.
3. Die toekoms en langtermyngebruiksvoordele van IRSA
IRSA se hoofdoel is, soos reeds genoem, om navorsing oor tolking in Suid-Afrika te ver-gemaklik deur al die relevante publikasies oor tolking in Suid-Afrika of deur Suid-Afrikaanse navorsers in een sentrale databasis beskikbaar te stel. 'n Aantal navorsingspublikasies met die IRSA-databasis as sentrale bron het reeds die lig gesien, onder meer Kotzé (2020), Kotzé en Wallmach (2020).
Die IRSA-databasis bied egter nog vele navorsingsmoontlikhede wat nog nie deur tolknavorsers ontgin is nie. Onder andere bied die databasis navorsers die geleentheid om gapings in die reeds bestaande gepubliseerde navorsingsonderwerpe soos opvoedkundige tolking, regstolking en die professionalisering van tolking in Suid-Afrika te identifiseer met die oog op toekomstige navorsing binne hierdie onderwerpe. In hierdie verband is IRSA 'n nuttige hulpbron vir nagraadse studente en hulle studieleiers.
IRSA kan verder gebruik word om nuwe of steeds onondersoekte navorsingsonderwerpe in Suid-Afrikaanse tolknavorsing uit te wys en te ondersoek. Laastens kan die databasis self dien as bron vir gebruikersnavorsing, studies wat die konteks van tolknavorsing in Suid-Afrika as fokuspunt het en vir bibliometriese studies wat die impak van publikasies, die verhoudings tussen outeurs of navorsingsinstansies en die sosiale netwerke binne die tolkgemeenskap in Suid-Afrika wil bestudeer.3
In die afgelope 4 jaar is bykans 353 soektogte reeds op IRSA uitgevoer en is daar reeds navorsers wat die databasis in hul ondersoekproses benut het. Tog, word daar beoog dat IRSA die vertrek- en sentrale verwysingspunt vir alle navorsing oor tolking in Suid-Afrika of deur Suid-Afrikaners moet word. Om hierdie doelwit te bereik, sal groter bewusmakingsveldtogte geloods moet word om potensiële gebruikers in te lig oor die bestaan en gebruiksmoontlikhede van IRSA. Tans is daar geen aktiewe bemarkingsveldtogte in plek om die nut van hierdie databasis aan die breër publiek bekend te maak nie. Die gevolg is dat die gebruikers wat IRSA tot hede besoek het van die databasis bewus gemaak is deur kongresbydraes, verwysings na IRSA in akademiese navorsingspublikasies, of deur middel van gesprekke met ander wat reeds bewus is van die databasis. Daar word dus onderneem om die databasis op institusionele en departementele sosiale media platforms aan tolke, tolknavorsers en -studente te bemark met die oog op toekomstige ontwikkeling in Suid-Afrikaanse tolknavorsing.
4. Slotsom
IRSA is 'n databasis wat verskeie voordele vir tolknavorsing in Suid-Afrika kan inhou. Hierdie voordele sluit onder andere in dat dit navorsers gratis toegang gee tot bibliografiese inligting oor 'n verskeidenheid wetenskaplike publikasies oor tolking in Suid-Afrika. Die soektogte wat op IRSA uitgevoer kan word, is ook meer akkuraat en betroubaar as algemene aanlyn soektogte, omdat hoofsaaklik gespesialiseerde wetenskaplike publikasies by die databasis ingesluit word. So ook kan IRSA vir gebruikers die geleentheid bied om neigings en tendense in Suid-Afrikaanse tolknavorsing te identifiseer, en leemtes in hierdie tendense te ondersoek. IRSA word deurgaans bygewerk, sodat die nuutste publikasies ingesluit word, en die strewe na omvattendheid en akkuraatheid volgehou kan word.
IRSA hou verdere navorsingsmoontlikhede in, onder meer kan 'n studie onderneem word om die navorsingstendense wat in IRSA opgemerk is, te vergelyk met dié van die internasionale publikasies wat in TSB voorkom. Só 'n vergelyking kan 'n aanduiding gee van hoe Suid-Afrikaanse tolknavorsing aansluiting vind by internasionale temas, ondersoekmetodes en die breër diskoers.
IRSA het ook die potensiaal om as templaat te dien vir soortgelyke databasisse in ander velde. 'n Databasis wat fokus op die ander fasette van taalpraktyk, soos vertaling en teksredaksie in Suid-Afrika, ontbreek nog. Só 'n databasis kan nuttig wees vir bibliometriese ondersoeke in hierdie navorsingsterreine en kan help om die leemtes en vooruitgang in die Suid-Afrikaanse konteks - veral met betrekking tot die ontwikkeling van hierdie dissiplines in die inheemse tale van Suid-Afrika - uiteen te sit.
BIBLIOGRAFIE
Balfour, R. 2007. University language policies, internationalism, multilingualism, and language development in South Africa and the UK. Cambridge Journal of Education, 37(1):35-49. [ Links ]
Beukes, A-M. 2009. Language policy incongruity and African languages in postapartheid South Africa. Language Matters, 40(1):35-55. [ Links ]
Borgman, CL. 1990. Editor's introduction. In CL Borgman (ed.). Scholarly communication and bibliometrics. Newbury Park: Sage, pp 10-27. [ Links ]
Borgman, CL. 2000. Scholarly communication and bibliometrics revisited. In B Cronin, & HB Atkins (eds). The web of knowledge. A festschrift in honor of Eugene Garfield. Medford, NJ: Information Today, pp.143-162. [ Links ]
Breed, A, Carstens, WAM & Olivier, JAK. 2016. Die DBAT: 'n Onbekende digitale taalkundemuseum. Tydskrif vir Geesteswetenskappe, 56(2):391-409. [ Links ]
Chen, H, Islam, AYM, Gu, X, Teo, T & Peng, Z. 2020. Technology-enhanced learning and research using databases in higher education: The application of the ODAS model. Education Psychology, 40(9):1506-1075. [ Links ]
Du Plessis, LT. 1997a. Interpreting in South Africa. In Du Plessis, LT (ed.). Onderweg na vertaal- en tolkopleiding in Suid-Afrika. Acta Varia, 3. UOFS occasional papers, pp. 1-9. [ Links ]
Du Plessis, LT. 1997b. Tolking en die Waarheids- en Versoeningskommissie. In Lotriet, A (ed.). Colloquium gerechtstolken: Theorie, praktijk en opleiding / Colloquium on legal interpreting: Theory, practice and training. Acta Varia, 4. UOFS occasional papers, pp. 144-161. [ Links ]
Du Plessis, LT. 1997c. Opleiding in tolking. In Du Plessis, LT (ed.). Onderweg na vertaal- en tolkopleiding in Suid-Afrika. Acta Varia, 3. UOFS occasional papers, pp. 46-50. [ Links ]
Du Plessis, LT. 1999. The translation and interpreting scenario in the new South Africa. In Erasmus, M, Mathibela, L, Hertog, E & Antonissen, H (eds). Liaison interpreting in the community. Pretoria: Van Schaik, pp. 3-28. [ Links ]
Du Plessis, LT. 2008. Educational interpreting at the University of the Free State: A language policy analysis. In Verhoef, M & Du Plessis, LT (eds). Multingualism and educational interpreting: Innovation and delivery. Pretoria: Van Schaik, pp. 18-33. [ Links ]
Erasmus, M, Mathibela, L, Hertog, E & Antonissen, H (eds). 1999. Liaison interpreting in the community. Pretoria: Van Schaik. [ Links ]
Gambier, Y & Van Doorslaer, L. 2021. Welcome to the Translation Studies Bibliography. Retrieved from https://benjamins.com/online/tsb. [ Links ]
Grbic, N. 2013. Bibliometrics. In Y Gambier, & L Van Doorslaer (eds). Handbook of translation studies, Vol. 4. Amsterdam: John Benjamins, pp. 20-24. [ Links ]
Grbic, N, & Pöllabauer, S. 2008. To count or not to count: Scientometrics as a methodological tool for investigating research on translation and Tolking. Translation and Tolking Studies, 3: 87-146. doi: 10.107/tis.3.1-2.04grb. [ Links ]
Illinois Library. 2020. Compare databases and library catalogs. Retrieved from https://www.library.illinois.edu/ugl/howdoi/compare2/. [ Links ]
Kotzé, H. 2020. Interpreting research in South Africa: A bibliometric study. Stellenbosch Papers in Linguistics Plus, 59:45-60. doi: 10.5842/59-0-830. [ Links ]
Kotzé, H & Wallmach, K. 2020. Interpreting research in South Africa: Where to begin to transform? In Kaschula, RH & Wolff, HE (eds). The transformative power of language: From Postcolonial to knowledge societies in Africa. Cambridge: Cambridge, pp. 305-325. [ Links ]
Lesch, HM. 2014. Die waarde en uitdagings van diensleer vir tolkopleiding: Die ervaring van die tolkopleidingsprogram aan die Universiteit Stellenbosch. Stellenbosch Papers in Linguistics Plus, 43(1):209-233. [ Links ]
Makhubu, L. 2015. A systemic modelling approach to interpreting service delivery. Journal of Current issues in Media & Telecommunications, 7(1):37-65. [ Links ]
Okoli, C & Schabram, K. 2010. A guide to conducting a systematic literature review of information systems Navorsing. Retrieved from https://pdfs.semanticscholar.org/31dc/753345d5230e421ea817dd7dcdd352e87ea2.pdf. [ Links ]
Pluddemann, P. 1999. Multilingualism and education in South Africa: One year on. International Journal of Educational Research, 31(4):327-340. [ Links ]
Suid-Afrika. 1996. Die Grondwet van die Republiek van Suid-Afrika, Wet 108 van 1996. Pretoria: Staatsdrukker. [ Links ]
Suid-Afrika Departement van Onderwys. 1997. Language-in-education policy. Pretoria: Departement van Onderwys. [ Links ]
Suid-Afrika Departement van Onderwys. 2002. National Education Policy Act. Pretoria: Departement van Onderwys. [ Links ]
Suid-Afrika Departement van Onderwys. 2009. Language policy incongruity and African languages in postapartheid South Africa. Language Matters, 40(1):35-55. [ Links ]
Van Doorslaer, L. 2016. Bibliometric studies. In CV Angelelli, & BJ Baer (eds). Navorsing translation and Tolking. London: Routledge, pp.168-176. [ Links ]
Wise, P. & Van Zyl, N. 1994. Interpreting: New policy. Bua!, 9(3). [ Links ]
Ontvang: 2021-
Goedgekeur: 2021-11-03
Gepubliseer: Desember 2021

Herculene Kotzé is verbonde aan die NWU as senior lektor in Taalpraktyk.
Sy is 'n opgeleide tolk met praktykervaring in opvoedkundige, gemeenskaps- en konferensie-tolking. Sy is tans adjunkdirekteur van die Skool vir Tale op die Potchefstroomkampus van die NWU, waar sy steeds by voor- en nagraadse on-derrig betrokke is.
Benewens bibliometriese ondersoeke, sluit haar navorsingsbelangstellings tolking, tolkop-leiding, vertaling en die rol wat tolke vervul, in. In hierdie opsig het sy al verskeie nasionale en internasionale kongresvoordragte gelewer, artikels en hoofstukke in boeke gepubliseer.
Herculene dien tans as die Voorsitter van SALALS (Southern African Linguistics and Applied Linguistics Society).
Herculene Kotzé is a senior lecturer, teaching Language Practice at NWU.
She is a trained interpreter with experience in educational, community and conference interpreting. She is currently the deputy director of the School of Languages on the Potchefstroom campus, where she is involved in under- and post-graduate teaching.
Apart from bibliometric investigations, her research interests include interpreting, interpreter training and translation, specifically the role interpreters play. In this regard she has delivered various national and international conference presentations and publications.
Herculene is currently the Chairperson for SALALS (Southern African Linguistics and Applied Linguistics Society).

Roné Wierenga is tans 'n taalkundeskrywer en -navorser vir die Virtuele instituut vir Afrikaans (VivA). Naas hierdie rolle is sy ook werksaam by die Digitale Bibliografie van die Afrikaanse Taalkunde (DBAT) en die Digitale Bibliografie van die Afrikaanse Letterkunde (DBAL), en sy dien as medewerker van die Afrikaanse Taalraad.
Sy onderneem vanjaar 'n Meestersgraad in Linguistiekteorie aan die Noordwes-Universiteit. Haar navorsing fokus op diachroniese, beskry-wende taalkunde, sintaksis en korpuslinguistiek. In 2019 verwerf sy 'n BA Honneurs in Afrikaans en Nederlands, met Klassieke Latyn en Engels as addisionele modules, aan die Noordwes-Universiteit se Potchefstroomkampus.
Roné Wierenga is an author and researcher in linguistics for the Virtual institute for Afrikaans (VivA). She is also involved in the Digital Bibliography for Afrikaans Linguistics and the Digital Bibliography for Afrikaans Literature, as well as the Afrikaans Language Council.
She is currently completing a Master's degree in Linguistic Theory at the North-West University. Her research focus is diachronic, descriptive linguistics, syntax and corpus linguistics. In 2019 she completed her BA honours in Afrikaans and Dutch, with English and Classical Latin as additional modules, at the North-West University's Potchefstroom Campus.
1 'n Vollediger weergawe van hierdie proses is uiteengesit in Okoli en Schabram (2010), asook in Kotzé en Wallmach (2020) en kan dus daar nagegaan word.
2 'n Kenmerk van die databasis is tans dat, indien 'n nagraadse studie 'n artikel oplewer, die twee publikasies afsonderlik getel word. Die rede hiervoor is gewoon dat die twee items in alle waarskynlikheid ewe waardevol is en nie gewoon 'n duplikasie is nie.
3 'n Aantal bibliometriese studies oor die impak van die publikasies wat op IRSA ingesluit is asook die verhoudings tussen outeurs en navorsingsinstansies is reeds gepubliseer of reeds onderweg. Tog, is daar steeds navorsingsmoontlikhede wat nie in hierdie publikasies ontgin is nie.

